本文共 9642 字,大约阅读时间需要 32 分钟。
本文翻译自Adam King于2019.4.28发表的《》,英文好的建议看原文。此翻译版本只是自我学习。
在这篇文章中,我们会创建一个深度强化学习代理(称其为经纪人),使其学习通过交易BTC赚钱。本教程使用OpenAI的gym【】以及stable-baselines库(OpenAI baselines包的一个分叉)的PPO代理。
本系列文章的目的是采用最先进的深度强化学习技术研究是否能创建出可盈利的BTC交易机器人。似乎现在可以很快关闭任何创建强化学习算法的企图,因为这是“建立交易算法的错误方式”。然而,最新研究表明强化学习智体(RL agents)常常表现优于有监督学习。正是基于此,我写了这系列文章来看看这些交易智体到底盈利如何。
非常感谢OpenAI和DeepMind在过去的几年为深度学习研究者开源的众多项目。如果你还没见过他们采用AlphaGo、OpenAI Five、AlphaStar所取得的辉煌成就,你可能落伍了,当然审慎的看待也是必要的。
虽然我们不是去创造奇迹,但是仅仅是在日常交易BTC中获利都是不容易的,不过Teddy Roosevelt曾说:
Nothing worth having comes easy
所以,与其学习手动交易,不如让我们来为自己创建一个机器人。
-
计划

- 为我们的智体创建一个gym环境
- 为环境提出一个简单同时细致的可视化
- 训练我们的智体学出一个正收益的训练策略
如果你不熟悉如何从头创建一个gym环境,或者实现环境可视化,我先前写过相关文章,可以参考。
-
开始
在本教程,我们采用提供的Kaggle数据集。相应的.csv数据文件可以从我的Github仓库中获取。
首先,
import必要的包,确保安装pip install你本地缺少的那些。import gymimport pandas as pdimport numpy as npfrom gym import spacesfrom sklearn import preprocessing然后,为环境创建类。需要传入一个
pandas的dataframe数据类型、可选参数initial_balance、以及lookback_window_size(表示每步中agent观察的时间步长)。手续费默认0.075%,这是Bitmex现行费率,默认serial参数为False,意味着默认情况下以随即切片遍历dataframe数据。我们在
dataframe上调用dropna()以及reset_index(),首先删除含有NaN的行,然后重置数据的index。class BitcoinTradingEnv(gym.Env): """A Bitcoin trading environment for OpenAI gym""" metadata = { 'render.modes': ['live', 'file', 'none']} scaler = preprocessing.MinMaxScaler() viewer = None def __init__(self, df, lookback_window_size=50, commission=0.00075, initial_balance=10000 serial=False): super(BitcoinTradingEnv, self).__init__() self.df = df.dropna().reset_index() self.lookback_window_size = lookback_window_size self.initial_balance = initial_balance self.commission = commission self.serial = serial # Actions of the format Buy 1/10, Sell 3/10, Hold, etc. self.action_space = spaces.MultiDiscrete([3, 10]) # Observes the OHCLV values, net worth, and trade history self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)我们的action_space以一组3元(买、卖、持有)离散数据集和一组10元(1/10,2/10,3/10,…)离散集表示。当选择buy action,我们会买入
amount * self.balance价值的BTC,如果选择sell action,会卖出amount * self.btc_held价值的BTC。以一组
(0-1)之间的连续float集定义我们的observation_space,形状为(10, lookback_window_size + 1).其中+1表示当前时间步。对于窗口内的每个时间步,我们会观察OHCLV值、净值、买入或卖出的BTC数量、以及买卖BTC造成的USD损益。然后,我们需要写出
reset方法来初始化环境。def reset(self): self.balance = self.initial_balance self.net_worth = self.initial_balance self.btc_held = 0 self._reset_session() self.account_history = np.repeat([ [self.net_worth], [0], [0], [0], [0] ], self.lookback_window_size + 1, axis=1) self.trades = [] return self._next_observation()这里,我们同时使用
self._reset_session和self._next_observation,这两个还未定义。下面给出定义。 -
交易周期

我们环境的一个重要部分是trading session的概念。如果我们将此agent部署在原始环境,我们基本不会一次就跑几个月。基于此,限制agent在某行可见的self.df中的连续数据的数量。
在我们的_reset_session方法中,我们首先重置current_step为0,然后设置steps_left为(1,MAX_TRADING_SESSION)之间的随机数。MAX_TRADING_SESSION是在文件头部位置定义的。
MAX_TRADING_SESSION = 100000 # ~2 months然后,如果我们串行遍历数据集,就将数据集设置为可遍历的,不然设置frame_start为self.df中的一个随机点。并创建一个称为active_df的新数据集,这个active_df就是self.df中从frame_start到frame_start + steps_left的切片。
def _reset_session(self): self.current_step = 0 if self.serial: self.steps_left = len(self.df) - self.lookback_window_size - 1 self.frame_start = self.lookback_window_size else: self.steps_left = np.random.randint(1, MAX_TRADING_SESSION) self.frame_start = np.random.randint( self.lookback_window_size, len(self.df) - self.steps_left) self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]以随机切片方式遍历dataframe的一个重要副作用是在长期训练后我们的agent会有很多独特数据。例如,如果我们仅以串行方式遍历数据集(例如,按序从0到len(df)),然后我们会有很多独特数据点。我们的观察空间每个时间步指挥采取一个离散数。
然而,如果随机遍历数据集切片,实际上我们是通过创建更多关于账户资产、交易、初始数据集中的未来数据等的有趣组合。让我们举例说明。
重置连续环境之后经过10时间步,智体总是在数据集内相同时间,每个时间步有3种选择:买、卖、持有。对于每个选择,另一个选择会是数量的10%,20%,…,100%.这意味着我们的智体会经历(1⁰³)¹⁰ 种状态中的任意一种。一共有1⁰³⁰种经历。
现在考虑随即切片的环境,在10时间步,我们的agent会是数据集中的任意len(df)时间步。每个时间步给出相同的各类选项,这意味着agent会经历 len(df)³⁰中的任意一种状态。
这样可能会对大体量数据集带来噪音,我相信这会允许智体从限定数量的数据集中学习。我们依然以串行方式遍历数据集,来获得对于新鲜数据算法有用性更精确的理解,近似理解为实盘。
-
Agent眼看世界
不管智体是作用于哪种特征,可视化一个环境的观察空间通常都是有用的。例如,下面是用OpenCV呈现的观察空间可视化。

图片中的每一行表示observation_space中的一行。像频谱的前面四行表示OHCL数据,虚的橙色和黄色点直接代表成交量。下面的波动蓝柱表示agent的净值,下面的亮点表示agent的交易。
如果你眯起眼睛,你会发现蜡烛图:下面是成交量,再下面有点像莫尔斯电码。看起来像是我们的agent可以从observation_space的数据中充分学习,让我们继续。我们在此定义_next_observation 方法,对观察数据进行归一化。
只对agent已经观察到的信息进行缩放能有效避免前视偏差。
def _next_observation(self): end = self.current_step + self.lookback_window_size + 1 obs = np.array([ self.active_df['Open'].values[self.current_step:end], self.active_df['High'].values[self.current_step:end], self.active_df['Low'].values[self.current_step:end], self.active_df['Close'].values[self.current_step:end], self.active_df['Volume_(BTC)'].values[self.current_step:end], ]) scaled_history = self.scaler.fit_transform(self.account_history) obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0) return obs-
采取行动
现在我们已经建立了观测空间,是时候写出我们的
step函数,然后反过来执行agent的预设行动。对于当前交易周期,无论何时self.steps_left == 0,我们会卖出持有的所有BTC并调用_reset_session()。另一方面,我们为当前净值设置reward,如果钱亏光了就只设置done为True。def step(self, action): current_price = self._get_current_price() + 0.01 self._take_action(action, current_price) self.steps_left -= 1 self.current_step += 1 if self.steps_left == 0: self.balance += self.btc_held * current_price self.btc_held = 0 self._reset_session() obs = self._next_observation() reward = self.net_worth done = self.net_worth <= 0 return obs, reward, done, { }采取行动就跟获取
current_price一样简单,决定一个特定的行动,或买或卖特定数量的BTC。让我们快速写出_take_action以便测试我们的环境。def _take_action(self, action, current_price): action_type = action[0] amount = action[1] / 10 btc_bought = 0 btc_sold = 0 cost = 0 sales = 0 if action_type < 1: btc_bought = self.balance / current_price * amount cost = btc_bought * current_price * (1 + self.commission) self.btc_held += btc_bought self.balance -= cost elif action_type < 2: btc_sold = self.btc_held * amount sales = btc_sold * current_price * (1 - self.commission) self.btc_held -= btc_sold self.balance += sales最后,用相同方法,将交易添加到
self.trades并更新净值和账户历史。if btc_sold > 0 or btc_bought > 0: self.trades.append({ 'step': self.frame_start+self.current_step, 'amount': btc_sold if btc_sold > 0 else btc_bought, 'total': sales if btc_sold > 0 else cost, 'type': "sell" if btc_sold > 0 else "buy" }) self.net_worth = self.balance + self.btc_held * current_price self.account_history = np.append(self.account_history, [ [self.net_worth], [btc_bought], [cost], [btc_sold], [sales] ], axis=1)我们的agent现在可以初始化一个新环境了,在环境内逐步运行,并采取行动影响环境。是时候看他们交易了。
-
观察我们的机器人交易
我们的render方法可以像print(self.net_worth)一样简单,但那样就太无趣了。相反,我们沪指一个带有价格信息和成交量的简单蜡烛图表,并单独呈现净值。
我们采用中
StockTradingGraph.py的代码,并为呈现我们的BTC环境做出适当改变。第一个改变是将所有
self.df['Date']更新为self.df['Timestamp'],并删除所有date2num调用,因为我们的日期已经成为unix时间戳格式。下一步,在我们的render方法中,我们更新数字式的日期标签为输出人可识别的日期。from datetime import datetime首先导入datetime包,然后使用
utcfromtimestamp方法从时间戳中获取UTC字符串,用strftime将此字符转格式化为Y-m-d H:M形式。date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])最后,我们将
self.df['Volume']改为self.df['Volume_(BTC)']以匹配数据集。返回BitcoinTradingEnv,现在我们可以写出render方法来呈现图形。def render(self, mode='human', **kwargs): if mode == 'human': if self.viewer == None: self.viewer = BitcoinTradingGraph(self.df, kwargs.get('title', None)) self.viewer.render(self.frame_start + self.current_step, self.net_worth, self.trades, window_size=self.lookback_window_size)至此,我们就可以观看agent交易BTC了。
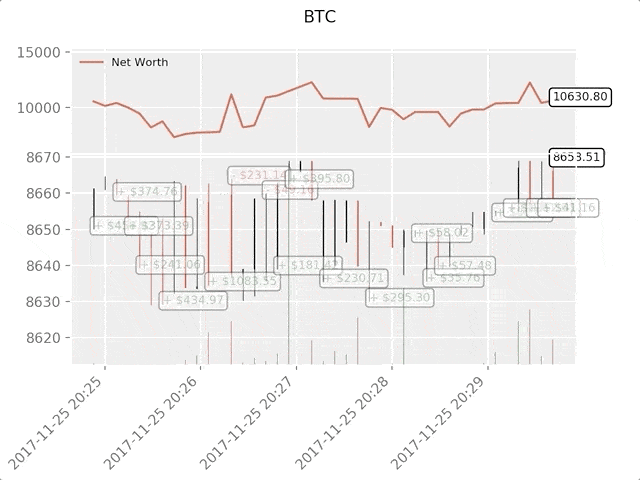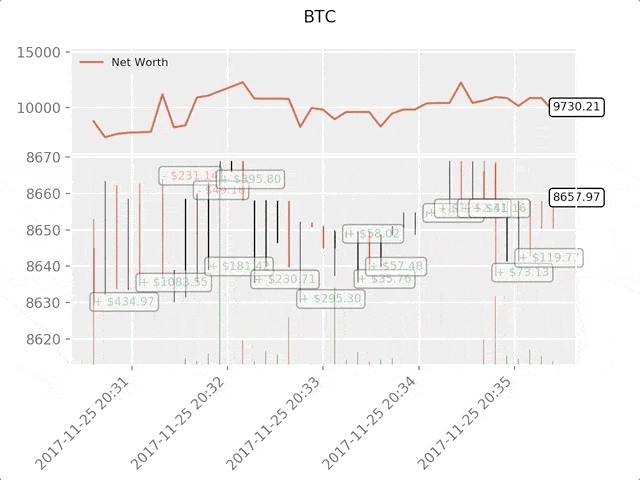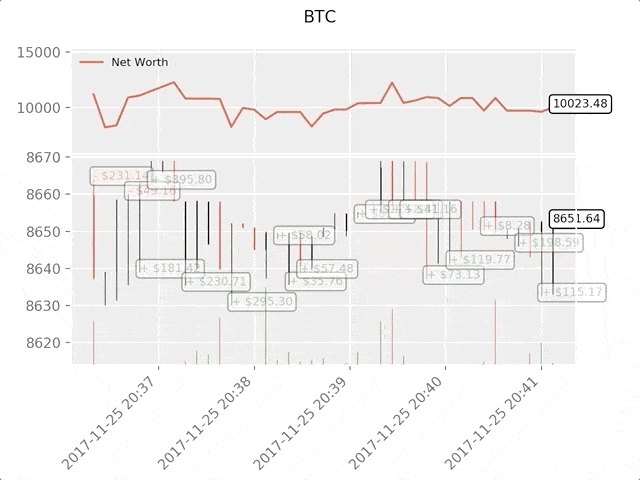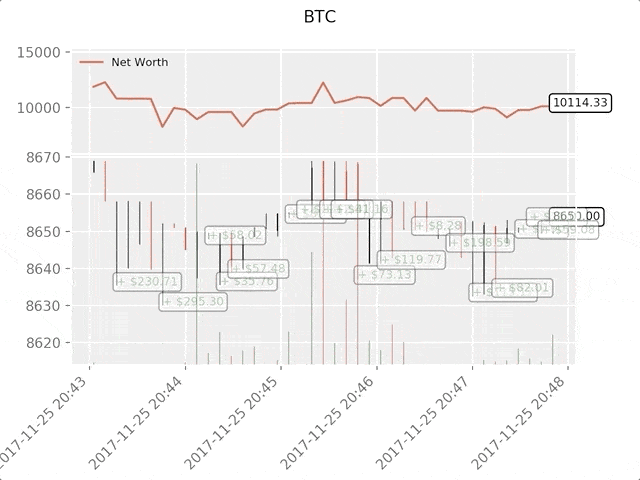
绿色标签表示BTC买入,红色表示BTC卖出。右上角的白色标签是agent的当前净值,右下角标签是BTC现价。简单,但优雅。现在是时候训练我们的agent并看看能为我们赚多少钱。
-
训练时间
我第一篇文章收到的批评有一项是缺乏交叉验证,或者说将数据集分成训练集和测试集。这样做的目的是测试最终模型在未见过的新数据上的准确性。这不是那篇文章的核心概念,在这里就很重要了。因为我们用的是时间序列,当谈及交叉验证时并没有太多选择。
例如,交叉验证的一种常见形式时k折验证,这种方式将数据集分成k等份,把每一子集逐一作为测试集剩余k-1项作为训练集。然而时间序列时时间高度相关的,意味着后续时间与前面的时间有关联。因此k折交叉验证不起作用,因为我们的
agent会从未来数据中学习,这是一种不公平的优势。将大部分交叉验证方法用于时间序列数据有相同缺点。因此就只剩简单的切片方式,随机选取前面的时间作为训练集,后面的数据作为测试集。
slice_point = int(len(df) - 100000)train_df = df[:slice_point]test_df = df[slice_point:]然后,由于我们的环境只设置为处理单数据集,我们创建两个环境,一个用于训练数据,一个用于测试数据。
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])现在,训练模型简单的就像用环境创建一个
agent,并调用model.learn。model = PPO2(MlpPolicy, train_env, verbose=1, tensorboard_log="./tensorboard/")model.learn(total_timesteps=50000)这里我们用
Tensorboard以便于可视化tensorflow图表,并查看一些agent的量化指标。例如下面是许多agents在超过200,000时间步内的折扣奖励。
哇哦,看起来似乎我们的智体收益极佳。我们最好的agent甚至能在200,000步内使账户增长1000倍,其余的平均至少30倍。
正是基于此,我意识到环境有个大bug…下面是修复bug之后新的奖励图。

如你所见,部分agent表现良好,其他的把自己搞破产了。然而,做的好的agents可以翻10倍甚至60倍。我必须指出,所有这些正收益agents都是在无佣金环境下训练和测试的,因此目前依然不能实盘。但是我们已经有进展了。
让我们在测试环境(他们不曾见过的新数据)测试agents,看看他们交易BTC的水平学的怎么样了。

明显,还有更多工作要做。舍弃先用的PPO2agent,改用stable-baseline的A2C模型,可以大大提升表现性能。最后微调reward函数,以获取净值增长奖励而不是仅仅获得高收益并保持在那。
reward = self.net_worth - prev_net_worth这两处修改独立提升模型在测试集上的效果,如下你可以看到,我们终于可以在新数据集上获取收益了。
然而,我们可以做的更好。为了提升结果,我们需要优化超参数、增加训练时长。是时候请出GPU开始工作了。
不过,本文已经够长了,而我们还有很多细节要处理,所以先休息一下。在我下篇文章中,我们用Bayes优化寻求问题的最优超参数。提升agent模型获得高收益训练模型。
-
结论
本文总,我们用深度强化学习。从0开始创建了一个正收益BTC交易机器人。我们是依据如下操作完成的:
- 用OpenAI的gym从头创建一个BTC交易环境
- 用Matplotlib将环境可视化
- 用简单交叉验证训练并测试agents
- 微调agent计算收益率
虽然我们的交易机器人并未获得期待的高收益。但也已经收获波峰。下面,我们会用先进的特征工程和Bayes优化技术提升算法,以确保agent持续战胜市场。
欢迎持续关注我的下篇文章。
Bitcoin万岁!
- Reference
发表评论
最新留言
关于作者
