数据结构-重中之重-搞懂哈希表(python)
发布日期:2021-05-07 08:51:57
浏览次数:22
分类:原创文章
本文共 2447 字,大约阅读时间需要 8 分钟。
哈希表
1.定义
\quad \quad 哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接访问内存存储位置的数据结构。 也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做哈希函数,存放记录的数组叫做哈希表。
-
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的存储位置,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。说白了,hash函数就是根据key计算出应该存储地址的位置,而哈希表是基于哈希函数建立的一种查找表。
-
例子:让哈希函数H(x)映射数组中索引x%10处的值。例如,如果值列表是[11,12,13,14,15],则它将分别存储在数组或哈希表中的位置{1,2,3,4,5}。
2.哈希函数的构造方法
- 构造函数时容易遇到的 “冲突”:
两个关键字key1!=key2,但是却有f(key1)=f(key2),这种现象,我们称为“冲突”,并把key1与key2称为这个散列函数的同义词。 - 好的哈希函数的评价标准:
1)计算简单
2)散列地址分布均匀
2.1直接定址法

2.2 数字分析法

- 数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀,就可以考虑用这个方法。
2.3 平方取中法
-
取关键字平方后的中间几位作为哈希地址。
-
平方取中法比较适合于不知道关键字的分布,而位数又不是很大的情况。
2.4 折叠法


2.5 除留余数法

- 本方法的关键在于选择合适的p值。
- 一般情况下,若散列表表长为m,p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因数的合数。这样可以减少地址的重复(冲突)。
例子:

2.6随机数法


3.处理冲突的方法
3.1 开放定址法

- 所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列表地址总能找到,并将记录存入。
- 公式:
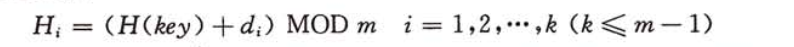
其中,H(key)为哈希函数,m为哈希表长度, d i d_i di为增量序列,有以下三种取法:


注意:
d i d_i di取二次探测再散列时表长m必须为4j+3的质数(二次探测再散列表长有限制)
随机探测时m和 d i d_i di没有公因子(随机探测 d i d_i di有限制)
3.2 再哈希法

3.3 链地址法

- 将所有关键字为同义词的记录存储在同一线性链表中,我们称这种表为同义词子表,在散列表中只存储所有同义词子表的头指针。即产生hash冲突后在存储数据后面加一个指针,指向后面冲突的数据

3.4 公共溢出区法

例子:

4.hash表的查找




哈希表的查找时间复杂度:O(1)
5.python-hash表以及哈希查找的实现
1.选择哈希函数(散列函数)——下面选择除留余数法
2.选择解决冲突的方法——下面选择线性探索再散列法
【python代码实现】
class HashTable: def __init__(self, size): self.elem = [None for i in range(size)] # 使用list数据结构作为哈希表元素保存方法 self.count = size # 最大表长 def hash(self, key): return key % self.count # 散列函数采用除留余数法 def insert_hash(self, key): """插入关键字到哈希表内""" address = self.hash(key) # 求散列地址 while self.elem[address]: # 当前位置已经有数据了,发生冲突。 address = (address+1) % self.count # 线性探测下一地址是否可用 self.elem[address] = key # 没有冲突则直接保存。 def search_hash(self, key): """查找关键字,返回布尔值""" star = address = self.hash(key) while self.elem[address] != key: address = (address + 1) % self.count if not self.elem[address] or address == star: # 说明没找到或者循环到了开始的位置 return False return True if __name__ == '__main__': list_a = [12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34] hash_table = HashTable(12) for i in list_a: hash_table.insert_hash(i) for i in hash_table.elem: if i: print((i, hash_table.elem.index(i)), end=" ") print("\n") print(hash_table.search_hash(15)) print(hash_table.search_hash(33))6.小结
- 哈希表(散列表)技术具有很好的平均性能,优于一些传统的技术
- 链地址法优于开地址法
- 除留余数法作散列函数优于其他类型函数
发表评论
最新留言
很好
[***.229.124.182]2025年04月17日 20时50分46秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
常用Windows 快捷键
2019-03-06
linux命令-压缩与打包
2019-03-06
ORACLE 11g 生产中高水位线(HWM)处理
2019-03-06
centos 6.x 编译安装 pgsql 9.6
2019-03-06
weblogic 服务器部署SSL证书
2019-03-06
oracle 11g not in 与not exists 那个高效?
2019-03-06
Linux 安装Redis 5.0(以及参数调优)
2019-03-06
html5 Game开发系列文章之 零[开篇]
2019-03-06
为什么阿里巴巴建议集合初始化时,指定集合容量大小
2019-03-06
为什么阿里巴巴要求谨慎使用ArrayList中的subList方法
2019-03-06
Redis不是一直号称单线程效率也很高吗,为什么又采用多线程了?
2019-03-06
基于Python的Appium环境搭建合集
2019-03-06
Requests实践详解
2019-03-06
接口测试简介
2019-03-06
Golang Web入门(4):如何设计API
2019-03-06
让sublime实现js控制台(前提是安装了nodejs)
2019-03-06
树莓派连接二手液晶屏小记
2019-03-06
error: 'LOG_TAG' macro redefined
2019-03-06
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 459579049 位访客