Python学习-基础(四)
发布日期:2021-05-07 06:37:08
浏览次数:24
分类:精选文章
本文共 3425 字,大约阅读时间需要 11 分钟。
- 注释
- 代码块
- 数据类型
- /,//,%
- 字符编码
- 格式化
一:注释
#python注释(ctrl+/):也可以选中当多行注释用备注:在java中注释有单行注释(Ctrl + /):// 多行注释(选中代码,Ctrl+Shift+/):/* ...... */取消还是同样操作
二:代码块
每一行都是一个语句,当语句以冒号:结尾时,缩进的语句视为代码块,使用4个空格的缩进//使用pycharm直接帮我缩进了if a >= 0: print(a)备注:java是这样写的if (a >= 0){ System.out.println(a);}
三:数据类型
#整数:Python3 支持 int(长整型)、float、bool、complex(复数)a = int(input("输入十进制数字10:"))print("二进制:", bin(a), "八进制:", oct(a), "十六进制:", hex(a))结果:二进制: 0b1010 八进制: 0o12 十六进制: 0xa二进制:以0B或者0b开头八进制:以0o或0O开头十六进制:以0X或0x开头print(type(a)) print(isinstance(a, int))True //整数十六进制用0x前缀和0-9,a-f表示//浮点数对于很大或很小的浮点数,用科学计数法表示,把10用e替代,1.23x109(9是次方)就是1.23e9//字符串以单引号'或双引号"括起来的任意文本如果'本身也是一个字符,那就可以用""括起来如果字符串内部既包含'又包含",可以用转义字符\来标识:如\',\"// r'内容' , ''内部的字符串默认不转义print(r'a\\1,')结果a\\1,// r'''内容'''(这个里面的内容换行输出也是换行的)print(r'''\\''')输出\\//布尔值布尔值只有True、False两种值布尔值可以用and、or和not(单目运算符)运算not True输出的false//空值用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值还有列表、字典、自定义类型等下面有bytes备注:java是这样的Java中8种基本数据类型(内置数据类型):逻辑类型:boolean整数类型:byte,short,int,long字符类型:char浮点类型:float,double还有引用类型:如string
//变量可以把一个变量a赋值给另一个变量b,这个操作实际上是把变量b指向变量a所指向的数据a = 'ABC'b = aa = 'XYZ'print(b)b输出的是ABC//常量使用大写去表示//理解a = 'ABC'在内存中创建了一个'ABC'的字符串;在内存中创建了一个名为a的变量,并把它指向'ABC'
四:/,//,%
#结果是浮点数:输出3.3333333333333335print(10/3)#地板除,支取整数部分:输出3print(10//3)#求余数:输出1print(10%3)Python的整数和浮点数没有大小限制,但是超出一定范围就直接表示为inf(无限大)
五:字符编码
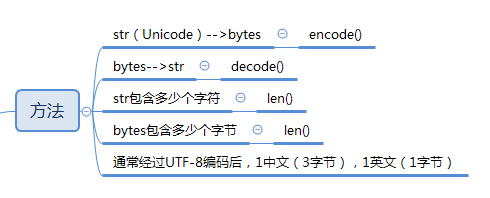
- ASCII:大小写英文、数字、符号(美国人发明的计算机,8比特(bit)=1字节(byte),1字节能表示最大的整数为255,二进制11111111=十进制255)
- 中文超出ASCII范围,而且存储中文至少2个字节,中国制定了
GB2312编码(每个国家都有自己的编码),于是不可避免有乱码 - 于是Unicode把所有语言都统一到一套编码里,这样就不会再有乱码,而且像ASCII,前面加0,就是Unicode编码了
- Unicode比ASCII要更多的存储空间,于是UTF-8诞生(可变长),UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节

计算机内存中,统一使用Unicode编码例子:编辑文本:从文件读取的utf-8字符转换为Unicode字符到内存里保存文本:把Unicode转化为utf-8保存在文件
Python 3版本中,字符串是以Unicode编码的
//注意:针对单个字符串#获取字符的整数表示print(ord('A'))#结果65#把编码转换为对应的字符print(chr(65))#结果A
(2)Python对bytes类型的数据用带b前缀的单引号或双引号表示
注意区分'ABC'和b'ABC',前者是str,但bytes的每个字符都只占用一个字节
在bytes中,无法显示为ASCII字符的字节,用\x##显示
以Unicode表示的str通过encode()方法可以编码为指定的bytes,如下:
#结果是b'ABC'print('ABC'.encode('ascii'))#结果是b'\xe4\xb8\xad\xe6\x96\x87'print('中文'.encode('utf-8'))#报错,中文编码的范围超过了ASCII编码的范围print('中文'.encode('ascii'))
从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
#结果是ABCprint(b'ABC'.decode('ascii')) #报错,bytes中包含无法解码的字节print(b'\xe4\xb8\xad\xff'.decode('utf-8'))#上面bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节#输出中print(b'\xe4\xb8\xad\xff'.decode('utf-8',errors='ignore'))
(3)1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节
#计算str包含多少个字符,可以用len()函数#结果3print(len('ABC'))#结果3,空格也算一个字符print(len(' 中文'))#如果换成bytes,len()函数就计算字节数#结果3print(len(b'ABC'))#结果是b'\xe4\xb8\xad\xe6\x96\x87'print('中文'.encode('utf-8'))#结果6print(len('中文'.encode('utf-8')))
(4)
#!/usr/bin/env python3# -*- coding: utf-8 -*-第一行告诉Linux/OS X系统,这是一个Python可执行程序第二行告诉Python解释器,按照UTF-8编码读取源代码
注意,如果你是使用Notepad++,就算声明了上面两句,还要确保文本编辑器正在使用UTF-8 without BOM编码
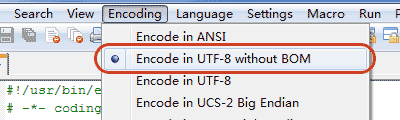
我使用这个也可以正确输出
六:格式化
(1)%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换
有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略
注意%前后有个空格,内容中,后的空格,可读性会更好
#‘%s%d’ % ('', )#输出hello worldprint('hello %s' % 'world')#有两个%?后面括号不能省略,而且?对应的值要符合#输出hello world50print('hello %s%d' % ('world', 50))

如果不确定用什么,使用%s,它会把任何数据类型转换为字符串
用%%来表示一个%
#格式化整数和浮点数还可以指定是否补0和整数与小数的位数print('%2d-%02d' % (3, 1))#结果:(前者补了空格,后者补了0) 3-01
(2)另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……
print('hello {0}'.format('world'))#结果:hello world#注意是从第0开始, .1f表示浮点型小数取一位#结果是10.1,10print('{0:.1f},{1}'.format(10.12,10))
发表评论
最新留言
很好
[***.229.124.182]2025年03月29日 17时17分46秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
系统编程-进程-ps命令、进程调度、优先级翻转、进程状态
2021-05-09
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 459555997 位访客
访问时间: 2025-04-19 17:17:46
访问IP: 3.138.181.157
Copyright © 2020 - 2025 css8.cn 京ICP备2021015314号-1
手机版