Elasticsearch自定义分析器analyzer分词实践
发布日期:2021-07-01 06:13:43
浏览次数:3
分类:技术文章
本文共 1948 字,大约阅读时间需要 6 分钟。
基础知识回顾
分析器的组成结构:
分析器(analyzer) - Character filters (字符过滤器)0个或多个 - Tokenizer (分词器)有且只有一个 - Token filters (token过滤器)0个或多个
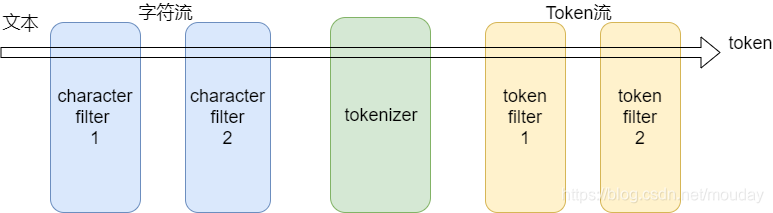
内置分析器
1、whitespace 空白符分词
POST _analyze{ "analyzer": "whitespace", "text": "你好 世界"}{ "tokens": [ { "token": "你好", "start_offset": 0, "end_offset": 2, "type": "word", "position": 0 }, { "token": "世界", "start_offset": 3, "end_offset": 5, "type": "word", "position": 1 } ]} 2、pattern正则表达式分词,默认表达式是\w+(非单词字符)
配置参数
pattern : 一个Java正则表达式,默认 \W+flags : Java正则表达式flags。比如:CASE_INSENSITIVE 、COMMENTSlowercase : 是否将terms全部转成小写。默认truestopwords : 一个预定义的停止词列表,或者包含停止词的一个列表。默认是 _none_stopwords_path : 停止词文件路径
// 拆分中文不正常POST _analyze{ "analyzer": "pattern", "text": "你好世界"}{ "tokens": []}// 拆分英文正常POST _analyze{ "analyzer": "pattern", "text": "hello world"}{ "tokens": [ { "token": "hello", "start_offset": 0, "end_offset": 5, "type": "word", "position": 0 }, { "token": "world", "start_offset": 6, "end_offset": 11, "type": "word", "position": 1 } ]}// 在索引上自定义分析器-竖线分隔PUT my-blog{ "settings": { "analysis": { "analyzer": { "vertical_line": { "type": "pattern", "pattern": "\\|" } } } }, "mappings": { "doc": { "properties": { "content": { "type": "text", "analyzer": "vertical_line" } } } }} // 测试索引分析器 POST /blog-v4/_analyze{ "analyzer": "vertical_line", "text": "你好|世界"}POST /blog-v4/_analyze{ "field": "content", "text": "你好|世界"}// 两者结果都是{ "tokens": [ { "token": "你好", "start_offset": 0, "end_offset": 2, "type": "word", "position": 0 }, { "token": "世界", "start_offset": 3, "end_offset": 5, "type": "word", "position": 1 } ]} 参考
转载地址:https://pengshiyu.blog.csdn.net/article/details/108854769 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
表示我来过!
[***.240.166.169]2024年05月08日 13时51分42秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
iOS 版本更新(强制更新)检测问题
2019-05-03
Struts2(1)简介
2019-05-03
XSS漏洞解析(一)
2019-05-03
Springboot使用详解
2019-05-03
leetcode算法 111. 二叉树的最小深度
2019-05-03
李洪强iOS开发之-cocopods安装
2019-05-03
实现string toHex(int)把一个十进制转换成十六进制。(完全用算法实现)
2019-05-04
覃仙球- 时装品牌Chilly Chin创始人 | 到「在行」来约见我
2019-05-04
struts2.5.10.1
2019-05-04
活动反作弊服务_防羊毛党_防作弊评论_防刷单_防作弊投票_网易易盾
2019-05-04
浅谈web指纹识别技术 - FreeBuf.COM | 关注黑客与极客
2019-05-04
技术漫谈 | 使用docker-compose进行python开发 - 推酷
2019-05-04
我眼中的领域驱动设计 - richiezhang - 博客园
2019-05-04
新风系统可取代空调吗? - 知乎
2019-05-04
高龄“潮男”优衣库老板柳井正_榜样_奢华主义_YOKA时尚网
2019-05-04
私人定制!13个在线纹理生成资源网站
2019-05-04
计算机内加减法的溢出处理
2019-05-04
DAO sql 传参
2019-05-04
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 312200082 位访客
访问时间: 2024-05-09 04:58:54
访问IP: 18.189.180.76
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版