大数据学习之Spark——06RDD持久化(控制算子)
发布日期:2021-05-06 17:19:32
浏览次数:48
分类:精选文章
本文共 3381 字,大约阅读时间需要 11 分钟。
1.控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化,持久化的单位是partition。
2. cache和persist都是懒执行的。必须有一个action类算子触发执行。 3. checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
一. RDD缓存
1. 说明
- RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM 的堆空间中。
- 但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
- 通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。

2. cache
默认将RDD的数据持久化到内存中。cache是懒执行。
- 代码
var line: RDD[String] = sc.textFile("./data/pvuvdata")line = line.cache()val start1: Long = System.currentTimeMillis()val count1: Long = line.count()val end1: Long = System.currentTimeMillis()System.out.println("共" + count1 + "条数据," + "初始化时间+cache时间+计算时间=" + (end1 - start1))val start2: Long = System.currentTimeMillis()val count2: Long = line.count()val end2: Long = System.currentTimeMillis()System.out.println("共" + count2 + "条数据," + "初始化时间+cache时间+计算时间=" + (end2 - start2)) - 结果
 不加缓存:
不加缓存: line = line.cache()
3. persist
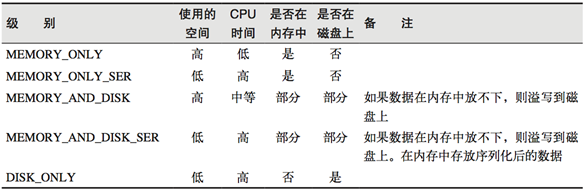
和cache可以指定持久化的级别。
-
持久化级别如下:

-
说明
-
代码
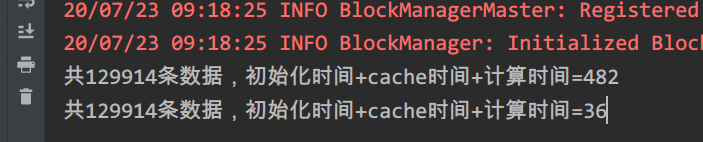
var line: RDD[String] = sc.textFile("./data/pvuvdata")// chche () = persist()=persist(StorageLevel.Memory_Only)line = line.persist(StorageLevel.MEMORY_ONLY)val start1: Long = System.currentTimeMillis()val count1: Long = line.count()val end1: Long = System.currentTimeMillis()System.out.println("共" + count1 + "条数据," + "初始化时间+cache时间+计算时间=" + (end1 - start1))val start2: Long = System.currentTimeMillis()val count2: Long = line.count()val end2: Long = System.currentTimeMillis()System.out.println("共" + count2 + "条数据," + "初始化时间+cache时间+计算时间=" + (end2 - start2)) -
运行结果
 如果不加:
如果不加: line = line.persist(StorageLevel.MEMORY_ONLY)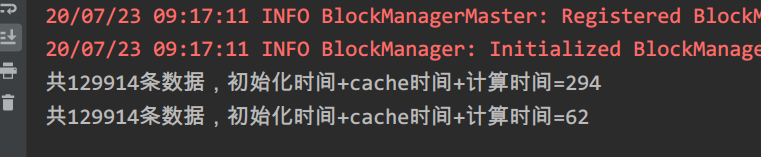
4. cache和persist的注意事项
- cache和persist都是懒执行,必须有一个action类算子触发执行。
- cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition。
- cache和persist算子后不能立即紧跟action算子。 错误:rdd.cache().count() 返回的不是持久化的RDD,而是一个数值了。
- cache和persist算子持久化的数据当applilcation执行完成之后会被清除。
二.CheckPoint
checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系。checkpoint目录数据当application执行完之后不会被清除
1. 执行原理
- 当RDD的job执行完毕后,会从finalRDD从后往前回溯。
- 当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
- Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。
2. 执行过程
- 为当前RDD设置CheckPoint:
SparkContext.setCheckpointDir()该函数将会创建一个二进制的文件,并存储到checkpoint目录中 - 在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移除。
- 对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
3. 案例
-
代码
package com.hjf.coreimport org.apache.spark.rdd.RDDimport org.apache.spark.{ SparkConf, SparkContext}object TestCheckPoint { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf() conf.setMaster("local").setAppName("cache") val sc: SparkContext = new SparkContext(conf) // 指定CheckPoint目录 sc.setCheckpointDir("hdfs://node01:8020/checkpoint/cp2") sc.setLogLevel("Error") var line: RDD[String] = sc.textFile("./data/pvuvdata") // 执行CheckPoint line.checkpoint() val start1: Long = System.currentTimeMillis() val count1: Long = line.count() val end1: Long = System.currentTimeMillis() System.out.println("共" + count1 + "条数据," + "初始化时间+cache时间+计算时间=" + (end1 - start1)) val start2: Long = System.currentTimeMillis() val count2: Long = line.count() val end2: Long = System.currentTimeMillis() System.out.println("共" + count2 + "条数据," + "初始化时间+cache时间+计算时间=" + (end2 - start2)) sc.stop() }} -
运行结果


4. 优化
- 对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以,省去了重新计算这一步。
声明
- 本文参考了尚硅谷Spark课程的课件
- 本文参考了尚学堂Spark课程的课件
发表评论
最新留言
逛到本站,mark一下
[***.202.152.39]2025年04月04日 07时37分05秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Javascript之旅——第十一站:原型也不好理解?
2021-05-09
Sql Server之旅——第十站 看看DML操作对索引的影响
2021-05-09
十五天精通WCF——第二天 告别烦恼的config配置
2021-05-09
双十一来了,别让你的mongodb宕机了
2021-05-09
asp.net mvc 之旅 —— 第六站 ActionFilter的应用及源码分析
2021-05-09
Tomcat 热部署
2021-05-09
深入解析 HTTP 缓存控制
2021-05-09
深入浅出访问者模式
2021-05-09
深入探索Android热修复技术原理读书笔记 —— 热修复技术介绍
2021-05-09
百度前端技术学院task16源代码
2021-05-09
解析js中( ( ) { } ( ) )的含义
2021-05-09
js设计模式总结5
2021-05-09
Python大神编程常用4大工具,你用过几个?
2021-05-09
一文带你了解图神经网络
2021-05-09
9个常用ES6特性归纳(一般用这些就够了)
2021-05-09
3D渲染集群,你了解多少?
2021-05-09
除了方文山,用TA你也能帮周杰伦写歌词了
2021-05-09
关于GO语言,这篇文章讲的很明白
2021-05-09
华为云FusionInsight湖仓一体解决方案的前世今生
2021-05-09
大数据处理黑科技:揭秘PB级数仓GaussDB(DWS) 并行计算技术
2021-05-09
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 459581497 位访客