本文共 2366 字,大约阅读时间需要 7 分钟。
1.简介
凸优化中一阶逼近的梯度下降法、二阶逼近的牛顿法在某点使用时都需要使用这个点对应的一阶二阶导数来进行逼近或判别。
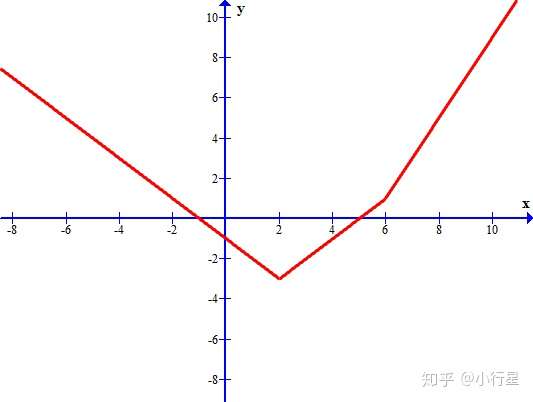
而某些优化问题的目标函数在某些点是不可导的,如下图在x=2,6处均不可导,若选择x=8为初始点使用梯度下降来做,则当点走到x=6(运气好也可能跳过去)函数不可导,无法做一阶逼近,方法也就无法进行下去。
解决方法也很简单直观,选择[1,2]之间的一个数作为梯度方向,1,2分别是两条折线的方向。[1,2]的数称为这个点的次梯度。
==================================================
2.次梯度
[1]次梯度的定义

一阶逼近时可导的点的支撑超平面只有一个即这个点的切面,切面对应的梯度称为这个点的梯度;而不可导的点可能有很多支撑超平面,每个支撑超平面对应一个梯度,这些梯度的集合为这个点的次梯度。
[2]次梯度的三个性质

[3]负次梯度方向不一定是下降方向

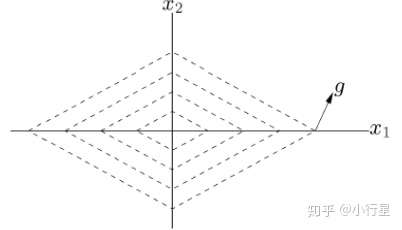
虚线为登高线
==================================================
3.几种情况求次梯度
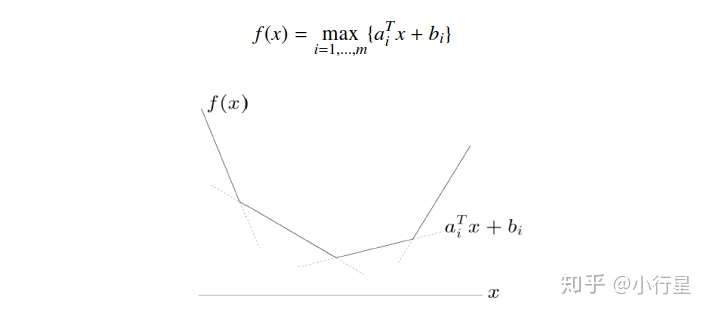
[1]逐点最大函数(Pointwise Maximum)

所以求次梯度实际是先求支撑平面,再求所有支撑平面的梯度的凸包。而对于可导的情况实际是不可导的一种特殊情况。
(1)分段函数

(2)l_1范数函数


[2]逐点上确界(Pointwise Supremum)
例子是和矩阵特征值相关。

例子:
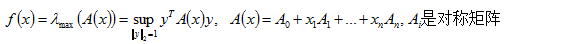
解释问题,

求次梯度,

[3]下确界
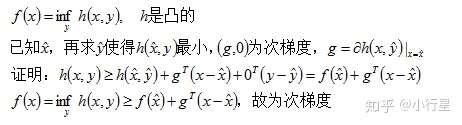
例子,

总之逐次的最大或最小求次梯度,先得到这个点的最大或最小函数,再按这个最大或最小函数求梯度即为次梯度。
[4]复合函数
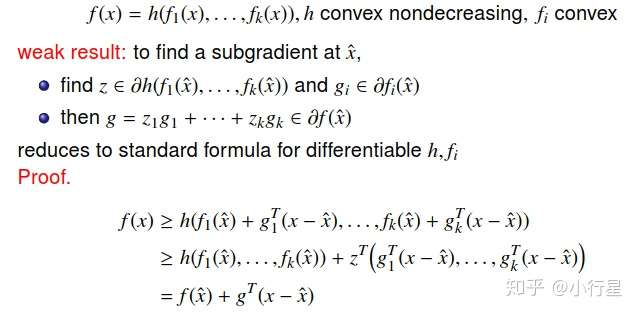
==================================================
4.最优化条件
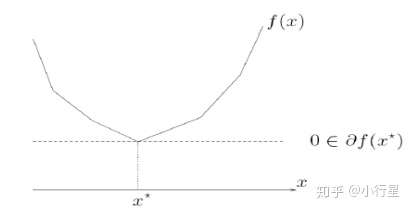
因为目标函数没有梯度,最优化条件也就不能用梯度为0
[1]无约束优化

[2]有约束优化
==================================================
5.例子+分析+编程
问题:
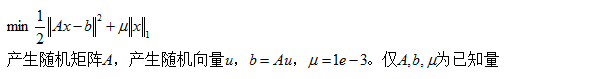
在其它的场景中,上式就类似于一个损失函数,而x则是参数
分析:
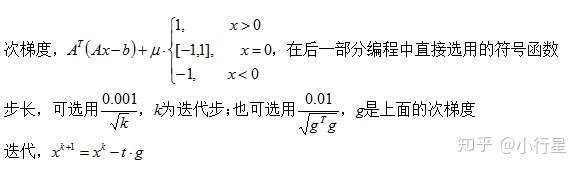
编程(用的python):
# -*- coding: utf-8 -*-import numpy as npimport scipy as spyfrom scipy.sparse import csc_matriximport matplotlib.pyplot as pltimport time #用来计算运行时间#=======模拟数据======================m = 512n = 1024#稀疏矩阵的产生,A使用的是正态稀疏矩阵u= spy.sparse.rand(n,1,density=0.1,format='csc',dtype=None)u1 = u.nonzero()row = u1[0]col = u1[1]data = np.random.randn(int(0.1*n))u = csc_matrix((data, (row, col)), shape=(n,1)).toarray() #u1 = u.nonzero() #观察是否是正态分布#plt.hist(u[u1[0],u1[1]].tolist())#u = u.todense() #转为非稀疏形式a = np.random.randn(m,n)b = np.dot(a,u)v = 1e-3 #v为题目里面的miudef f(x0): #目标函数 return 1/2*np.dot((np.dot(a,x0)-b).T,np.dot(a,x0)-b)+v*sum(abs(x0))#==========初始值=============================x0 = np.zeros((n,1))y = []time1 = []start = time.clock()#=========开始迭代==========================for i in range(1000): y.append(f(x0)[0,0]) #存放每次的迭代函数值 g0 = (np.dot(np.dot(a.T,a),x0)-np.dot(a.T,b) + v*np.sign(x0)) #次梯度 t = 0.01/np.sqrt(sum(np.dot(g0.T,g0))) #设为0.01效果比0.1好很多,步长 x1 = x0 - t[0]*g0 x0 = x1 end = time.clock() time1.append(end)y = np.array(y).reshape((1000,1)) time1 = np.array(time1)time1 = time1 - starttime2 = time1[np.where(y - y[999] < 10e-4)[0][0]]plt.plot(y) # if i % 100 == 0: # f = 1/2*np.dot((np.dot(a,x0)-b).T,np.dot(a,x0)-b)+v*sum(abs(x0))# print(f) #在计算机计算时,可以明显感受到proximal gradient方法比次梯度方法快
目标函数的值变化:
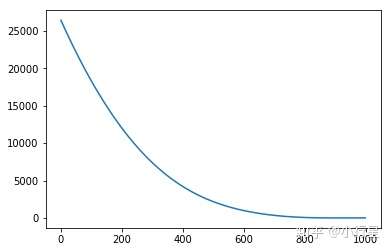
我们的目的是最小化目标函数的值,从上图可以看出函数下降的过程
发表评论
最新留言
关于作者
