本文共 18829 字,大约阅读时间需要 62 分钟。
如何使用mmdetection训练自己的数据可以参考这篇文章,在这篇文章中只是用训练集进行训练,没有用到验证集验证模型的指标,因此这篇文章中将会讨论如何增加验证集,并且使用tensorboard可视化训练集与验证集的指标参数。
以cascade_rcnn_hrnetv2p_w32_20e.py为例,原始的文件内容如下:
# model settingsmodel = dict( type='CascadeRCNN', num_stages=3, pretrained='open-mmlab://msra/hrnetv2_w32', backbone=dict( type='HRNet', extra=dict( stage1=dict( num_modules=1, num_branches=1, block='BOTTLENECK', num_blocks=(4, ), num_channels=(64, )), stage2=dict( num_modules=1, num_branches=2, block='BASIC', num_blocks=(4, 4), num_channels=(32, 64)), stage3=dict( num_modules=4, num_branches=3, block='BASIC', num_blocks=(4, 4, 4), num_channels=(32, 64, 128)), stage4=dict( num_modules=3, num_branches=4, block='BASIC', num_blocks=(4, 4, 4, 4), num_channels=(32, 64, 128, 256)))), neck=dict(type='HRFPN', in_channels=[32, 64, 128, 256], out_channels=256), rpn_head=dict( type='RPNHead', in_channels=256, feat_channels=256, anchor_scales=[8], anchor_ratios=[0.5, 1.0, 2.0], anchor_strides=[4, 8, 16, 32, 64], target_means=[.0, .0, .0, .0], target_stds=[1.0, 1.0, 1.0, 1.0], loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)), bbox_roi_extractor=dict( type='SingleRoIExtractor', roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2), out_channels=256, featmap_strides=[4, 8, 16, 32]), bbox_head=[ dict( type='SharedFCBBoxHead', num_fcs=2, in_channels=256, fc_out_channels=1024, roi_feat_size=7, num_classes=81, target_means=[0., 0., 0., 0.], target_stds=[0.1, 0.1, 0.2, 0.2], reg_class_agnostic=True, loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)), dict( type='SharedFCBBoxHead', num_fcs=2, in_channels=256, fc_out_channels=1024, roi_feat_size=7, num_classes=81, target_means=[0., 0., 0., 0.], target_stds=[0.05, 0.05, 0.1, 0.1], reg_class_agnostic=True, loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)), dict( type='SharedFCBBoxHead', num_fcs=2, in_channels=256, fc_out_channels=1024, roi_feat_size=7, num_classes=81, target_means=[0., 0., 0., 0.], target_stds=[0.033, 0.033, 0.067, 0.067], reg_class_agnostic=True, loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)), ])# model training and testing settingstrain_cfg = dict( rpn=dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.7, neg_iou_thr=0.3, min_pos_iou=0.3, ignore_iof_thr=-1), sampler=dict( type='RandomSampler', num=256, pos_fraction=0.5, neg_pos_ub=-1, add_gt_as_proposals=False), allowed_border=0, pos_weight=-1, debug=False), rpn_proposal=dict( nms_across_levels=False, nms_pre=2000, nms_post=2000, max_num=2000, nms_thr=0.7, min_bbox_size=0), rcnn=[ dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.5, neg_iou_thr=0.5, min_pos_iou=0.5, ignore_iof_thr=-1), sampler=dict( type='RandomSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False), dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.6, neg_iou_thr=0.6, min_pos_iou=0.6, ignore_iof_thr=-1), sampler=dict( type='RandomSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False), dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.7, neg_iou_thr=0.7, min_pos_iou=0.7, ignore_iof_thr=-1), sampler=dict( type='RandomSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False) ], stage_loss_weights=[1, 0.5, 0.25])test_cfg = dict( rpn=dict( nms_across_levels=False, nms_pre=1000, nms_post=1000, max_num=1000, nms_thr=0.7, min_bbox_size=0), rcnn=dict( score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100), keep_all_stages=False)# dataset settingsdataset_type = 'CocoDataset'data_root = 'data/coco/'img_norm_cfg = dict( mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)train_pipeline = [ dict(type='LoadImageFromFile'), dict(type='LoadAnnotations', with_bbox=True), dict(type='Resize', img_scale=(1333, 800), keep_ratio=True), dict(type='RandomFlip', flip_ratio=0.5), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),]test_pipeline = [ dict(type='LoadImageFromFile'), dict( type='MultiScaleFlipAug', img_scale=(1333, 800), flip=False, transforms=[ dict(type='Resize', keep_ratio=True), dict(type='RandomFlip'), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='ImageToTensor', keys=['img']), dict(type='Collect', keys=['img']), ])]data = dict( imgs_per_gpu=2, workers_per_gpu=2, train=dict( type=dataset_type, ann_file=data_root + 'annotations/instances_train2017.json', img_prefix=data_root + 'train2017/', pipeline=train_pipeline), val=dict( type=dataset_type, ann_file=data_root + 'annotations/instances_val2017.json', img_prefix=data_root + 'val2017/', pipeline=test_pipeline), test=dict( type=dataset_type, ann_file=data_root + 'annotations/instances_val2017.json', img_prefix=data_root + 'val2017/', pipeline=test_pipeline))# optimizeroptimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))# learning policylr_config = dict( policy='step', warmup='linear', warmup_iters=500, warmup_ratio=1.0 / 3, step=[16, 19])checkpoint_config = dict(interval=1)# yapf:disablelog_config = dict( interval=50, hooks=[ dict(type='TextLoggerHook'), # dict(type='TensorboardLoggerHook') ])# yapf:enable# runtime settingstotal_epochs = 20dist_params = dict(backend='nccl')log_level = 'INFO'work_dir = './work_dirs/cascade_rcnn_hrnetv2p_w32'load_from = Noneresume_from = Noneworkflow = [('train', 1)] 其中配置文件中的workflow参数的含义是工作流,比如workflow = [('train', 1), ('val', 1)]表示按照训练一个epoch,接着再进行一个epoch的验证的策略迭代训练,如果workflow = [('train', 1)]表示训练完一个epoch后接着进行下一个epoch的训练,期间不进行验证。因此,增加验证集需要配置workflow,比如我们期望训练完一个epoch后接着进行验证,从而可以评估当前模型在验证集上的效果,这样我们设置workflow = [('train', 1), ('val', 1)]。
仅仅修改了这里,训练完一个epoch接下来进行验证的时候会报如下错误:
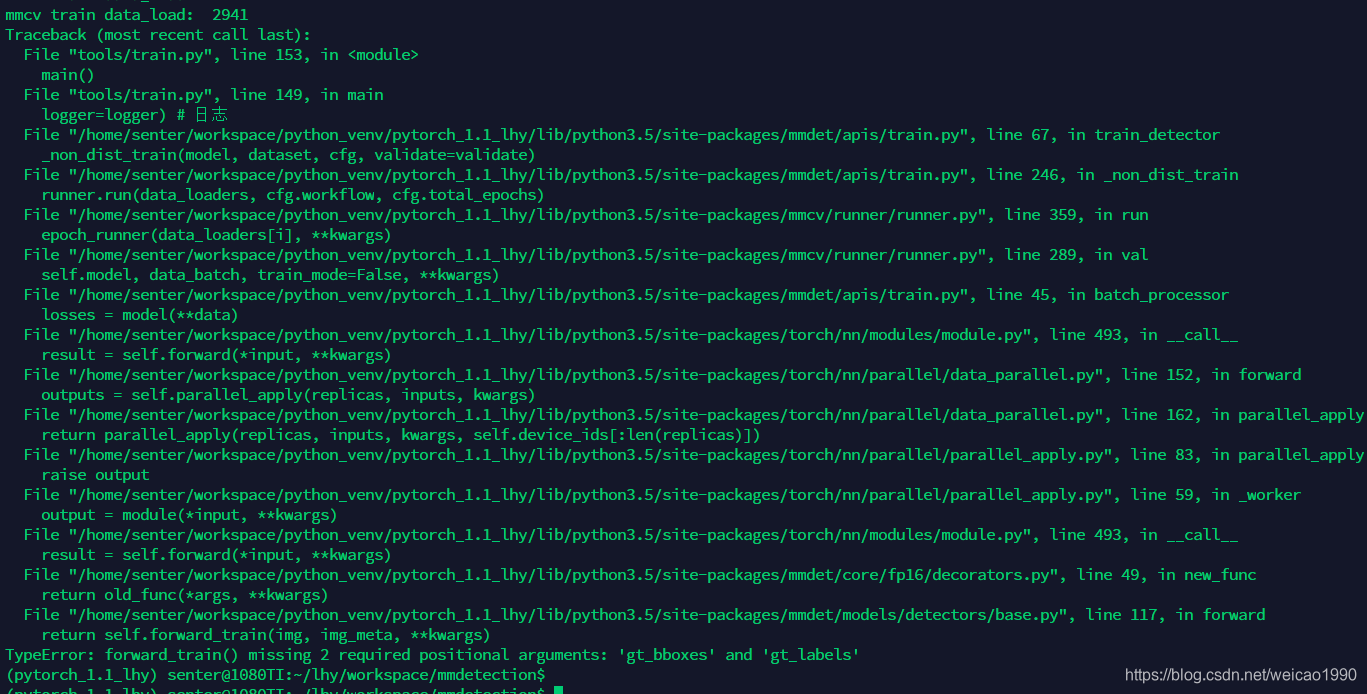
这是因为,还缺少验证集pipline的配置,默认配置文件中是没有val_pipeline的配置的,我们需要参考train_pipeline的内容添加val_pipeline,在cascade_rcnn_hrnetv2p_w32_20e.py中的train_pipeline与test_pipeline之间添加val_pipeline的内容:
val_pipeline = [ dict(type='LoadImageFromFile'), dict(type='LoadAnnotations', with_bbox=True), dict(type='Resize', img_scale=(1333, 800), keep_ratio=True), dict(type='RandomFlip', flip_ratio=0.5), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),]
可以看到val_pipeline的内容与train_pipline的内容是一样的。添加了val_pipeline后,还需要将cascade_rcnn_hrnetv2p_w32_20e.py中验证集的pipeline修改为刚才添加的val_pipeline,修改后如下:
data = dict( imgs_per_gpu=2, workers_per_gpu=2, train=dict( type=dataset_type, ann_file=data_root + 'annotations/instances_train2017.json', img_prefix=data_root + 'train2017/', pipeline=train_pipeline), val=dict( type=dataset_type, ann_file=data_root + 'annotations/instances_val2017.json', img_prefix=data_root + 'val2017/', pipeline=val_pipeline), test=dict( type=dataset_type, ann_file=data_root + 'annotations/instances_val2017.json', img_prefix=data_root + 'val2017/', pipeline=test_pipeline))
至此,验证集的添加工作就完成了。
接下来添加tensorboard的配置(要使用tensorboard进行可视化需要提前安装tensorboardx,执行sudo pip install tensorboardx即可安装),默认配置文件中是不开启tensorboard的配置的,只需要在log_config中的tensorboard注释取消即可,如下:
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])
至此,所有的配置已完成,修改后的完整的配置文件内容如下:
# model settingsmodel = dict( type='CascadeRCNN', num_stages=3, pretrained='open-mmlab://msra/hrnetv2_w32', backbone=dict( type='HRNet', extra=dict( stage1=dict( num_modules=1, num_branches=1, block='BOTTLENECK', num_blocks=(4, ), num_channels=(64, )), stage2=dict( num_modules=1, num_branches=2, block='BASIC', num_blocks=(4, 4), num_channels=(32, 64)), stage3=dict( num_modules=4, num_branches=3, block='BASIC', num_blocks=(4, 4, 4), num_channels=(32, 64, 128)), stage4=dict( num_modules=3, num_branches=4, block='BASIC', num_blocks=(4, 4, 4, 4), num_channels=(32, 64, 128, 256)))), neck=dict(type='HRFPN', in_channels=[32, 64, 128, 256], out_channels=256), rpn_head=dict( type='RPNHead', in_channels=256, feat_channels=256, anchor_scales=[8], anchor_ratios=[0.5, 1.0, 2.0], anchor_strides=[4, 8, 16, 32, 64], target_means=[.0, .0, .0, .0], target_stds=[1.0, 1.0, 1.0, 1.0], loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)), bbox_roi_extractor=dict( type='SingleRoIExtractor', roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2), out_channels=256, featmap_strides=[4, 8, 16, 32]), bbox_head=[ dict( type='SharedFCBBoxHead', num_fcs=2, in_channels=256, fc_out_channels=1024, roi_feat_size=7, num_classes=20, target_means=[0., 0., 0., 0.], target_stds=[0.1, 0.1, 0.2, 0.2], reg_class_agnostic=True, loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)), dict( type='SharedFCBBoxHead', num_fcs=2, in_channels=256, fc_out_channels=1024, roi_feat_size=7, num_classes=20, target_means=[0., 0., 0., 0.], target_stds=[0.05, 0.05, 0.1, 0.1], reg_class_agnostic=True, loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)), dict( type='SharedFCBBoxHead', num_fcs=2, in_channels=256, fc_out_channels=1024, roi_feat_size=7, num_classes=20, target_means=[0., 0., 0., 0.], target_stds=[0.033, 0.033, 0.067, 0.067], reg_class_agnostic=True, loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)), ])# model training and testing settingstrain_cfg = dict( rpn=dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.7, neg_iou_thr=0.3, min_pos_iou=0.3, ignore_iof_thr=-1), sampler=dict( type='RandomSampler', num=256, pos_fraction=0.5, neg_pos_ub=-1, add_gt_as_proposals=False), allowed_border=0, pos_weight=-1, debug=False), rpn_proposal=dict( nms_across_levels=False, nms_pre=2000, nms_post=2000, max_num=2000, nms_thr=0.7, min_bbox_size=0), rcnn=[ dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.5, neg_iou_thr=0.5, min_pos_iou=0.5, ignore_iof_thr=-1), sampler=dict( type='RandomSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False), dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.6, neg_iou_thr=0.6, min_pos_iou=0.6, ignore_iof_thr=-1), sampler=dict( type='RandomSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False), dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.7, neg_iou_thr=0.7, min_pos_iou=0.7, ignore_iof_thr=-1), sampler=dict( type='RandomSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False) ], stage_loss_weights=[1, 0.5, 0.25])test_cfg = dict( rpn=dict( nms_across_levels=False, nms_pre=1000, nms_post=1000, max_num=1000, nms_thr=0.7, min_bbox_size=0), rcnn=dict( score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100), keep_all_stages=False)# dataset settingsdataset_type = 'VOCDataset'data_root = 'data/VOCdevkit/'img_norm_cfg = dict( mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)train_pipeline = [ dict(type='LoadImageFromFile'), dict(type='LoadAnnotations', with_bbox=True), dict(type='Resize', img_scale=(1333, 800), keep_ratio=True), dict(type='RandomFlip', flip_ratio=0.5), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),]val_pipeline = [ dict(type='LoadImageFromFile'), dict(type='LoadAnnotations', with_bbox=True), dict(type='Resize', img_scale=(1333, 800), keep_ratio=True), dict(type='RandomFlip', flip_ratio=0.5), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),]test_pipeline = [ dict(type='LoadImageFromFile'), dict( type='MultiScaleFlipAug', img_scale=(1333, 800), flip=False, transforms=[ dict(type='Resize', keep_ratio=True), dict(type='RandomFlip'), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='ImageToTensor', keys=['img']), dict(type='Collect', keys=['img']), ])]data = dict( imgs_per_gpu=1, workers_per_gpu=8, train=dict( type=dataset_type, ann_file=data_root + 'VOC2007/ImageSets/Main/train.txt', img_prefix=data_root + 'VOC2007', pipeline=train_pipeline), val=dict( type=dataset_type, ann_file=data_root + 'VOC2007/ImageSets/Main/val.txt', img_prefix=data_root + 'VOC2007', pipeline=val_pipeline), test=dict( type=dataset_type, ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt', img_prefix=data_root + 'VOC2007', pipeline=test_pipeline))# optimizeroptimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001)optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))# learning policylr_config = dict( policy='step', warmup='linear', warmup_iters=500, warmup_ratio=1.0 / 3, step=[16, 19])checkpoint_config = dict(interval=1)# yapf:disablelog_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])# yapf:enable# runtime settingstotal_epochs = 20dist_params = dict(backend='nccl')log_level = 'INFO'work_dir = './work_dirs/cascade_rcnn_hrnetv2p_w32'load_from = Noneresume_from = Noneworkflow = [('train', 1), ('val', 1)] 开启tensorboard,执行如下命令:
tensorboard --logdir=work_dirs/cascade_rcnn_hrnetv2p_w32/
开启成功可以看到如下现象:

我们可以通过浏览器访问,便可以看到tensorboard的信息,但是通常我们训练是在服务器上进行的,可能不方便接显示器,无法通过服务器的浏览器对上述连接进行访问,因此需要端口转发将服务器上的6006端口转发到其它便于访问的主机上,一种简单的方式是通过ssh实现端口转发,在PC上开启命令行模式输入如下指令:
ssh -p 50000 -L 16006:127.0.0.1:6006 lhy@192.168.3.11
接下来,在PC的浏览器上输入如下链接:
http://127.0.0.1:16006/
如果一切正常,可以看到tensorboard的界面了:
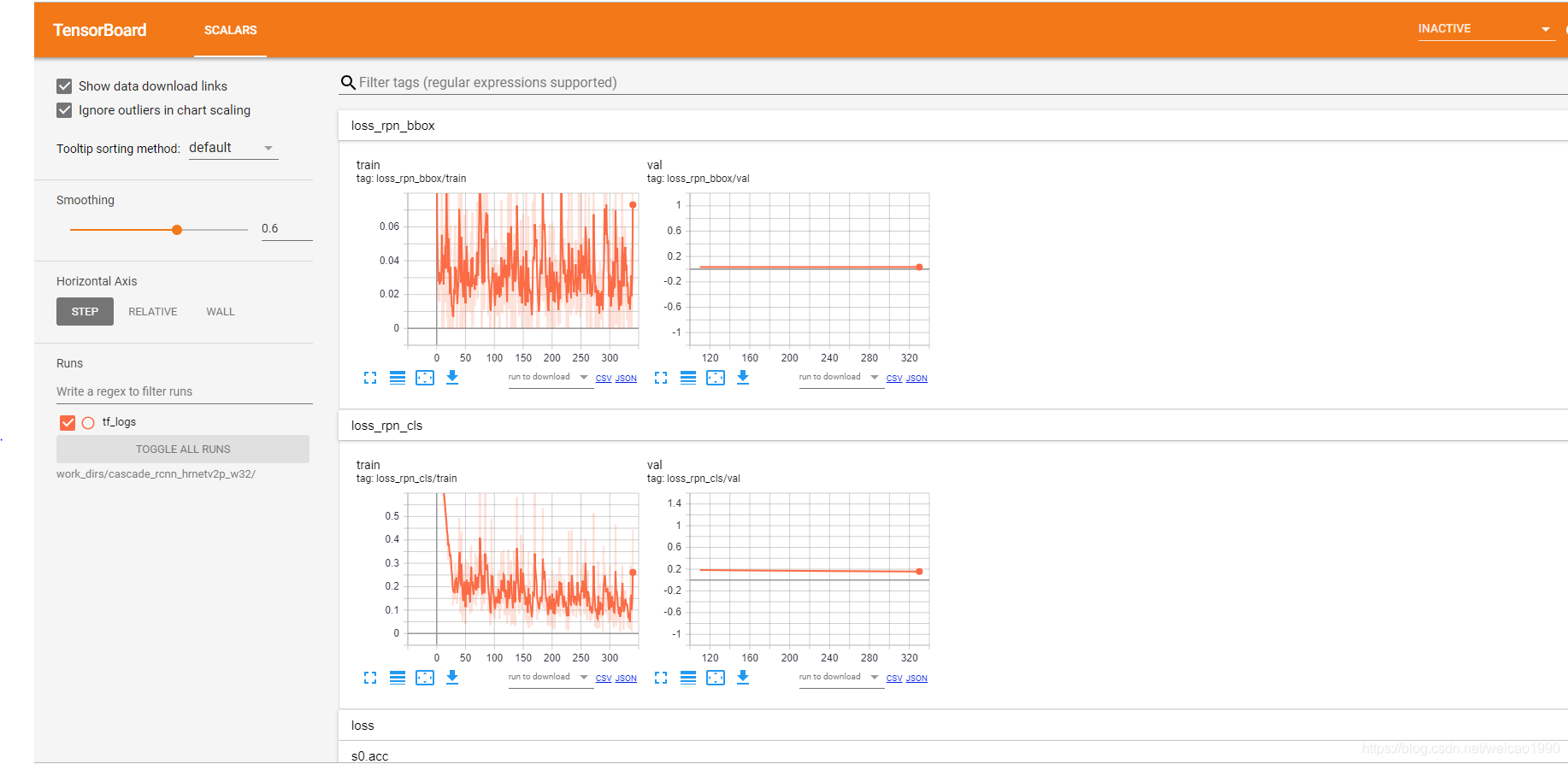
左边一栏是训练集的指标,右边是验证集的指标。
另外,mmdetection会自动收集log信息,存储在work_dirs/cascade_rcnn_hrnetv2p_w32目录下,官方提供了tools/analyze_logs.py工具可以轻松的可视化日志信息,如可视化损失值并保存为pdf文件,执行如下命令:
python tools/analyze_logs.py plot_curve work_dirs/cascade_rcnn_hrnetv2p_w32/20191130_125701.log.json --keys loss --out losses.pdf
结果图:
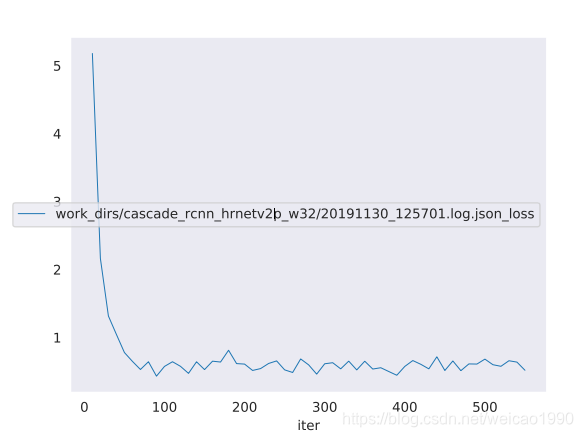
疑惑:在添加验证集训练时,只看到训练集的日志信息,看不到验证集的日志信息,mmdetection的日志存储目录下也只有训练集的日志信息没有验证集的日志信息,有哪位知悉原因望指教。
转载地址:https://blog.csdn.net/weicao1990/article/details/103324218 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
