本文共 3170 字,大约阅读时间需要 10 分钟。
Record Lock
行锁,总是会去锁住索引记录,如果InnoDB存储引擎表在建立的时候没有设置任何一个索引,那么这时InnoDB存储引擎会使用隐式的主键来进行锁定
Gap Lock
间隙锁,锁定一个范围,但不包含记录本身(⚠️注意间隙锁只会存在隔离级别REPEATABLE-READ),如下表中,当锁定id=3,Gap Lock会锁定(1,3),(3,5);
| id | a | b |
|---|---|---|
| 1 | 2 | a |
| 3 | 4 | b |
| 5 | 6 | c |
| 7 | 8 | d |
Next-Key Lock
临键锁,即Gap Lock+Record Lock,锁定一个范围,并且锁定记录本身;它是InnoDB默认隔离级别的锁算法,其设计的目的是为了解决Phantom Problem(幻读)。根据上面的表数据可以得出,其锁定的范围有(负无穷,1],(1,3],(3,5],(5,7],(7,正无穷],如果插入id为10,他锁定范围会变成(负无穷,1],(1,3],(3,5],(5,7],(7,10],(10,正无穷]。
这里有个误区,当锁定a=4时,锁定范围是不是(2,4],(4,6]呢?其实不然,其锁定范围为(2,4),4,(4,6),这些锁定范围((负无穷,1],(1,3],(3,5],(5,7],(7,正无穷])是整张表的锁定范围,具体锁定;
当查询的索引是唯一索引时,InnoDB存储引擎会对Next-Key Lock进行优化,将其降级为Record Lock,即仅锁定索引本身,而不是锁定范围了。
当索引是唯一索引的情况下:
条件:
-
t表数据有a = 1,2,5
-
a是唯一索引
-
隔离级别为:REPEATABLE-READ
骚操作
| 时间节点 | session1 | session2 |
|---|---|---|
| 1 | begin; | |
| 2 | select * from t where a = 5 for update; | |
| 3 | begin; | |
| 4 | insert into t (a) values(4);//不会阻塞 | |
| 5 | commit; | |
| commit; |
解释:
在session1中首先会a=5加X锁,而且由于a是主键且唯一,因此锁定的只有5这个值,而不是(2,5]这个范围;在session2中插入值4,是可以成功插入的,即锁定由Next-Key Lock算法降级为了Record Lock,从而提高应用的并发性。
当索引是辅助索引的情况下:
创建表:
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_a` (`a`)) ENGINE=InnoDB -- id为主键-- a为辅助索引insert into t(a,b) values(1,1);insert into t(a,b) values(3,1);insert into t(a,b) values(5,1);insert into t(a,b) values(7,1);insert into t(a,b) values(9,1);insert into t(a,b) values(11,1);
骚操作:
| 时间 | session1 | session2 |
|---|---|---|
| 1 | begin; | |
| 2 | select * from t where a = 5 for update; | |
| 3 | begin; | |
| 4 | insert into t(a,b) values (2,1);//不阻塞🙅♂️ | |
| 5 | insert into t(a,b) values (10,1);//不阻塞🙅♀️ | |
| 6 | insert into t(a,b) values (4,1);//阻塞 | |
| 7 | insert into t(a,b) values(6,1);//阻塞 | |
| 8 | insert into t(a,b) values(5,1);//阻塞 | |
| 9 | commit; | |
| 10 | commit; |
解释:
Next-Key Lock锁算法中,我们知道它是Gap Lock+Record Lock组成的,根据上表可以知,当锁定a = 5时,其锁算法会锁定哪些数据呢?他会锁定5,(3,5),(5,7)这些数据;所以插入a=4、a=5和a=6数据都会被阻塞,大家最好自己试一下,但是要注意隔离级别是RR(REPEATABLE-READ)哦!
思考🤔:如果我插入a=3和a=7,大家猜猜会不会阻塞呢?
一顿操作猛如虎,直接试一试:
| 时间 | session1 | session2 |
|---|---|---|
| 1 | begin; | |
| 2 | select * from t where a = 5 for update; | |
| 3 | begin; | |
| 4 | insert into t(a,b) values (3,1);//阻塞 | |
| 5 | insert into t(a,b) values (7,1);//不阻塞🙅♀️ | |
| 6 | commit; | |
| 7 | commit; |
震惊!!!
上面不是说如果锁定a=5,就会锁定5,(3,5),(5,7)这些数据吗?那为什么插入a=3时,会阻塞呢
因为因为因为~
首先,你要先了解一下普通索引是根据索引字段排序,还是根据主键排序的?了解清楚了,就知道为什么了?
来证明以上问题:
可以肯定的跟你说普通索引中叶子节点他是以主键id进行排序的.InnoDB的普通索引树B+tree中的叶子节点,大概是这样的存储方式:
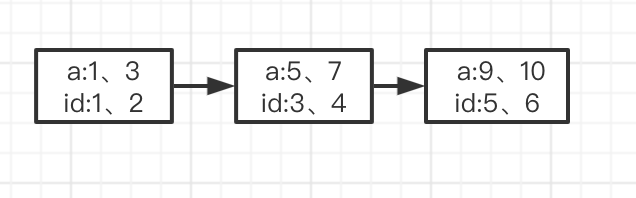
如果他插入数据为a=3,id是自增长的主键,所以id为7,他的叶子节点数据变成:
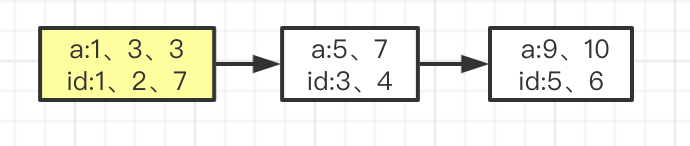
所以,从这个图可以引申出另外一个面试题,什么样的字段创建索引会更合理?当然是数据不重复最好,因为重复的数据会导致B+tree裂变,影响性能。
小结:根据普通索引的B+tree的叶子节点的数据存储情况,可以得出,当锁定a=5时,会导致a=3也会被锁住,这里有人可能心里会个想法,那我主键搞成不是有序的,保存UUID为主键,不好意思,这种我也试过了,你使用UUID这种无序的字段作为主键索引,InnoDB储存引擎会默认给你创建一个隐式ID,用于数据的排序。
使用UUID作为主键:
CREATE TABLE `t` ( `id` varchar(50) NOT NULL, `a` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_a` (`a`)) ENGINE=InnoDB -- id为主键-- a为辅助索引insert into t(id,a) values('aadfas',1);insert into t(id,a) values('badfdas',3);insert into t(id,a) values('adfdsac',5);insert into t(id,a) values('rted',7);insert into t(id,a) values('twertwere',9);insert into t(id,a) values('rwetrewtref',11); 事务操作过程:
| 时间 | session1 | session2 |
|---|---|---|
| 1 | begin; | |
| 2 | select * from t where a = 5 for update; | |
| 3 | begin; | |
| 4 | insert into t(id,a) values(‘rtoooooed’,3);//阻塞 | |
| 5 | commit; | |
| 6 | commit; |
如果文章存在问题,或者有疑惑麻烦给我留言,大家一起学习,感谢您~
欢迎关注我的微信公众号,里面有很多干货,各种面试题
发表评论
最新留言
关于作者
