Python爬虫基础
4. 网页下载器(

发布日期:2021-07-01 05:19:42
浏览次数:2
分类:技术文章
本文共 364 字,大约阅读时间需要 1 分钟。
1. 爬虫简介
- 爬虫:一段自动抓取互联网信息的程序。
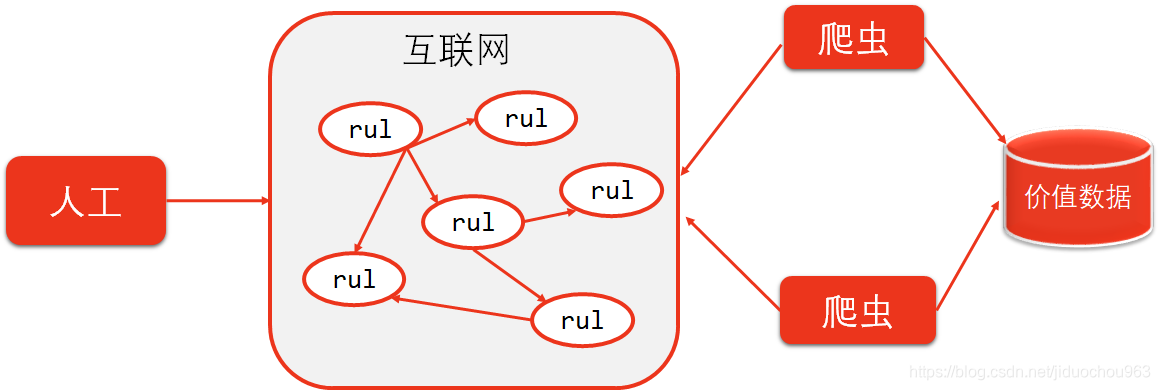
- 价值:互联网数据,为我所用!
2. 简单爬虫架构
Python简单爬虫架构
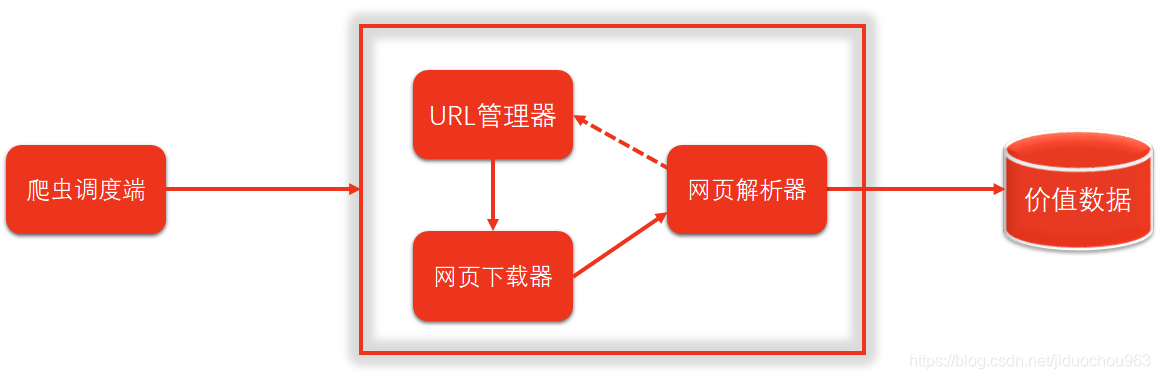
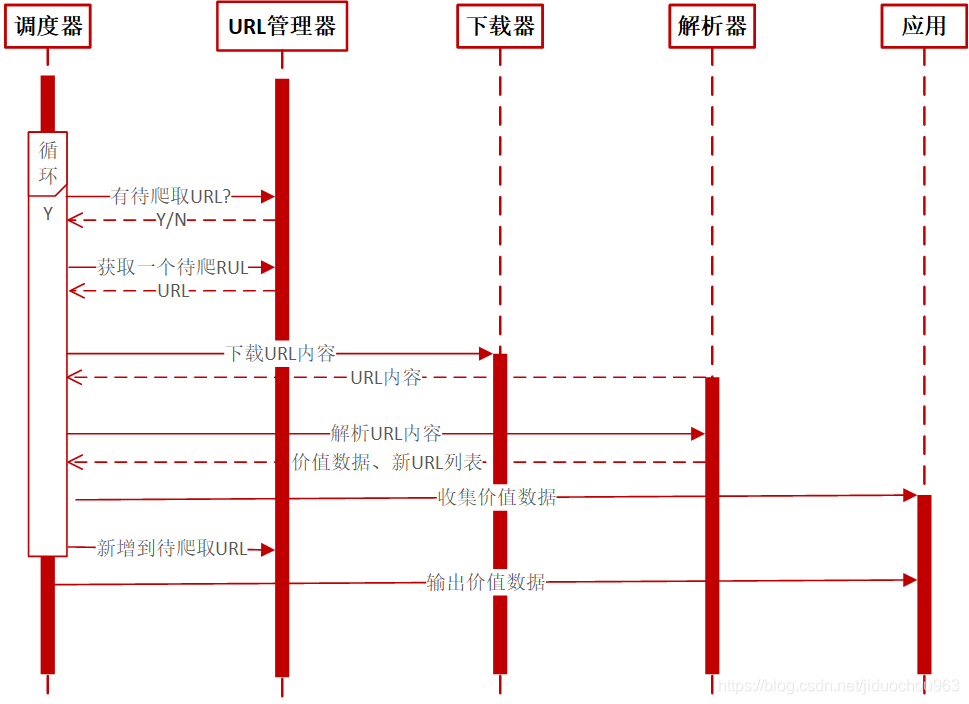
Python简单爬虫架构的动态运行流程
3. URL管理器
RUL管理器
- 管理待爬取RUL集合和已抓取URL集合。
- 防止重复抓取、防止循环抓取
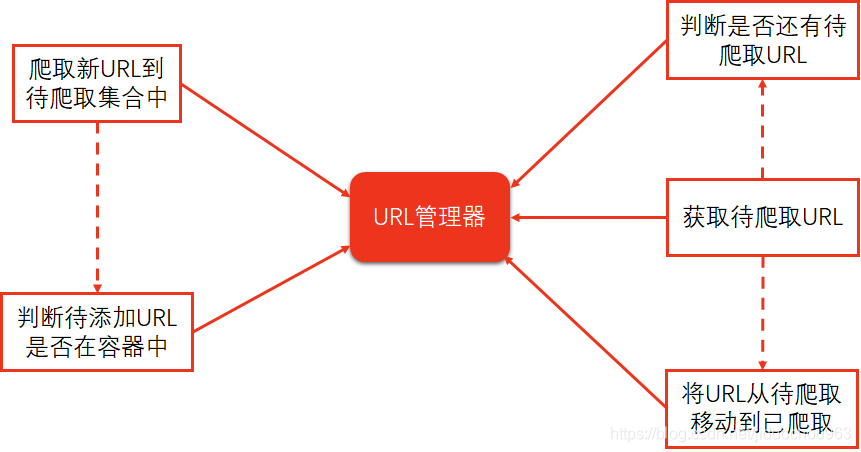
实现方式
- 内存
如Python中:
- 待爬取URL集合:
set() - 已爬取URL集合:
set()
- 关系数据库
如MySQL:
urls(url, is_crawled)
- 缓存数据库
如Redis:
- 待爬取URL集合:
set - 已爬取URL集合:
set
4. 网页下载器(urllib2)
网页下载器:将互联网上RUL对应的网页下载到本地的工具。
Python有哪几种网页下载器呢?
- Python官方基础模块:
urllib2 - 更强大的第三方包:
requests
转载地址:https://onefine.blog.csdn.net/article/details/86658551 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
很好
[***.229.124.182]2024年04月16日 06时20分07秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
记一次曲折的Debug经历
2019-04-30
基于SSM的兼职论坛系统的设计与实现
2019-04-30
基于java的ssm框架就业信息管理系统的设计
2019-04-30
Oracle字符串分隔符替换(替换奇数个或偶数个)
2019-04-30
Oracle 利用 UTL_SMTP 包发送邮件
2019-04-30
Oracle的pfile和spfile的一点理解和笔记
2019-04-30
2021-05-18
2019-04-30
基础架构系列篇-NGINX部署VUE
2019-04-30
在 Vue 中用 Axios 异步请求API
2019-04-30
Mysql 之主从复制
2019-04-30
【NLP学习笔记】中文分词(Word Segmentation,WS)
2019-04-30
对于时间复杂度的通俗理解
2019-04-30
如何输入多组数据并输出每组数据的和?
2019-04-30
行阶梯型矩阵
2019-04-30
JAVA学习笔记6 - 数组
2019-04-30
【学习笔记】Android Activity
2019-04-30
location区段
2019-04-30
linux内存的寻址方式
2019-04-30
how2heap-double free
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 312030507 位访客
访问时间: 2024-05-08 15:27:19
访问IP: 3.136.97.64
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版