本文共 2078 字,大约阅读时间需要 6 分钟。
机器学习评估
交叉验证与训练集、验证集、测试集

-
使用验证集来选择假设模型。
-
使用测试集来衡量假设模型的泛化误差。
如果给定的样本数据充足,我们通常使用均匀随机抽样的方式将数据集划分成3个部分——训练集、验证集和测试集,这三个集合不能有交集,常见的比例是8:1:1。需要注意的是,通常都会给定训练集和测试集,而不会给验证集。这时候验证集该从哪里得到呢?一般的做法是,从训练集中均匀随机抽样一部分样本作为验证集。
训练集
训练集用来训练模型,即确定模型的权重和偏置这些参数,通常我们称这些参数为学习参数。
验证集
而验证集用于模型的选择,更具体地来说,验证集并不参与学习参数的确定,也就是验证集并没有参与梯度下降的过程。验证集只是为了选择超参数,比如网络层数、网络节点数、迭代次数、学习率这些都叫超参数。比如在k-NN算法中,k值就是一个超参数。所以可以使用验证集来求出误差率最小的k。
测试集
测试集只使用一次,即在训练完成后评价最终的模型时使用。它既不参与学习参数过程,也不参数超参数选择过程,而仅仅使用于模型的评价。
值得注意的是,千万不能在训练过程中使用测试集,而后再用相同的测试集去测试模型。这样做其实是一个cheat,使得模型测试时准确率很高。
交叉验证
之所以出现交叉验证,主要是因为训练集较小。无法直接像前面那样只分出训练集,验证集,测试就可以了(简单交叉验证)。
需要说明的是,在实际情况下,人们不是很喜欢用交叉验证,主要是因为它会耗费较多的计算资源。一般直接把训练集按照50%-90%的比例分成训练集和验证集。但这也是根据具体情况来定的:如果超参数数量多,你可能就想用更大的验证集,而验证集的数量不够,那么最好还是用交叉验证吧。至于分成几份比较好,一般都是分成3、5和10份。
交叉验证的实现

图上面的部分表示我们拥有的数据,而后我们对数据进行了再次分割,主要是对训练集,假设将训练集分成5份(该数目被称为折数,5-fold交叉验证),每次都用其中4份来训练模型,粉红色的那份用来验证4份训练出来的模型的准确率,记下准确率。然后在这5份中取另外4份做训练集,1份做验证集,再次得到一个模型的准确率。直到所有5份都做过1次验证集,也即验证集名额循环了一圈,交叉验证的过程就结束。算得这5次准确率的均值。留下准确率最高的模型,即该模型的超参数是什么样的最终模型的超参数就是这个样的。
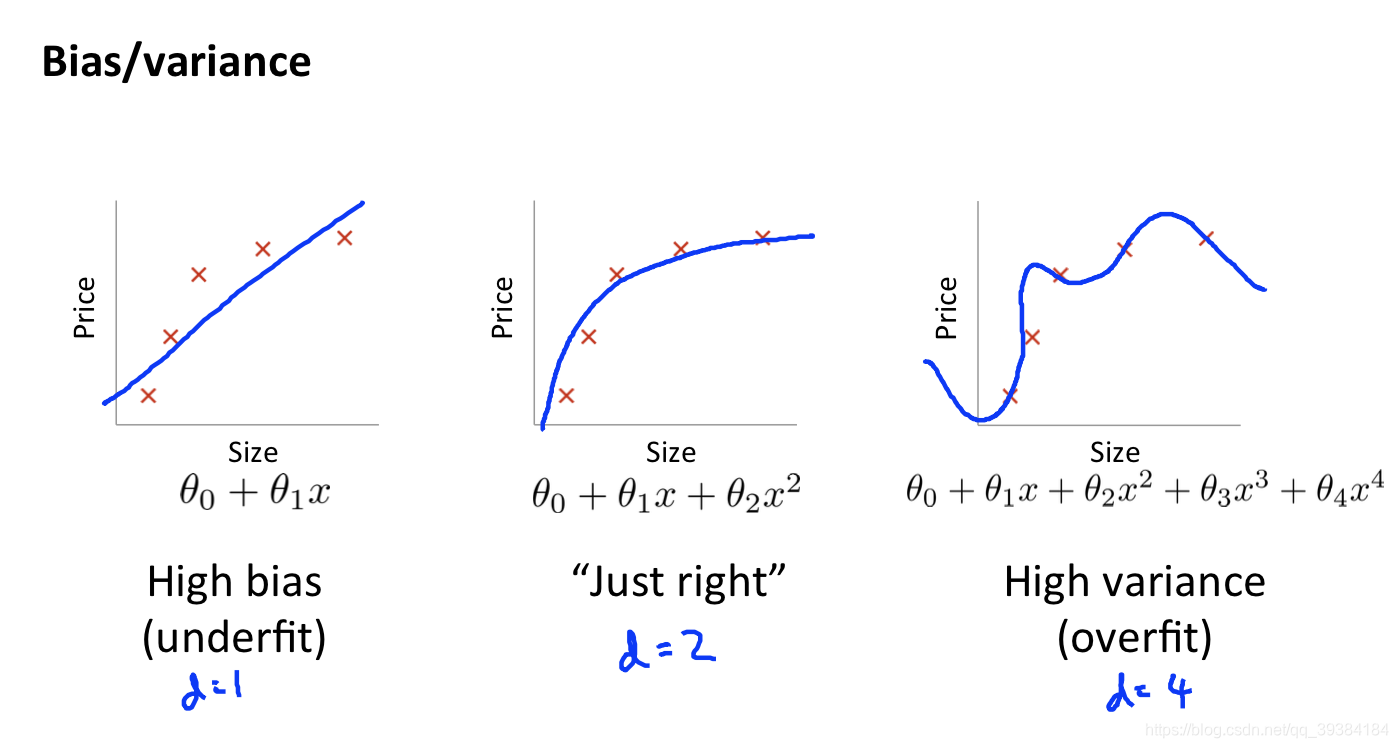
偏差与方差
偏差(欠拟合)、方差(过拟合)

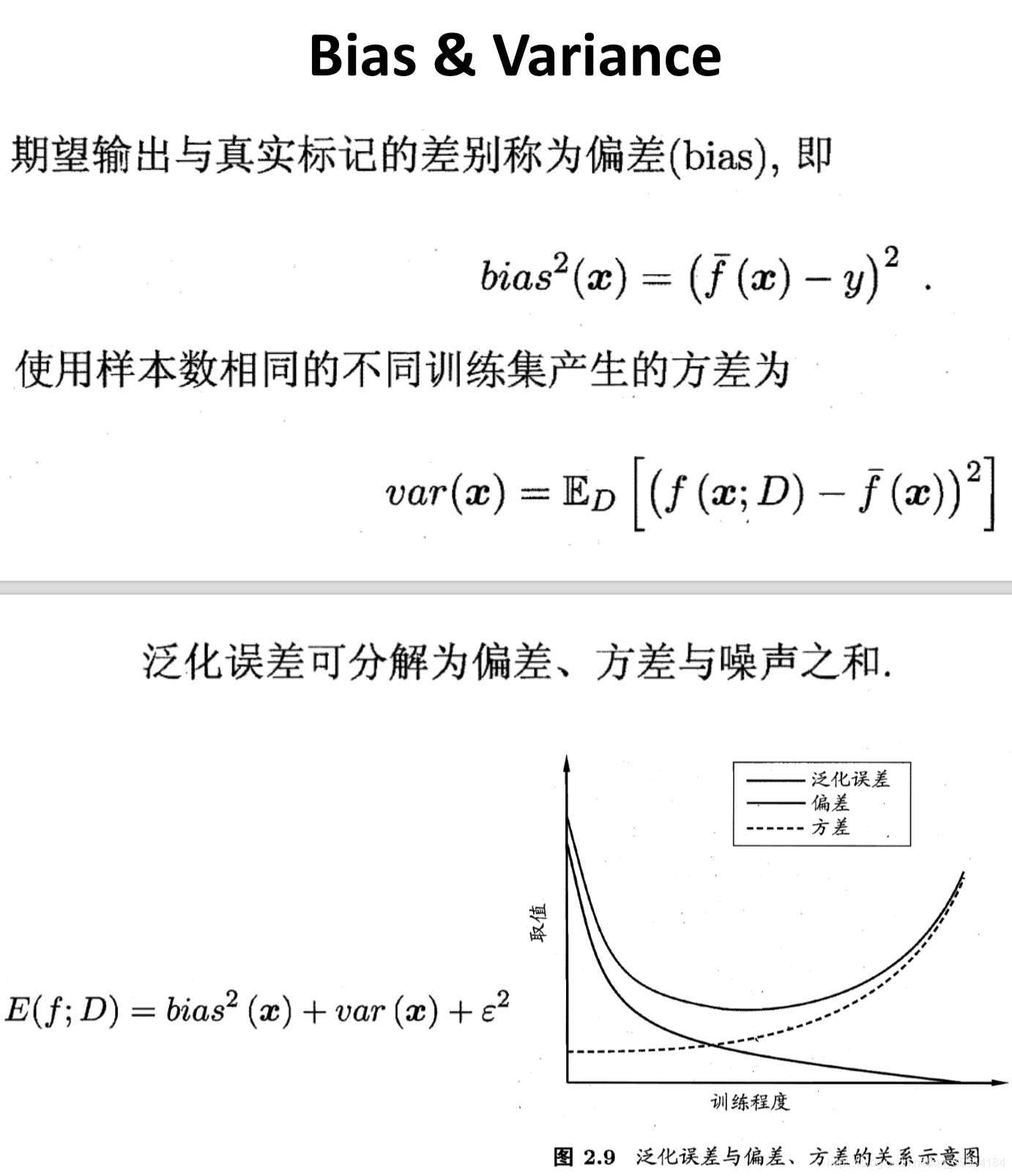
正则化和偏差、方差
根据验证集选择 λ
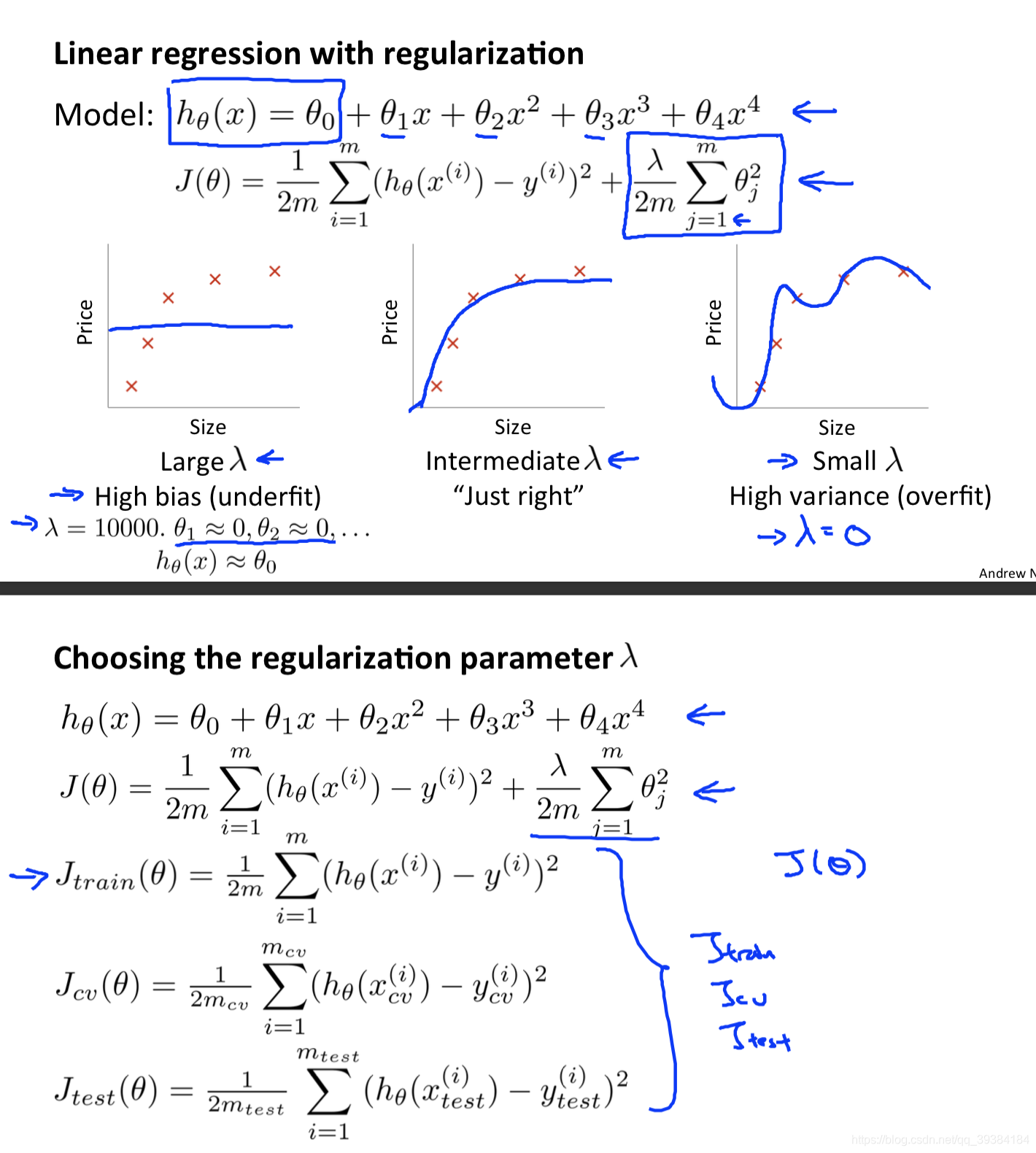

学习曲线
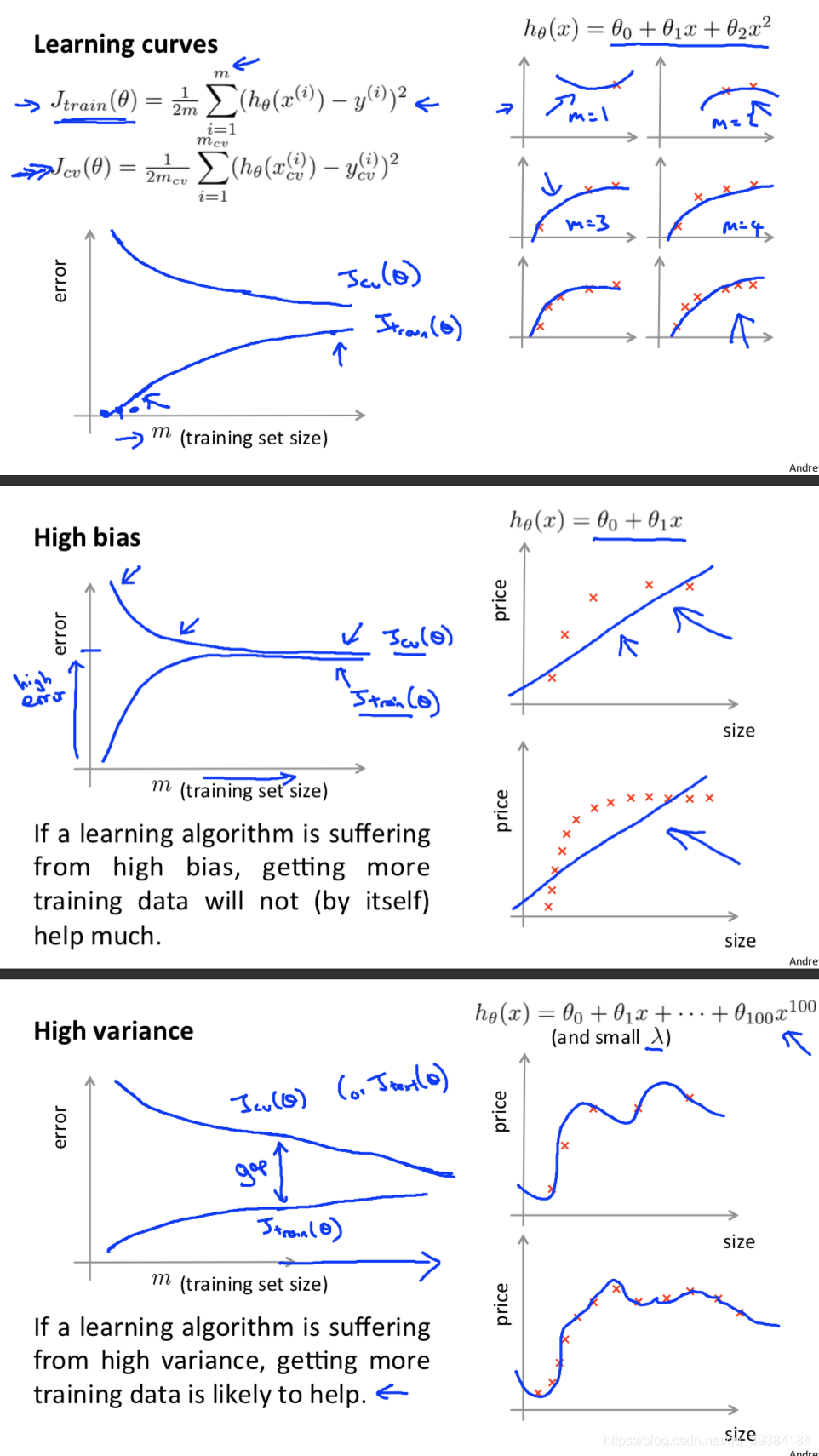
总结
通过画出学习曲线和检验误差来判断算法是否存在高偏差或者高方差的问题,再决定是否使用更多的数据或者特征。

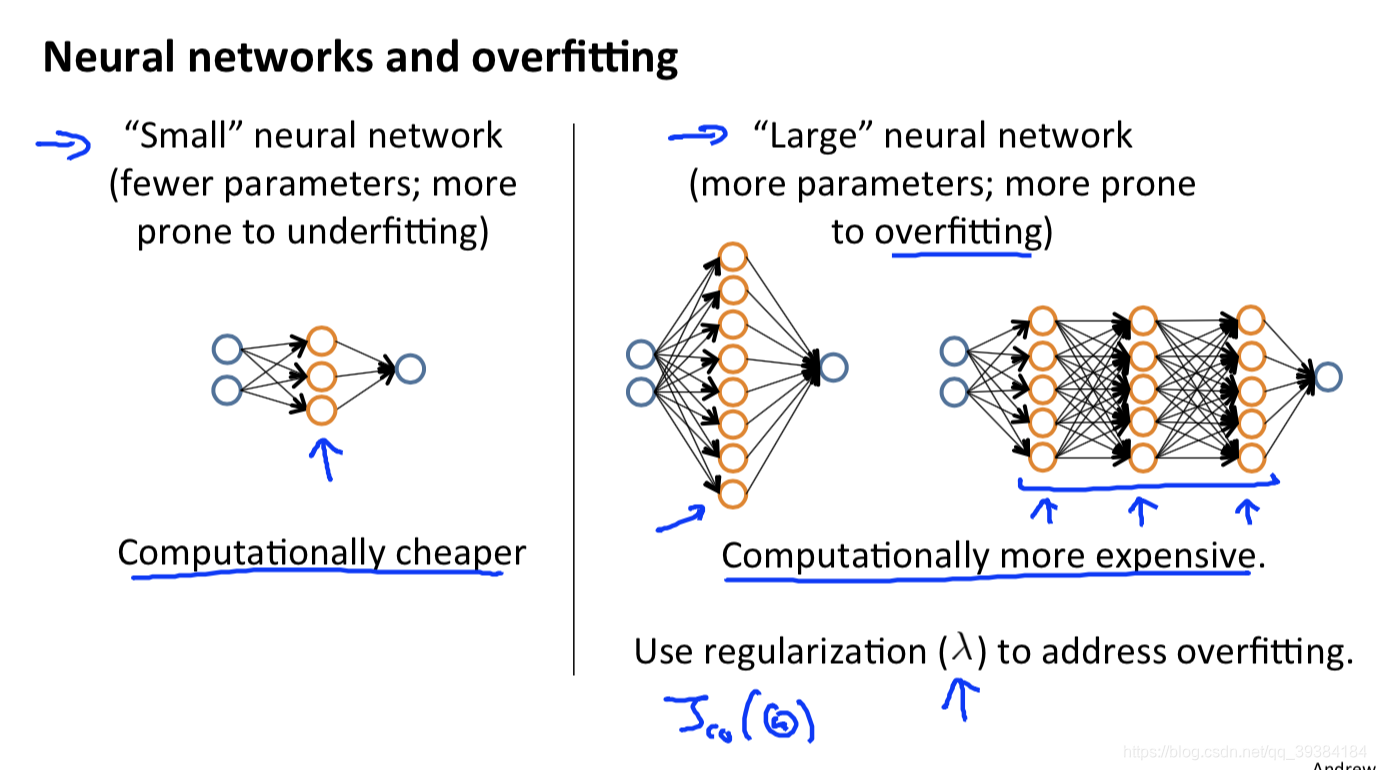
神经网络的评估
神经网络的选择,隐含层层数的选择
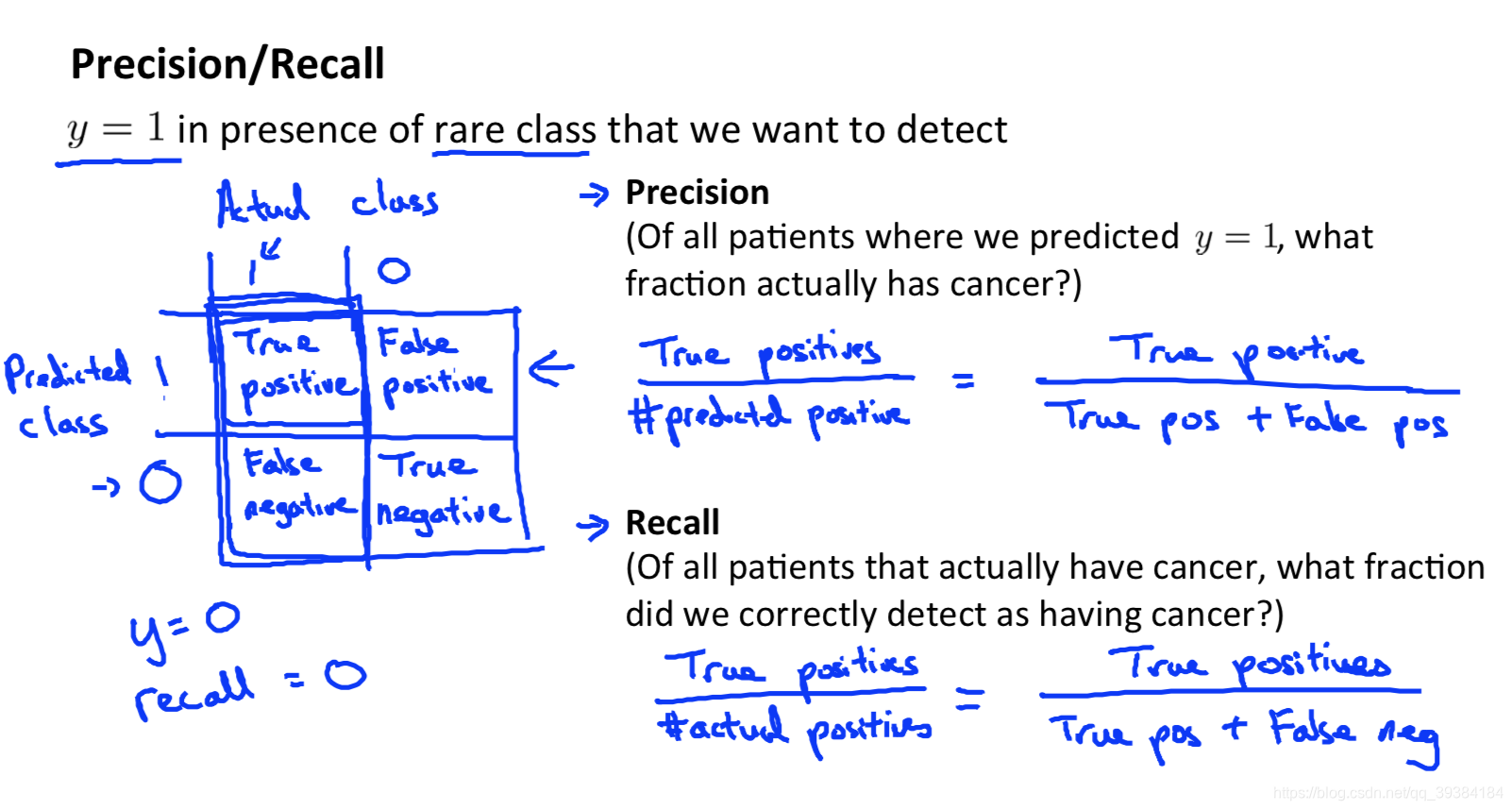
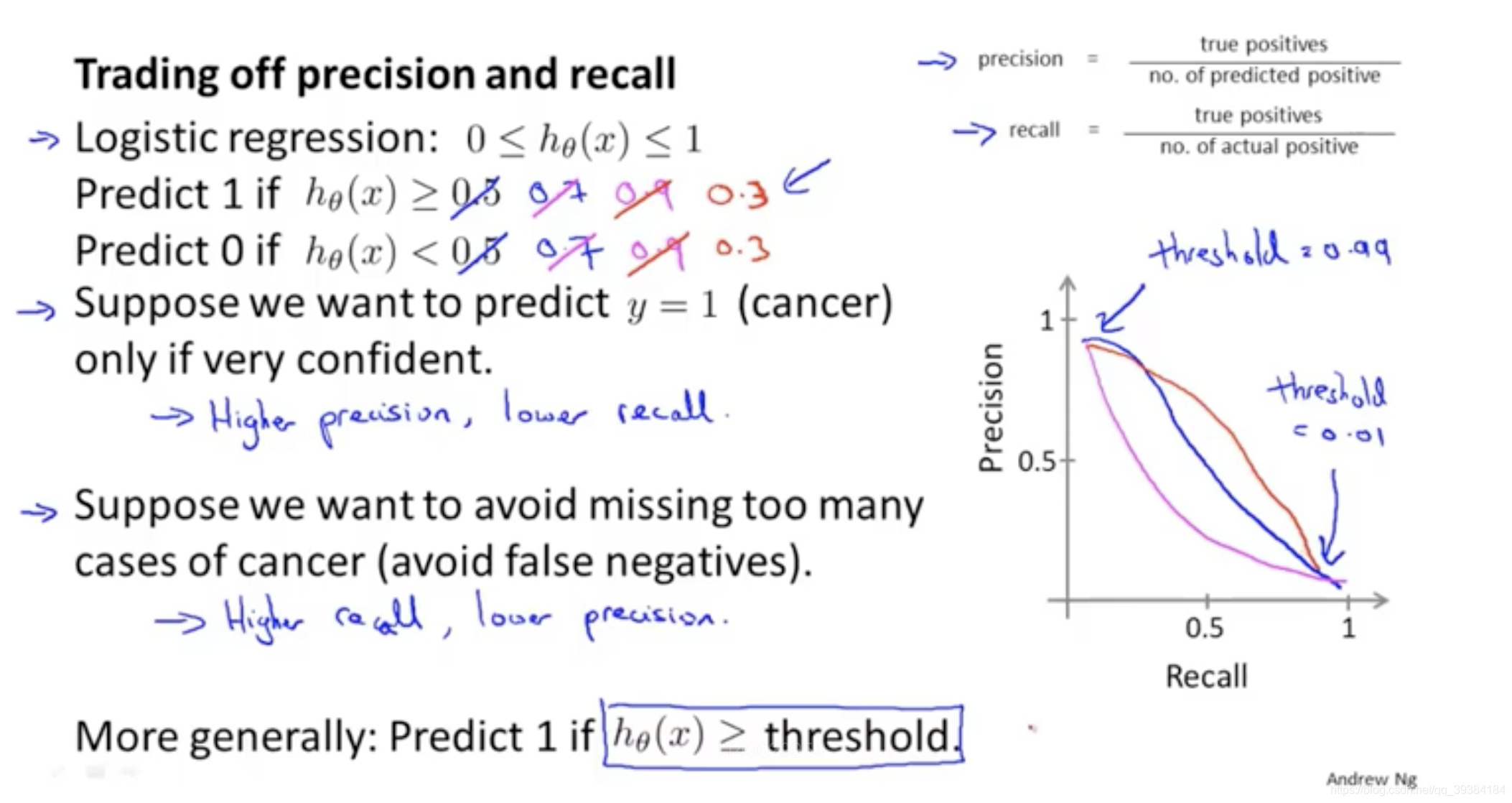
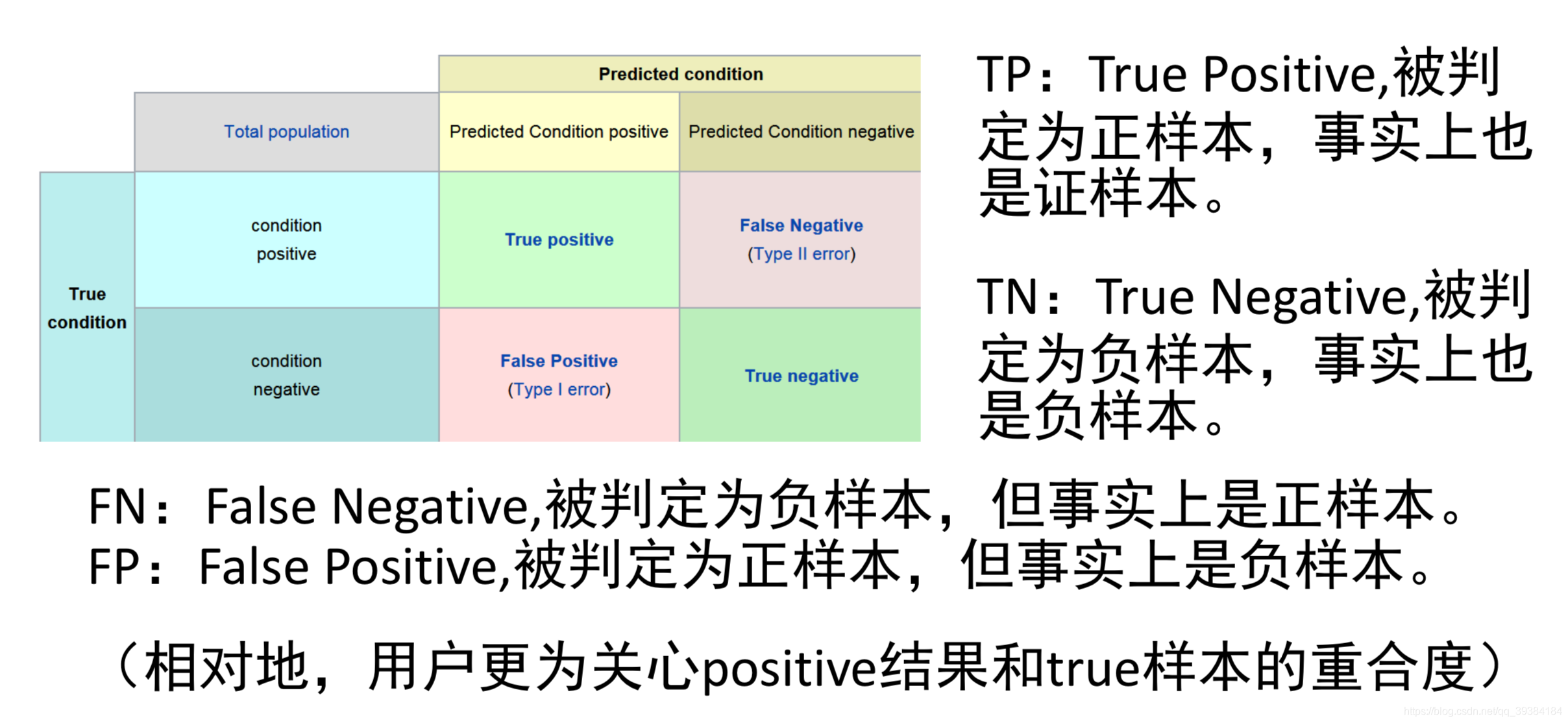
不对称分类的误差评估和精确度,召回率
不对称分类也叫偏斜类。

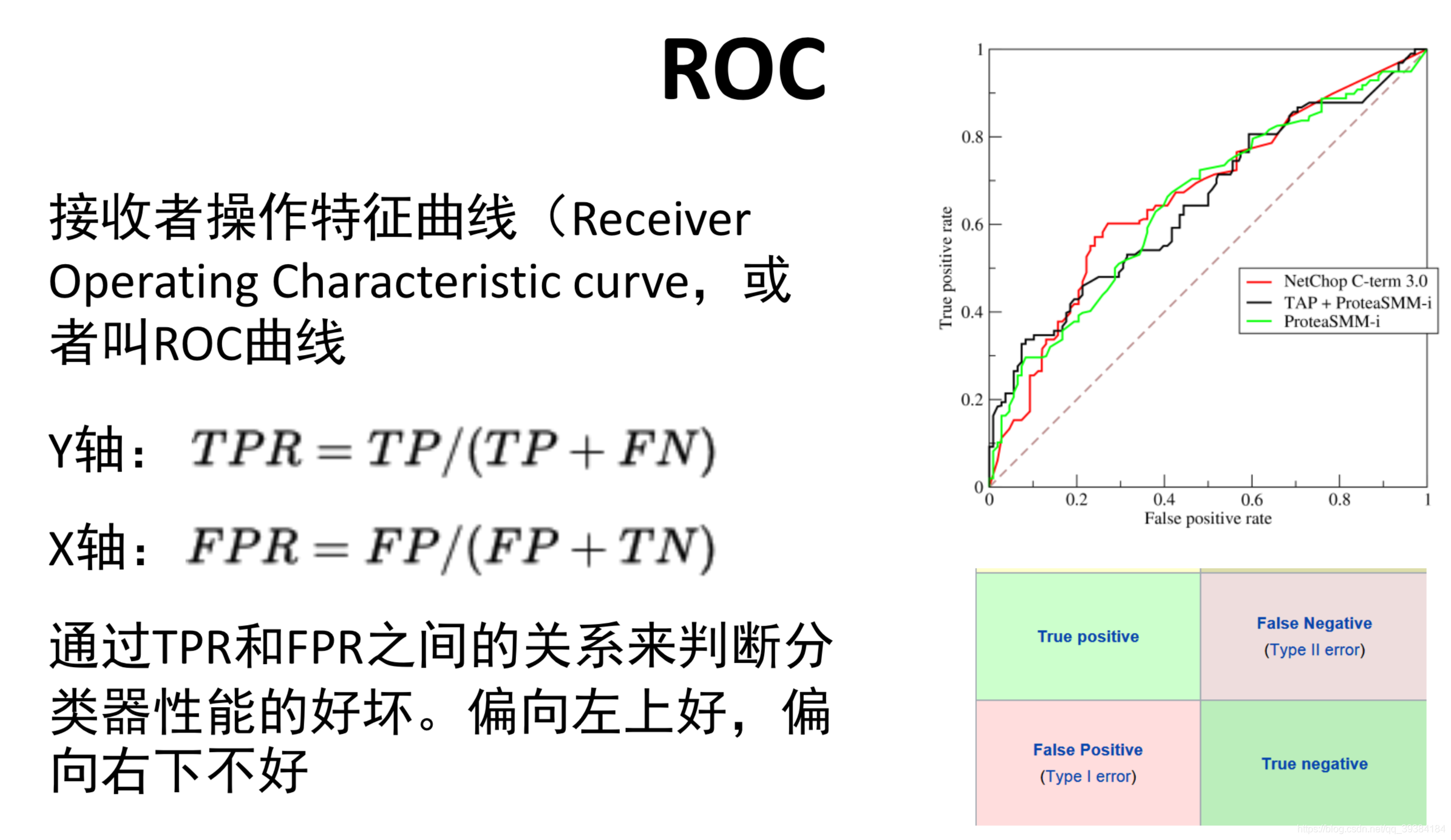
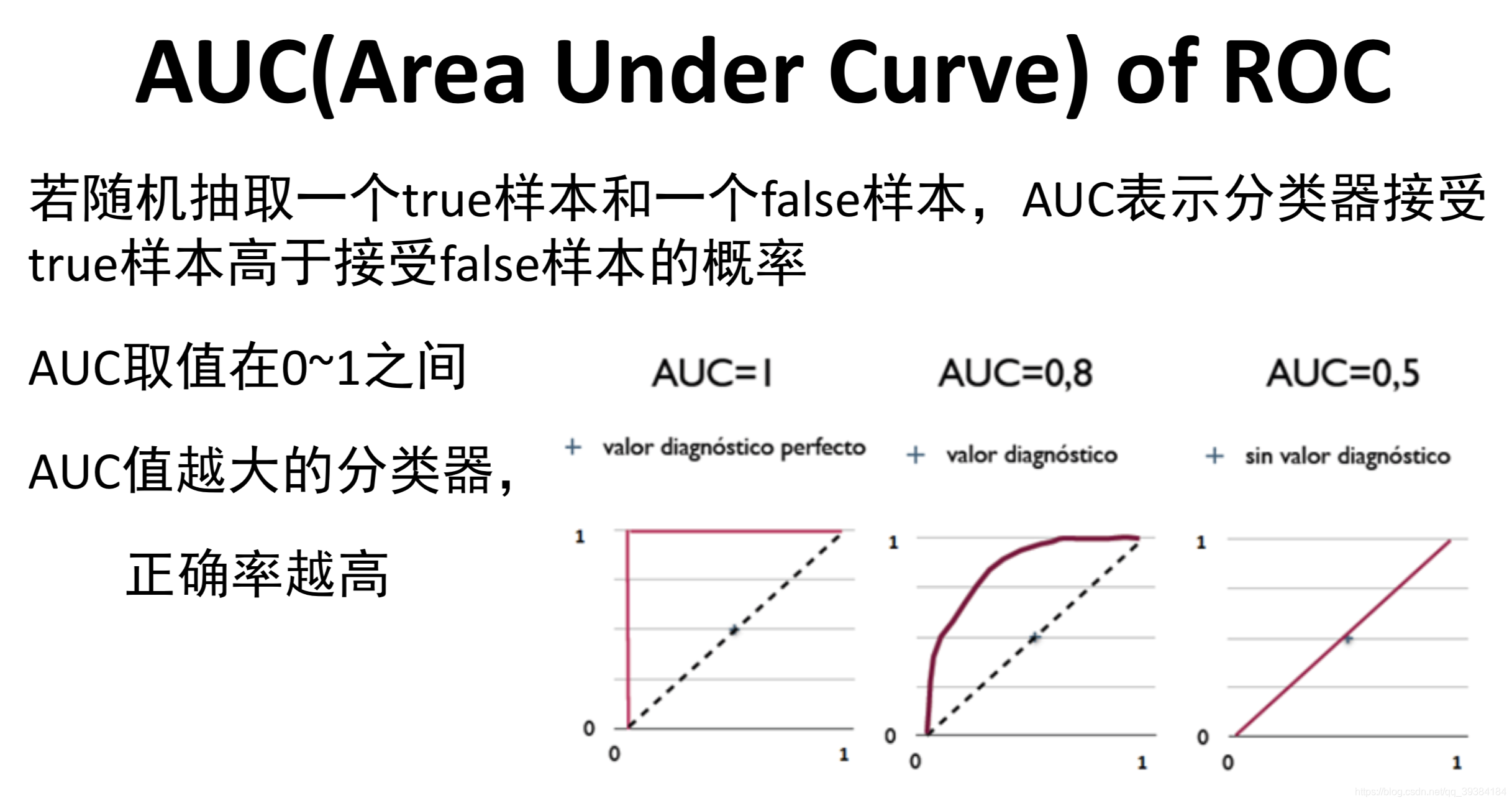
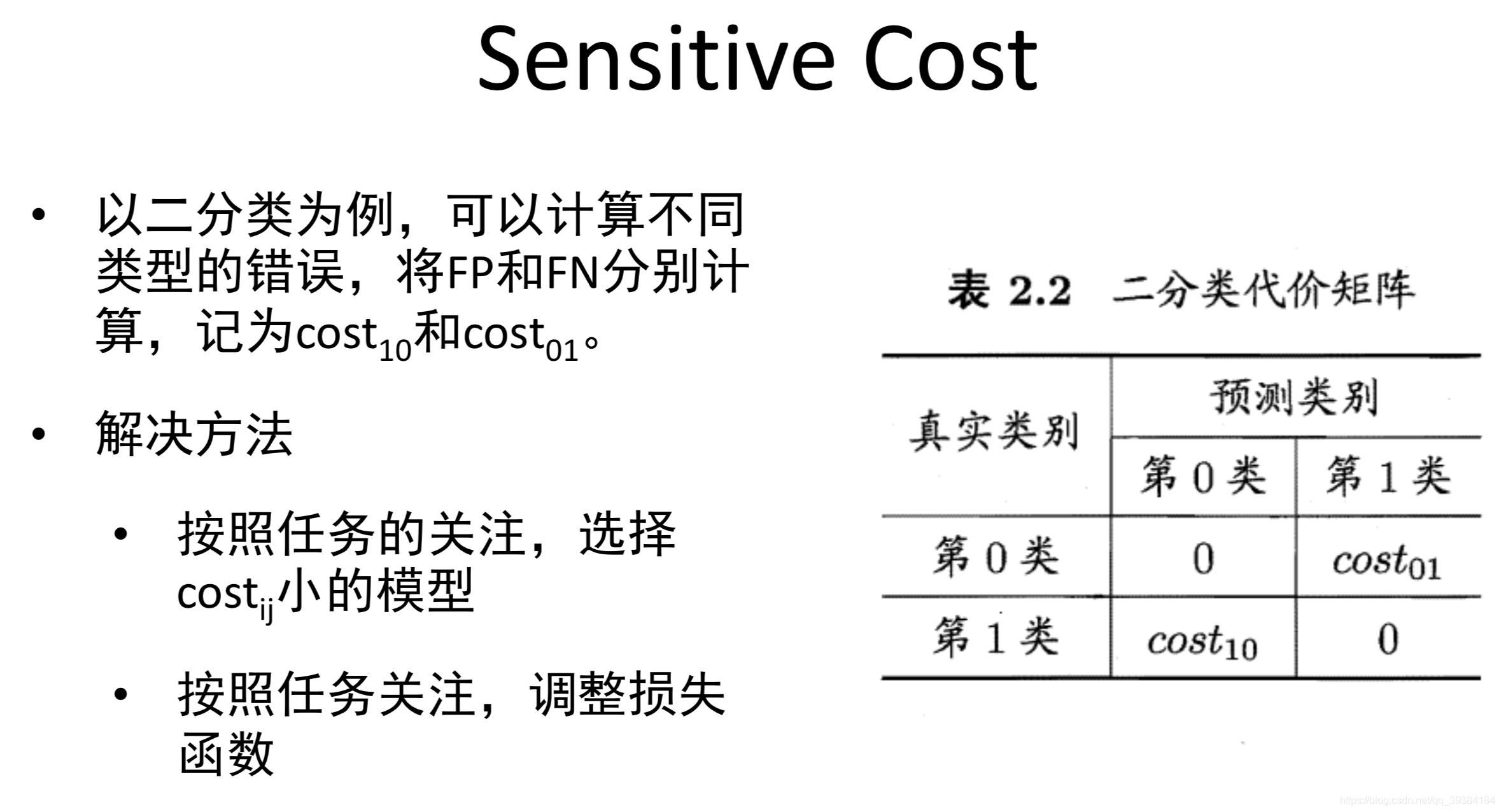
机器学习数据
- 参数多,特征值多的假设模型可以得到低偏差
- 很大的测试集可以得到低方差

统计学习理论
统计学习的三要素
- 模型
- 策略
- 算法
- 假设空间
我们可以把学习过程看做一个在所有假设组成的空间中 进行搜索的过程,搜索目标是找到与训练及匹配的假设。 也就是说能够将训练集中判断正确的假设。
可见的样本空间到不可见的函数族/概念空间
- 归纳学习与归纳偏好(或偏置)
归纳偏好:评估候选假设或概念的准则,并利用该特性将 机器学习工作从枚举变为搜索(带剪枝)。智能也体现在此。
典型的归纳偏好
- 最大条件独立性
- 最小交叉验证误差
- 最大间隔(Maximum Margin)
- 最小描述长度(Minimum description length,奥卡姆剃刀)。
- 最少特征数
- 最近邻居
- 过拟合、偏差与方差、学习曲线
- 从偏差和方差角度看,很难同时追求最优。
- 从统计学习理论角度:
- 低偏差代表经验风险最小化
- 低方差代表结构风险最小化
- 过拟合、正则化与统计风险最小化
- 为避免过拟合,使用正则化方法
- 统计学习理论、VC维与SVM
- 计算学习理论与PAC学习
VC 维
定义是:对一个指示函数集,如果存在H个样本能够被函数集中的函数按所有可能的2的H次方种形式分开,则称函数集能够把H个样本打散;函数集的VC维就是它能打散的最大样本数目H。若对任意数目的样本都有函数能将它们打散,则函数集的VC维是无穷大,有界实函数的VC维可以通过用一定的阈值将它转化成指示函数来定义。
VC维反映了函数集的学习能力,VC维越大则学习机器越复杂(容量越大)
若输入数据量N小于VC维,则有可能输入数据D会被完全的二分类。
PAC 学习
- PAC:Probably Approximately Correct
- 弱学习算法—识别错误率小于1/2(即准确率仅比随机猜测略高的学习算法)。
- 强学习算法—识别准确率很高并能在多项式时间内完成的学习算法。
- 弱学习和强学习算法的等价性—即任意给定仅比随机猜测略好的弱学习算法,可以将其提升为强学习算法。
- Adaboost—一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
转载地址:https://mortal.blog.csdn.net/article/details/91620374 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
