Hadoop之Hadoop安装
 我的子网IP:192.168.2.0,子网掩码是:255.255.255.0 因此我的网络号是192.168.2,主机号范围是0~255 注意:一般情况不要使用0、1(网关),255(广播地址),部分网管也会将253设置为网关,不要占用这几个地址 我选择的地址是
我的子网IP:192.168.2.0,子网掩码是:255.255.255.0 因此我的网络号是192.168.2,主机号范围是0~255 注意:一般情况不要使用0、1(网关),255(广播地址),部分网管也会将253设置为网关,不要占用这几个地址 我选择的地址是 
发布日期:2021-05-04 20:59:57
浏览次数:25
分类:精选文章
本文共 4481 字,大约阅读时间需要 14 分钟。
Hadoop安装
序
一直在学习hadoop,但是一直认为自己太渣,所以没有记录博客,但是最近在学习过程中有一些问题还是需要记录一下。所以不管写的是不是合格,就just do it。如果不合理的地方,还请诸君多多指点。
注意:hadoop生态圈比较大,而hadoop官方一直被大家诟病的就是,各个组件之间的兼容问题。经过思考,采用CDH官方提供的版本配置:,但是不使用CDH进行构建。(系统资源不足以支撑CDH集群的构建…)。 下面是一些环节的说明: 选择的配置版本: Vmware 12(版本可以自由选择) Centos7 x64(最小安装):三台(master,slave1,slave2),建议使用国内yum源,对于下载安装包速度会有所提升 JDK 8操作系统环境准备
时钟同步(root账户)
在所有节点执行:
crontab -e# 保存下面内容 cron表达式 执行命令 时间服务器0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org #手动同步时间命令/usr/sbin/ntpdate cn.pool.ntp.org
配置主机名
在所有节点执行:
vim /etc/sysconfig/network# 添加内容如下(重启生效)NETWORKING=yes #启动网络 HOSTNAME=master #主机名,另外两个为slave1、slave2# 直接设置,重启失效hostname master# 查看主机名hostname
关闭防火墙(所有节点)
在所有节点执行:
不再赘述(话说我最小安装没有防火墙…)修改网络(所有节点)
目的将ip地址与主机映射起来
注意:尽量使用固定ip,如果ip地址发生改变,hadoop各节点之间很有可能会找不到。修改固定IP
首先你要根据虚拟机知道自己的IP地址段,网络使用Net模式,这样就相当于Net主机之间形成一个局域网,不需要占用主机IP。
VMware>编辑>虚拟网络编辑器,点击进入下面页面 我的子网IP:192.168.2.0,子网掩码是:255.255.255.0 因此我的网络号是192.168.2,主机号范围是0~255 注意:一般情况不要使用0、1(网关),255(广播地址),部分网管也会将253设置为网关,不要占用这几个地址 我选择的地址是 master:192.168.2.50slave1:192.168.2.101slave2:192.168.2.102
IP地址根据自己的网络进行选择
因此需要修改,下面截取的是slave1节点配置vim /etc/sysconfig/network-scripts/ifcfg-ens32

BOOTPROTO="static"ONBOOT="yes"DNS1=114.114.114.114 # 也可使用 8.8.8.8IPADDR=192.168.2.101PREFIX=24GATEWAY=192.168.2.1PEERDNS=no
,三台主机均修改完成后,修改host文件,达到各个节点可以通过主机名进行通信的目的
均添加以下内容192.168.2.50 master192.168.2.101 slave1192.168.2.102 slave2
最终效果各节点直接能相互ping通
配置JDK
因为hadoop是基于java语言进行开发的,所以要安装jdk
下载JDK 8,放到/usr/local/,解压,配置环境变量,篇幅无限,我也不想一一赘述。如有需要,可反馈给我,我再进行补充。。。免秘钥登录
由于master节点需要对slave1,slave2进行RPC通信,需要进行免秘钥登录设置,
原来将master节点的公钥复制到其他节点的信任列表中,master节点用直接的私钥进行签名,其他节点在信任列表中找到可信的公钥解密完成,运行操作 ,篇幅无限,我也不想一一赘述。如有需要,可反馈给我,我再进行补充。。。Hadoop环境配置(先配置好一个,然后将配置好的包拷贝到其他节点)
总之下载,解压。配置
下载Hadoop安装包,放到安装路径,解压,不多说,常规操作 我的文件路径是:(和上述文献版本不一致)/home/gugu/application/hadoop-2.9.0
配置开始:
- 配置环境变量 hadoop-env.sh
vim /home/gugu/application/hadoop-2.9.0/etc/hadoop/hadoop-env.sh# 修改下面内容,注意export前面有# 那个是注释符号,需要去掉的亲,后面值是你jdk的路径export JAVA_HOME=/usr/local/jdk1.8.0_181/

vim /home/gugu/application/hadoop-2.9.0/etc/hadoop/core-site.xml# 添加下面内容,第一项默认文件系统,第二项数据目录fs.defaultFS hdfs://master:9000 hadoop.tmp.dir /home/gugu/application/hadoopdata

vim /home/gugu/application/hadoop-2.9.0/etc/hadoop/hdfs-site.xml# 添加下面内容,默认副本数,其实可以不添加,默认的副本数是3,但是我有两台datanode,hadoop不允许一个节点存储两份文件副本。dfs.replication 2

vim /home/gugu/application/hadoop-2.9.0/etc/hadoop/yarn-site.xml# 添加下面内容yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.address master:18040 yarn.resourcemanager.scheduler.address master:18030 yarn.resourcemanager.resource-tracker.address master:18025 yarn.resourcemanager.admin.address master:18141 yarn.resourcemanager.webapp.address master:18088

# 复制配置文件模板cp /home/gugu/application/hadoop-2.9.0/etc/hadoop/mapred-site.xml.template /home/gugu/application/hadoop-2.9.0/etc/hadoop/mapred-site.xml# 编辑mapred-site.xml内容,添加下面内容,指定调度框架为yarn,后面的可以不配置mapreduce.framework.name yarn yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=/home/gugu/application/hadoop-2.9.0 mapreduce.map.env HADOOP_MAPRED_HOME=/home/gugu/application/hadoop-2.9.0 mapreduce.reduce.env HADOOP_MAPRED_HOME=/home/gugu/application/hadoop-2.9.0

vim /home/gugu/application/hadoop-2.9.0/etc/hadoop/slaves# 添加下面内容,指定slave1,slave2为slave角色slave1slave2
保存退出
7. 将hadoop复制到其他节点# 可以使用scp命令进行远程拷贝,-r代表递归拷贝,gugu指远程主机的登录用户,slave1指远程主机,后面的是远程主机上的路径 scp -r /home/gugu/application/hadoop-2.9.0 gugu@slave1:~/application/
- 创建数据目录(所有节点),配置环境变量
mkdir /home/gugu/application/hadoopdata# 配置环境变量#HADOOPexport HADOOP_HOME=/home/gugu/application/hadoop-2.9.0export PATH=$HADOOP_HOME/bin:$PATH

- 格式化文件系统(注意,执行此操作会格式化hdfs所有数据,谨慎操作,只在master节点执行)
# 格式化hdfs文件系统hdfs namenode -format# 如果出现error可能需要查找日志,判断原因
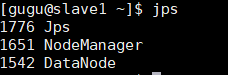
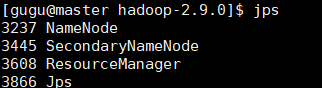
- 启动hadoop
sbin/start-all.sh# 此目录下也有单独启动的脚本,如启动hdfs的start-dfs.sh等jps # 查看节点上启动的java进程#主节点出现下面进程是正常的# 关闭sbin/stop-all.sh
发表评论
最新留言
很好
[***.229.124.182]2025年03月25日 05时19分46秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
对模拟器虚假设备识别能力提升15%!每日清理大师App集成系统完整性检测
2021-05-09
使用Power BI构建数据仓库与BI方案
2021-05-09
Django认证系统并不鸡肋反而很重要
2021-05-09
快用Django REST framework写写API吧
2021-05-09
tep用户手册帮你从unittest过渡到pytest
2021-05-09
12张图打开JMeter体系结构全局视角
2021-05-09
Spring Boot 2.x基础教程:构建RESTful API与单元测试
2021-05-09
[UWP 自定义控件]了解模板化控件(1):基础知识
2021-05-09
UWP 自定义控件:了解模板化控件 系列文章
2021-05-09
[UWP]从头开始创建并发布一个番茄钟
2021-05-09
在 Azure 上执行一些简单的 python 工作
2021-05-09
WinUI 3 Preview 3 发布了,再一次试试它的性能
2021-05-09
使用命令把SpringBoot项目打包成可运行的jar包(简洁,操作性强)
2021-05-09
List数组排序
2021-05-09
VMware vSphere 离线虚拟机安装 BIND 9
2021-05-09
说说第一份工作
2021-05-09
dojo/request模块整体架构解析
2021-05-09
dojo/aspect源码解析
2021-05-09
Web性能优化:What? Why? How?
2021-05-09
Javascript定时器学习笔记
2021-05-09
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 459561505 位访客
访问时间: 2025-04-19 18:02:59
访问IP: 3.145.124.186
Copyright © 2020 - 2025 css8.cn 京ICP备2021015314号-1
手机版