自己启动spark集群的实验记录
发布日期:2021-05-06 21:48:11
浏览次数:17
分类:精选文章
本文共 222 字,大约阅读时间需要 1 分钟。
第一步、将master和slave电脑重启
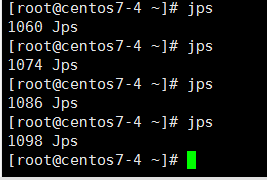
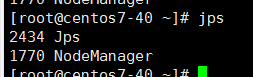
第二、查看jps命令,结果如下:
master
slave
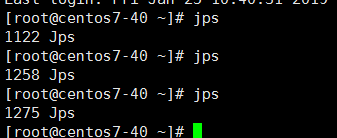
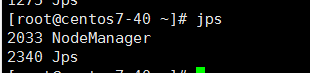
第三、启动hadoop集群,准确的使用目录./等来保证执行的命令为hadoop目录 下的start-all.sh
主机:

slave
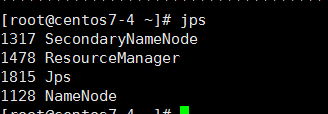
第四、hadoop namenode -format
master
slave
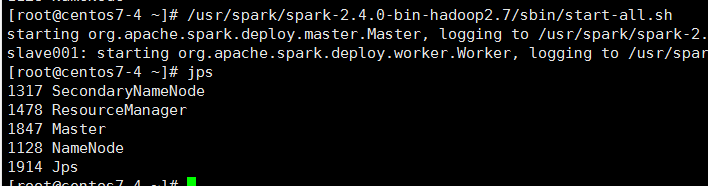
第五步、启动spark,命令如下:
![]()
master
slave
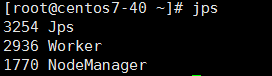
master上面多了master;slave上面多少worker
发表评论
最新留言
初次前来,多多关照!
[***.217.46.12]2025年03月29日 15时42分24秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
高德算法工程一体化实践和思考
2019-03-06
为亿级用户的美好出行而战!高德地图首届算法大赛落幕 95后北邮在读博士带队夺冠
2019-03-06
重温网络编程——常识(三)
2019-03-06
判断一个数是否是2的幂
2019-03-06
js 闭包(新)
2019-03-06
vscode 编辑python 如何格式化
2019-03-06
正则表达针对html(九)
2019-03-06
seo 回忆录百度基本概念(一)
2019-03-06
重新整理数据结构与算法(c#)—— 算法套路二分法[二十四]
2019-03-06
重学c#系列——异常续[异常注意事项](七)
2019-03-06
不一样的备忘录模式(设计模式十六)
2019-03-06
【golang-GUI开发】qt之signal和slot(一)
2019-03-06
Markdown使用笔记
2019-03-06
「从零单排HBase 06」你必须知道的HBase最佳实践
2019-03-06
跟面试官侃半小时MySQL事务,说完原子性、一致性、持久性的实现
2019-03-06
「从零单排canal 04」 启动模块deployer源码解析
2019-03-06
用ThreadLocal来优化下代码吧
2019-03-06
netcore中使用session
2019-03-06
js 写日期选择器
2019-03-06
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 457512189 位访客
访问时间: 2025-04-18 05:08:48
访问IP: 18.118.193.52
Copyright © 2020 - 2025 css8.cn 京ICP备2021015314号-1
手机版