本文共 2498 字,大约阅读时间需要 8 分钟。
Time Series Shapelets:A New Primitive for Data Mining
本篇论文发表于2009年,首次提出了shapelets这一概念。
摘要
shapelets是时间序列的一个子序列,可以称作最大区分子序列。这里的最大指的是这个子序列的区分能力最大。常用的近邻算法是一种全局性的方法,因为它需要用到全部的数据集,而shapelets属于一种局部模式,它使用具有区分能力的子序列来进行分类与聚类。它有两个优点:(1)局部模式;(2)具有很强的可解释性。
1、引言
近邻算法有两个弱点(1)时间空间开销大;(2)可解释性差,具体来说就是不能告诉我们为什么一个特定的对象被分配给一个特定的类。shapelets可以减轻这两个弱点。
论文中举了一个形象的例子来让读者直观的感受一下什么是shapelets。 上图中第一排树叶是荨麻草,第二排树叶是马鞭草也叫“假荨麻”,有些叶子被昆虫咬伤,这两种植物的叶子非常相似。现在要用一个分类器来区分这两种植物。那么应该选用什么特征?因为叶子的大小的颜色几乎是相同的,最好的选择就是基于叶子的形状。但是叶子整体上的形状差异是比较小的,而且由于昆虫咬伤以及其他变形会混淆任何基于全局形状的测量。尝试使用“局部形状”是一个比较好的想法。
上图中第一排树叶是荨麻草,第二排树叶是马鞭草也叫“假荨麻”,有些叶子被昆虫咬伤,这两种植物的叶子非常相似。现在要用一个分类器来区分这两种植物。那么应该选用什么特征?因为叶子的大小的颜色几乎是相同的,最好的选择就是基于叶子的形状。但是叶子整体上的形状差异是比较小的,而且由于昆虫咬伤以及其他变形会混淆任何基于全局形状的测量。尝试使用“局部形状”是一个比较好的想法。 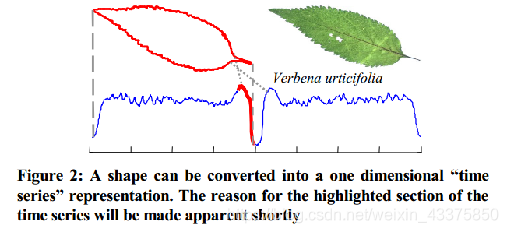 如图,形状可以转化为一维的时间序列表示。这种转化后的时间序列可以用来分类、聚类等一系列数据挖掘任务。但是直接使用全部数据的欧式距离或DTW距离的近邻分类器效果并没有明显优于随机猜测(基本上没分出来)。原因就是数据中的噪声(比如本例中的昆虫咬伤)足以掩盖掉形状上的细微差异。但是可以不比较全部的数据,之比较数据中有差异的一小部分,这一个“小部分”便是本文提出的shapelets,体现在上图中就是红色的那一段子序列。
如图,形状可以转化为一维的时间序列表示。这种转化后的时间序列可以用来分类、聚类等一系列数据挖掘任务。但是直接使用全部数据的欧式距离或DTW距离的近邻分类器效果并没有明显优于随机猜测(基本上没分出来)。原因就是数据中的噪声(比如本例中的昆虫咬伤)足以掩盖掉形状上的细微差异。但是可以不比较全部的数据,之比较数据中有差异的一小部分,这一个“小部分”便是本文提出的shapelets,体现在上图中就是红色的那一段子序列。 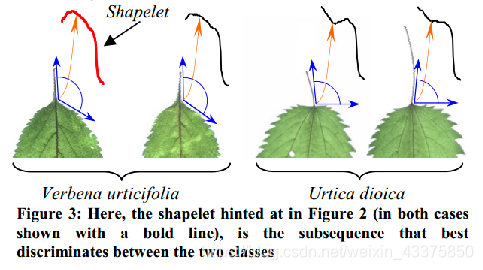 如图上图所示,通过找到的“两个类之间最好的区分子序列”,即shapelets,我们可以发现,两个物种之间最大的区别在于茎与叶子的连接角度,荨麻草大约为90度,假荨麻要比90度大得多(这里可以体现shapelets的可解释性)。找到shapelets并且计算它到数据集中所有实例最近匹配的距离后,就可以构建一个简单的决策树分类器。
如图上图所示,通过找到的“两个类之间最好的区分子序列”,即shapelets,我们可以发现,两个物种之间最大的区别在于茎与叶子的连接角度,荨麻草大约为90度,假荨麻要比90度大得多(这里可以体现shapelets的可解释性)。找到shapelets并且计算它到数据集中所有实例最近匹配的距离后,就可以构建一个简单的决策树分类器。 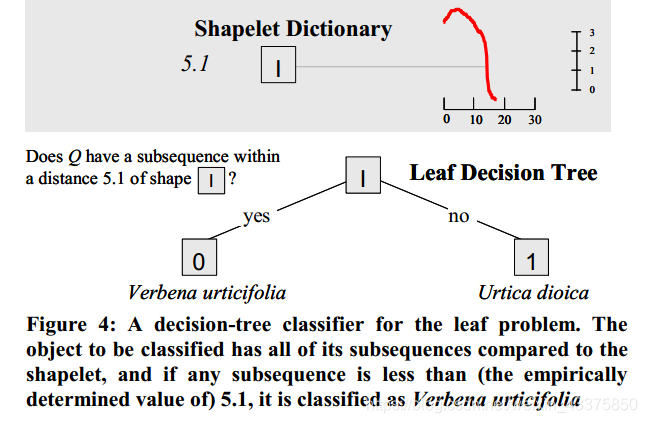 如上图所示,红色的那条线是提取出来的shapelets,分类过程就是计算数据集中每个实例到shapelets的距离,如果距离小于5.1它就被分为马鞭草,否则就是荨麻草。那么问题来了,分类阈值5.1哪来的?后面会讲这个问题,目前先放一放。
如上图所示,红色的那条线是提取出来的shapelets,分类过程就是计算数据集中每个实例到shapelets的距离,如果距离小于5.1它就被分为马鞭草,否则就是荨麻草。那么问题来了,分类阈值5.1哪来的?后面会讲这个问题,目前先放一放。 到目前为止读者会发现这种分类方法潜在的优点:
(1)shapelets能够提供可解释的结果,帮助分析人员更好的理解数据。这是其他机器学习和时序分类算法办不到的。 (2)shapelets有更强的鲁棒性/准确性。因为它是一种“局部特征”,比起那些“全局特征”的分类算法,它的抗噪能力更强。 (3)shapelets比现有的分类方法更快。2、相关工作和背景
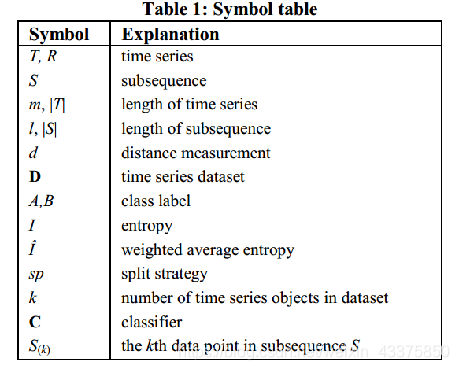
符号表
定义1:时间序列
m个实值的有序集。
定义2:子序列
定义3:滑动窗口
定义4:时间序列之间的距离
使用某种距离计算方法返回两个长度相同的序列之间的距离,比如使用欧氏距离或DTW。
定义5:时间序列和子序列之间的距离
所有长度和待测子序列一致的子序列中距离最小的那一个。
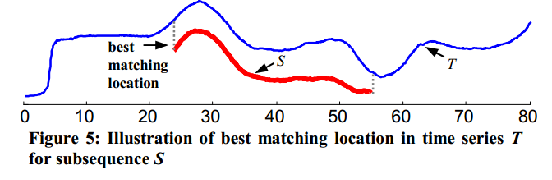 如图中,现在原序列中匹配到和子序列最佳的位置,再计算距离。
如图中,现在原序列中匹配到和子序列最佳的位置,再计算距离。 定义6:信息熵
定义7:信息增益
定义8:最佳分裂点
这个地方就是前面提到分裂阈值如何取的问题。就是在这个阈值处进行划分所获得的信息增益要大于任何其他点,这个阈值(距离值)就是最佳分裂点。所以说使用shapelets时包括两个步骤,寻找shapelets和相应的最佳分裂点。
定义9:shapelets
在shapelets和它对应的最佳分裂点处产生的信息增益要大于任何其他子序列和其他分裂点的信息增益。说白了shapelets就是一个具有区分能力的子序列和一个最佳的分裂阈值,拿这一组东西去分类会产生最佳效果(最大信息增益)。下文会介绍如何寻找shapelets和对应的最佳分裂点,以及如何构造一颗决策树。
3、蛮力法寻找shapelets
最简单的方法就是使用蛮力算法进行寻找,但这种方法在实际中并不可行,时间复杂度太高了,必须配合相应的加速技术。这里只是为了介绍它的算法思想。
 算法程序入上图: 给定一个数据集D,给定shapelets的最大和最小长度,最小长度可以为1,最大长度为数据集D中长度最小的序列对应的长度。数据集D中每个序列对应一个类别A或B。第一行生成了所有子序列的候选集,存储在一个列表中。具体做法其实是使用MAXLEN和MINLEN之间所有长度的滑动窗口去截数据集中所有的序列,相当于子序列的一个全集。第二行将最大信息增益bsf_fain赋值为0;接下来3到7行,使用候选集candidates中的每个子序列去分类,寻找分类效果最好的那一个,也就是信息增益最大的那一个便是shapelets。最佳分裂点的选择具体如下图:
算法程序入上图: 给定一个数据集D,给定shapelets的最大和最小长度,最小长度可以为1,最大长度为数据集D中长度最小的序列对应的长度。数据集D中每个序列对应一个类别A或B。第一行生成了所有子序列的候选集,存储在一个列表中。具体做法其实是使用MAXLEN和MINLEN之间所有长度的滑动窗口去截数据集中所有的序列,相当于子序列的一个全集。第二行将最大信息增益bsf_fain赋值为0;接下来3到7行,使用候选集candidates中的每个子序列去分类,寻找分类效果最好的那一个,也就是信息增益最大的那一个便是shapelets。最佳分裂点的选择具体如下图: 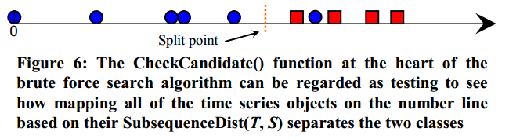 假设现在在候选集canditates中拿出一个子序列s,然后将s和数据集D中所有序列的距离计算出来然后排序。如上图中数轴所示,数轴上值代表候选序列和数据集D中序列的距离,蓝色圆形和红色正方形代表两个不同类别,红色虚线箭头所指地方就是最佳分裂点,寻找它的过程是从左到右每相邻两个点之间的均值作为分裂点都计算信息增益,选最大的那个。
假设现在在候选集canditates中拿出一个子序列s,然后将s和数据集D中所有序列的距离计算出来然后排序。如上图中数轴所示,数轴上值代表候选序列和数据集D中序列的距离,蓝色圆形和红色正方形代表两个不同类别,红色虚线箭头所指地方就是最佳分裂点,寻找它的过程是从左到右每相邻两个点之间的均值作为分裂点都计算信息增益,选最大的那个。  上图是生成候选集的过程,就是上面讲过的用户滑动窗口截就行了。
上图是生成候选集的过程,就是上面讲过的用户滑动窗口截就行了。  上图是计算每个候选集的信息增益。第一行是寻找最佳分裂点,然后数据集中距离小于阈值的分到D1集合,大于的分到D2集合,分完后计算增益返回。 寻找一个shapelets的蛮力方法就是这样,可以看到复杂度是相当高的。
上图是计算每个候选集的信息增益。第一行是寻找最佳分裂点,然后数据集中距离小于阈值的分到D1集合,大于的分到D2集合,分完后计算增益返回。 寻找一个shapelets的蛮力方法就是这样,可以看到复杂度是相当高的。 4、子序列距离早弃
在寻找shapelets中大多数计算量集中在计算子序列和序列的距离上。我们需要的是子序列之间的最小距离而不是所有距离,因此一直当前是最小距离时就可以停止计算。这个方法叫早弃,非常简单但十分有效。
后面部分以后再更新转载地址:https://blog.csdn.net/weixin_43375850/article/details/100580560 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
