本文共 8617 字,大约阅读时间需要 28 分钟。
redis基础操作
简介
redis是单线程+多路IO复用技术
redis的原子操作得益于redis单线程
基本操作 仅写一些常规操作,具体操作可以去查文档
keys * //查看所有键exists//判断一个键是否存在type //查看键对应的value的数据类型del //删除某个键expire //设置一个键过期时间,单位是秒ttl //查看键还有多久过期,-1表示永不过期,-2表示已过期dbsize //查看当前数据库有多少keyflushdb //清空当前数据库flushall //清空所有数据库
String的操作
get//查询对应键值set //设置key对应的键值,如果key已存在会覆盖原valueappend //给key追加value到原值的末尾strlen //查看值的长度setnx //只有key不存在的时候才会设置成功incr //将key存储的值+1,如果为空,新增值变为1decr //。。。。-1,。。。。。。。-1incrby / decrby <步长> //与前面类似,不再是 +/- 1改成 +/- 步长mset ... //一下设置多对key-valuemget ...//一下获取多对key对应的valuemsetnx ... //一下设置多对key-value,只有所有的key都不存在时才能成功getrange <起始位置> <结束位置> //获取key指定位置的数据,可以理解为切片setrange <起始位置> //用 覆盖 所存储的字符串值,从 <起始位置> 开始>set <过期时间> //设置key-value的同时指定生存时间getset //用value替换原值并返回原值
List的操作
list的底层是双线链表(类比java的LinkedList),因此对两端的操作性能很高,通过索引访问中间结点的性能会比较差
lpush / rpush... //从左/右边插入一个/多个值lpop/rpop //从左/右吐出一个值,当值全部吐出时,键将自动删除rpoplpush //从key1右边拿出一个值放到key2左边lrange //获取key的指定下标的元素lindex //按照索引下标获取元素llen //获取列表长度linsert before //在value前面插入newvaluelrem //从左边删除n个value
Set操作
set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
sadd//将多个value添加到key对应的集合中,已经存在的元素会被忽略smembers //取出该集合的所有值sismember //判断集合 是否含有value值,有返回1,否则返回0scard //返回集合中元素的个数srem //删除集合中的指定元素spop //随机从集合中吐出一个或多个值srandmember //随机从集合中取出n个值,但是不会从集合中删除这n个元素sinter //返回两个集合的交集sunion //返回两个集合的并集sdiff //返回两个元素的差集
Hash操作
类似java中HashMap,保存的是键值对的集合,适合存储对象。每个key存储了一个hash表
hset//给key集合中的field赋值valuehget //从key中取出field对应的值hgetall //获取所有filed-valuehmset ... //批量设置value的值hmget ...// 批量获取fieldhexists 查看key中是否存在fieldhkeys //列举key下所有的fieldhvals //列举key下所有valuehincrby //给key下field对应值+increment 原值和increment必须是整数,10.0也不行hincrbyfloat //给key下field对应值+increment 原值和increment必须是整数,10.0也不行hsetnx //将哈希表key中的field的值设置为value,只有filed原来不存在的情况下才能成功hdel ...//批量删除指定field
zset操作
redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的所有成员都关联了一个评分(score) ,这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。简单理解成有序集合。类似java的LinkedHashSet或者TreeSet
zadd...//将一个或多个 member 元素及其 score 值加入到有序集 key 当中zrange [WITHSCORES] //返回有序集 key 中,下标在 之间的元素 带WITHSCORES,可以让分数一起和值返回到结果集zrangebyscore key min max [withscores] [limit offset count] //返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。 zrevrangebyscore key max min [withscores] [limit offset count] //同上,改为从大到小排列。 zincrby //为元素的score加上增量zrem //删除该集合下,指定值的元素 zcount //统计该集合,分数区间内的元素个数 zrank //返回该值在集合中的排名,从0开始。
redis事务
multi //开启事务。。。一坨指令,没出错的会成功执行,出错的指令(incrby h1 h1存的是aaa)会失败如果含有本身使用错误的指令(get 缺少参数),则会和mysql的事务一个含义,所有指令都会被取消exec //执行事务discard //取消
redis锁
redis的锁有 表锁(悲观锁) 和 行锁(乐观锁)。因为redis的multi和exec之间正常的错误是不会令其他指令取消的,因此需要加锁
对于 读取频繁的 使用 乐观锁 用watch。。
对于 写入频繁的 使用 悲观锁 用
watch key //在执行mutli之前,先执行watch key,可以监视一个(或多个key) ,如果在事务执行之间,这个或这些key被改动,那么事务将被打断。如果watch之后,在写multi的时候,另一个操作修改了watch的变量,运行exec不会成功unwatch key会取消监视,用于exec之后

redis持久化
redis持久化,将redis保存成文件。每次启动redis都会加载存储在本地的文件,redis会fork一个子进程进行持久化。rdb时默认开启的,aof是默认不开启的
redis有两类持久化方式RDB 后缀文件为.rdb 在指定的时间间隔内将内存数据快照写入磁盘,恢复时是将快照文件读到内存里面。rdb的缺点是最后一次持久化的数据可能丢失。linux的父进程和子进程一般是通过写时复制策略,平时公用一段物理内存,只有进程空间的各段内容发生变化的时候,才会将父进程的内容赋值一份给子进程(看看os课本)rdb的保存策略在redis.conf,保存到文件在dump.rdb里面(默认)。AOF
RDB

第一条含义是900s内发生一条数据变化,就会保存
每次shutdown会保存一次
 默认是dump.rdb可以手动修改文件名和路径
默认是dump.rdb可以手动修改文件名和路径 手动保存快照save //保存过程不能进行其他操作,会被阻塞bgsave //保存过程中可以进行增删改查操作--------------------------------stop-writes-on-bgsave-error yes当redis无法写入磁盘的话,直接关掉reids的写操作rdbcompression yes 进行rdb保存时,将文件压缩rdbchecksum yes在存储快照后,可以让redis使用CRC64算法进行数据校验,这样做会增加大约10%的性能小号,如果希望获取到大的性能提升,可以关闭这个功能rdb的备份,只需要将rdb文件复制到其他路径即可想要关闭DRB,只需要删除所有的save就行了
AOF
以日志的方式记录每个操作,将redis执行过的所有指令记录下来(不会记录读操作),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis启动的话会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
 修改成yes就行了,redis默认开启了rdb,aof默认是关闭的。
修改成yes就行了,redis默认开启了rdb,aof默认是关闭的。 如果打开了AOF,每次redis启动会读取.aof文件来启动数据库,不会读取.rdb文件来启动数据库
//AOF同步频率设置1、始终同步,每次redis的写入操作都会被记入日志2、每秒同步,每秒记录一次日志,可能会丢失一秒的数据3、不主动同步,把同步时机交给操作系统修改appendfsync always/everysec/no 即可

当aof文件大小超过阈值,可以使用bgrewriteaof指令对aof进行内容压缩,只保留可以恢复数据的最小指令集

RDB,AOF修复
使用 即可修复redis-check-aof ???.aofredis-check-rdb ???.rdb二者比较:RDB效率高,AOF稳定RDB可能丢失数据,AOF恢复文件可能有bug对数据不敏感可以使用RDB不建议单独使用AOF,因为可能存在bug如果只是单纯做缓存,可以都不使用
Redis主从复制
简单的说就是主机完成各种操作,与此同时保留一台从机,从机用于备份主机数据,用于恢复用处:读写分离,性能扩展;容灾快速回复往主机写内容,写完只会复制到从机上。访问数据直接访问从机。
主机开启daemonize
 从机重新配置reids.conf,这个文件只是修改基础信息,不涉及配置主从机
从机重新配置reids.conf,这个文件只是修改基础信息,不涉及配置主从机 
主从机设置
info replication 查看信息slaveof成为某个机器的从机slaveof no one 变回主机

 主机信息
主机信息  主机加入k1 v1
主机加入k1 v1  从机完成备份,并且从机不能写只能读。但是主机可以读也可以写,当然我们一般将主机用于读
从机完成备份,并且从机不能写只能读。但是主机可以读也可以写,当然我们一般将主机用于读 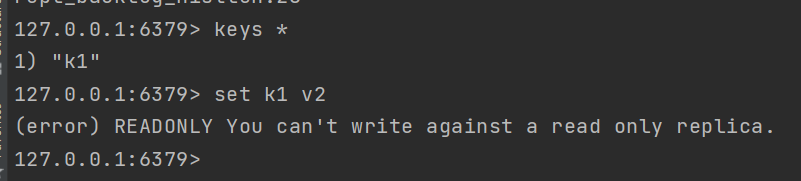
注意,一旦从机使用了slaveof指令,就完全会使用主机的数据,自带的数据不会出现在数据库里面主机死了,重启还是主机从机死了重启只会需要重新slaveof,否则不再属于任何主机,从机重启会保存宕机前已经备份的文件,因此从机重启之后无法再和主机保存联系。主机死了,从机会等着主机从机死了,主机失去从机
主从复制原理(redis2.0电子书里面有介绍):每次从机联通,都会给从机发送sync指令,主机立刻进行RDB备份,发送RDB文件给从机,从机会全盘加载。之后每一次主机的写操作都会立刻发送给从机,从机执行相同的操作。
薪火相传:一个从机可以是另一个机器的主机当一个master宕机,后面的从机会立刻变成主机,实现薪火相传优点:可以减轻主机的写压力缺点:一台从机宕机,它旗下的从机都会失去实时服务能力。A->B->CA死了B可以当主机,B死了C也完了,因为C没法获取A的备份,如果C后面还有机器,都会收到影响当然,前面说过了主机死了从机会等待,因此不加以设置的话,是不会出现薪火相传的情形的。下面介绍相关操作
哨兵模式: 反客为主的自动版,运行slaveof no one指令,可以让自己从从机变成主机。哨兵模式可以实现后台监控主机受否故障,如果故障了根据投票数自动将从库转换为主库。也就是前面说的主机死了,在主机下的从机中找一个从机接替主机的位置。由于redis是从机找主机的方式,因此主机宕机,从机可以及时得到信息,完成转变主机到其他机器的目标。 使用方法很简单:在sentinel.conf里面加入配置内容 sentinel monitor mymaster ip port 1 其中mymaster为监控对象起的服务器名称, 1 为 至少有多少个哨兵同意迁移的数量 然后执行执行redis-sentinel /myredis/sentinel.conf 选择主机的具体原理: 1、选择优先级靠前的 redis.conf里面有一个slave-priority 100的设置,这个可以手动改 2、选择偏移量最大的 偏移量是指获取原主数据最多的 3、选择runid最小的从服务 每个redis启动时都会随机产生一个40位的runid
Redis集群
注意搭建集群至少需要6台机器,因为redis的集群环境最少3台主机
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
集群环境配置
yum install rubyyum install rubygems
下载合适你redis版本的gem文件文件名称大致为redis-版本号.gem,拷贝到/opt目录下在/opt目录下执行gem install --local reids-版本号.gem然后在所有集群自己配置好自己的redis.conf文件加上这三行cluster-enabled yes //打开集群模式cluster-config-file nodes-端口号.conf //设定节点配置文件名cluster-node-timeout 15000 //设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。
启动所有的机器的redis然后 cd 到redis的src目录下执行./redis-trib.rb create --replicas 1 ip1:port1 ip2:port2 ip3:port3 ip4:port4 ip5:port5 ip6:port6...一个集群至少三个主节点选项--replicas 1 表示我们为每个主节点创建一个从节点前三个是主机,1-4,2-5,3-6循环分配从机。ip写真实ip,不写127.0.0.1
使用cluster nodes可以看到集群的信息
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中: 节点 A 负责处理 0 号至 5500 号插槽。 节点 B 负责处理 5501 号至 11000 号插槽。 节点 C 负责处理 11001 号至 16383 号插槽。
在集群中录入值在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis实例地址和端口。redis-cli客户端提供了 –c 参数实现自动重定向。如 redis-cli -c –p 6379 登入后,再录入、查询键值对可以自动重定向。不在一个slot下的键值,是不能使用mget,mset等多键操作。可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。 CLUSTER KEYSLOT计算键 key 应该被放置在哪个槽上。CLUSTER COUNTKEYSINSLOT 返回槽 slot 目前包含的键值对数量。 CLUSTER GETKEYSINSLOT 返回 count 个 slot 槽中的键。
n 故障判定1:集群中每个节点都会定期向其他节点发出ping命令,如果没有收到回复,就认为该节点为疑似下线,然后在集群中传播该信息2:当集群中的某个节点,收到半数以上认为某节点已下线的信息,就会真的标记该节点为已下线,并在集群中传播该信息3:如果已下线的节点是master节点,那就意味着一部分插槽无法写入了4:如果集群任意master挂掉,且当前master没有slave,集群进入fail状态5:如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态6:当集群不可用时,所有对集群的操作做都不可用,收到CLUSTERDOWN Thecluster is down错误信息n 故障恢复发现某个master下线后,集群会进行故障恢复操作,来将一个slave变成master,基于Raft算法,大致步骤如下:1:某个slave向集群中每个节点发送请求,要求选举自己为master2:如果收到请求的节点没有选举过其他slave,会同意3:当集群中有超过节点数一半的节点同意该slave的请求,则该Slave选举成功4:如果有多个slave同时参选,可能会出现没有任何slave当选的情况,将会等待一个随机时间,再次发出选举请求5:选举成功后,slave会通过 slaveof no one命令把自己变成master如果故障后还想集群继续工作,可设置cluster-require-full-coverage为no,默认yesn 对于集群故障恢复的说明1:master挂掉了,重启还可以加入集群,但挂掉的slave重启,如果对应的master变化了,是不能加入集群的,除非修改它们的配置文件,将其master指向新master2:只要主从关系建立,就会触发主和该从采用save方式持久化数据,不论你是否禁止save3:在集群中,如果默认主从关系的主挂了并立即重启,如果主没有做持久化,数据会完全丢失,从而从的数据也被清空
意该slave的请求,则该Slave选举成功
4:如果有多个slave同时参选,可能会出现没有任何slave当选的情况,将会等待一个随机时 间,再次发出选举请求 5:选举成功后,slave会通过 slaveof no one命令把自己变成master 如果故障后还想集群继续工作,可设置cluster-require-full-coverage为no,默认yes n 对于集群故障恢复的说明 1:master挂掉了,重启还可以加入集群,但挂掉的slave重启,如果对应的master变化了,是 不能加入集群的,除非修改它们的配置文件,将其master指向新master 2:只要主从关系建立,就会触发主和该从采用save方式持久化数据,不论你是否禁止save 3:在集群中,如果默认主从关系的主挂了并立即重启,如果主没有做持久化,数据会完全丢 失,从而从的数据也被清空发表评论
最新留言
关于作者
