本文共 15814 字,大约阅读时间需要 52 分钟。
文章目录
数据解析分类
- 正则
- bs4
- xpath(***)
数据解析原理
- 解析的局部文本内容都会在标签之间或者标签对应属性中进行存储
- 进行指定标签定位
- 标签或标签对应属性中存储的数据值进行提取
正则匹配
先学习正则表达式
import re// \w 匹配数字、字母、下划线print(re.findall('\w','abc123_*()-=')) # findall是从左到右匹配字符串// ['a', 'b', 'c', '1', '2', '3', '_']// \W 匹配非数字字母下划线print(re.findall('\W','aAbc123_*()-='))//['*', '(', ')', '-', '=']// \s 匹配任意空白字符,等价于\t\n\r\fprint(re.findall('\s','aAb\tc\r123_*()-= '))//['\t', '\r', ' ']// \S 匹配任意非空字符print(re.findall('\S','aAb\tc\r123_*()-= '))//['a', 'A', 'b', 'c', '1', '2', '3', '_', '*', '(', ')', '-', '=']// \d 匹配任意数字,等价于[0-9]print(re.findall('\d','aAb\tc\r123_*()-= '))//['1', '2', '3']// \D 匹配任意非数字print(re.findall('\D','aAb\tc\r123_*()-= '))//['a', 'A', 'b', '\t', 'c', '\r', '_', '*', '(', ')', '-', '=', ' ']// \A 只匹配字符串的开头print(re.findall('\Ashyshy','shyshyis is 20'))//['shyshy']// \Z 只匹配字符串的结尾print(re.findall('20\Z','shyshyis is 20'))//['20']// ^ 匹配字符串的开头print(re.findall('^shyshy','shyshyis is 20'))//['shyshy']// $ 匹配字符串的结尾print(re.findall('20$','shyshyis is 20'))//['20']// . 匹配除\n外的任意字符,指定re.DOTALL才能匹配换行符print(re.findall('a.b','a b ab acb a\nb acccb'))//['a b', 'acb']print(re.findall('a.b','a b ab acb a\nb acccb',re.DOTALL))//['a b', 'acb', 'a\nb']// * 左侧字符重复0次或无数次print(re.findall('ab*','ab abb abbbbbbb ab aa'))// ['ab', 'abb', 'abbbbbbb', 'ab', 'a', 'a']// + 左侧字符重复1次或无数次print(re.findall('ab+','ab abb abbbbbbb ab aa bbbbbbbbb'))// ['ab', 'abb', 'abbbbbbb', 'ab']// ? 匹配左侧字符0次或1次print(re.findall('ab?','ab abb abbbbbbb ab aa bbbbbbbbb'))// ['ab', 'ab', 'ab', 'ab', 'a', 'a']// { m,n} 匹配左侧字符m到n次,{ n} 代表只出现n次print(re.findall('ab{2,5}','ab abb abbbbbbb ab aa bbbbbbbbb'))// ['abb', 'abbbbb']// [] 匹配字符1次print(re.findall('a[0-9]b','a1b a22b acb'))// ['a1b']// [^] 对匹配的内容取反print(re.findall('a[^0-9]b','a1b a22b acb'))// ['acb']// () 是为了提取匹配字符串的,表达式中有几个()就有几个相应的匹配字符串爬取糗事百科图片
首先是爬取单个图片
import requestsif __name__ == '__main__': url = 'https://pic.qiushibaike.com/system/pictures/12401/124017243/medium/CAN7KLR2PPDXJ932.jpg' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' } # content返回文件的二进制数据 # text (字符串) content (二进制数据) json(对象) img_data = requests.get(url=url,headers=headers).content with open('./1.jpg','wb') as fp: fp.write(img_data)注意url是图片的地址,和之前的爬取文本不同,这里因为爬取的是图片,所有获取数据时不说text,而是能返回文件二进制数据的content,在写入时,注意是wb而并非w,下面是他们的区别:
w 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
接下来是爬取这一页的所有图片,首先,可以在源码中看到图片的地址,主要是被以下标签包裹
<div class="thumb"> <a href="/article/124104208" target="_blank"> <img src="//pic.qiushibaike.com/system/pictures/12410/124104208/medium/JIIR7Y6T2PDU8P0V.jpg" alt="糗事#124104208" class="illustration" width="100%" height="auto"> </a> </div>想要得到中间的地址,需要用正则匹配
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'这里面,.*?表示非贪婪匹配,满足条件的情况只匹配一次,()用于提取匹配字符串的。
匹配完了后,因为这个网址中没有协议头,需要拼接一个https:上去,这个可以用列表遍历来实现;因为图片数量比较多,可以用os模块去执行系统命令os.mkdir('./qiutupic'),创建一个目录,然后将图片保存到里面。
最后,还剩下图片名的问题,可以看到,html标签中是有图片名的,我们可以用字符串切割,来得到图片名,这里可以用split()函数来实现。
import requestsimport reimport osif __name__ == '__main__': if not os.path.exists('./qiutupic'): os.mkdir('./qiutupic') url = 'https://www.qiushibaike.com/imgrank/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' } # 使用通用爬虫对url对应的一整张页面爬取 page_text = requests.get(url=url, headers=headers).text # 使用聚焦爬虫对页面中所有糗图进行提取 """ <div class="thumb"> <a href="/article/124104208" target="_blank"> <img src="//pic.qiushibaike.com/system/pictures/12410/124104208/medium/JIIR7Y6T2PDU8P0V.jpg" alt="糗事#124104208" class="illustration" width="100%" height="auto"> </a> </div> """ ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>' img_src_list = re.findall(ex, page_text, re.S) print(img_src_list) for src in img_src_list: # 拼接出一个完整的url src = 'https:' + src img_data = requests.get(url=src, headers=headers).content # 生成图片名称 img_name = src.split('/')[-1] //将url以/切割开后,查找倒数第一个(-1) # 拼接图片路径 imgpath = './qiutupic/' + img_name with open(imgpath,'wb') as fp: fp.write(img_data) print(img_name + 'success')str.split(str="", num=string.count(str)).
str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num – 分割次数。默认为 -1, 即分隔所有。
最后,实现对每个分页的爬取,
import requestsimport reimport osif __name__ == '__main__': headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' } if not os.path.exists('./wholeqiutupic'): os.mkdir('./wholeqiutupic') # 设置通用url模板 url = 'https://www.qiushibaike.com/imgrank/page/%d' for pagenum in range(1,13): # 对应页码的url new_url = format(url%pagenum) # 使用通用爬虫对url对应的一整张页面爬取 page_text = requests.get(url=new_url, headers=headers).text # 使用聚焦爬虫对页面中所有糗图进行提取 """ <div class="thumb"> <a href="/article/124104208" target="_blank"> <img src="//pic.qiushibaike.com/system/pictures/12410/124104208/medium/JIIR7Y6T2PDU8P0V.jpg" alt="糗事#124104208" class="illustration" width="100%" height="auto"> </a> </div> """ ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>' img_src_list = re.findall(ex, page_text, re.S) print(img_src_list) for src in img_src_list: # 拼接出一个完整的url src = 'https:' + src img_data = requests.get(url=src, headers=headers).content # 生成图片名称 img_name = src.split('/')[-1] # 拼接图片路径 imgpath = './wholeqiutupic/' + img_name with open(imgpath,'wb') as fp: fp.write(img_data) print(img_name + 'success')因为每次换页,不同的是url中最后的数字,所以可以采用for循环的方式,依次遍历,并格式化字符串,将页数填充到url中,这样就可以实现对不同页数的爬取。
bs4
bs4数据解析的原理:
- 实例化一个BeautifulSoup对象,并将页面源码数据加载到该对象中
- 通过调用BeautifulSoup对象中相关属性或方法进行标签定位和数据提取
环境安装
pip install bs4pip install lxml对象的实例化
- 将本地的html文档中的数据加载到该对象中
from bs4 import BeautifulSoupif __name__ == '__main__': # 将本地html文档的数据加载到对象中 fp = open('./baidu.html', 'r', encoding='utf-8') soup = BeautifulSoup(fp, 'lxml') print(soup)- 将互联网上获取的源码加载到该对象中
page_text = response.textsoup = BeautifulSoup(page_text,'lxml')数据解析的方法和属性
- soup.tagName:返回的是html中第一次出现的tagName标签内容
print(soup.a)"""输出内容:<a class="toindex" href="/">百度首页</a>"""soup.find('tagName'):作用等同于soup.tagNamesoup.find('div',class_='s-isindex-wrap'):查找div标签中class为s-isindex-wrap的内容soup.find_all('tagName'):以列表方式返回符合要求的所有标签soup.select('某种选择器(id、class、标签选择器)'):返回的是一个列表soup.select('.tang > ul >li >a'):>表示的是一个层级soup.select('.tang > ul a'):空格表示的是多个层级soup.tagName.text/string/get_text():获取标签间文本数据,text/get_text()能获取标签中所有的文本内容,string只可以获取该标签下的直系文本内容soup.a['href']:获取标签中属性值
爬取三国演义所有标题和内容
想要爬取所有标题和内容,先信息搜集
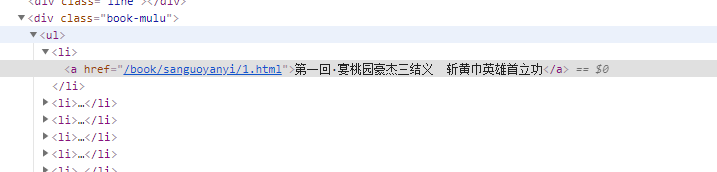
文章标题是存在这里的,前面a标签里的是标题对应章节的链接,可以用前面的bs4数据解析爬取到。先爬取所有li标签,然后用遍历的方法,得到每个li标签里章节对应的内容。
# 需求:爬取三国演义所有章节和内容import requestsfrom bs4 import BeautifulSoupif __name__ == '__main__': # 对首页页面数据进行爬取 url = 'https://www.shicimingju.com/book/sanguoyanyi.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/86.0.4240.75 Safari/537.36' } page_text = requests.get(url=url, headers=headers).text.encode('ISO-8859-1') # 在首页中解析出标题和url # 1.实例化beautifulsoup对象 soup = BeautifulSoup(page_text, 'lxml') # 解析章节标题和详情页url li_list = soup.select('.book-mulu > ul > li') fp = open('./sanguoyanyi.txt','w',encoding='utf-8') for li in li_list: title = li.a.string detail_url = 'http://www.shicimingju.com' + li.a['href'] # 对详情页发请求,得到文章内容 detail_page_text = requests.get(url=detail_url, headers=headers).text.encode('ISO-8859-1') # 解析出详情页内容 detail_soup = BeautifulSoup(detail_page_text, 'lxml') div_tag = detail_soup.find('div', class_='chapter_content') content = div_tag.text fp.write(title+':'+content+'\n') print(title,'爬取成功')xpath
最常用且最便捷高效的一种解析方式
原理:
- 实例化一个etree对象,且需要将被解析的页面源码数据加载到该对象中
- 调用etree对象中的xpath方法结合xpath表达式实现标签的定位和内容的捕获
环境安装
pip install lxml对象的实例化
- 将本地的html文档中的源码数据加载到etree对象中
etree.parse(filepath)- 将互联网上获取的源码数据加载到etree对象中
etree.HTML('page_text')xpath表达式
from lxml import etreeif __name__ == '__main__': # 1.实例化好一个etree对象,且将被解析的源码加载到该对象中 parser = etree.HTMLParser(encoding='utf-8') tree = etree.parse('./sougou.html', parser=parser) # 注意和视频里的不同,否则会报错 r = tree.xpath('/html/head/meta') r = tree.xpath('//script[@type="text/javascript"]') r = tree.xpath('//div[@class="top-nav"]/ul/li[3]') r = tree.xpath('//div[@class="top-nav"]/ul/li[3]/a/text()') print(r)"""输出结果:[<Element meta at 0x22136e7e4c0>, <Element meta at 0x22136e7e500>, <Element meta at 0x22136e7e540>, <Element meta at 0x22136e7e580>, <Element meta at 0x22136e7e5c0>][<Element script at 0x1f7d478f4c0>][<Element li at 0x2211a1af3c0>]['知乎']"""/表示的是从根节点开始定位,表示的是一个层级。
//表示的是多个层级,也可以表示从任意位置开始定位
属性定位://script[@type="text/javascript"]—>tag[@attrName="attrValue"
索引定位://div[@class="top-nav"]/ul/li[3] 索引从1开始
取文本:/text()获取直系标签中文本内容,//text()获取非直系标签
爬取58同城北京二手房名称
import requestsfrom lxml import etreeif __name__ == '__main__': # 爬取页面数据 url = 'https://bj.58.com/ershoufang/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' } page_text = requests.get(url=url, headers=headers).text # 数据解析 tree = etree.HTML(page_text) div_list = tree.xpath('//div[@class="property-content-title"]') fp = open('./ershoufang.txt', 'w', encoding='utf-8') for div in div_list: title = div.xpath('./h3/text()')[0] fp.write(title+'\n')
信息搜集发现每个标题都是在这个div标签内的,只需要定位到该div标签,然后定位到h3标签,就能获取里面的文本。
研(我)究(是)了(个)一(Fe)下(f)午(w),终于想到能把房子名称和价格一一对应的方法,每一步的解释都在代码中的注释里
import requestsfrom lxml import etreeif __name__ == '__main__': # 爬取页面数据 url = 'https://bj.58.com/ershoufang/' title_list = [] # 用于存储房子名称 title_price = [] #用于存储房子价格 flat_information = { } #用于存储上面两列表合并后的数据 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' } page_text = requests.get(url=url, headers=headers).text # 数据解析 tree = etree.HTML(page_text) div_name_list = tree.xpath('//div[@class="property-content-title"]') div_price_list = tree.xpath('//div[@class="property-price"]') fp = open('./ershoufang.txt', 'w', encoding='utf-8') # 创建文本文档,用于保存房子信息 for div1 in div_name_list: title = div1.xpath('./h3/text()')[0] # 定位到房子名称相应的位置 title_list.append(title) # 往列表中添加房子名称 for div2 in div_price_list: price = div2.xpath('./p/span[@class="property-price-total-num"]/text()')[0] # 定位到房子价格数字相应的位置 unit = div2.xpath('./p/span[@class="property-price-total-text"]/text()')[0] # 定位到房子价格单位相应的位置 title_price.append(price + unit) # 往列表中添加房子价格 flat_information = dict(zip(title_list, title_price)) #将房子名称和房子价格两个列表合并为一个字典 for k in flat_information: fp.write('%s : %s' % (k,flat_information[k]) + '\n') #遍历字典,用格式化字符串将房子名称和价格一一对应输出爬取4k网站图片
网站url:
先进行信息搜集,

可以看到,图片的地址和名称都在//div[@class="slist"]/ul/li/a中,而每一个li标签对应着一张图片,那么就可以先将li标签存储在列表中,然后用for循环遍历的方法,逐一访问和爬取。
直接上代码,解释都在注释中。
from lxml import etreeimport requestsimport osif __name__ == '__main__': if not os.path.exists('./love'): os.mkdir('./love') url = 'https://pic.netbian.com/4kmeinv/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' } response = requests.get(url=url, headers=headers) # 手动设置相应数据的编码方式 # response.encoding = 'gbk' page_text = response.text # 数据解析:src属性值 alt属性值 tree = etree.HTML(page_text) li_list = tree.xpath('//div[@class="slist"]/ul/li') for li in li_list: img_src = 'http://pic.netbian.com' + li.xpath('./a/img/@src')[0] img_name = li.xpath('./a/img/@alt')[0] + '.jpg' # 处理乱码的常规操作 img_name = img_name.encode('iso-8859-1').decode('gbk') # print(img_name,img_src) # 获取网址对应图片数据 img_data = requests.get(url=img_src, headers=headers).content img_path = './love/' + img_name with open(img_path, 'wb') as fp: fp.write(img_data) print(img_name + 'finish')以上的代码,实现了对一页图片的爬取,这个网站一共有172页的图片,如果想要爬取全部呢?可以用函数来实现。注意到每一页的url区别,都是index_数字.html,那么可以采用格式化字符串的方法,将所有页面的url存储到一个列表中,再将爬取一页的代码用函数封装,实现对每一页的爬取。
from lxml import etreeimport requestsimport osdef getpic(the_url): response = requests.get(url=the_url, headers=headers) # 手动设置相应数据的编码方式 # response.encoding = 'gbk' page_text = response.text tree = etree.HTML(page_text) li_list = tree.xpath('//div[@class="slist"]/ul/li') for li in li_list: img_src = 'http://pic.netbian.com' + li.xpath('./a/img/@src')[0] img_name = li.xpath('./a/img/@alt')[0] + '.jpg' # 处理乱码的常规操作 img_name = img_name.encode('iso-8859-1').decode('gbk') # print(img_name,img_src) # 获取网址对应图片数据 img_data = requests.get(url=img_src, headers=headers).content img_path = './love/' + img_name with open(img_path, 'wb') as fp: fp.write(img_data) print(img_name + 'finish')if __name__ == '__main__': if not os.path.exists('./love'): os.mkdir('./love') url = 'https://pic.netbian.com/4kmeinv/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' } all_url = [] for i in range(2, 172): each_url = url + ('index_%d.html' % i) all_url.append(each_url) for one_url in all_url: getpic(one_url)爬取全国城市名
网站url:
先进行信息搜集,可以看到网站中城市分为热门城市和其他城市,这两个种类里城市名所在的标签也是不同的,热门城市的名称所在标签为div[@class="bottom"]/ul/li/a,其他城市的名称所在的标签为div[@class="bottom"]/ul/div[2]/li/a
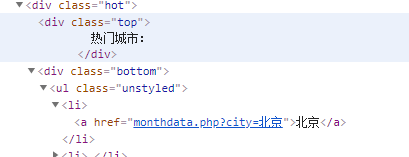
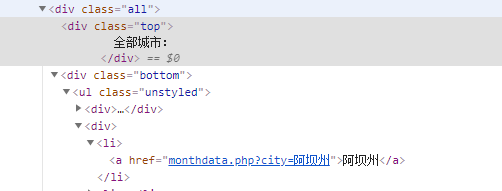
直接上代码:
import requestsfrom lxml import etreeif __name__ == '__main__': url = 'https://www.aqistudy.cn/historydata/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' } page_text = requests.get(url=url,headers=headers).text tree = etree.HTML(page_text) hot_li_list = tree.xpath('//div[@class="bottom"]/ul/li') # print(hot_li_list) all_city_name = [] # 解析到热门城市名称 for li in hot_li_list: hot_city_name = li.xpath('./a/text()')[0] all_city_name.append(hot_city_name) # 解析到其他城市名称 other_li_list = tree.xpath('//div[@class="bottom"]/ul/div[2]/li') # print(other_li_list) for li in other_li_list: other_city_name = li.xpath('./a/text()')[0] all_city_name.append(other_city_name) print(all_city_name,len(all_city_name))上面的程序是将热门城市及其他城市分开爬取的,想要将他们合并在一起,可以使用到|运算符://div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a
import requestsfrom lxml import etreeif __name__ == '__main__': url = 'https://www.aqistudy.cn/historydata/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' } page_text = requests.get(url=url,headers=headers).text tree = etree.HTML(page_text) a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a') all_city_name = [] for a in a_list: one_city_name = a.xpath('./text()')[0] all_city_name.append(one_city_name) print(all_city_name, len(all_city_name))发表评论
最新留言
关于作者
