B站2千万视频信息爬虫
 爬虫代码见
爬虫代码见
发布日期:2022-03-18 18:19:14
浏览次数:6
分类:技术文章
本文共 918 字,大约阅读时间需要 3 分钟。
此文首发于我的个人博客:
声明
- 代码、教程均为本人原创,且仅限于学习交流,请勿用于任何商业用途!
数据结果在最下面。
准备工作
我使用的是Python3,数据库用的是Python自带的sqlite,使用requests库爬取。
安装需要的库pip install requests
直接刷新视频页面来获取视频信息太慢,通过api地址能快速获取视频信息。
如:https://api.bilibili.com/x/web-interface/archive/stat?aid=19801429, 在浏览器中打开这个页面,可以获取json格式的数据:{ "code":0, "message":"0", "ttl":1, "data":{ "aid":19801429, "view":583, "danmaku":4, "reply":2, "favorite":378, "coin":6, "share":6, "now_rank":0, "his_rank":0, "no_reprint":0, "copyright":2}} 使用requests库获取数据,用concurrent.futures的多线程来加快爬取的速度,我采用的是32线程爬取。
数据获取
B站对爬虫采取的是一旦发现,就封ip半小时到1天不等的时间。
但是如果使用代理,爬取总共数量1900万(在2018年2月24,B站视频av号已经到2000万了)个视频信息需要花费很多时间。 幸运的我发现我的服务器爬取B站视频信息不会被封ip,于是我就把爬虫放到服务器上跑了整整5天,获得了1300万条有效数据。数据库文件有300M,GitHub无法上传,数据处理
我使用的是SQLite Studio进行数据库操作
查询播放量前十的视频
查询收藏数前十的视频
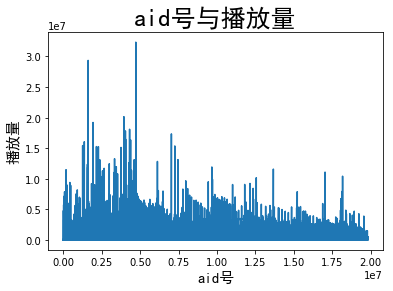
aid号与播放量关系
可以从下图看出,随aid号的增加,视频的平均播放量在变少,爆款视频也在变少。
我认为主要原因是B站UP主变多,把许多大的UP主的粉丝分流了部分。 画图代码见GitHub项目地址:
转载地址:https://zhang0peter.blog.csdn.net/article/details/83419311 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年04月03日 05时46分28秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
expires与etag控制页面缓存的优先级
2019-04-27
取消掉Transfer-Encoding:chunked
2019-04-27
HTTP协议中的Tranfer-Encoding:chunked编码解析
2019-04-27
JavaScript面向对象编程
2019-04-27
在Javascript中使用面向对象的编程
2019-04-27
由浅入深剖析.htaccess
2019-04-27
php函数serialize()与unserialize()
2019-04-27
PHP Webservice的发布与调用
2019-04-27
php反射类 ReflectionClass
2019-04-27
php扩展xdebug基本使用
2019-04-27
为 PHP 应用提速、提速、再提速
2019-04-27
Linux下gedit显示行号
2019-04-27
《Advanced PHP Programming》读书笔记
2019-04-27
让我们谈谈RAID
2019-04-27
jQuery日期选择器插件date-input
2019-04-27
PHP使用curl_multi_add_handle并行处理
2019-04-27
NP问题
2019-04-27
AT&T与Intel汇编语言的比较
2019-04-27
javascript解析json
2019-04-27
WinDbg安装与使用
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308053833 位访客
访问时间: 2024-04-26 13:12:52
访问IP: 3.133.160.156
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版