本文共 16014 字,大约阅读时间需要 53 分钟。
绪论
机器学习能做什么?
- 手写字符识别
- 汽车自动驾驶
- 下棋(Deep Blue)
- 判断你的年龄
如何实现,存在的问题:
- 用何种形式来表示经验。
- 如何从历史数据中提取经验。

什么是机器学习?
定义一:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
定义二:
让计算机程序发现数据中的规律,并根据规律给出预测的一种智能技术。
定义三:
机器学习解决了如何构建计算机程序的问题,这些程序通过经验来提高它们在某些任务中的性能。
定义四:
机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。
经典的机器学习算法有什么?
- 分类(Classification):把事物按标准分成一些类别。
- 例子:
- 垃圾邮件诊断
- 疾病诊断
- 是否发放信用卡
- 是否录用
- 特点:Y=f(x), 其中y为离散值。
- 例子:
- 回归(Regression):由过去、现在的数据计算出未来状态。
- 例子:
- 预测身高
- 预测年龄
- 预测方向盘旋转角度
- 特点:Y=f(x), 其中y为连续值。
- 例子:
- 聚类(Clustering, Unsupervised Learning):没有类别的标准,按事物间的相似性划分成一些类别。
- 根据经验确定:如交易数据按上、下、晚
- 由机器自动确定 给定记录间的相似的尺度 不同类别间的差异尺度
- 对于有监督学习,需要训练样本{(x,y)}
- 对于无监督学习,只有{x},没有可供训练的样本标签 y。
- 增强学习(Reinforce Learning)
机器学习的分类
- 监督学习:通过已有的一部分输入数据与输出数据之间的关系,生成一个函数,将输入映射到合适的输出,例如回归和分类。
- k近邻算法
- 线性回归
- 逻辑回归
- 支持向量机
- 决策树和随机森林
- 神经网络
- 贝叶斯学习
- 无监督学习:直接对输入数据进行建模,例如聚类。
- 聚类
- 降维(主成分分析,PCA)
- 关联规则学习
- 半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。
- 强化学习:用于描述和解决智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
- 标准的马尔可夫决策过程
线性方法
线性回归
任务和模型
获取样本数据的一些特征,看作特征空间中的点,然后寻找线去拟合样本分布。
训练集->学习算法->假设函数(h:是从 X 到 Y 的一个关系映射,可以是线性的,也可以是非线性的)
解决机器学习问题的一般流程
- 数据收集
- 数据预处理与特征工程
- 模型的选择与训练
- 模型的评估与优化
- 用线性函数表示预测模型。
- 用损失函数衡量模型(即线性函数的参数)。
- 梯度下降将损失函数最小化以获得最佳模型。
损失函数和梯度下降
- 线性回归使用平方损失函数
- 逻辑回归使用交叉熵损失函数
平方损失函数对每一个输出结果都非常看重,而交叉熵损失函数只对正确分类的结果看重。

- 等值线图
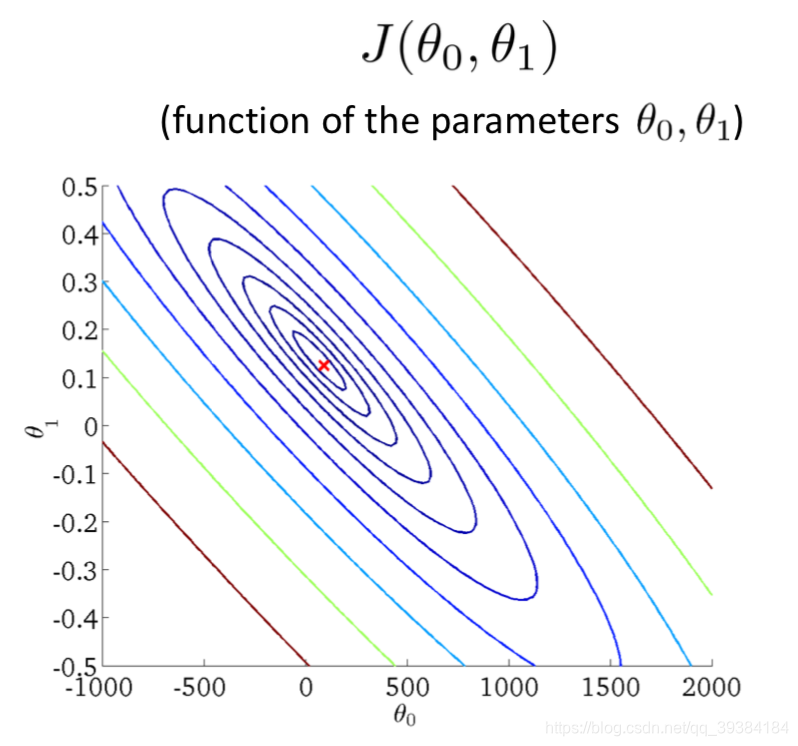

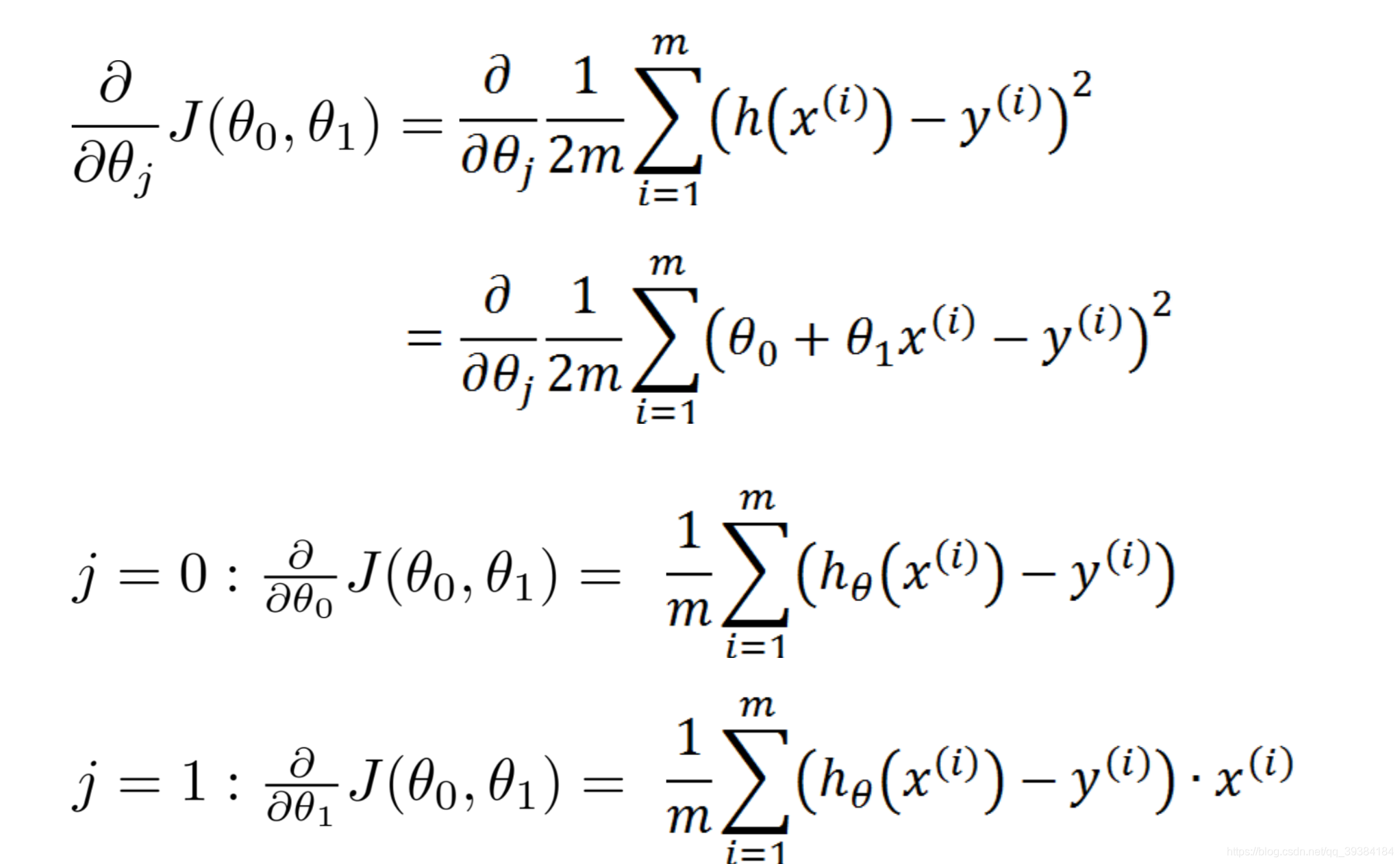
梯度下降方法
- Batch gradient descent,BGD:一次迭代训练所有样本。
- stochastic(随机的) gradient descent,SGD:每次只训练一个样本去更新参数。
- 随机把数据打乱很重要,因为这个随机性相当于引入了“噪音”,正是因为这个噪音,使得SGD可能会避免陷入局部最优解中。
- Mini-batch gradient descent:每次用一部分样本来更新参数,即 batch_size。
多元线性回归


特征缩放
Make sure features are on a similar scale.
- better:(-1,1)
- maybe:(-1/3,1/3)or(-3,3)
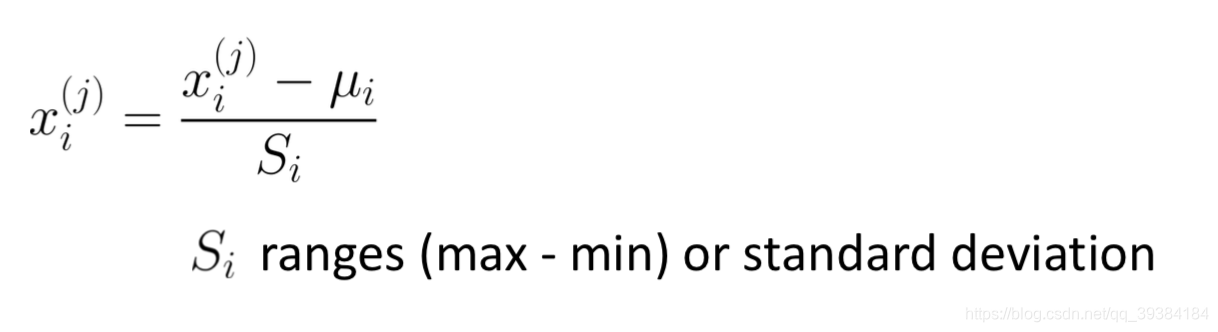
学习率

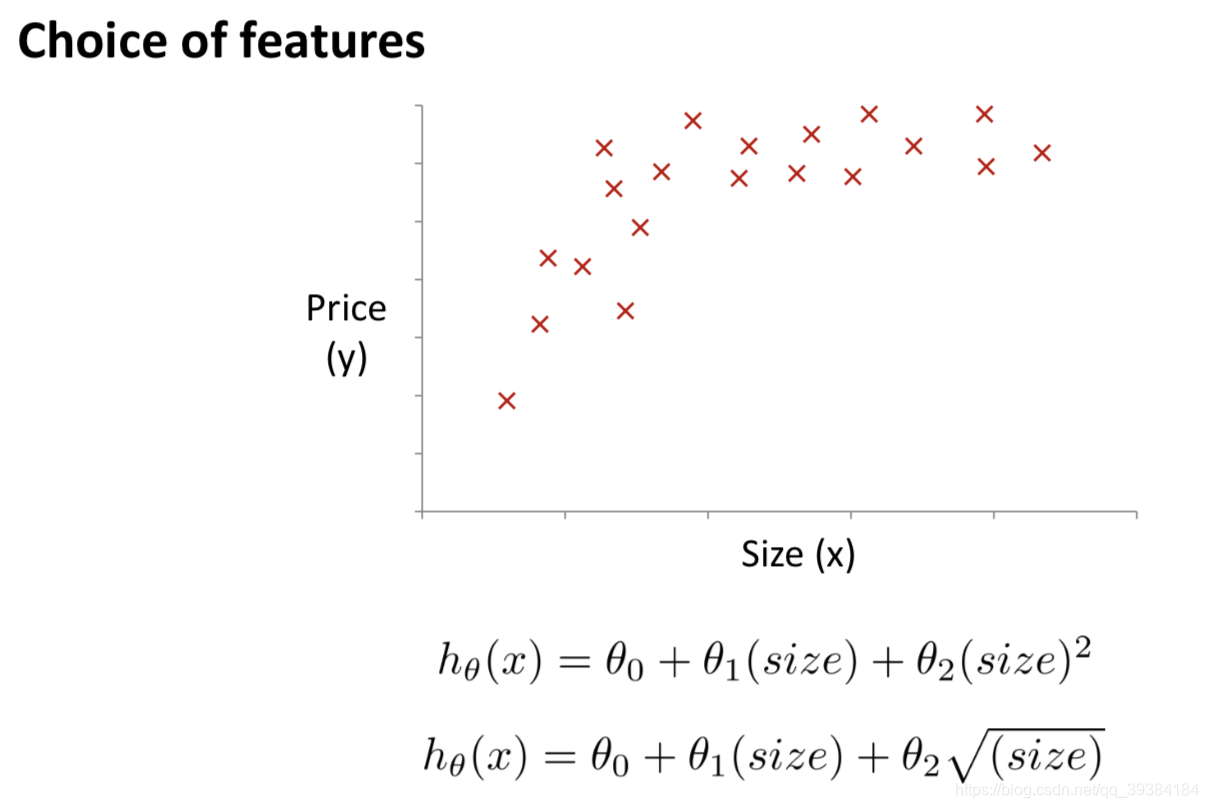
特征与多项式回归
正态方程
一种分析地求解θ的方法。
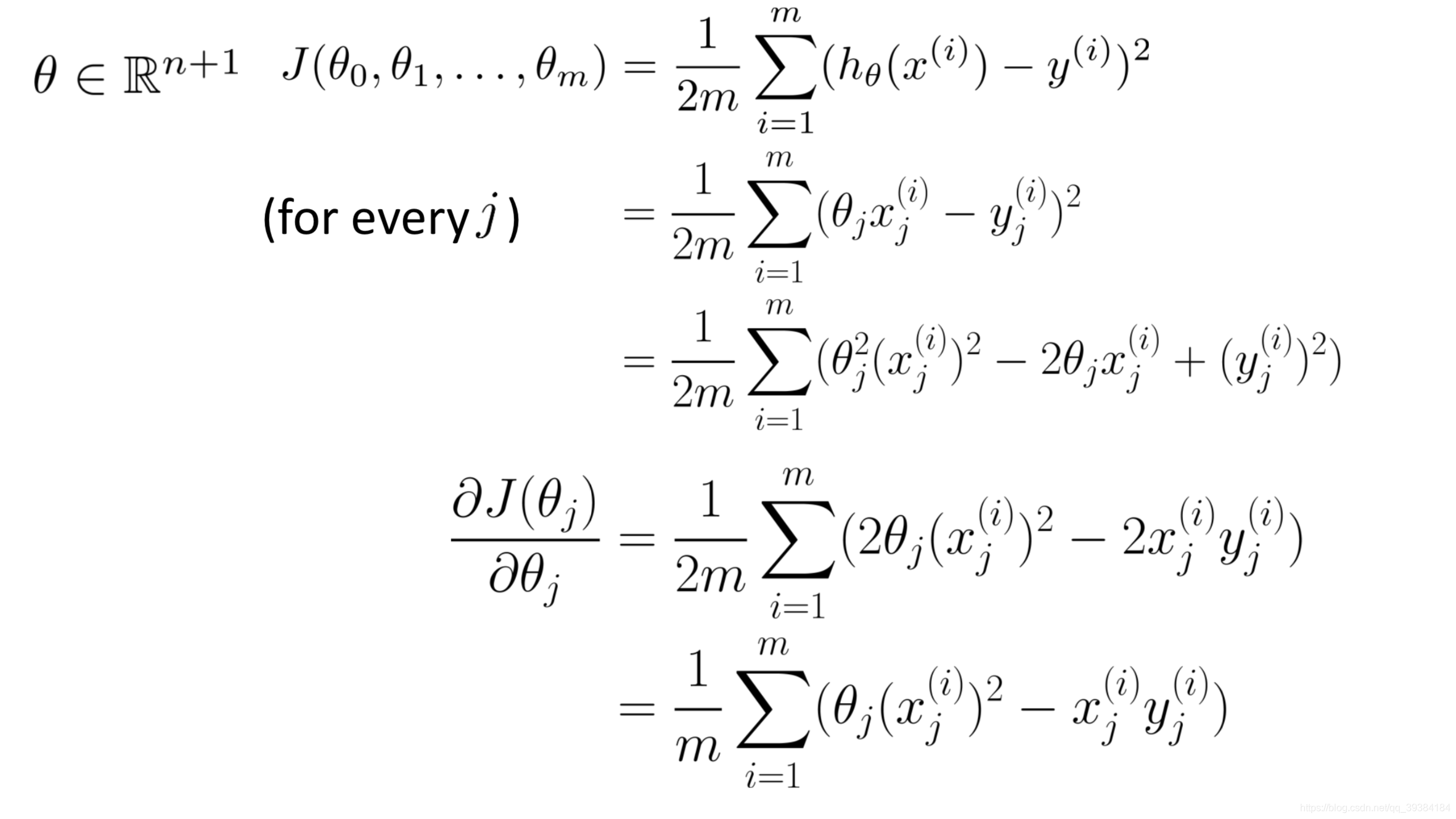
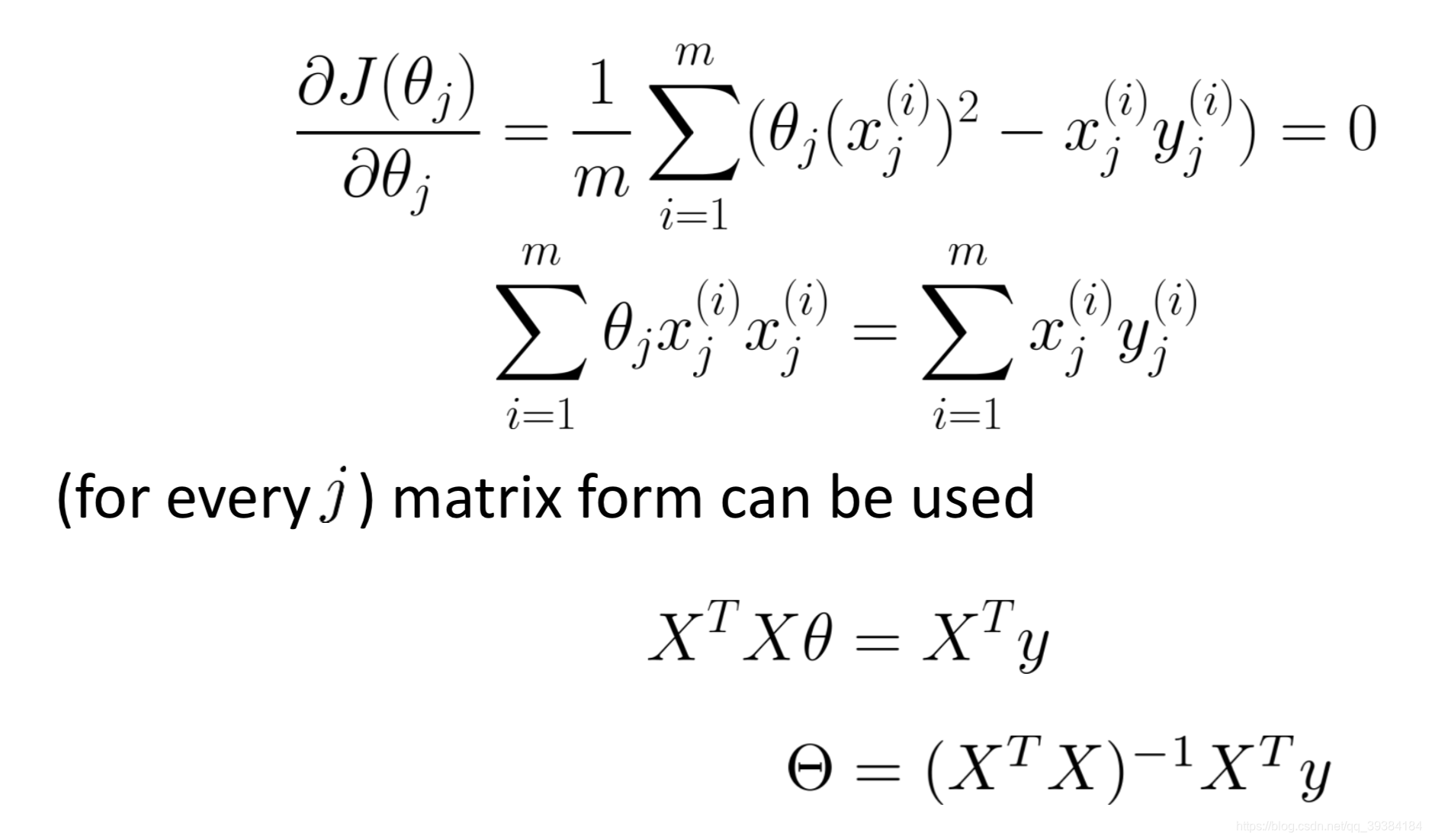
若 X 不可逆,则存在冗余的特征,或特征数量太多。
梯度下降与正态方程的比较
m 个训练样本,n 个特征。
| 梯度下降 | 正态方程 |
|---|---|
| 需要选择α | 不需要选择α |
| 需要很多次迭代 | 不需要迭代 |
| 需要计算 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1 | |
| 即使 n 很大也能很好的工作 | 当 n 很大时计算慢 |
逻辑回归
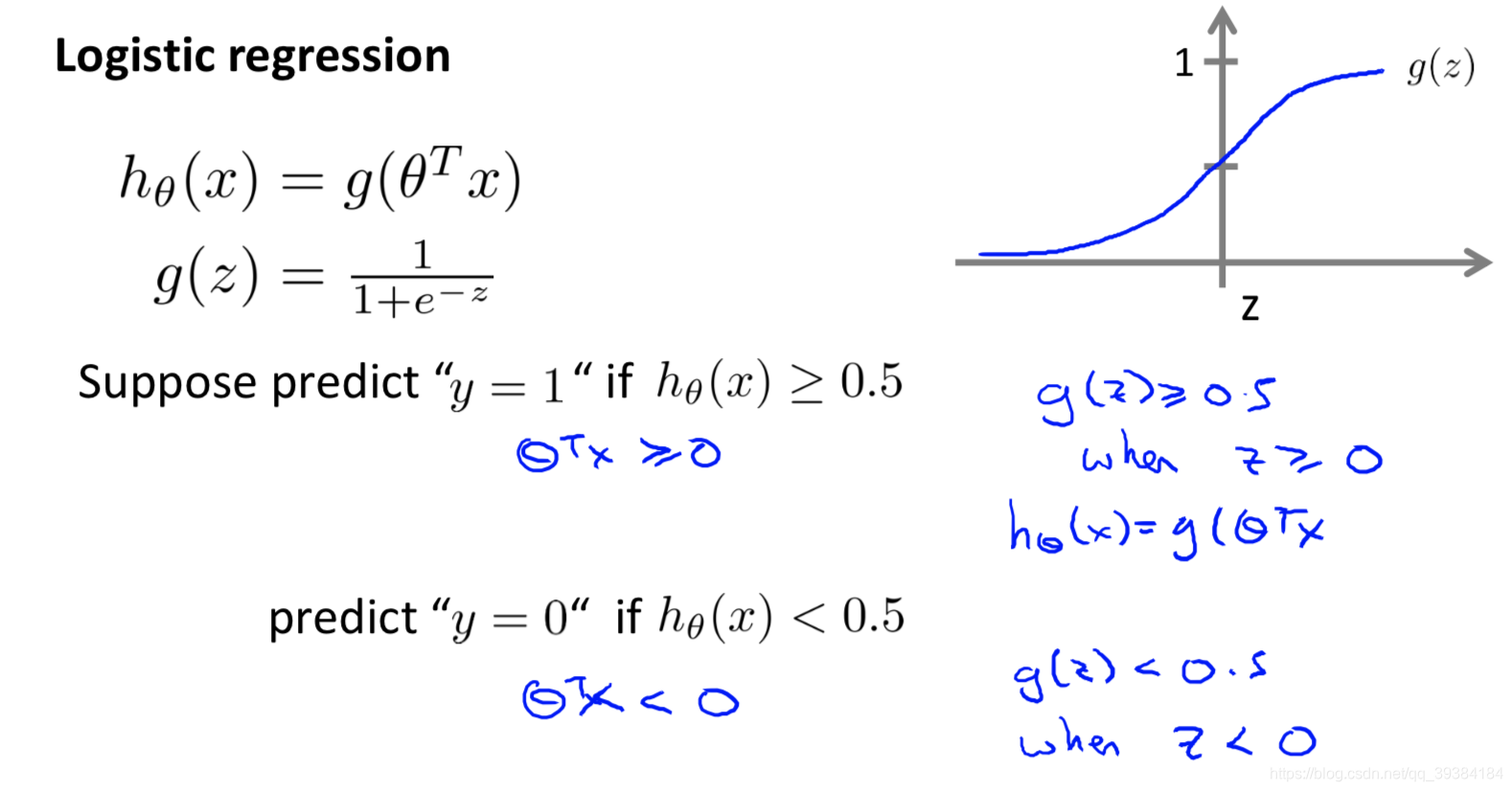
假设表示
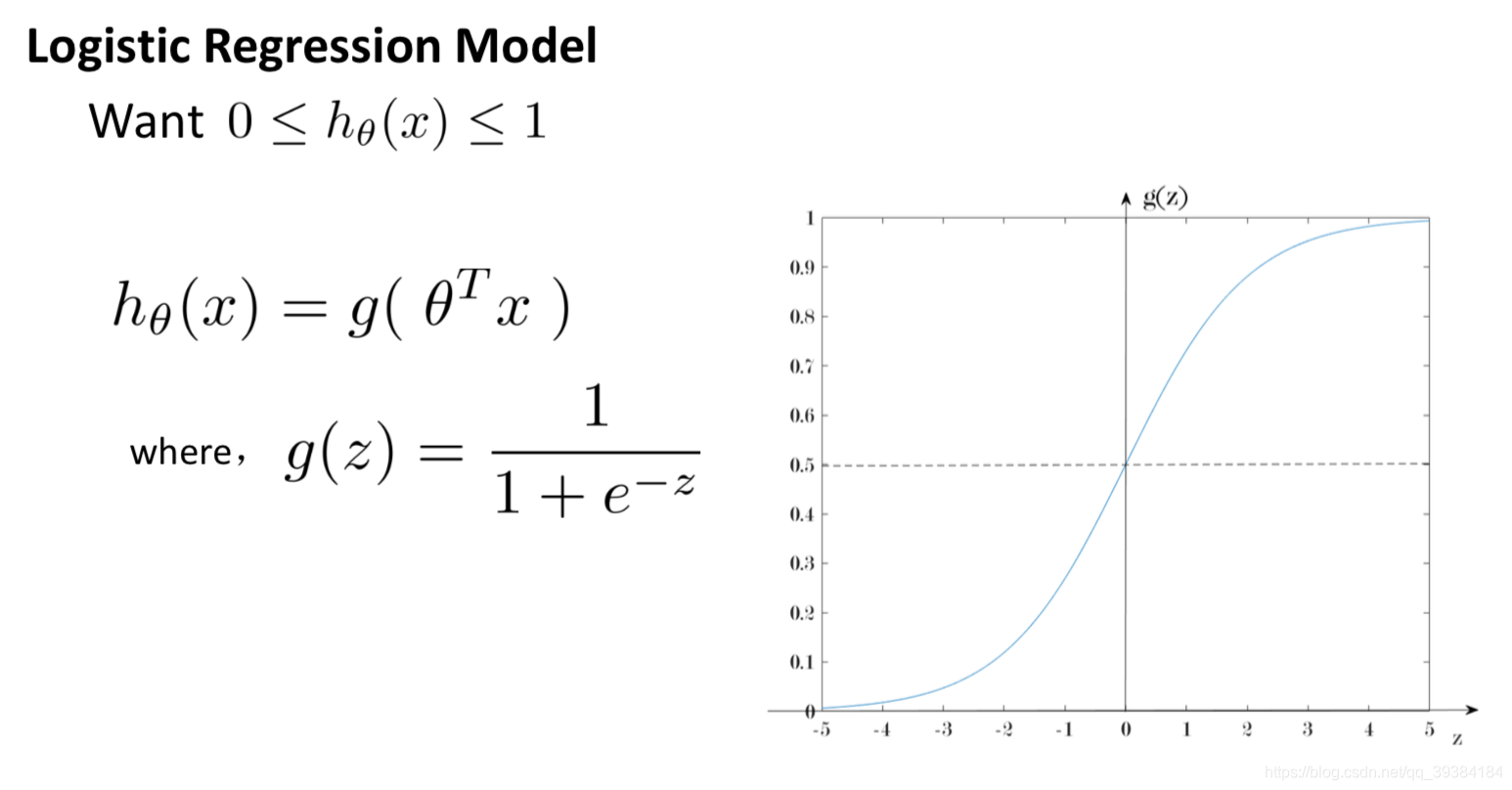

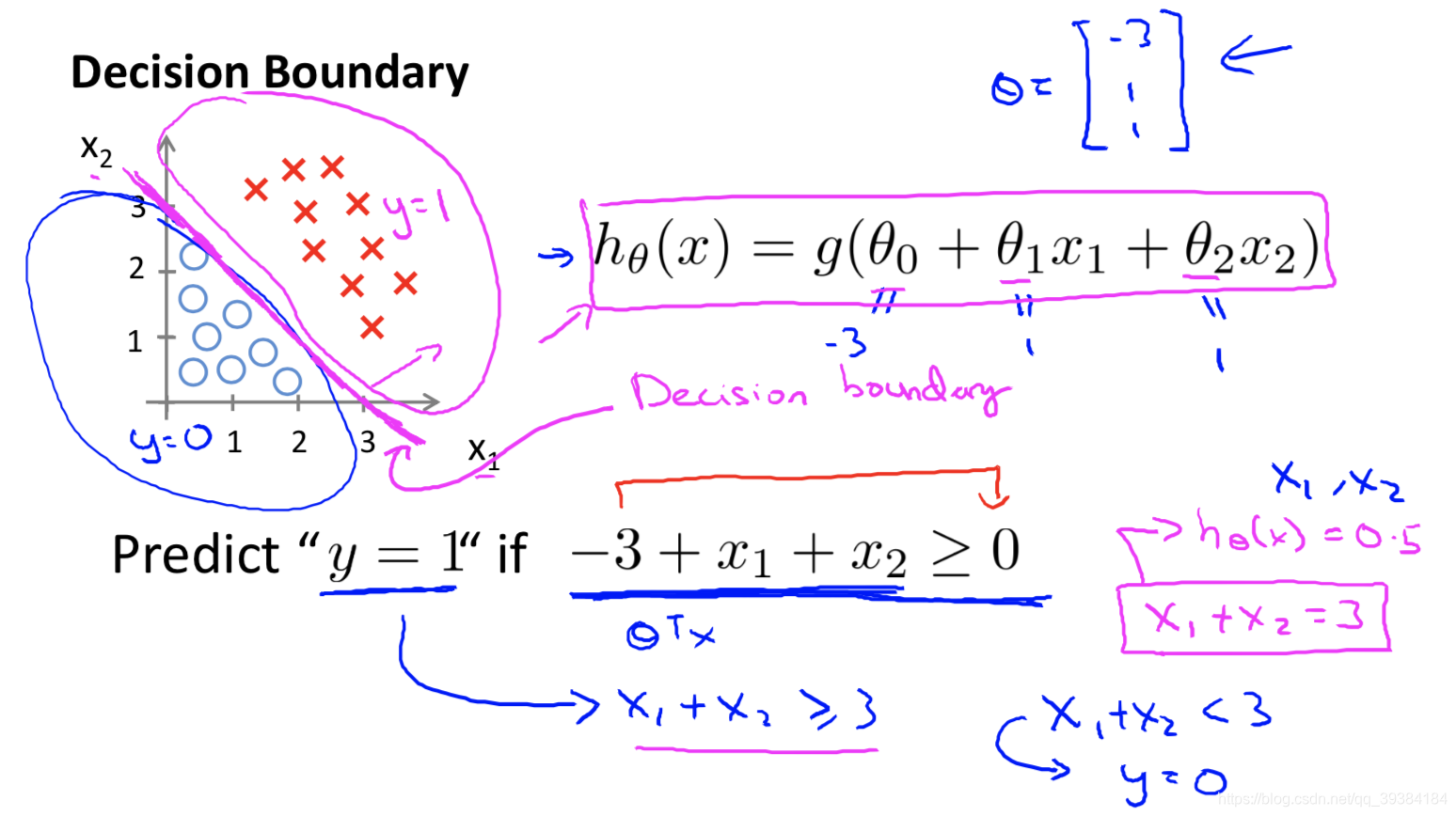
决策边界
所谓决策边界(decision boundary)就是能够把样本正确分类的一条边界,主要有线性决策边界(linear decision boundaries)和非线性决策边界(non-linear decision boundaries)。注意:决策边界是假设函数的属性,由参数决定,而不是由数据集的特征决定。

损失函数与梯度下降
如果逻辑回归使用平方损失函数:
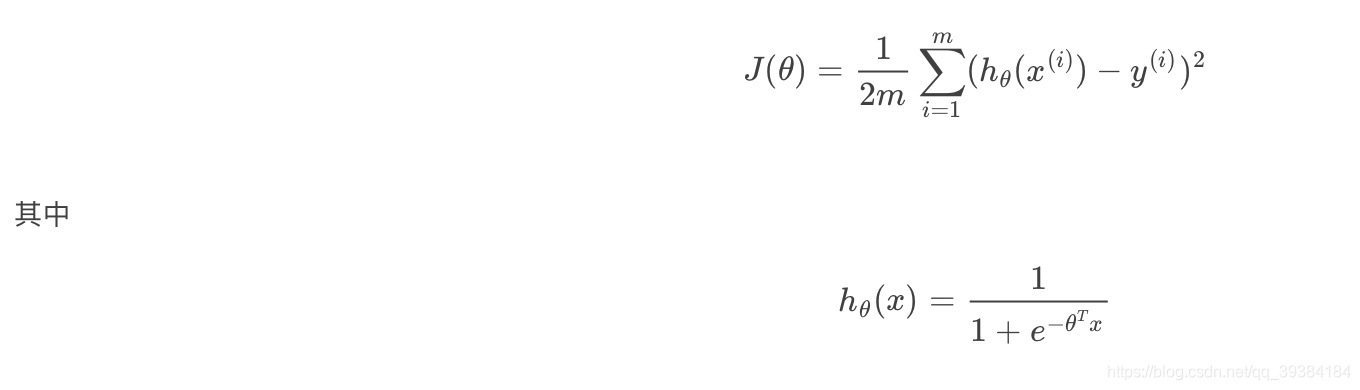
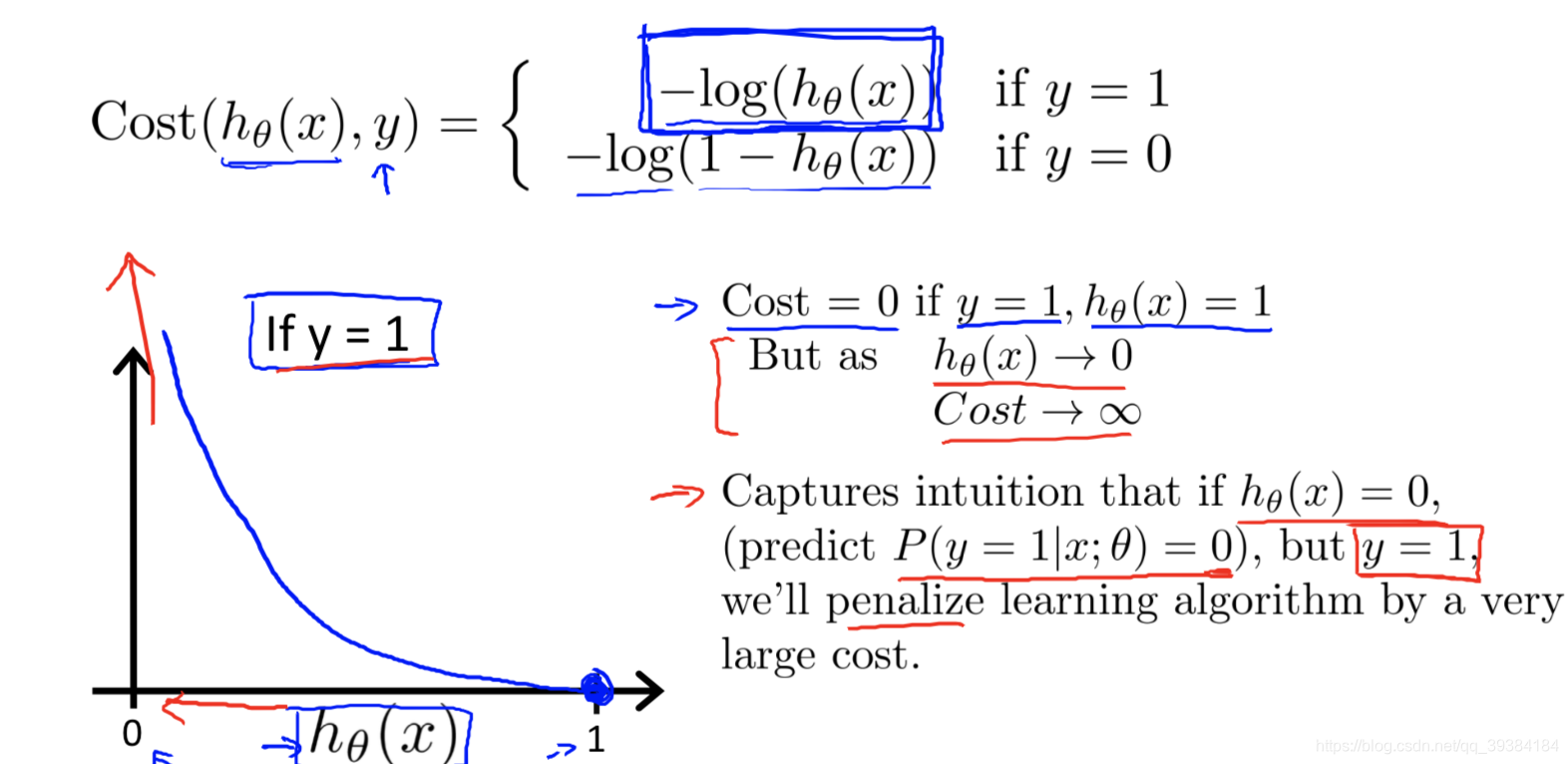
这样代价函数J(θ)关于算法参数θ会是非凸函数,存在多个局部解。我们想要的代价函数是关于θ的凸函数,这样我们就可以根据梯度下降法等最优化手段去找到全局最优解了。
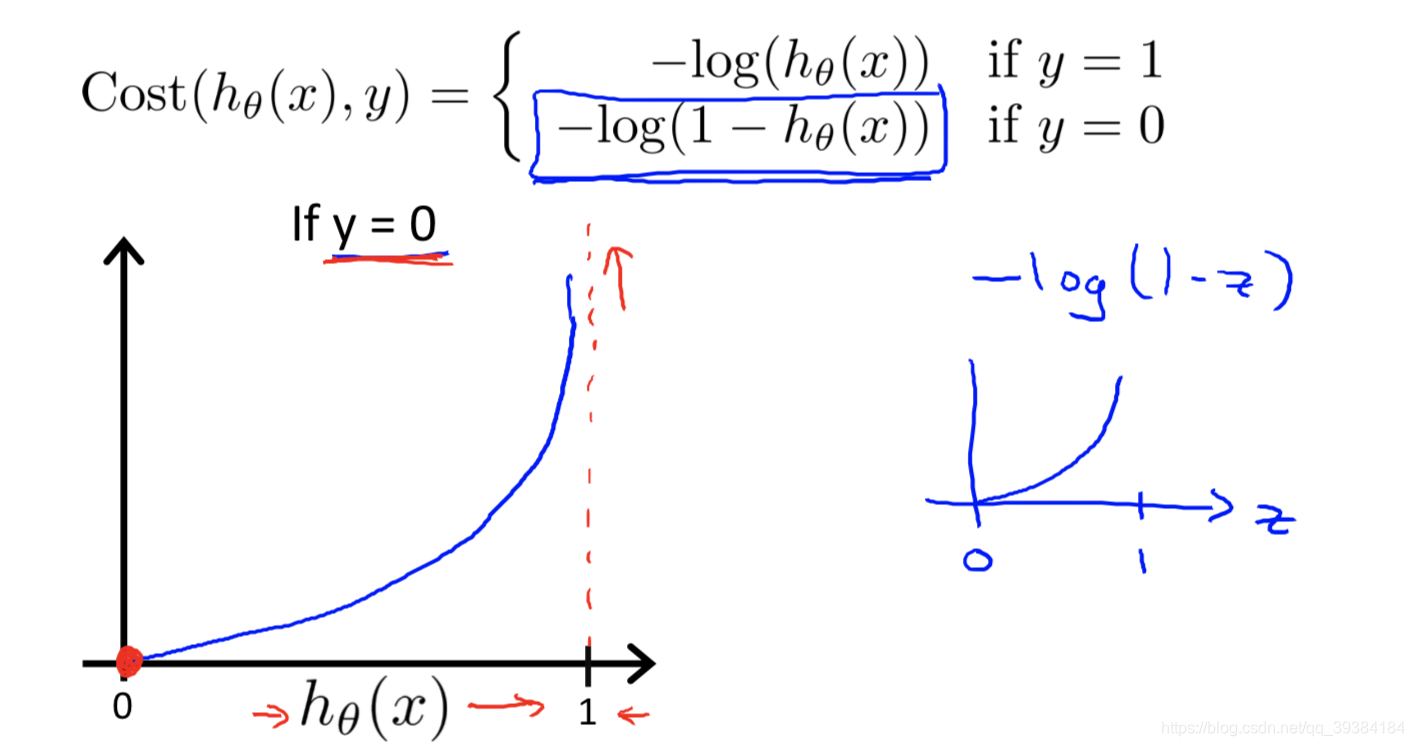


极大似然计算损失函数



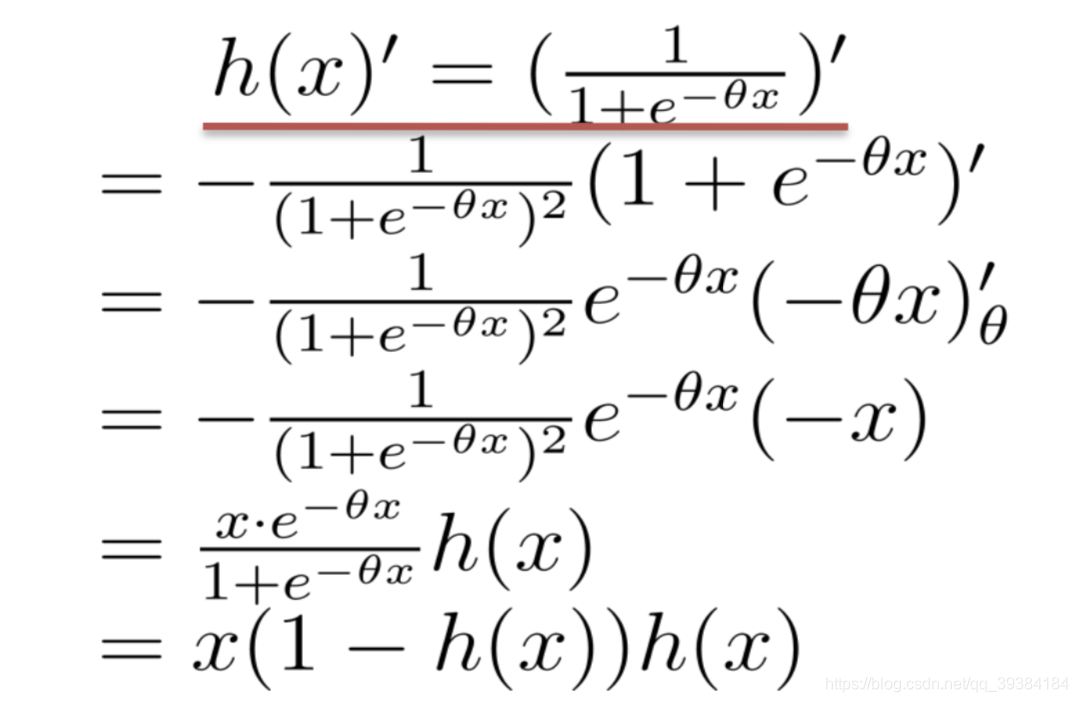
高级优化

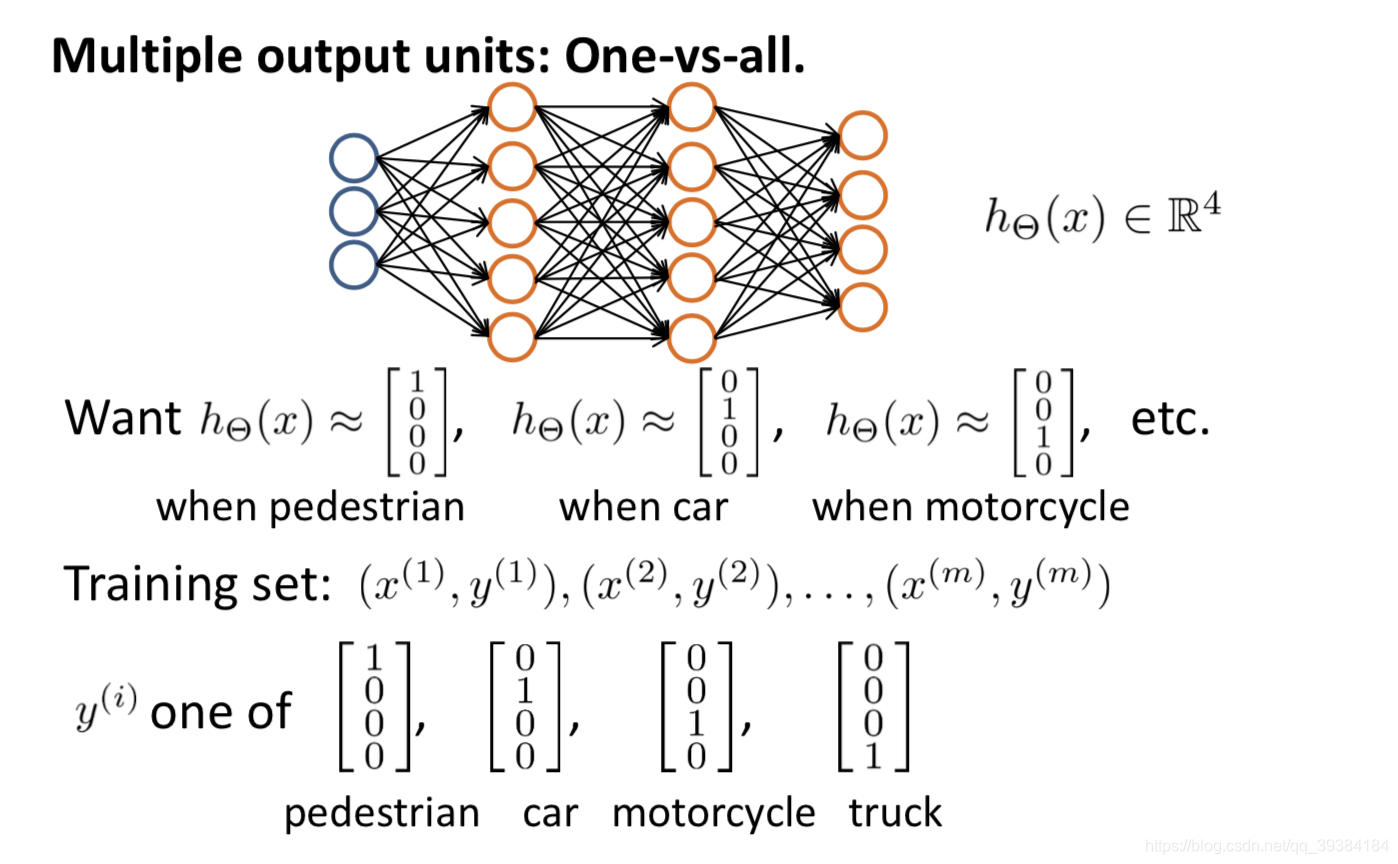
多元分类
有些二分类学习方法可直接推广到多分类,但在更多情形下,我们是基于一些基本策略,利用二分类学习器来解决多分类问题。
不失一般性,考虑 N 个类别 C1, C2, •••, CN,多分类学习的基本思路是"拆解法",即将多分类任务拆为若干个二分类任务求解。具体来说,先对问题进行拆分,然后为拆出的每个二分类任务训练一个分类器;在测试时,对这些分类器的预测结果进行集成以获得最终的多分类结果。这里的关键是如何对多分类任务进行拆分,以及如何对多个分类器进行集成。
最经典的拆分策略有三种:
- 一对一(One vs. One,简称 OvO)
- OvO 将这 N 个类别两两配对,从而产生 N(N-1)/2 个二分类任务。在测试阶段,新样本将同时提交给所有分类器,于是将得到 N(N-1)/2 个分类结果,最终结果可通过投票产生:即把被预测得最多的类别作为最终分类结果。
- 一对其余(One vs. Rest,简称 OvR)(One vs. All)
- OvR 则是每次将一个类的样例作为正例、所有其他类的样例作为反例来训练 N 个分类器。在测试时若仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果;若有多个分类器预测为正类,则通常考虑各分类器的预测置信度,选择置信度最大的类别标记作为分类结果。
- 多对多(Many vs. Many,简称 MvM)
- MvM 是每次将若干个类作为正类,若干个其他类作为反类。显然,OvO 和 OvR 是 MvM 的特例。MvM 的正、反类构造必须有特殊的设计,不能随意选取。
线性判别分析
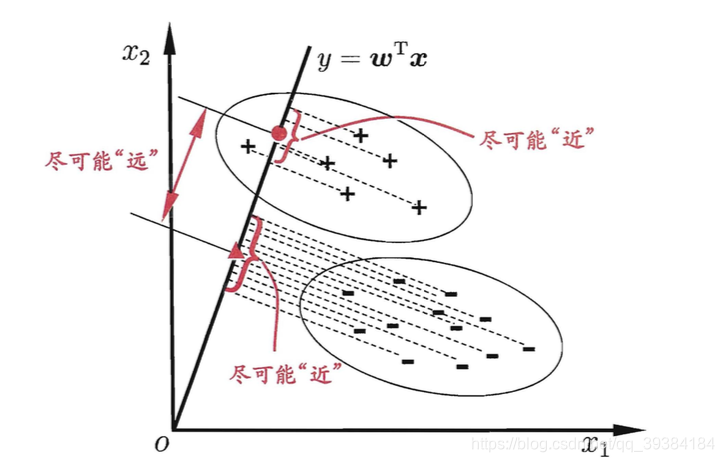
线性判别分析(Linear Discriminant Analysis,LDA)是一种经典的线性学习方法。
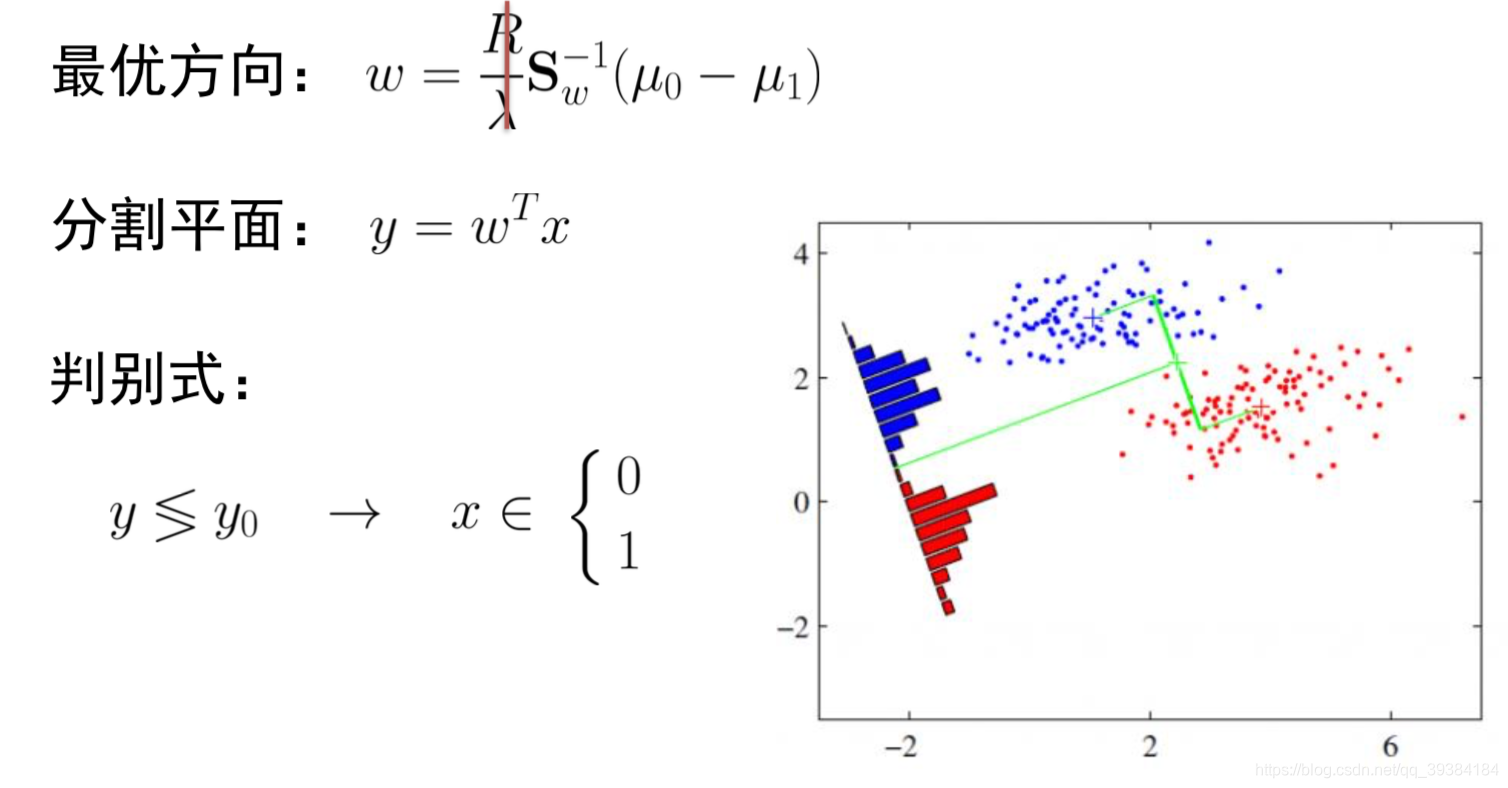
LDA的思想非常朴素:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。
- LDA 的二维示意图




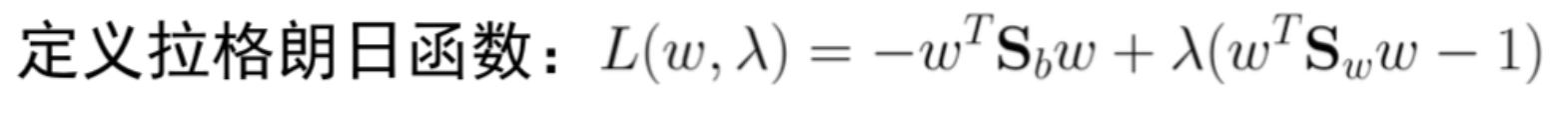
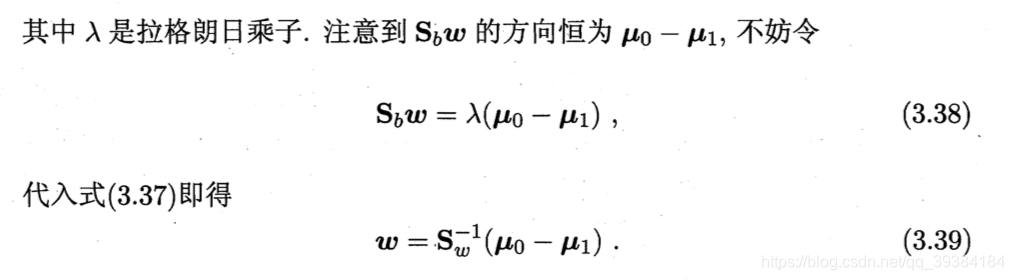
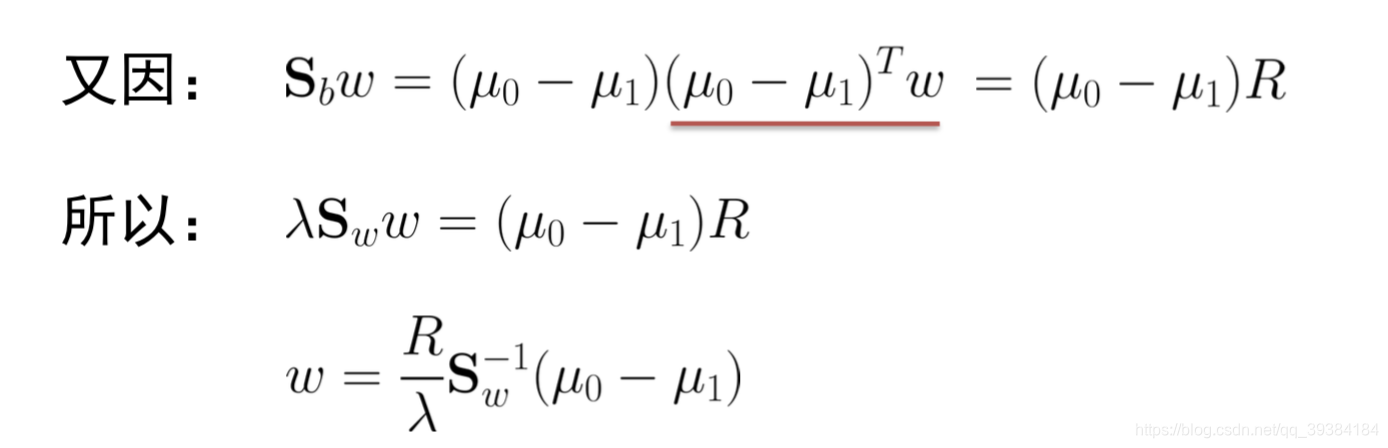
正则化
过拟合问题
- 过拟合:过拟合是指为了得到一致假设而使假设变得过度严格。避免过拟合是分类器设计中的一个核心任务。通常采用增大数据量和测试样本集的方法对分类器性能进行评价。
- 过拟合的判断方法:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少。
- 过拟合的常见原因:
- 建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的样本数据不足以代表预定的分类规则;
- 样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
- 假设的模型无法合理存在,或者说是假设成立的条件实际并不成立;
- 参数太多,模型复杂度过高。
解决过拟合问题:
- 减少特征的数目
- 正则化

代价函数
正则化使 θo、……、θn尽可能小:
- 简化了假设模型(参数数值越小,得到的函数就越平滑,也越简单)
- 不太容易过拟合

若 λ 的值太大,则会导致欠拟合。
线性回归的正则化
梯度下降


正态方程

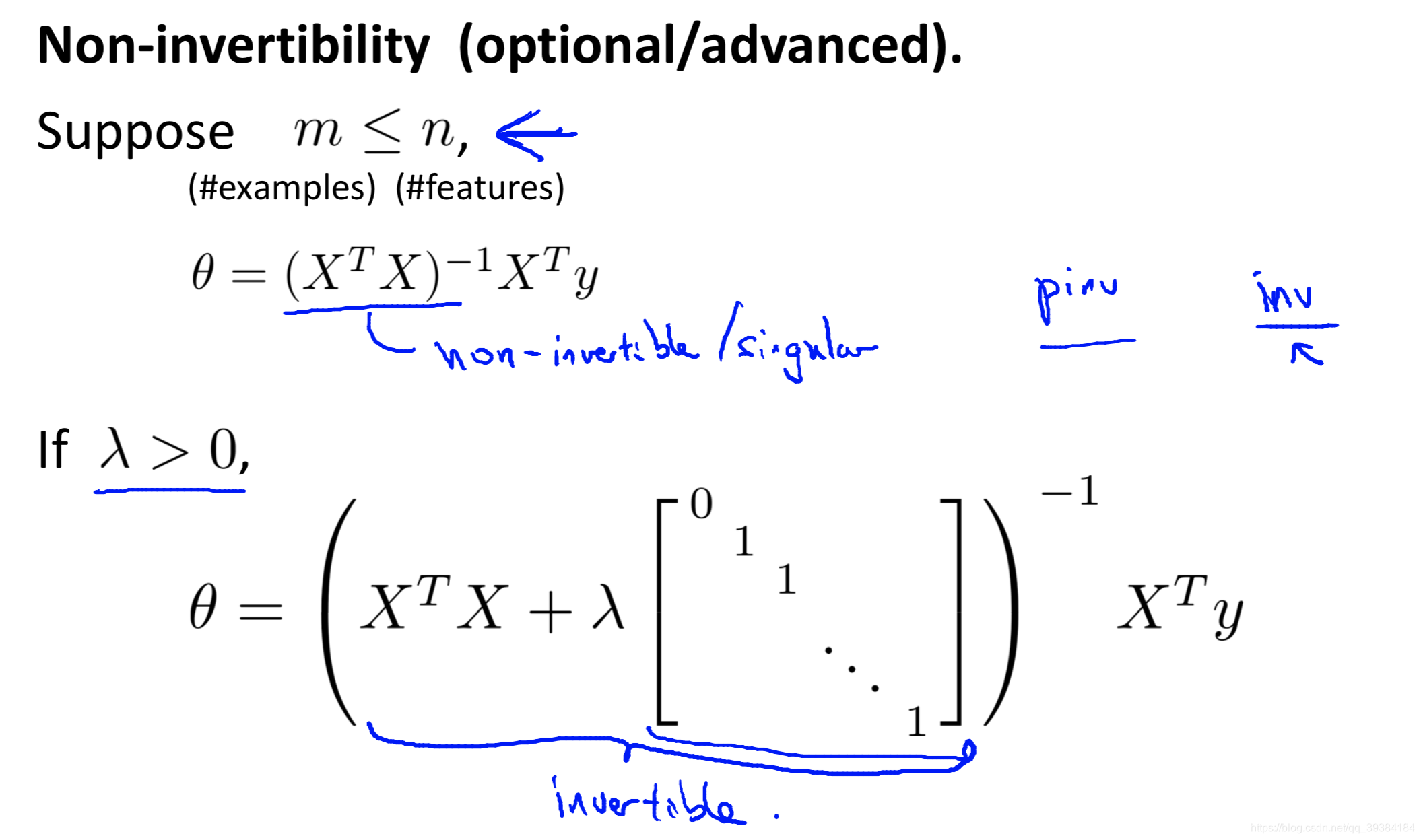
只要 λ 是严格大于 0 的,这个矩阵就一定是可逆的。因此,正则化还可以解决使用正态方程时不可逆的问题。
逻辑回归的正则化
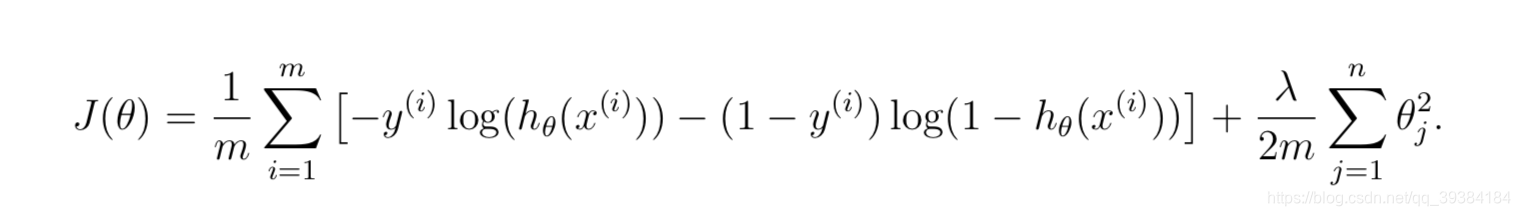

神经网络
非线性假设
- 线性描述只能解决小部分问题,机器学习能解决的问题很少。
- 使用特征二次组合和三次组合过于复杂,容易过拟合。
非线性假设采用神经网络的原因:逻辑回归问题不是解决包含大量特征的数据分类问题好办法。所以我们引入了神经网络。
如果数据包含上百个特征时呢?例如包含上百个特征的房屋分类问题,或者图像识别领域。例如:(x1, x2, x3, … x100),则即便只包含二次项,二次项的个数也会非常的多。这将导致非常多的高阶多项式,多项式规模急剧膨胀。逻辑回归问题不是解决包含大量特征的数据分类问题好办法。所以我们引入了神经网络。
神经网络的定义:神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实 世界物体所作出的交互反应。
模型展示
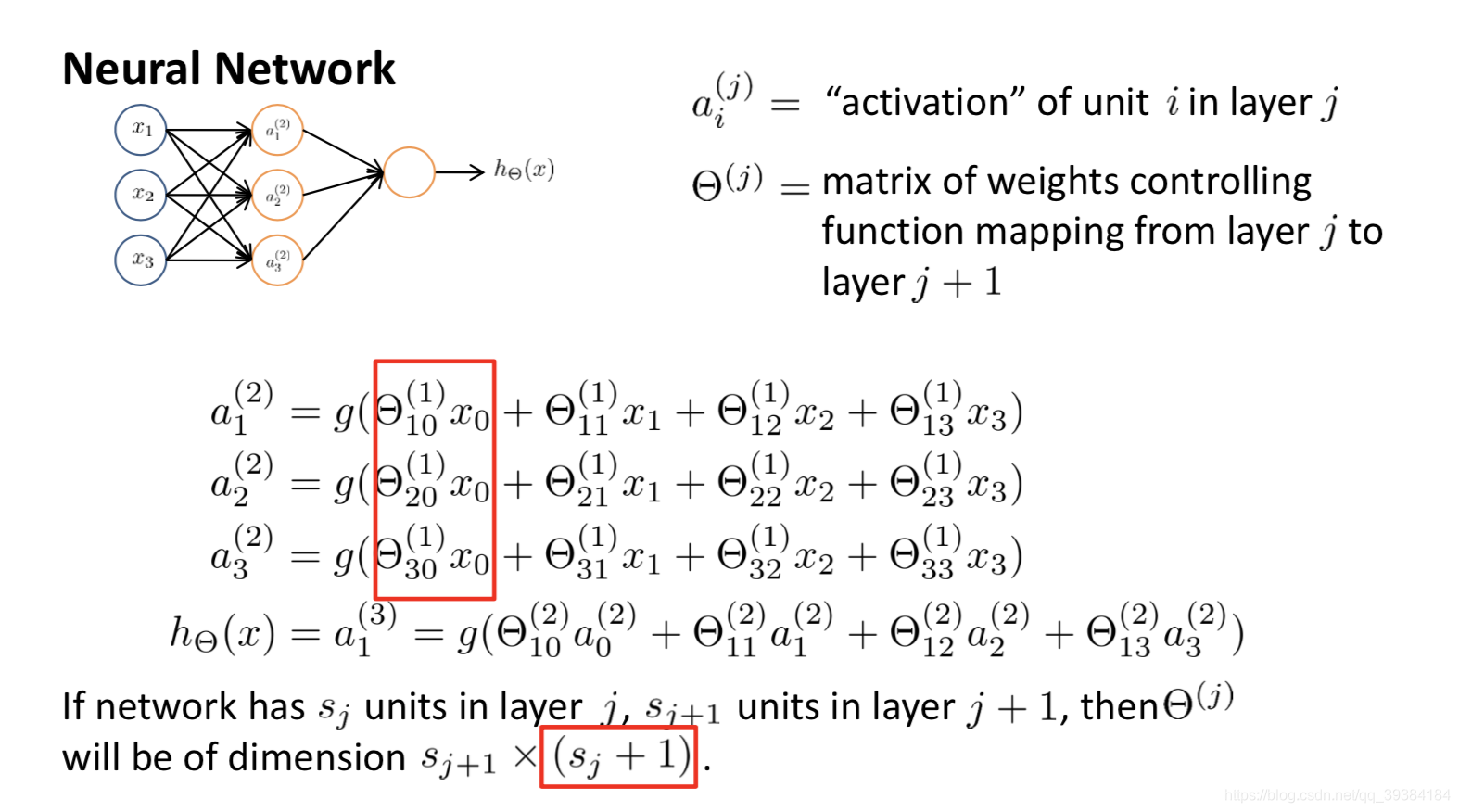
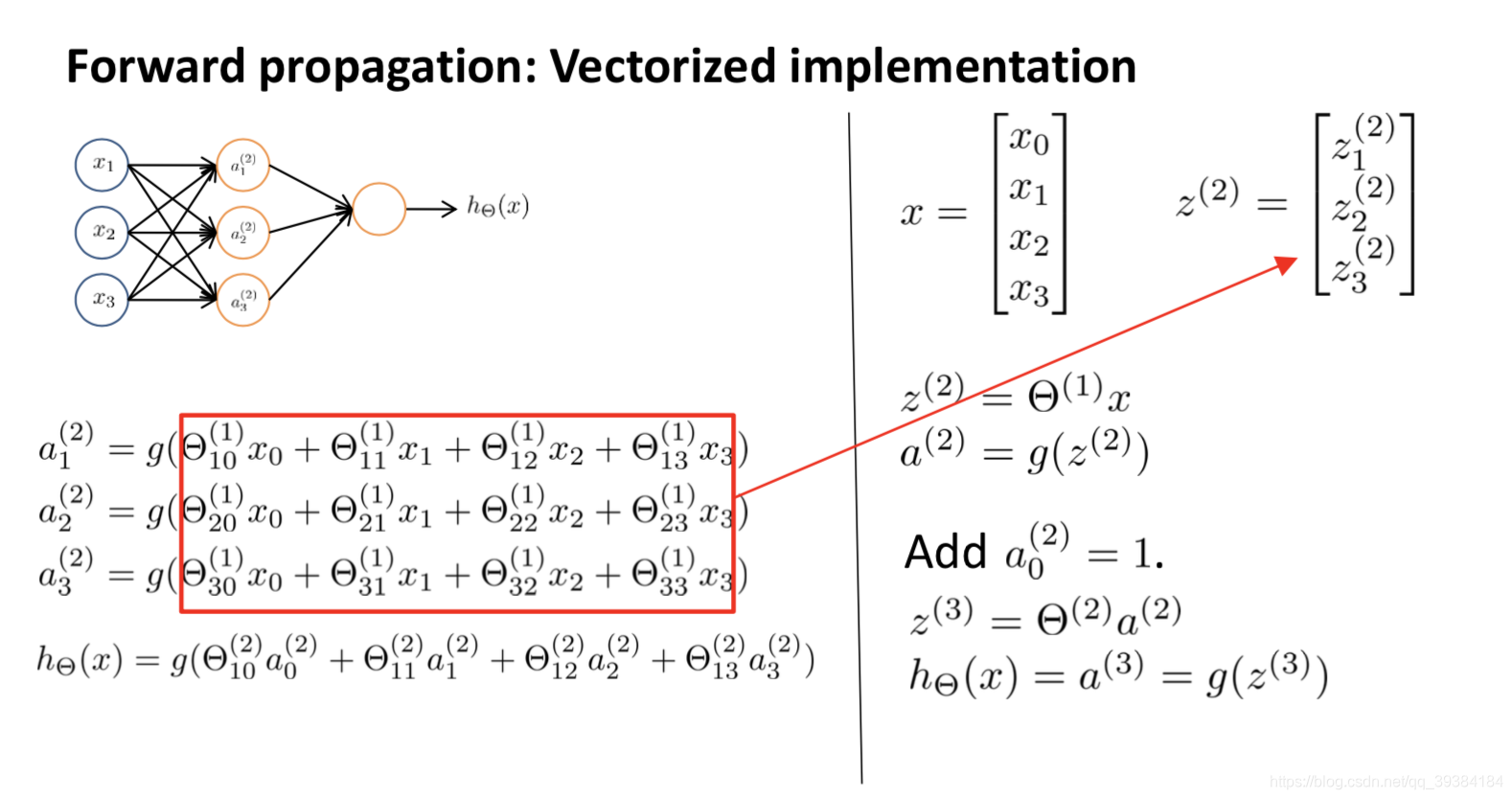
神经网络所做的事情实际上就是逻辑回归,只不过不是以 x1、……、xn 为特征,而是用 a1、……、an 作为新的特征。a1、……、an 是学习得到的函数输入值,这样就可以学习到一些很有趣和复杂的特征,就可以得到一个更好的假设函数。
示例
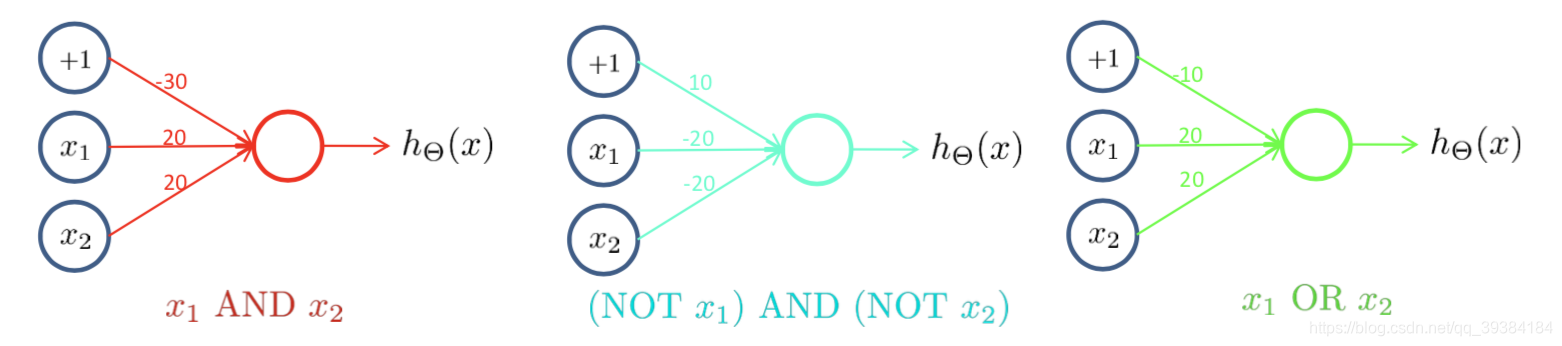
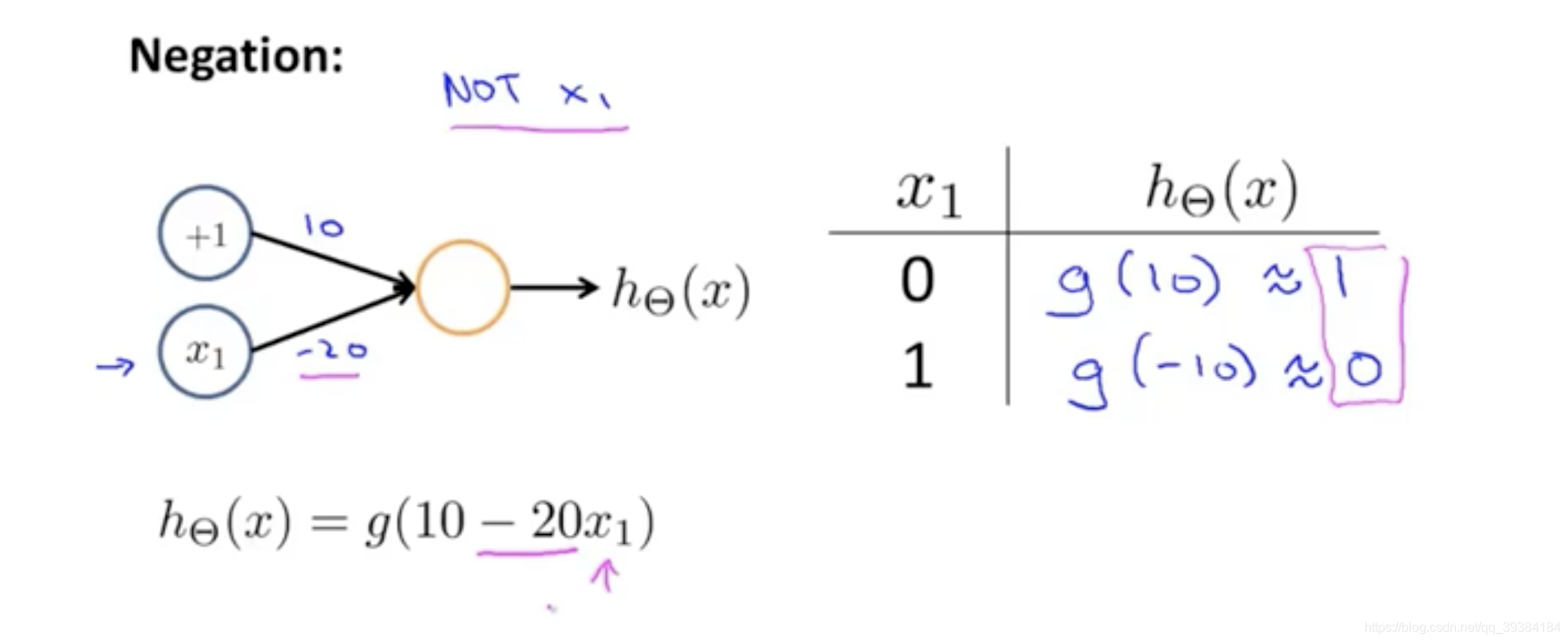
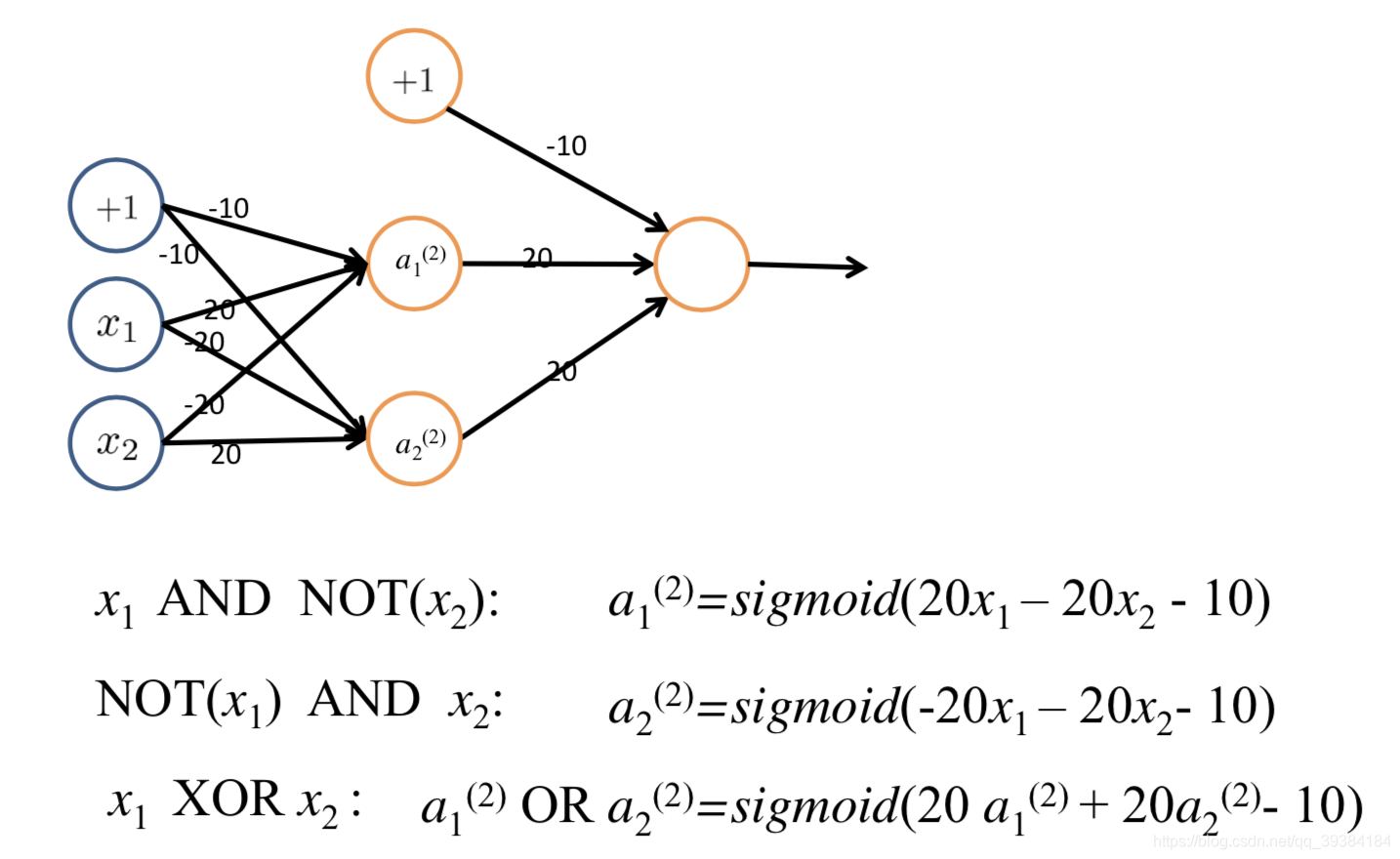
多元分类
代价函数
和逻辑回归相似。

反向传播算法
正向传播

反向传播
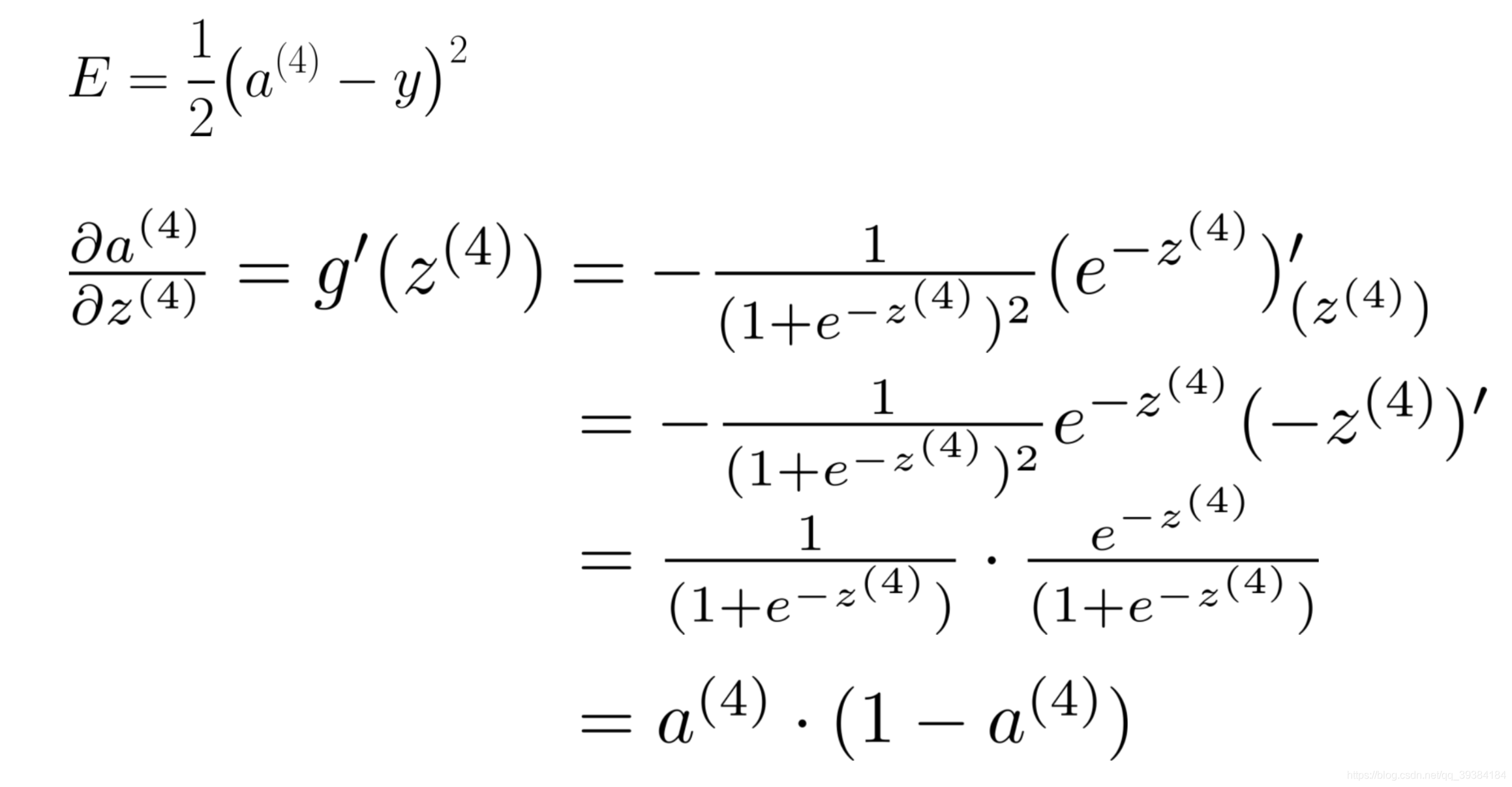


梯度检测
为何进行梯度检验?
神经网络算法使用反向传播计算目标函数关于每个参数的梯度,可以看做解析梯度。由于计算过程中涉及到的参数很多,反向传播计算的梯度很容易出现误差,导致最后迭代得到效果很差的参数值。
为了确认代码中反向传播计算的梯度是否正确,可以采用梯度检验(gradient check)的方法。通过计算数值梯度,得到梯度的近似值,然后和反向传播得到的梯度进行比较,若两者相差很小的话则证明反向传播的代码是正确无误的。



一旦通过检验确定反向传播的实现是正确的,就应该关掉梯度检测,否则程序运行的速度就会非常慢。
随机初始化
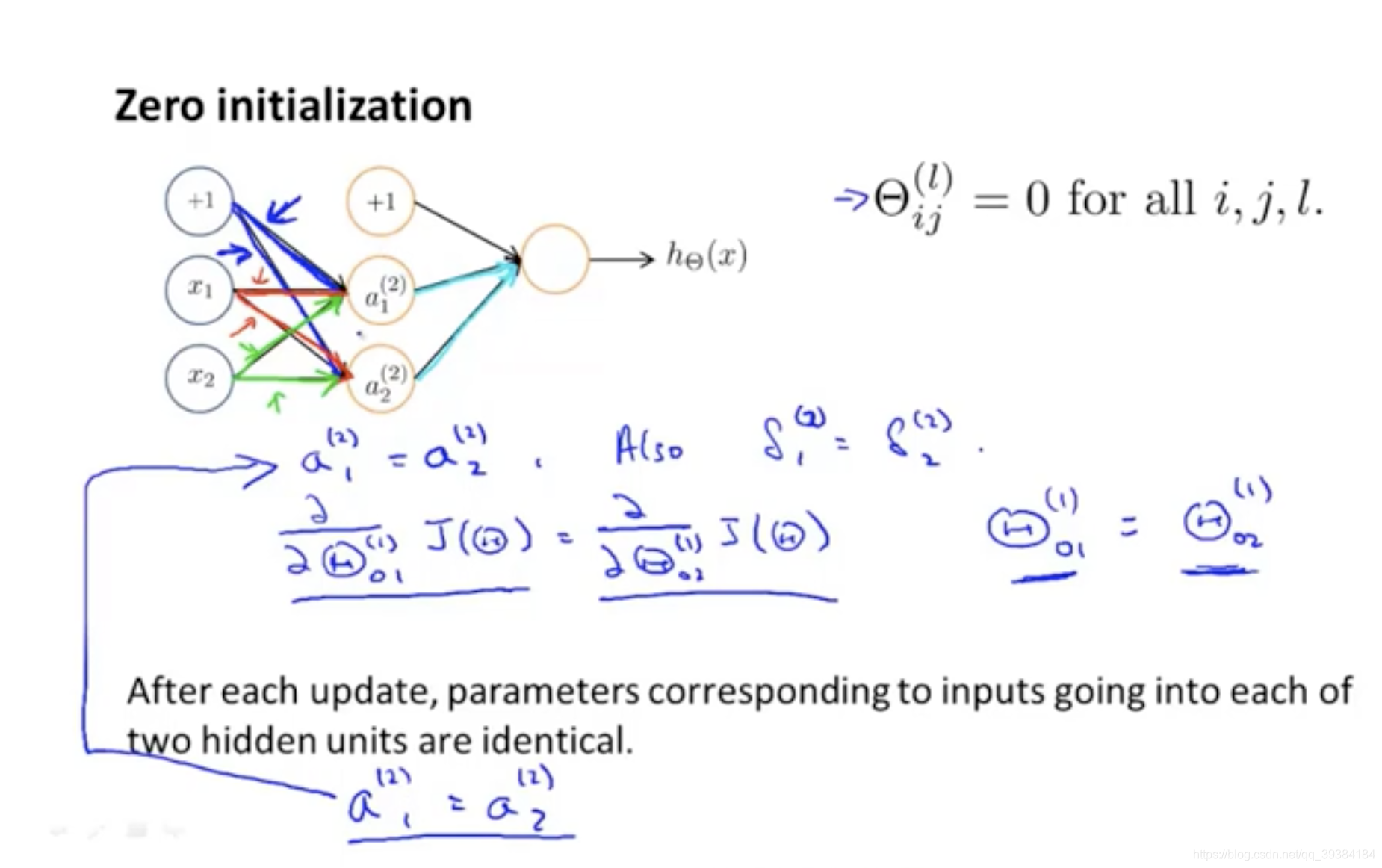
如果没有随机初始化,θ 都初始化为 0,每次更新后,进入两个隐藏单元的输入对应的参数是相同的,那么每个节点到下一层节点的权重都是相同的。

训练神经网络


对于神经网络,代价函数 J(θ) 不是一个凸函数,因此理论上可能停留在局部最小值的位置。
模型评估与选择
假设空间
假设空间(hypothesis space):由输入空间到输出空间的映射的集合。将学习过程看作一个在所有假设组成的空间中进行搜索的过程,搜索目标是找到与训练集"匹配"的假设。与训练集一致的"假设集合”称为版本空间(version space)。
归纳偏好
归纳偏好(inductive bias):机器学习算法在学习过程中对某种类型假设的偏好。
任何一个有效的机器学习算法必有其归纳偏好,否则它将被假设空间中看似在训练集上"等效"的假设所迷惑,而无法产生确定的学习结果。归纳偏好可看作学习算法自身在一个可能很庞大的假设空间中对假设进行选择的启发式或"价值观"。
奥卡姆剃刀(Occam’s razor):是一种常用的、自然科学 研究中最基本的原则,即"若有多个假设与观察一致,则选最简单的那个"。并且我们认为"更平滑"意味着"更简单"。
典型的归纳偏好
- 最大条件独立性
- 最小交叉验证误差
- 最大间隔(Maximum Margin)
- 最小描述长度(Minimum description length,奥卡姆剃刀)。
- 最少特征数
- 最近邻居
经验误差与过拟合
通常我们把分类错误的样本数占样本总数的比例称为"错误率"(error rate),即如果在m个样本中有α个样本分类错误,则错误率E=α/m;相应的,1一α/m称为"精度"(accuracy),即"精度=1一错误率"。
经验误差(empirical error):我们把学习器的实际预测输出与样本的真实输出之间的差异称为"误差"(error),学习器在训练集上的误差称为"训练误差"(training error)或"经验误差",在新样本上的误差称为"泛化误差"(generalization error).
过拟合(over fitting):应该从训练样本中尽可能学出适用于所有潜在样本的"普遍规律",这样才能在遇到新样本时做出正确的判别。但是把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降,这种现象在机器学习中称为"过拟合"。与"过拟合"相对的是"欠拟合" (under fitting),这是指对训练样本的一般性质尚未学好。
评估方法
评估方法:们可通过实验测试来对学习器的泛化误差进行评估并进而做出选择。为此,需使用一个"测试集"(testing set)来测试学习器对新样本的判别能力,然后以测试集上的"测试误差" (testing error)作为泛化误差的近似。
通常我们假设测试样本也是从样本真实分布中独立同分布采样而得,但需注意的是,测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现、未在训练过程中使用过。
留出法(hold-out):直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即D=S∪T,S∩T=∅。在S上训练出模型后,用T来评估其测试误差,作为对泛化误差的估计。
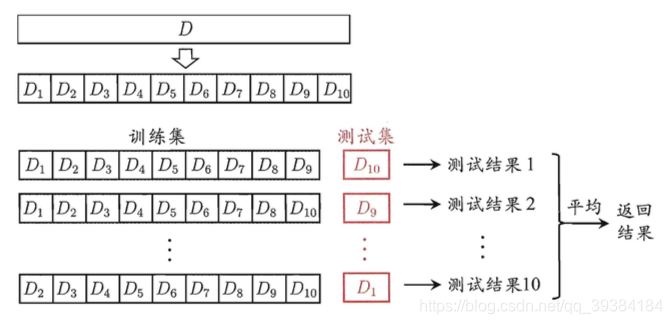
交叉验证法(cross validation):先将数据集D划分为k个大小相似的互斥子集,即D=D1∪D2∪…∪Dk,Di∩Dj=∅(i≠j)。 每个子集Di都尽可能保持数据分布的一致性,即从D中通过分层采样得到。然后,每次用k-1个子集的并集作为训练集,余 F的那个子集作为测试集;这样就可获得k组训练/测试集,从而可进行k次训练和测试,最终返回的是这k个测试结果的均值。显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于 k的取值,为强调这一点,通常把交叉验证法称为"k折交叉验证"(k-fold cross validation)。k最常用的取值是 10,此时称为10折交叉验证;其他常用的k值有5、20等。
- 10折交叉验证示意图
自助法(bootstrapping):给定包含m个样本的数据集D, 我们对它进行采样产生数据集D’:每次随机从D中挑选一个 样本,将其拷贝放入D’,然后再将该样本放回初始数据集D中,使得该样本在 次采样时仍有可能被采到;这个过程重复执行 m 次后,我们就得到了包含m个样本的数据集D’,这就是自助采样的结果。显然,D中有一部分样本会在D’中多次出现,而另一部分样本不出现。可以做一个简单的估计,样本在m次采样中始终不被采到的概率是(1一1/m)^m,取极限得到
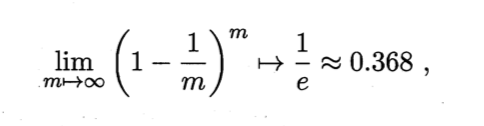
即通过自助采样,初始数据集D中约有36.8%的样本未出现在采样数据集D’中。于是我们可将D’用作训练集,D\D’用作测试集;这样实际评估的模型与期望评估的模型都使用m个训练样本,而我们仍有数据总量约1/3的、没在训练集中出现的样本用于测试。这样的测试结果,亦称"包外估计"(out-of-bag estimate)。
自助法在数据集较小、难以有效划分训练集和测试集时很有用;此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大的好处。然而,自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差。因此,在初始数据量足够时,留出法和交叉验证法更常用一些。
大多数学习算法都有些参数(parameter)需要设定,参数配置不同,学得模型的性能往往有显著差别。因此,在进行模型评估与选择时,除了要对适用学习算法进行选择,还需对算法参数进行设定,这就是通常所说的"参数调节"或简称"调参"(parameter tuning).
我们通常把学得模型在实际使用中遇到的数据称为测试数据,为了加以区分,模型评估与选择中用于评估测试的数据集常称为"验证集" (validation set)。例如,在研究对比不同算法的泛化性能时,我们用测试集上的判别效果来估计模型在实际使用时的泛化能力,而把训练数据另外划分为训练集和验证集,基于验证集上的性能来进行模型选择和调参。
性能度量
性能度量(performance measure):对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量。
回归任务最常用的性能度量是"均方误差"(mean squared error),逻辑回归为"交叉熵”(Cross Entropy)。
查准率(precision)与查全率(recall)是更为适用的性能度量。两者分别定义为:
- P=TP/(TP+FP)
- R=TP/(TP+FN)
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)四种情形,令TP、FP、TN、FN分别表示其对应的样例数,则显然有TP+FP+TN+FN=样例总数。
- 混淆矩阵

综合考虑查准率、查全率的性能度量:
-
平衡点(Break-EventPointBEP):它是"查准率=查全率"时的取值。
-
F1 度量:F1=2PR/(P+R)
-
Fβ 度量:F1= ( 1 + β 2 ) P R / ( β 2 P + R ) (1+β^2)PR/(β^2P+R) (1+β2)PR/(β2P+R),β>1时查全率有更大影响,β<1查准率有更大影响。
-
PR曲线与平衡点示意图

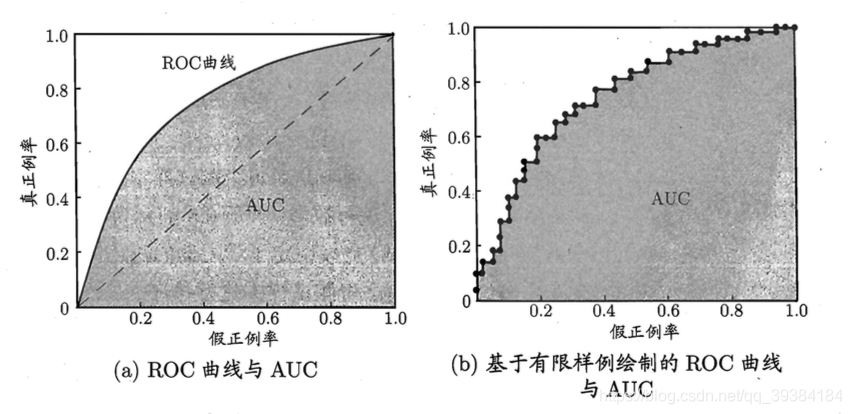
受试者工作特征曲线(Receiver Operating Characteristic curve,ROC):ROC曲线的纵轴是"真正 例率"(True Positive Rate,TPR),横轴是"假正例率"(False Positive Rate,FPR),两者分别定义为:
- TPR=TP/(TP+FN)
- FPR=FP/(TN+FP)
若一个学习器的ROC曲线被另一个学习器的曲线完全"包住",则可断言后者的性能优于前者;则较为合理的判据是比较ROC曲线下的面积,即AUC(Area Under ROC Curve),AUC表示分类器接受true样本高于接受false样本的概率。AUC取值在0~1之间,AUC值越大的分类器,正确率越高。
- ROC 曲线与 AUC 示意图
代价敏感(cost-sensitive)错误率为:
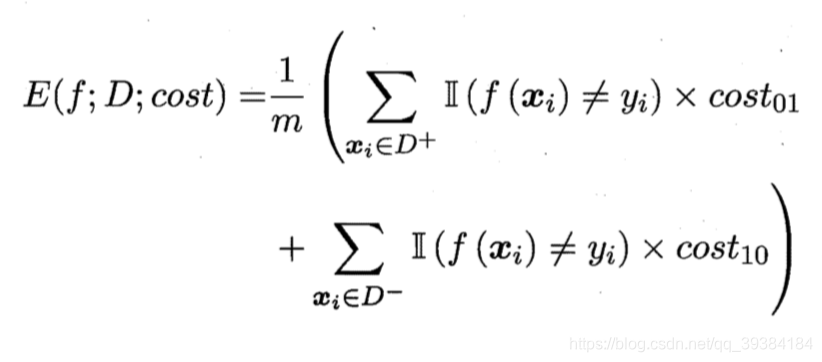
- 代价矩阵(cost matrix,其中 costij 表示将第 i 类样本预测为第 j 类样本的代价)
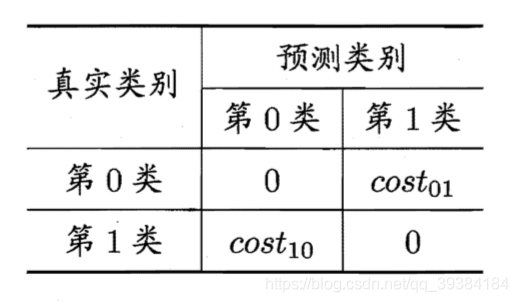
- 正例概率代价(取值[0,1])
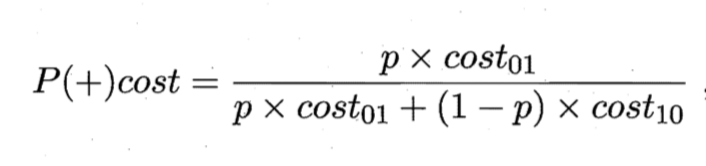
- 归一化代价(取值[0,1])
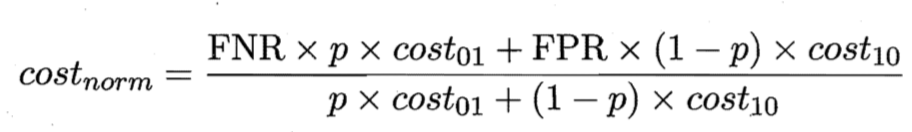
其中 p 是样例为正例的概率,FPR 是假正例率,FNR=1 -TPR是假反例率。
ROC曲线上每一点对应了代价平面上的一条线段。
- 代价曲线和期望总体代价
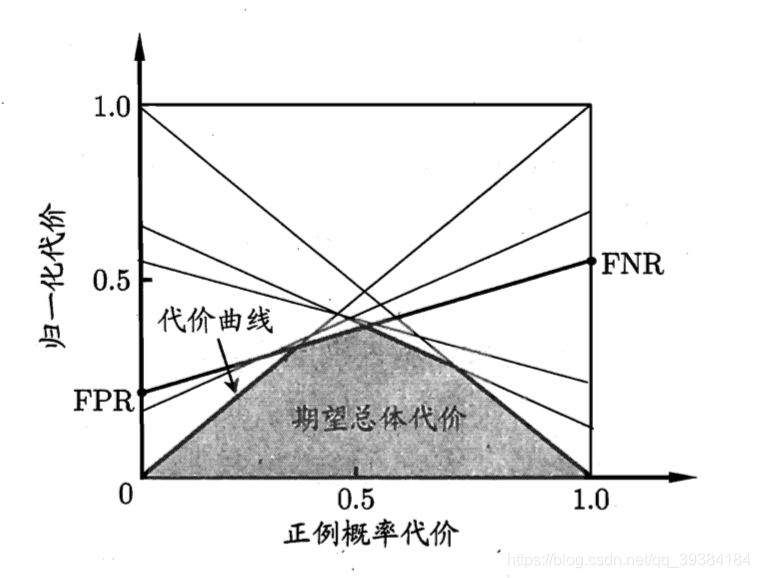
设 ROC 曲 线上点的坐标为(TPR,FPR),则可相应计算出FNR,然后在代价平面上绘制一条从(O,FPR)到(1,FNR)的线段,线段下的面积即表示了该条件下的期望总体代价;如此将ROC曲线上的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的自积即为在所有条件下学习器的期望总体代价。
比较检验
统计假设检验(hypothesis test)为我们进行学习器性能比较提供了重要依据。基于假设检验结果我们可推断出,若在测试集上观察到学习器A比B好,则A的泛化性能是否在统计意义上优于B,以及这个结论的把握有多大。
- 二项检验:泛化错误率为 c 的学习器在 m 个测试样本中将 m’ 个样本误分类的概率服从二项分布。
- 交叉验证 t 检验:对两个学习器 A 和 B ,若错误率相同,则使用 k 折交叉验证法得到的测试错误率cAi-cBi的差均值为零,服从 t 分布。
偏差与方差
偏差方差分解(bias-variance decomposition)是解释学习算法泛化性能的一种重要工具。


泛化误差可分解为偏差、方差与噪声之和。
一般来说,偏差与方差是有冲突的,这称为偏差一方差窘境(bias-variance dilemma)。
假定我们能控制学习算法 的训练程度,则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的特性被学习器学到了,则将发生过拟合。
- 泛化误差与偏差、方差的关系示意图
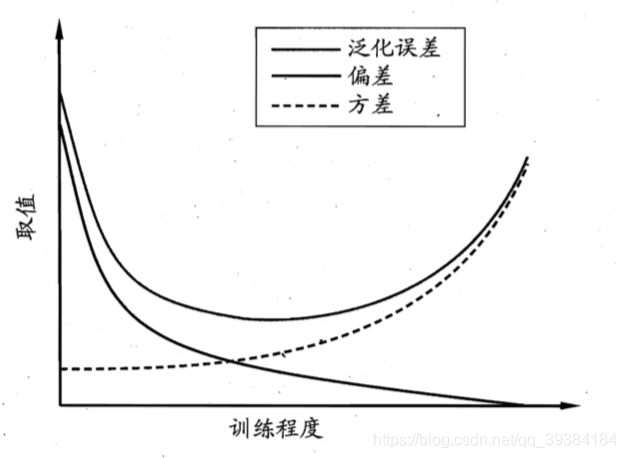
偏差(欠拟合)、方差(过拟合)
- 从偏差和方差角度看,很难同时追求最优。
- 从统计学习理论角度:
- 低偏差代表经验风险最小化
- 低方差代表结构风险最小化
正则化和偏差、方差
根据验证集选择 λ:
- λ过大:偏差高(欠拟合)
- λ过小:方差高(过拟合)
学习曲线

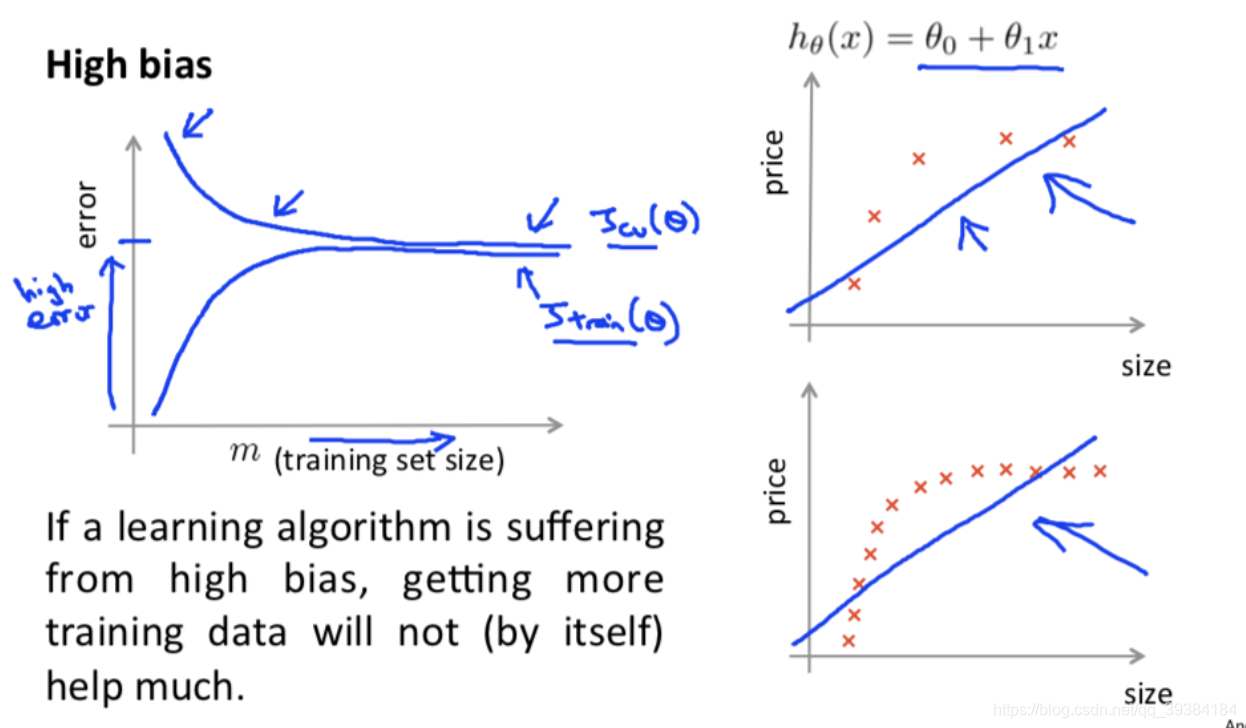
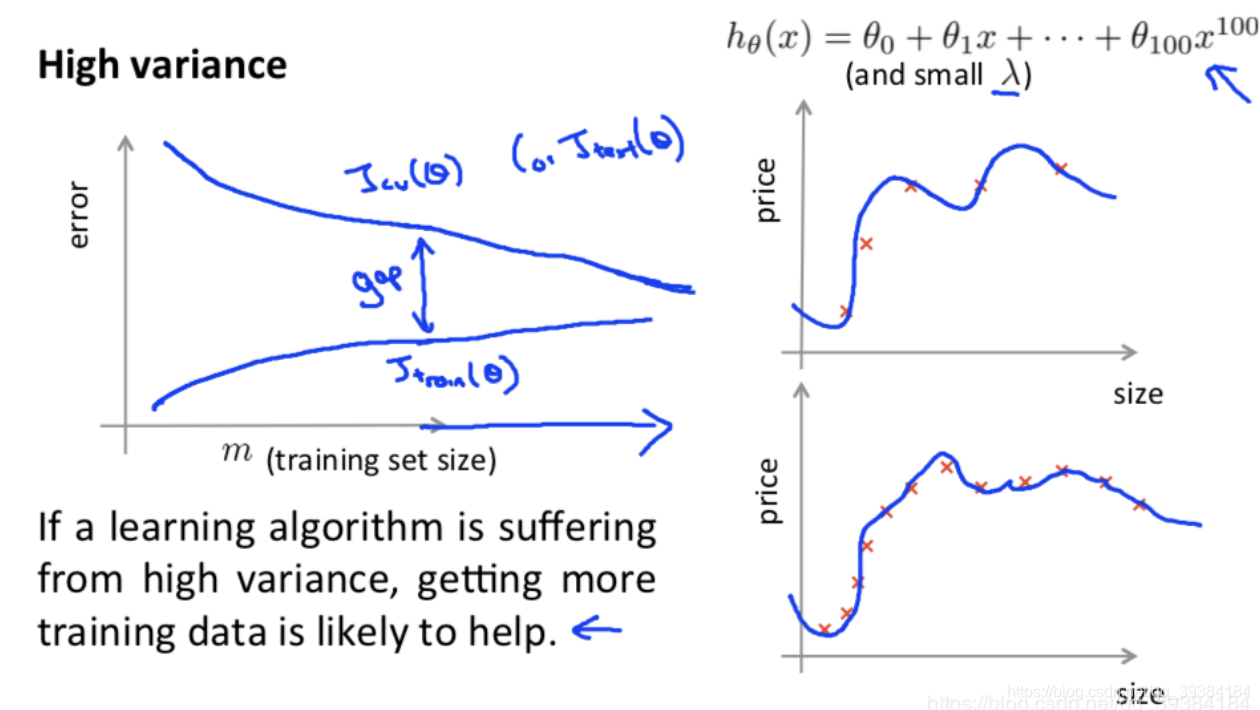
总结
通过画出学习曲线和检验误差来判断算法是否存在高偏差或者高方差的问题,再决定是否使用更多的数据或者特征。

机器学习数据
- 参数多,特征值多的假设模型可以得到低偏差
- 很大的测试集可以得到低方差
统计学习理论
统计学习的三要素
- 模型
- 策略
- 算法
支持向量机
优化目标
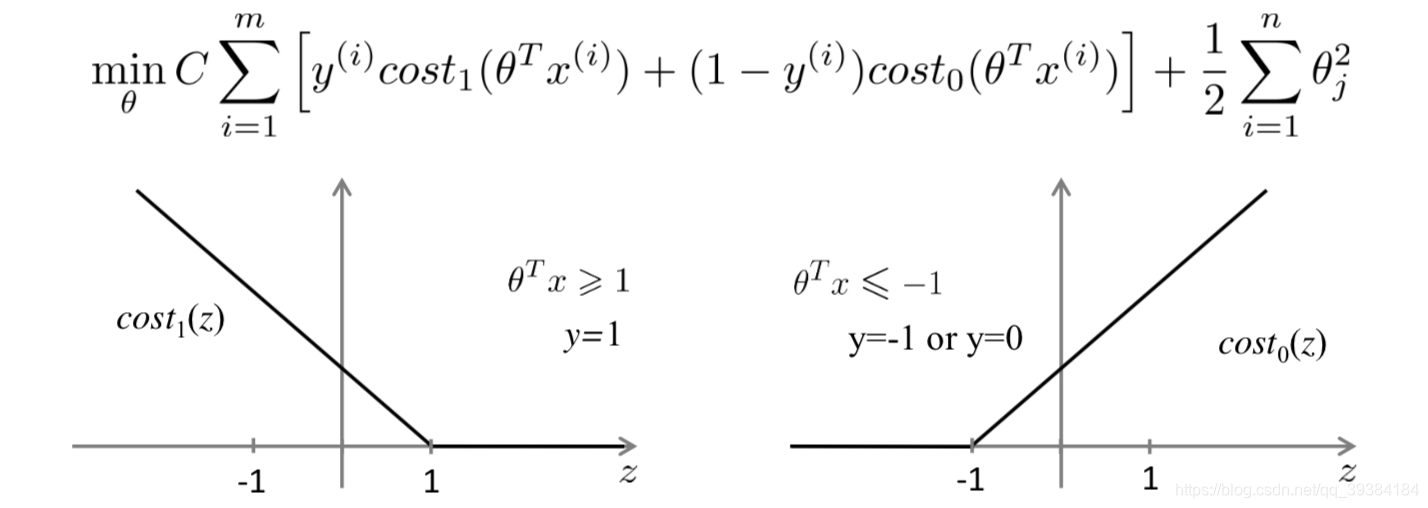
间隔与支持向量
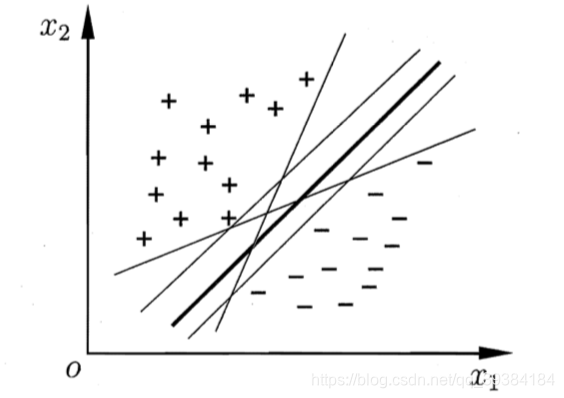


如上图所示,距离超平面最近的这几个训练样本点使式(6.3)的等号成立,它们被称为"支持向量"(support vector),两个异类支持向量到超平面的距离之和为:
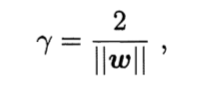
它被称为"间隔"(margin)。
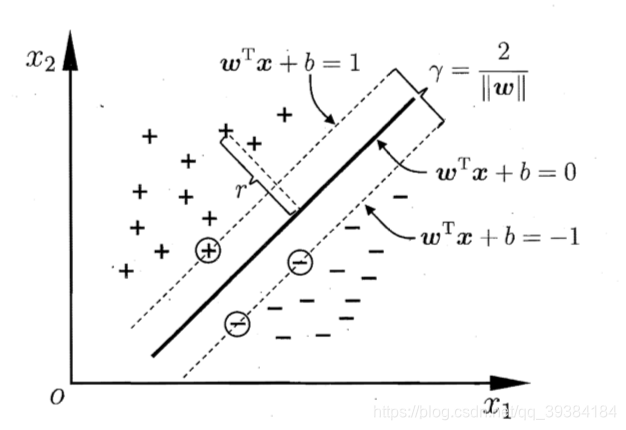
直观上对大间隔的理解
要想优化损失函数,不仅需要大于 0,更需要大于 1 才可以。
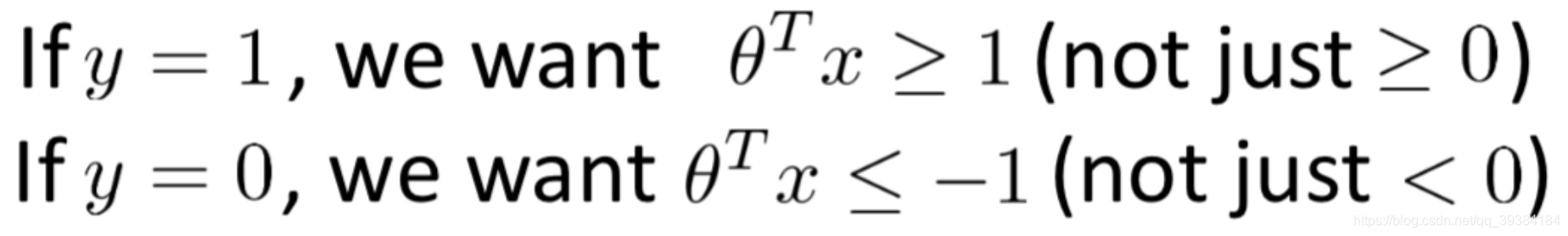
大间隔的数学原理
间隔越大,X 到 θ 的投影越大,损失函数越小。
核函数
对线性不可分问题,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分。
令φ(x)表示将x映射后的特征向量,可以设想这样一个函数:
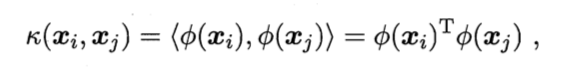
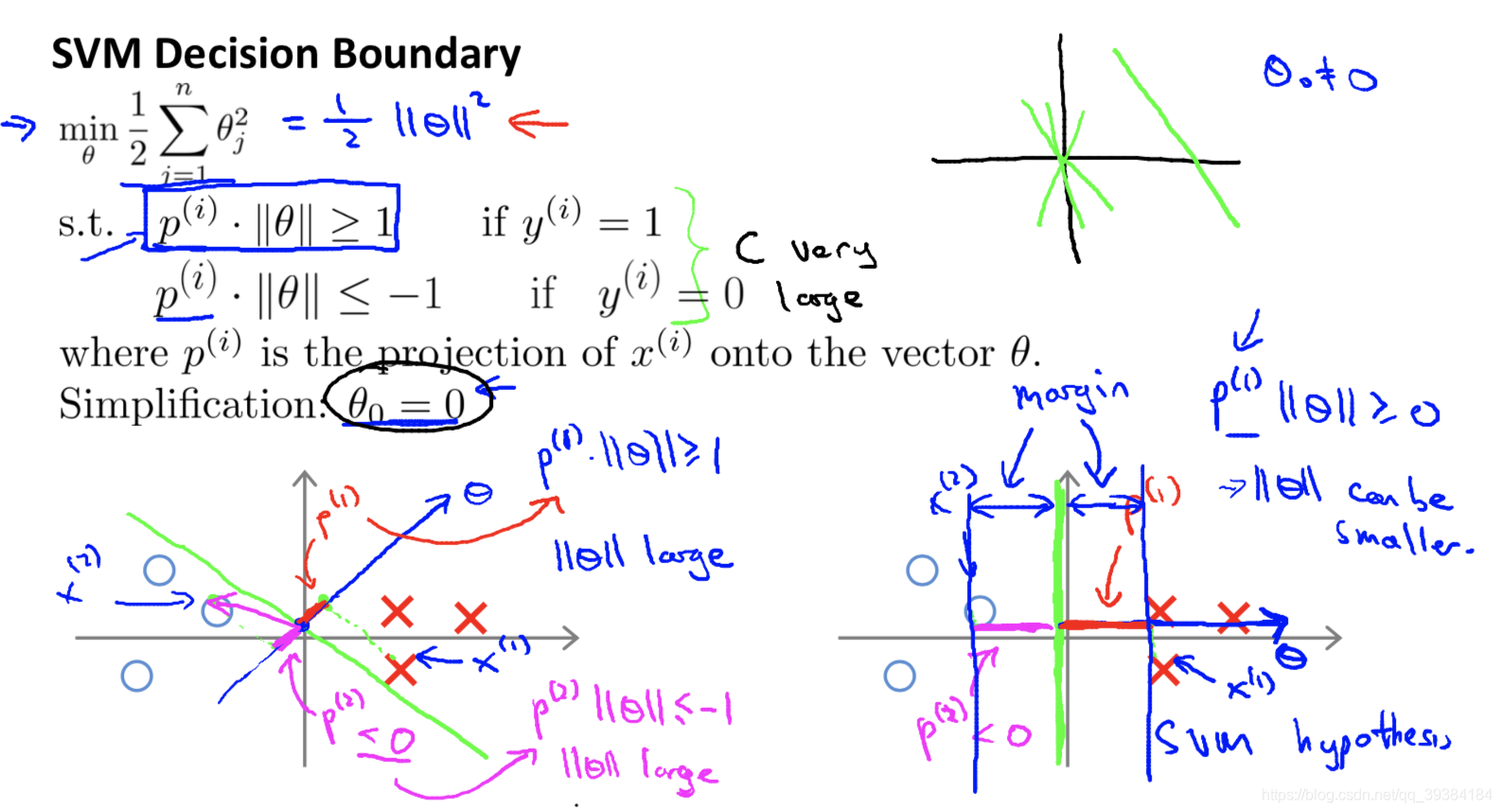
有了这样的函数,我们就不必直接去计算高维甚至无穷维特征空间中的内积。这个函数就是核函数(kernel function)。
- 常用核函数

- 选择标记点(样本)
- 使用高斯核函数
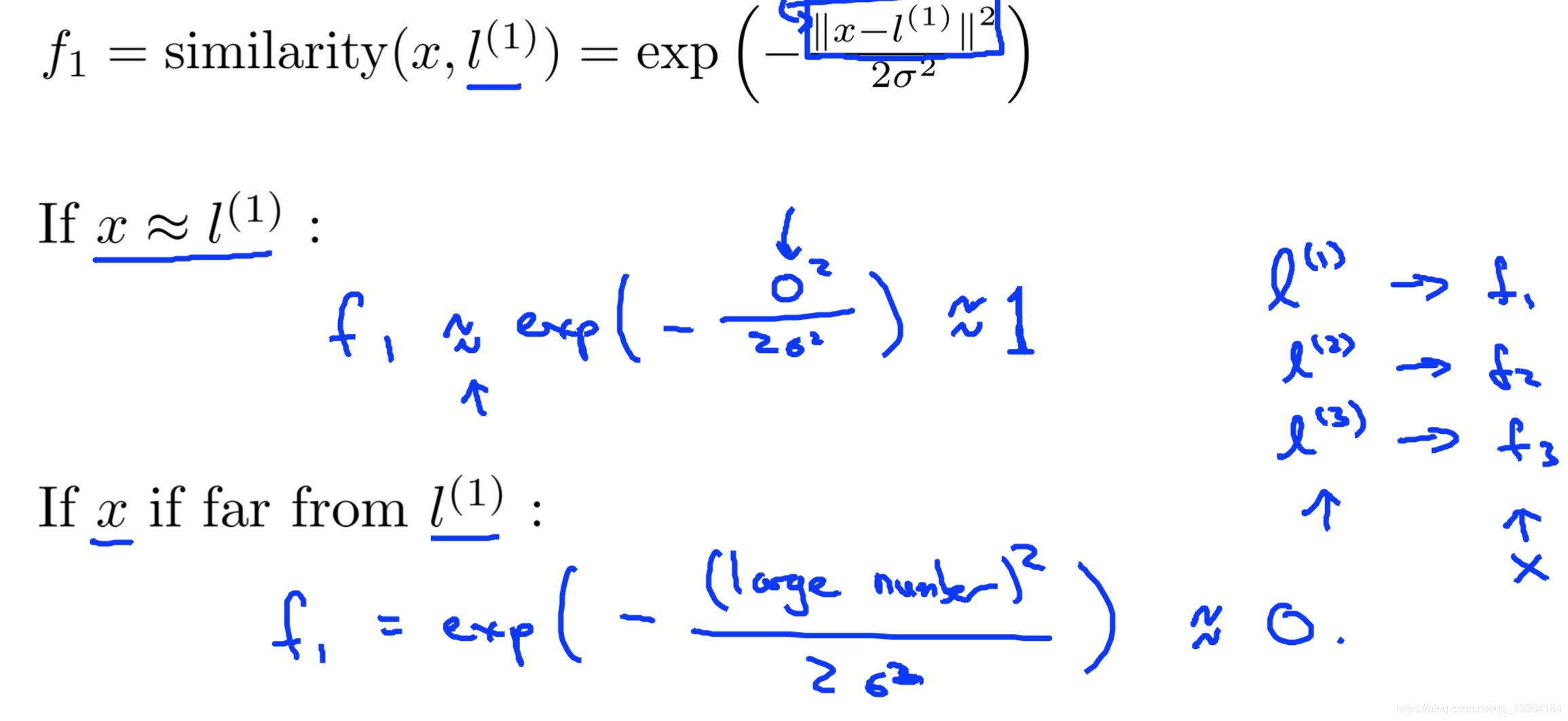
- 使用核函数的 SVM 的损失函数
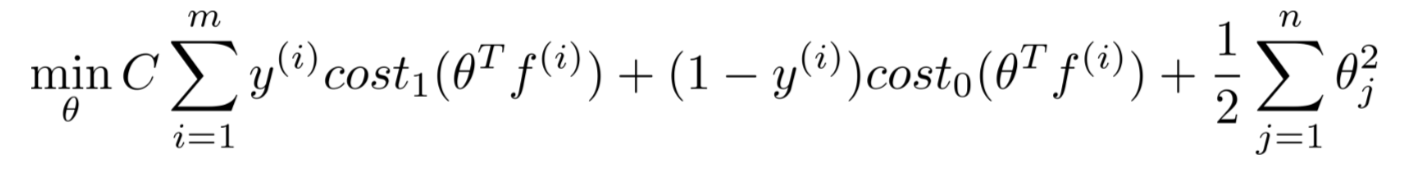
偏差方差折中
C=1/λ
- C 越大(λ越小):低偏差,高方差(过拟合)
- C 越小(λ越大):高偏差,低方差(欠拟合)
σ^2
- σ^2 越大,f 越平缓,高偏差,低方差(欠拟合)
- σ^2 越小,f 不平缓,低偏差,高方差(过拟合)
使用 SVM
- 选择 C
- 选择核函数(符合默瑟定理,Mercer’s Theorem)
- 高斯核函数
- 线性核函数(无核函数)
- 多项式核函数
- 字符串核函数
- 卡方核函数
- 直方相交核函数
SVM 和逻辑回归的选择
N 个特征,M 个样本
- N 对于 M 很大:逻辑回归或者无核 SVM
- N 很小,M 适中:高斯核 SVM
- N 很小,M 很大:增加更多的特征,然后使用逻辑回归或者无核 SVM
SVM 不需要解决局部最优的问题,神经网络可以解决几乎所有的问题,但是训练速度比 SVM 慢。
其他
软间隔与正则化
在现实任务中往往很难确定合适的核函数使得训练样本在特征空间中线性可分;即使恰好找到了某个核函数使训练集在特征空间中线性可分,也很难断定这个貌似线性可分的结果不是由于过拟合所造成的。
所有样本都必须划分正确,这称为"硬间隔"(hard margin),而"软间隔”(soft margin)则是允许某些样本不满足约束。当然,在最大化间隔的同时,不满足约束的样本应尽可能少。
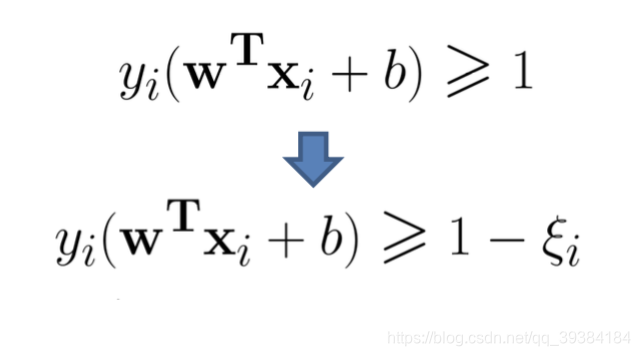
支持向量回归
对样本(x,y)的传统回归模型通常直接基于模型输出 f(x) 与真实输出 y 之间的差别来计算损失,当且仅当 f(x) 与 y 完全相同时,损失才为零。与此不同,支持向量回归(Support Vector Regression,SVR)假设我们能容忍 f(x) 与 y 之间最多有 e 的偏差,即仅当 f(x) 与 y 之间的差别绝对值大于 e 时才计算损失。
- 传统回归:f(x)与y完全相等时损失为0;
- SVR: f(x)与y的差异大于一定值时才计算损失,落入间隔带中不计算损失。
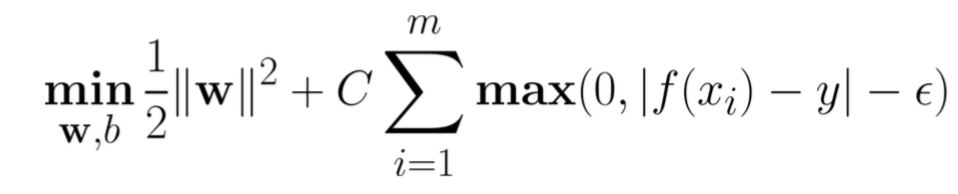
网络机器学习
PageRank核心思想


PageRank算法
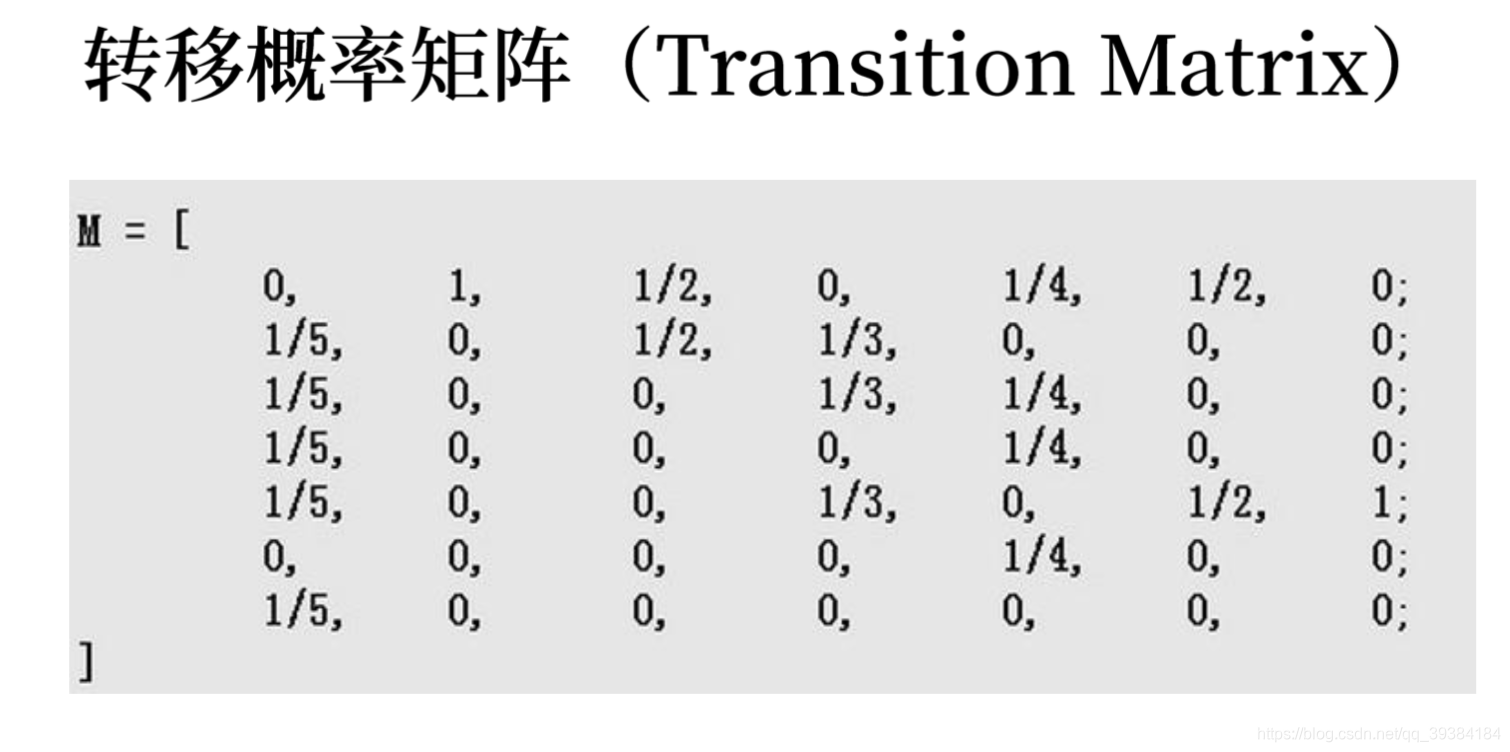
PageRank算法总的来说就是预先给每个网页一个PR值(下面用PR值指代PageRank值),由于PR值物理意义上为一个网页被访问概率,所以一般是 1 N \frac{1}{N} N1,其中N为网页总数。另外,一般情况下,所有网页的PR值的总和为1。如果不为1的话也不是不行,最后算出来的不同网页之间PR值的大小关系仍然是正确的,只是不能直接地反映概率了。
所以PageRank算法实际上就是预先给定PR值后,通过每个网页之间的链接关系不断迭代,直至达到平稳分布为止。
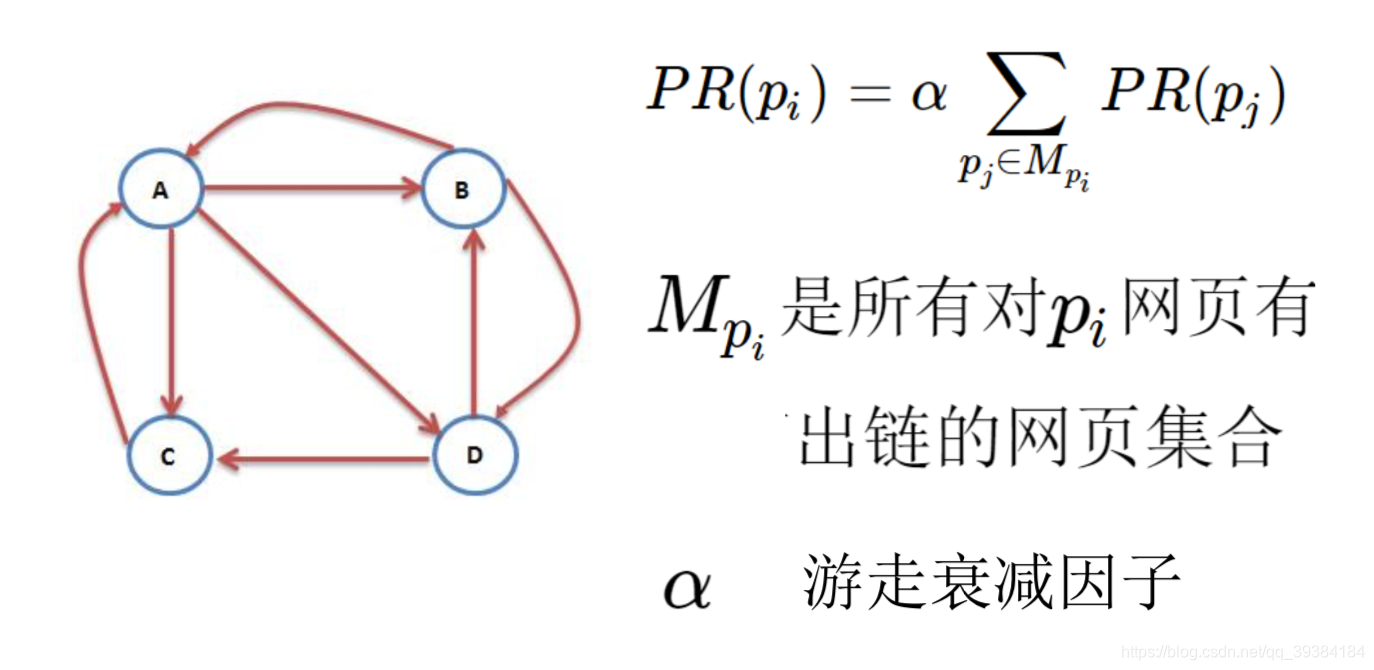
各个网页的PR值之间的关系一般情况下表示为如下的式子:
P R ( p i ) = α ∑ p j ∈ M p i P R ( p j ) L ( p j ) + ( 1 − α ) N \LARGE PR(p_i)=α\sum_{p_j∈M_{p_i}}\frac{PR(p_j)}{L(p_j)}+\frac{(1-α)}{N} PR(pi)=α∑pj∈MpiL(pj)PR(pj)+N(1−α)
其中 M p i M_{p_i} Mpi是所有对 p i p_i pi网页有出链的网页集合; L ( p j ) L(p_j) L(pj)是网页的出链数目; N N N是网页总数; α α α是阻尼系数,即用户离开当前网页重新输入网址访问的概率,一般取0.85。
根据这一关系不断迭代,当算法收敛的时候,得到的PR值即使每个网页的PR排序值。
PageRank随机游走
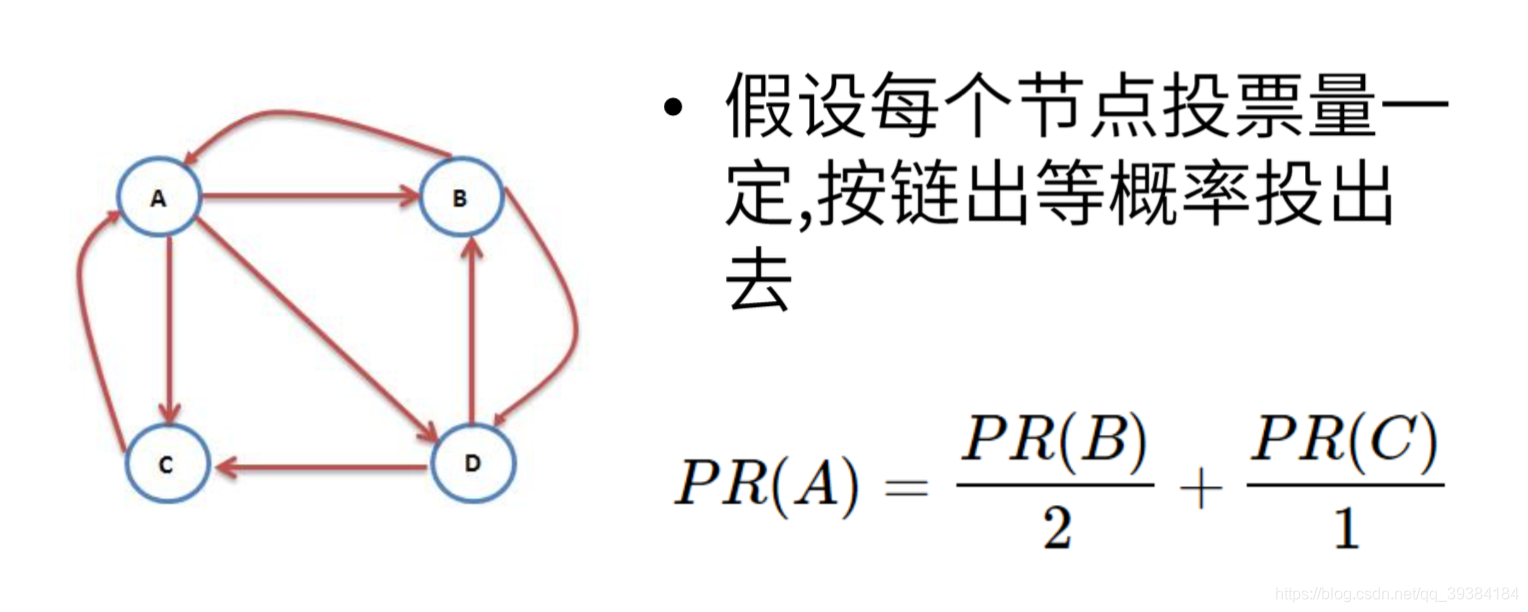
PageRank计算举例


随机游走算法
随机游走算法的基本思想是,从一个或一系列顶点开始遍历一张图。在任意一个顶点,遍历者将以概率1-a游走到这个顶点的邻居顶点,以概率a随机跳跃到图中的任何一个顶点,称a为跳转发生概率,每次游走后得出一个概率分布,该概率分布刻画了图中每一个顶点被访问到的概率。用这个概率分布作为下一次游走的输入并反复迭代这一过程。当满足一定前提条件时,这个概率分布会趋于收敛。收敛后,即可以得到一个平稳的概率分布。随机游走模型广泛应用于数据挖掘和互联网领域,PageRank算法可以看作是随机游走模型的一个实例。
重启随机游走算法
重启随机游走算法是在随机游走算法的基础的改进。从图中的某一个节点出发,每一步面临两个选择,随机选择相邻节点,或者返回开始节点。算法包含一个参数a为重启概率,1-a表示移动到相邻节点的概率,经过迭代到达平稳,平稳后得到的概率分布可被看作是受开始节点影响的分布。重启随机游走可以捕捉两个节点之间多方面的关系,捕捉图的整体结构信息。
其他的例子
- 论文权威程度(SCI 影响因子)
- 治病基因预测
聚类
性能度量
聚类性能度量亦称聚类"有效性指标"(validity index),与监督学习中的性能度量作用相似。
我们希望"物以类聚",即同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。换言之,聚类结果的"簇内相似度"(intra-cluster similarity)高且"簇间相似度"(inter-cluster similarity)低。
聚类性能度量大致有两类。一类是将聚类结果与某个"参考模型"(reference model)进行比较,称为"外部指标"(external index);另一类是直接考察聚类结果而不利用任何参考模型,称为"内部指标"(internal index)。
- 外部指标
- Jaccard 指数
- FM 指数
- Rand 指数
- 内部指标
- DB 指数
- Dunn 指数
距离计算
对函数dist(.,.),若它是一个"距离度量"(distance measure),则需满足一些基本性质:
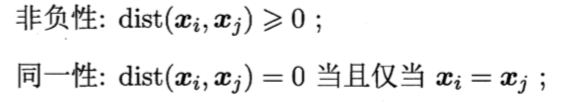
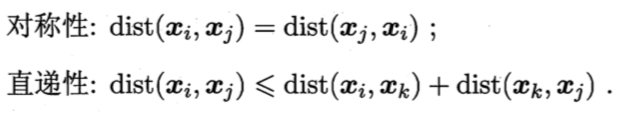
- 闵可夫斯基距离(Minkowski distance)
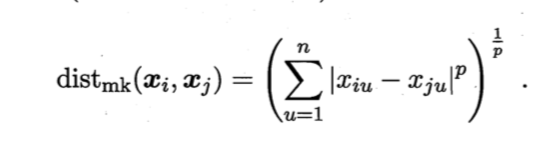
- 欧氏距离(Euclidean distance)

- 曼哈顿距离 (Manhattan distance)
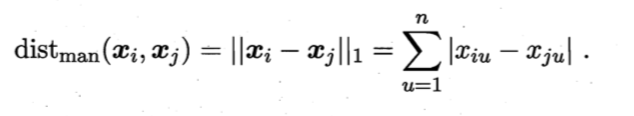
K-means算法

优化目标

随机初始化

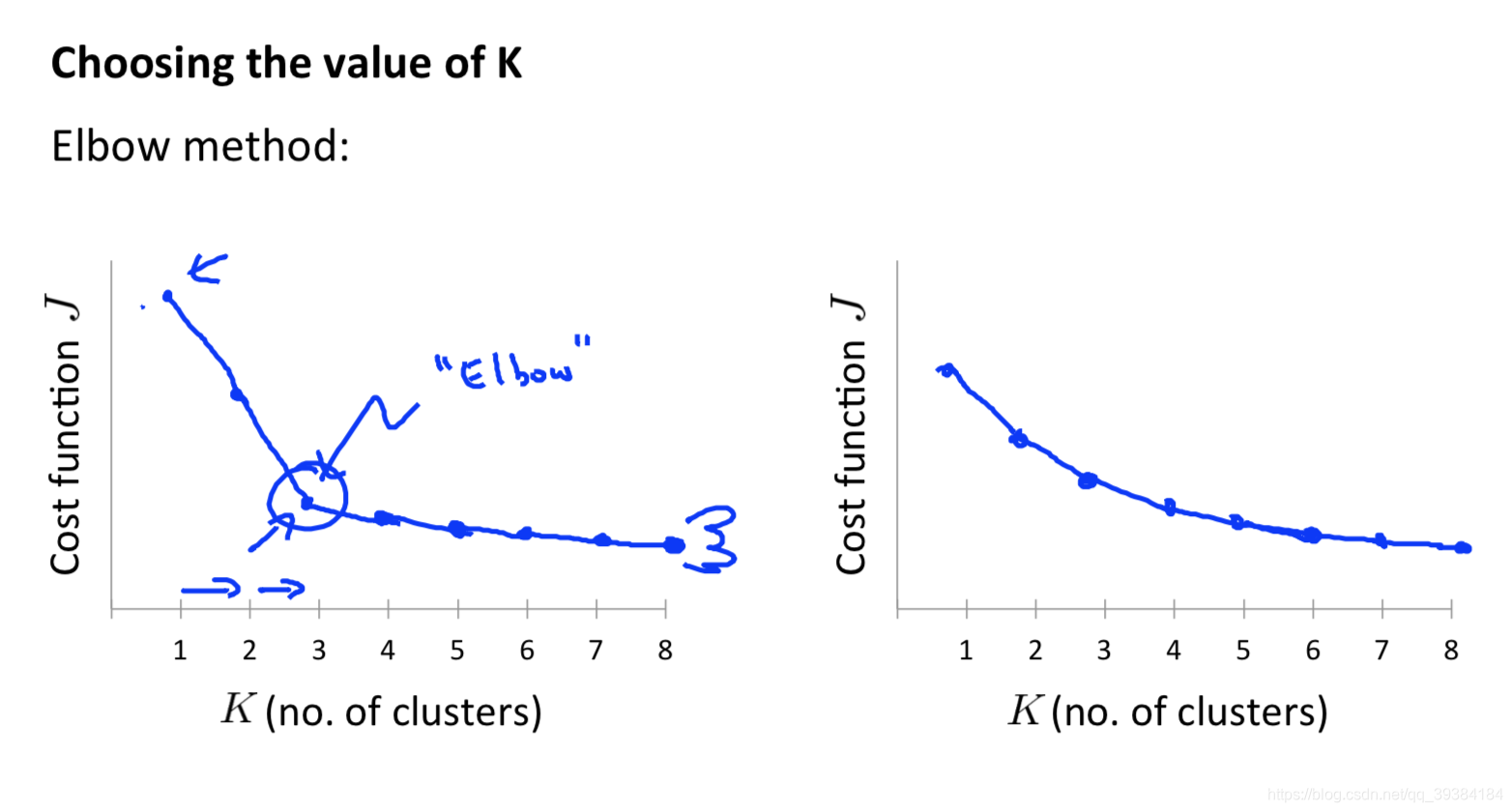
选取聚类数量
肘部方法
其他聚类算法
- 原型聚类(基于原型的聚类)
- k 均值(k-means)
- 学习向量化(Learning Vector Quantization,LVQ)
- 高斯混合聚类(Mixture-oι Gaussian)
- 密度聚类(基于密度的聚类)
- DBSCAN
- 层次聚类(基于层次的聚类)
- AGNES
贝叶斯分类器
贝叶斯决策论



极大似然估计
概率模型的训练过程就是参数估计(parameter estimation)过程。对于参数估计,统计学界的两个学派分别提供了不同的解决方案:频率主义学派(Frequentist)认为参数虽然未知,但却是客观存在的固定值,因此,可通过优化似然函数等准则来确定参数值;贝叶斯学派(Bayesian)则认为参数是未观察到的随机变量,其本身也可有分布,因此,可假定参数服从一个先验分布,然后基于观测到的数据来计算参数的后验分布。
朴素贝叶斯分类器
朴素贝叶斯分类器(naive Bayes classifier)采用了"属性条件独立性假设"(attribute conditional independence assumption):对已知类别,假设所有属性相互独立。换言之,假设每个属性独立地对分类结果发生影响。
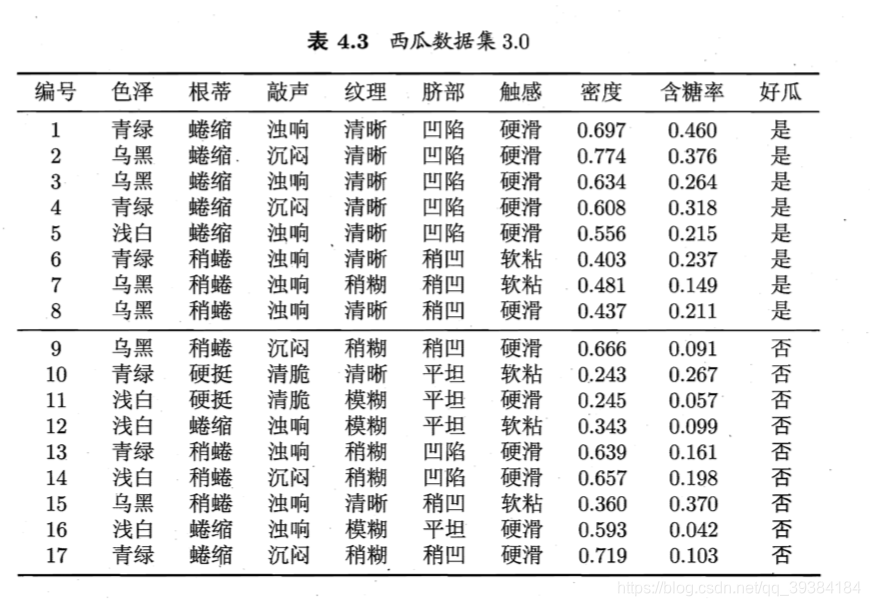





显然,拉普拉斯修正(Laplacian correction)避免了因训练集样本不充分而导致概率估值为零的问题,并且在训练集变大时,修正过程所引入的先验(prior)的影响也会逐渐变得可忽略,使得估值渐趋向于实际概率值。
贝叶斯网
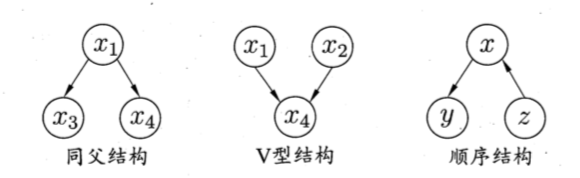
贝叶斯网(Bayesian network)亦称"信念网"(belief network),它借助有向无环图(Directed Acyclic Graph,DAG)来刻画属性之间的依赖关系,并使用条件概率表 (Conditional Probability Table,CPT)来描述属性的联合概率分布。
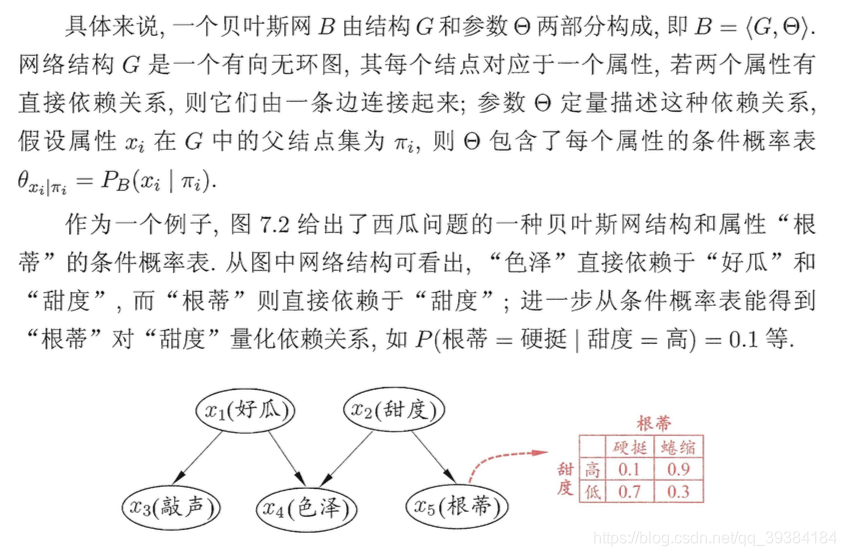
以上图为例,联合概率分布定义为:

贝叶斯网中三个变量之间的典型依赖关系:

EM 算法
未观测变量的学名是"隐变量"(latent variable)。我们可通过对隐变量计算期望,来最大化己观测数据的对数"边际似然" (marginal likelihood)。
EM算法(Expectation-Maximization)是常用的估计参数隐变量的利器,它是一种迭代式的方法。其基本想法是:
- 若参数θ己知,则可根据训练数据推断出最优隐变量Z的值(E 步);
- 若Z的值已知,则可方便地对参数θ做极大似然估计(M 步)。
算法步骤:
- 基于 θt 推断 Z 的期望,记为 Zt。
- 基于已观察变量 X 和 Zt 对θ做极大似然估计,记为θt+1
集成学习
个体与集成
集成学习(ensemble learning):通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等。
- 同质(homogeneous)集成学习:神经网络。
- 异质(heterogenous)集成学习。
同质集成中的个体学习器亦称"基学习器"(base learner),相应的学习算法称为"基学习算法"(base learning algorithm)。异质集成中的个体学习器由不同的学习算法生成,这时就不再有基学习算法,相应的,个体学习器一般不称为基学习器,常称为"组件学习器"(component learner)或直接称为个体学习器。
集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能。因为集成学习的很多理论研究都是针对弱学习器(weak learner)进行的,所以基学习器有时也被直接称为弱学习器。
要获得好的集成,个体学习期应该"好而不同”,即个体学习器要有一定的"准确性”,即学习器不能太坏,并且要有"多样性" (diversity),即学习器间具有差异。
在基学习器的误差相互独立的情况下,随着集成中个体分类器数目 T 的增大,集成的错误率将指数级下降,最终趋向于零。
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类:
- 个体学习器间存在强依赖关系、必须串行生成的序列化方法:Boosting;
- 个体学习器间不存在强依赖关系、可同时生成的并行化方法:Bagging 和"随机森林"(Random Forest)。
Boosting
Boosting是一族可将弱学习器提升为强学习器的算法。这族算法的工作机制类似:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合。
Boosting 族算法最著名的代表是 AdaBoost。
Adaboost的自适应在于:最开始,所有的训练样本具有相同权重。被前一个分类器分错的样本会被用于训练下一个分类器,即提高这个分错的样本被选中进入下一个弱分类器选中的概率,分对的样本被选中的概率会被降低。
Bagging 与随机森林
Bagging是并行式集成学习方法最著名的代表。由自助采样法采样出 T 个含 m 个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。这就是 Bagging 的基本流程。在对预测输出进行结合时,Bagging通常对分类任务使用简单投票法,对回归任务使用简单平均法。若分类预测时出现两个类收到同样票数的情形,则最简单的做法是随机选择一个,也可进一步考察学习器投票的置信度来确定最终胜者。
随机森林(Random Forest,RF)是Bagging的一个扩展变体。RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)中选择一个最优属性;而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参数k控制了随机性的引入程度;若令k=d,则基决策树的构建与传统决策树相同;若令k=1,则是随机选择一个属性用于划分;一般情况下,推荐值k=log2d。
结合策略
学习器结合可能会从三个方面带来好处:
- 从统计的方面来看,由于学习任务的假设空间往往很大,可能有多个假设在训练集上达到同等性能,此时若使用单学习器可能因误选而导致泛化性能不佳,结合多个学习器则会减小这一风险。
- 从计算的方面来看,学习算法往往会陷入局部极小,有的局部极小点所对应的泛化性能可能很糟糕,而通过多次运行之后进行结合,可降低陷入糟糕局部极小点的风险。
- 从表示的方面来看,某些学习任务的真实假设可能不在当前学习算法所考虑的假设空间中,此时若使用单学习器则肯定无效,而通过结合多个学习器,由于相应的假设空间有所扩大,有可能学得更好的近似。
结合的常见策略:
- 平均法
- 简单平均法
- 加权平均法
- 投票法
- 绝对多数投票法(票低于半数拒绝预测)
- 相对多数投票法
- 加权投票法
- 学习法
当训练数据很多时,一种更为强大的结合策略是使用"学习法",即通过另一个学习器来进行结合。Stacking学习法的典型代表,这里我们把个体学习器称为初级学习器,用于结合的学习器称为次级学习器或元学习器(meta-learner)。
Stacking先从初始数据集训练出初级学习器,然后"生成"一个新数据集用于训练次级学习器。在这个新数据集中,初级学习器的输出被当作样例输入特征,而初始样本的标记仍被当作样例标记。
降维与主成分分析(PCA)
目标
- 数据压缩
- 可视化
主成分分析(PCA)
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
- 计算协方差矩阵
- 奇异值分解(SVD)计算特征向量
- 由特征向量计算降维后的表示 z


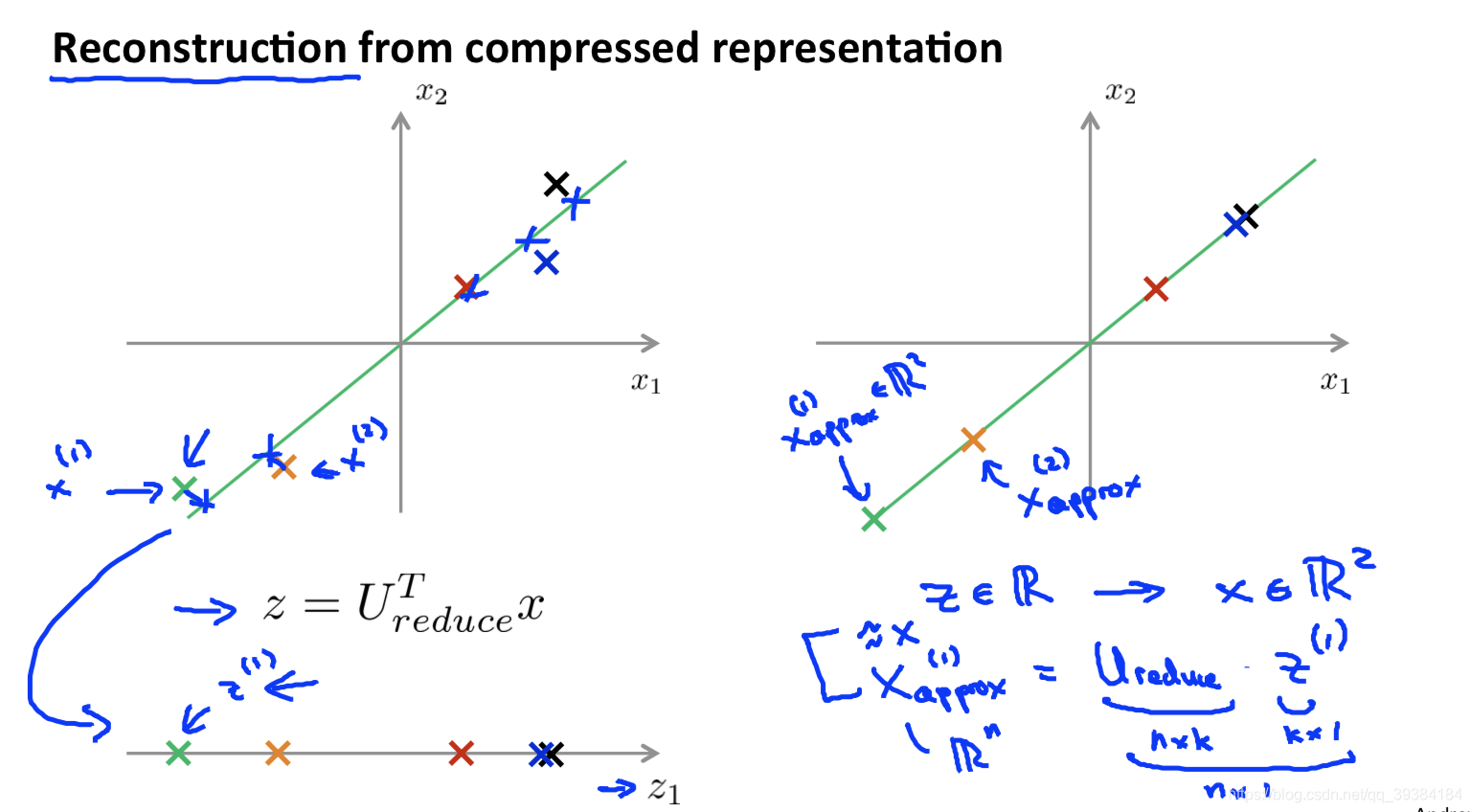
压缩重现
主成分数量选择


PCA 的使用
定义 X 到 Z 的映射。

PCA 的作用:
- 数据压缩
- 减少内存或硬盘的数据存储
- 提高算法的运行效率
- 可视化
- 错误使用:避免过拟合(可能有效果,但不是一个好的解决办法)
在使用 PCA 之前,先使用原始的数据尝试,如果没有达到效果再考虑使用 PCA。
非负矩阵分解(NMF)





计算学习理论
PAC 学习
计算学习理论中最基本的是概率近似正确(Probably Approximately Correct,PAC)学习理论。
有限假设空间
- 可分情形:
- 目标概念 c 属于假设空间 H,只保留与训练集 D 一致的假设,若训练集足够大,则直到 H 中只剩一个假设。
- 不可分情形:
- H 中必存在一个泛化误差最小的假设。
VC 维
现实学习任务所面临的通常是无限假设空间,最常见的办法是考虑假设空间的"VC维"(Vapnik-Chervonenkis dimension)。
假设空间H的VC维是能被H打散的最大示例集的大小,VC(H)=d 表明存在大小为d的示例集能被假设空间H打散。
注意:并不意味着所有大小为d的示例集都能被假设空间H打散,VC 维的定义与数据分布D无关,因此,在数据分布未知时仍能计算出假设空间H的VC维。
- 二维实平面上所有线性划分构成的假设空间的 VC 维为 3。

VC维反映了函数集的学习能力,VC维越大则学习机器越复杂(容量越大)
若输入数据量N小于VC维,则有可能输入数据D会被完全的二分类。
转载地址:https://mortal.blog.csdn.net/article/details/92759593 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
