python爬虫框架feapder的使用简介
 feapder的介绍和环境安装就完成了,下面开始真正去使用fepader来爬取网站,并存储到mysql数据库。
feapder的介绍和环境安装就完成了,下面开始真正去使用fepader来爬取网站,并存储到mysql数据库。 

 chromedriver.exe 只是一个模拟浏览器驱动,不用管。 6、存储到数据库 在 target_spider.py 中引入刚刚的 booklist_item.py,并创建对象BooklistItem。把爬取的数据表中的字段名初始化到对象中。最后yieId list_item,实际上就直接存储到数据库了(因为数据库表和item是对应连接关系,这样就直接存储到数据库了)。
chromedriver.exe 只是一个模拟浏览器驱动,不用管。 6、存储到数据库 在 target_spider.py 中引入刚刚的 booklist_item.py,并创建对象BooklistItem。把爬取的数据表中的字段名初始化到对象中。最后yieId list_item,实际上就直接存储到数据库了(因为数据库表和item是对应连接关系,这样就直接存储到数据库了)。
发布日期:2022-02-23 07:42:36
浏览次数:11
分类:技术文章
本文共 6018 字,大约阅读时间需要 20 分钟。
python爬虫框架feapder的使用简介
1、前言
Feapder 是一款上手简单、功能强大、快速、轻量级的爬虫框架的Python爬虫框架。支持轻量爬虫、分布式爬虫、批次爬虫、爬虫集成,以及完善的爬虫报警机制。- AirSpider 轻量级爬虫,适合简单场景、数据量少的爬虫
- Spider 分布式爬虫,基于 Redis,适用于海量数据,并且支持断点续爬、自动数据入库等功能
- BatchSpider 分布式批次爬虫,主要用于需要周期性采集的爬虫
2、Feapder的安装
# 安装依赖库pip3 install feapder
2、Feapder的安装
出现如下信息表示安装成功 feapder的介绍和环境安装就完成了,下面开始真正去使用fepader来爬取网站,并存储到mysql数据库。 3、新建feapder项目
通过下方的命令去创建一个名为:chenge_yc_spider的的爬虫项目feapder create -p chenge_yc_spider

4、编写爬虫
在终端中进入到项目(chenge_yc_spider)下的spiders文件夹下,通过下面的命令创建一个目标爬虫文件(target_spider)feapder create -s target_spider

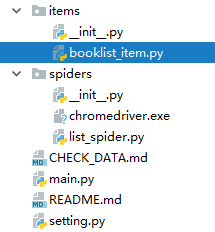
项目结构如下:
target_spider.py 为主要书写整体逻辑的文件
setting.py 为配置文件 下面代码书写在target_spider.py文件中import feapderfrom items import booklist_itemclass ListSpider(feapder.AirSpider): def start_requests(self): self.count = 1 yield feapder.Request("https://book.douban.com/top250") # def parse(self, request, response): print('Start the page {}'.format(self.count)) infos = response.xpath("//tr[@class='item']") for info in infos: # 书名 name = info.xpath('td/div/a/@title').extract_first() # 书的链接地址 book_url = info.xpath('td/div/a/@href').extract_first() # 获取的是书本的基本信息,有作者和出版社,和出版日期... book_infos = info.xpath('td/p/text()').extract_first() # 作者 author = book_infos.split('/')[0] # 出版社 publisher = book_infos.split('/')[-3] # 出版日期 date = book_infos.split('/')[-2] # 价格 price = book_infos.split('/')[-1] # 书本的评分 rate = info.xpath('td/div/span[2]/text()').extract_first() # 下面的评论 comments = info.xpath('td/p/span/text()').extract() # 这里单行的if语句是:如果comments的长度不为0时,则把comments的第1个元素给comment,否则就把"空"赋值给comment comment = comments[0] if len(comments) != 0 else "NULL" # print((name ,book_url , book_infos , author , publisher , date , price , rate , comment)) print((name)) list_item = booklist_item.BooklistItem() # Load database list_item.name = name list_item.book_url = book_url list_item.book_infos = book_infos list_item.author = author list_item.publisher = publisher list_item.date = date list_item.price = price list_item.rate = rate list_item.comment = comment yield list_item if infos.xpath("//span[@class='next']/a"): next_pag = infos.xpath("//span[@class='next']/a/@href").extract_first() self.count += 1 yield feapder.Request(url=next_pag) # When the next page appears, go directly toif __name__ == "__main__": ListSpider().start() #整体逻辑是: 获取当前页所有相关信息,并获取下一页链接,持续循环 """ feapder.Request中的参数 @summary: Request参数 --------- 框架参数 @param url: 待抓取url @param retry_times: 当前重试次数 @param priority: 优先级 越小越优先 默认300 @param parser_name: 回调函数所在的类名 默认为当前类 @param callback: 回调函数 可以是函数 也可是函数名(如想跨类回调时,parser_name指定那个类名,callback指定那个类想回调的方法名即可) @param filter_repeat: 是否需要去重 (True/False) 当setting中的REQUEST_FILTER_ENABLE设置为True时该参数生效 默认True @param auto_request: 是否需要自动请求下载网页 默认是。设置为False时返回的response为空,需要自己去请求网页 @param request_sync: 是否同步请求下载网页,默认异步。如果该请求url过期时间快,可设置为True,相当于yield的reqeust会立即响应,而不是去排队 @param use_session: 是否使用session方式 @param random_user_agent: 是否随机User-Agent (True/False) 当setting中的RANDOM_HEADERS设置为True时该参数生效 默认True @param download_midware: 下载中间件。默认为parser中的download_midware @param is_abandoned: 当发生异常时是否放弃重试 True/False. 默认False @param render: 是否用浏览器渲染 @param render_time: 渲染时长,即打开网页等待指定时间后再获取源码
5、配置MySQL相关内容
- 创建 bookList 数据表
CREATE TABLE `booklist` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `book_url` varchar(255) DEFAULT NULL, `book_infos` varchar(255) DEFAULT NULL, `author` varchar(255) DEFAULT NULL, `publisher` varchar(255) DEFAULT NULL, `date` varchar(255) DEFAULT NULL, `price` varchar(255) DEFAULT NULL, `rate` varchar(255) DEFAULT NULL, `comment` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 在setting.py文件中配置 MySQL相关连接
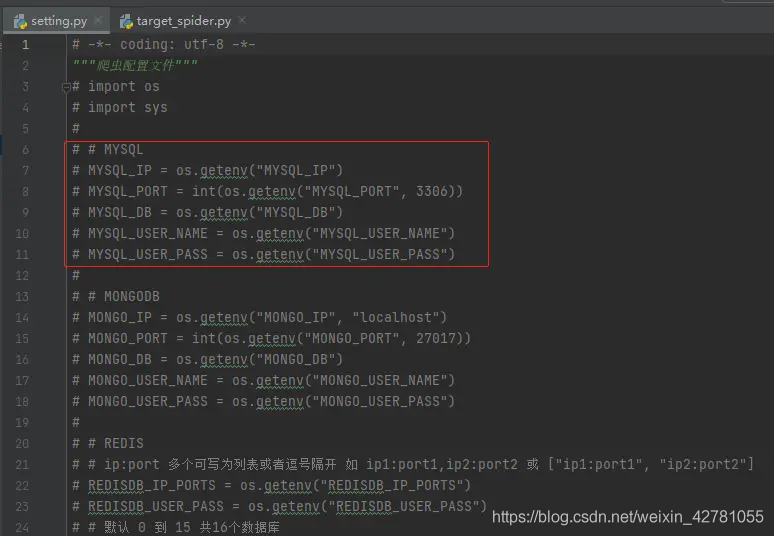 ( 注意:需要将os.geteny 这些内容删除掉 )
( 注意:需要将os.geteny 这些内容删除掉 ) 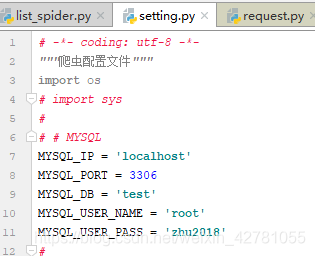
不删除就会是这样:
D:\AisonoWork\Amazon-spider\items>feapder create -i bookList2021-07-07 15:38:15.746 | DEBUG | feapder.db.mysqldb:__init__:91 - 连接到mysql数据库 None : None[]Traceback (most recent call last): File "d:\anaconda3\lib\runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "d:\anaconda3\lib\runpy.py", line 85, in _run_code exec(code, run_globals) File "D:\Anaconda3\Scripts\feapder.exe\__main__.py", line 7, inFile "d:\anaconda3\lib\site-packages\feapder\commands\cmdline.py", line 41, in execute create_builder.main() File "d:\anaconda3\lib\site-packages\feapder\commands\create_builder.py", line 76, in main CreateItem().create(item_name, support_dict) File "d:\anaconda3\lib\site-packages\feapder\commands\create\create_item.py", line 155, in create raise KeyError(tip)KeyError: 'mysql数据库中无 bookList 表 '
删除后, 配置成功后
接着在终端下,进入到根目录下的items文件夹,执行下面命令生成数据库表对于的itemfeapder create -i booklist # -i 表名
D:\AisonoWork\Amazon-spider\items>feapder create -i bookList2021-07-07 15:39:17.260 | DEBUG | feapder.db.mysqldb:__init__:91 - 连接到mysql数据库 localhost : testbooklist_item.py 生成成功
生成成功后,如下文件将会产生:
chromedriver.exe 只是一个模拟浏览器驱动,不用管。 6、存储到数据库 在 target_spider.py 中引入刚刚的 booklist_item.py,并创建对象BooklistItem。把爬取的数据表中的字段名初始化到对象中。最后yieId list_item,实际上就直接存储到数据库了(因为数据库表和item是对应连接关系,这样就直接存储到数据库了)。 """ 导入到数据库中 """from items import booklist_itemlist_item = booklist_item.BooklistItem() # Load databaselist_item.name = namelist_item.book_url = book_urllist_item.book_infos = book_infoslist_item.author = authorlist_item.publisher = publisherlist_item.date = datelist_item.price = pricelist_item.rate = ratelist_item.comment = commentyield list_item
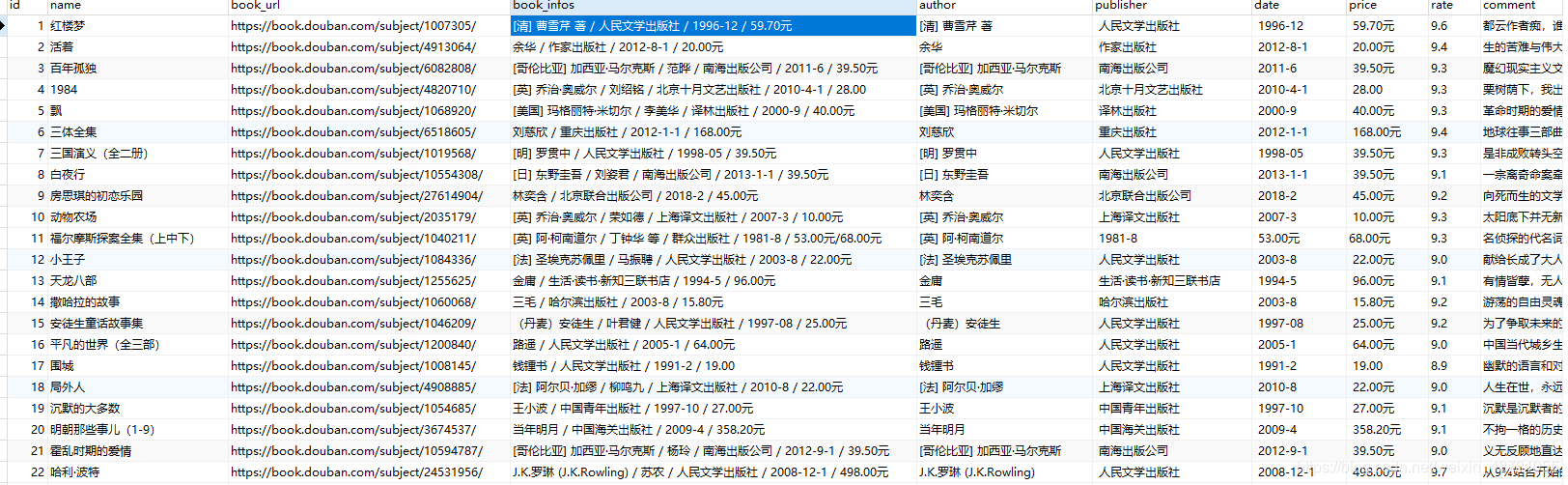
建议大家还是看看源码,多动手尝试。多动手尝试。多动手尝试。
转载地址:https://blog.csdn.net/weixin_42781055/article/details/118549695 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过按个爪印,很不错,赞一个!
[***.219.124.196]2024年04月03日 09时08分39秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
UGUI 列表循环使用
2019-04-27
使用命令行运行unity并执行某个静态函数(运用于命令行打包和批量打包)
2019-04-27
web.py框架
2019-04-27
web.py学习笔记
2019-04-27
python的代码缩进
2019-04-27
A* Pathfinding Project (Unity A*寻路插件) 使用教程
2019-04-27
bash学习笔记
2019-04-27
sqlite学习
2019-04-27
手把手教你实现Unity与Android的交互
2019-04-27
手把手教你使用Unity的Behavior Designer
2019-04-27
Unity3D摄像机裁剪——NGUI篇
2019-04-27
lua深拷贝一个table
2019-04-27
app运行提示Unable to Initialize Unity Engine
2019-04-27
spring boot 与 Ant Design of Vue 实现修改按钮(十七)
2019-04-27
spring boot 与 Ant Design of Vue 实现删除按钮(十八)
2019-04-27
spring boot 与 Ant Design of Vue 实现新增角色(二十)
2019-04-27
spring boot 与 Ant Design of Vue 实现修改角色(二十一)
2019-04-27
spring boot 与 Ant Design of Vue 实现删除角色(补二十一)
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308279355 位访客
访问时间: 2024-04-27 06:59:03
访问IP: 3.141.35.60
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版