本文共 3500 字,大约阅读时间需要 11 分钟。
这是我10个月前看到的一篇博客吧,感觉分析指针和引用的文章这是我目前见过讲解得最清晰的一篇:
本文主要基于反汇编代码,从初始化、赋值以及取地址三个角度来理解指针和引用的区别。
初始化
写出以下代码并查看反汇编代码:
int main(){ int x = 5; int * ptr = &x; //指针 int & ref = x; //引用 return 0;}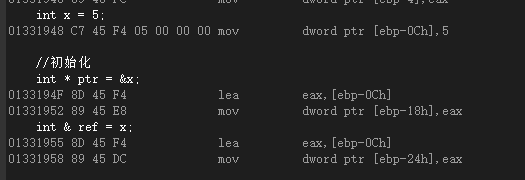
在初始化阶段,指针和引用的行为都是一样的:先将x的地址加载到寄存器eax中,然后把eax的值拷贝到另一个内存地址中。
从反汇编中可以看到,x的地址就是ebp-0ch,对于指针来说,用x的地址来初始化指针ptr实际上就是把x的地址ebp-0c放到了ptr的地址单元中,而ptr的地址则是ebp-18h;
对于引用来说,这里就有点问题了:常说的引用都是“变量的别名”,似乎ref和x就应该是同一个地址,而实际上这里做了和指针初始化相同的操作——把x的地址放到了另一个内存单元(地址为ebp-24h)中。其实在这就可以有一种猜测:虽然ref是x的引用,但是ref也有自己的地址的,而在初始化阶段,它的地址单元中存放的是它所引用的变量x的地址。如下所示:

为了便于叙述,下文中把ref叫做“引用变量”,来表明它也是一个有地址的“变量”(这种说法并不准确,只是暂时找不到其它说法)。
赋值
由于自加自减也是一个赋值的过程,为了便于叙述,这里就用自加来进行分析。写出以下代码并查看反汇编代码:
int main(){ ...... ptr++; //指针自加 ref++; //引用自加 return 0;}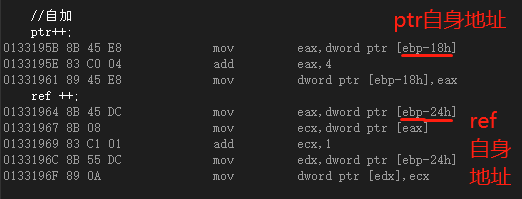
从反汇编代码可以看到,指针的自加和引用的自加是不同的,引用的步骤更多。
在指针方面,一共有三步:①把指针变量ptr内存单元中的数据拷贝到eax;②eax加4(这里的4对应32位编译器下int型的size);③将eax的值写回到指针变量ptr的内存单元中。这三个步骤其实就做了一件事:把指针变量ptr内存单元中的数据加4。而在此之前指针变量ptr的内存单元中存放的是变量x的地址,因此,这就相当于断开了ptr和x之间的联系;
在引用方面,一共有五步:①把引用变量ref内存单元中的数据拷贝到eax;②根据eax的值找到相应的内存单元并把该内存单元中的数据拷贝到ecx中;③ecx加1;④再次把引用变量ref内存单元中的数据拷贝到edx中;⑤把ecx的值写到edx的值对应的内存单元中。要分析这五步做了什么,一定要知道在此之前,引用变量ref的内存单元中存的是变量x的地址。这五步做的事就是:根据ref存放的x的地址来找到x的内存单元,然后把x的内存单元中的值加1。从这个过程可以知道,ref++;表面上是对ref进行自加,而实际上,ref只是一个媒介,通过ref找到x,然后对x进行自加。
通过对二者赋值,可以发现,引用变量ref的确有自己的地址,它在内存中是占空间的。并且指针变量ptr完全具有“主导权”,对指针变量ptr进行赋值,改变的就是它本身;而引用变量ref则完全没有“主导权”,对引用变量ref进行赋值,改变的并不是它本身,而是通过它所找到的x。如下所示:

取地址
对ptr和ref分别进行取地址,这里的变量t和t1可以不用管它,只需要观察取地址的过程。查看相应反汇编代码:
int main(){ ...... //取地址 int ** t1 = &ptr; int * t = &ref; return 0;}
由于不需要管t和t1,因此只需要关注ptr和ref取地址各自反汇编代码第一行即可。
在指针方面,取出ptr的地址&ptr是通过lea eax,[ebp-18h]来实现的。这句汇编代码的意思是,把ebp-18h这个地址,加载到eax中。而在ebp-18h就是指针变量ptr的内存地址,因此,指针变量ptr取地址很直接,就是取出ptr的内存地址;
再看引用方面,取出ref的地址&ref是通过mov eax,dword ptr [ebp-24h]实现的。这句汇编代码的意思是,取出ebp-24h这个地址的内存单元中的值,拷贝到eax中。根据前面已经知道,ebp-24h是ref的地址,在这个地址中存放的是ref引用的x的地址,因此&ref实际上是x的地址。
由此可以发现,对指针取地址,取出的就是指针变量的地址,而对引用取地址,取出的实际上是引用变量所在内存单元中的值,也就是它引用的变量的地址。
总结
1.引用和指针都是占用内存的。引用变量和指针变量各自的内存单元中,存放的都是它们引用或指向的变量的地址;
2.引用实际上是把引用变量本身给隐藏了,表面上对引用变量进行赋值,实际上改变的是它引用的变量的值;表面上是对引用变量取地址,实际上取出来的是它引用的变量的地址;
3.由于引用变量的操作的实际对象都是引用变量所在内存单元中的值,因此引用变量必须和另一个变量关联起来。也就是说,引用必须初始化。原因很简单,如果你不对一个引用进行初始化,那么引用变量的内存单元中存放的都是垃圾数据,后面对引用变量进行操作时就会通过这些垃圾数据找到对应的内存地址,这是非常危险的;
那么直接初始化的时候对引用赋一个常量值呢?这实际上也是不对的,因为引用的初始化实际是用用来初始化的变量的地址来初始化引用变量它自己的内存单元,而一个常量值哪有地址呢?虽然在C++11中已经可以用一个常量来初始化右值引用,但是通过反汇编可以看到,右值引用的根本,还是先用一个地址去保存这个常量值,然后再用这个地址去初始化引用变量。
而指针变量则完全不一样了,指针变量的操作的实际对象都是它自己,因此指针变量不像引用那样必须初始化,但是为了安全,也应该初始化。
4.依然是由于引用变量的一切操作实际对象都是它引用的变量,因此从用户角度来说是没有入口让用户去修改引用变量本身的。换句话说,用户层面没有任何办法去改变引用变量内存单元中存放的地址,这也就是为什么引用一旦初始化后就无法再修改。
5.由于引用变量自身对于用户是不可见的,对引用变量取地址得到的也不是引用变量的地址,因此你无法让一个引用变量的内存中存放另一个引用变量的地址,换句话说,不存在引用的引用。而相反,由于指针变量取出来的地址就是它本身的地址,因此你完全可以把一个指针变量的地址存放在另一个指针变量的内存中,这也就是为什么可以存在多级指针,但是多级引用是不允许的。
6.关于“引用是变量的别名”的考虑。感觉这句话既对也不对,说它不对是因为引用变量和引用的变量二者实际上是独立的两块内存单元,只不过前者依托后者而存在,但是这并不能说前者就是后者的别名,这是矛盾的;说它对,是因为对引用变量进行操作时,改变的对象实际上都是引用的变量而不是引用变量,这就感觉引用变量只是一层伪装,真正的还是它引用的变量,从这个角度来说,引用确实可以说是变量的别名。
7.函数传指针与传引用的区别。函数传指针的原型类似于int add(int * a, int * b);这类函数的形参是指针,调用方式为int x = 1, y = 2; add(&x,&y);那么传入的实参则是变量的地址,因此在函数内部,是用地址型实参&x和&y来初始化形参a和b,相当于int *a = &x,int * b = &y的;因此形参a和b内存单元中存放的是x和y的地址。
而对于函数传引用,函数原型则类似于int add(int & a,int & b),这类函数的形参是引用,调用方式为int x = 1, y = 2; add(x,y);传入的实参就是x和y变量自身,在函数内部,则是用x和y来初始化a和b,相当于int &a = x,int &b = y,因此,形参a和b内存单元中存放的也是x和y的地址,不过它毕竟是引用,如前面所说,当你试图对形参a或b的值进行改变的时候,改变的不是它内存中存放的&x和&y,其实是x或y;当你对形参a或b取地址时,取出来的并不是形参本身的地址,而是它内存中存放的&x和&y。
而再说一个与本文无关的函数传值,如int add(int a,int b);这类函数的形参只是普通的int型变量,当调用add(x,y)时,在函数内部实际上就是用x和y来初始化a和b,相当于int a = x,int b = y,所以形参和实参实际上只是值相同而已,改变形参并不会影响实参。
发表评论
最新留言
关于作者
