Pandas入门2(DataFunctions+Maps+groupby+sort_values)
learn from
发布日期:2021-07-01 03:25:48
浏览次数:3
分类:技术文章
本文共 6703 字,大约阅读时间需要 22 分钟。
文章目录
上一篇:
下一篇:3. Summary Functions and Maps
3.1 Summary Functions 数据总结函数
3.1.1 describe()
wine_rev.points.describe(),各种统计信息,数字信息总结
# 数字列的总结count 129971.000000mean 88.447138std 3.039730min 80.00000025% 86.00000050% 88.00000075% 91.000000max 100.000000Name: points, dtype: float64
wine_rev.country.describe(),文字信息总结
# 文字类列的总结count 129908unique 43top USfreq 54504Name: country, dtype: object
3.1.2 mean(),median(),idxmax(),unique(),value_counts()
wine_rev.points.mean(),均值,median(),中位数,idxmax(),最大数据的下标wine_rev.country.unique(),不同的值多少个
array(['Italy', 'Portugal', 'US', 'Spain', 'France', 'Germany', 'Argentina', 'Chile', 'Australia', 'Austria', 'South Africa', 'New Zealand', 'Israel', 'Hungary', 'Greece', 'Romania', 'Mexico', 'Canada', nan, 'Turkey', 'Czech Republic', 'Slovenia', 'Luxembourg', 'Croatia', 'Georgia', 'Uruguay', 'England', 'Lebanon', 'Serbia', 'Brazil', 'Moldova', 'Morocco', 'Peru', 'India', 'Bulgaria', 'Cyprus', 'Armenia', 'Switzerland', 'Bosnia and Herzegovina', 'Ukraine', 'Slovakia', 'Macedonia', 'China', 'Egypt'], dtype=object)
wine_rev.country.value_counts(),各个值的计数
US 54504France 22093Italy 19540Spain 6645.....Egypt 1China 1Name: country, dtype: int64
3.2 Maps 映射
3.2.1 map()
wine_points_mean = wine_rev.points.mean()wine_rev.points.map(lambda p : p-wine_points_mean),将数据变到均值上下(产生一个Series,原DF数据没变)
0 -1.4471381 -1.4471382 -1.4471383 -1.4471384 -1.447138 ... 129966 1.552862129967 1.552862129968 1.552862129969 1.552862129970 1.552862Name: points, Length: 129971, dtype: float64
3.2.2 apply()
通过定义函数,使用apply对整个表进行转换,对每一行进行操作
def remean_points(row): row.points = row.points - wine_points_mean return rowwine_rev.apply(remean_points,axis='columns')
Note that map() and apply() return new, transformed Series and DataFrames, respectively.
They don’t modify the original data they’re called on. 上面两种方法都不会修改原始数据
3.2.3 内置转换方法
wine_rev.points - wine_points_mean,直接相减就可以,每个数据都会减去右边的单个value
0 -1.4471381 -1.4471382 -1.4471383 -1.4471384 -1.447138 ... 129966 1.552862129967 1.552862129968 1.552862129969 1.552862129970 1.552862Name: points, Length: 129971, dtype: float64
wine_rev.country + '-' + wine_rev.region_1,相等长度的两个Series操作,直接1v1对应起来
0 Italy-Etna1 NaN2 US-Willamette Valley3 US-Lake Michigan Shore4 US-Willamette Valley ... 129966 NaN129967 US-Oregon129968 France-Alsace129969 France-Alsace129970 France-AlsaceLength: 129971, dtype: object
4. Grouping and Sorting
4.1 Grouping 分组
4.1.1 groupby()
wine_rev.groupby('points').points.count()
points80 39781 69282 183683 302584 648085 953086 1260087 1693388 1720789 1222690 1541091 1135992 961393 648994 375895 153596 52397 22998 7799 33100 19Name: points, dtype: int64
wine_rev.groupby('points').price.min(),按得分分组,然后每组里面价格最低的
points80 5.081 5.082 4.083 4.084 4.085 4.086 4.087 5.088 6.089 7.090 8.091 7.092 11.093 12.094 13.095 20.096 20.097 35.098 50.099 44.0100 80.0Name: price, dtype: float64
wine_rev.groupby('points').apply(lambda df : df.title.iloc[0]),按得分分组后,每个DataFrame的 title的第一行,代码产生的是一个Series
points80 Viña Tarapacá 2015 Gran Reserva Chardonnay (Le...81 Pura 8 2010 Grand Reserve Pinot Noir (Rapel Va...82 Mémoires 2015 Rosé (Coteaux Varois en Provence)83 Koyle 2015 Costa Pinot Noir (Colchagua Costa)84 Three Brothers 2014 Zero Degree Dry Riesling (...85 Casa Silva 2008 Gran Reserva Petit Verdot (Col...86 Clarksburg Wine Company 2010 Chenin Blanc (Cla...87 Nicosia 2013 Vulkà Bianco (Etna)88 Fattoria Sardi 2015 Rosato (Toscana)89 David Fulton 2008 Petite Sirah (St. Helena)90 Beaumont 2005 Hope Marguerite Chenin Blanc (Wa...91 Le Riche 2003 Cabernet Sauvignon Reserve Caber...92 Dopff & Irion 2004 Schoenenbourg Grand Cru Ven...93 Claiborne & Churchill 2014 Twin Creeks Estate ...94 Sandeman 2015 Quinta do Seixo Vintage (Port)95 Jasper Hill 2013 Georgia's Paddock Shiraz (Hea...96 Oremus 2005 Eszencia (Tokaji)97 Robert Weil 2014 Kiedrich Gräfenberg Trockenbe...98 Chambers Rosewood Vineyards NV Rare Muscadelle...99 Quilceda Creek 2008 Cabernet Sauvignon (Columb...100 Chambers Rosewood Vineyards NV Rare Muscat (Ru...dtype: object
wine_rev.groupby(['country','province']).apply(lambda df : df.loc[df.points.idxmax()])按照,先按国家分组、再按省份分组,每个组里得分最大的,产生的是一个DataFrame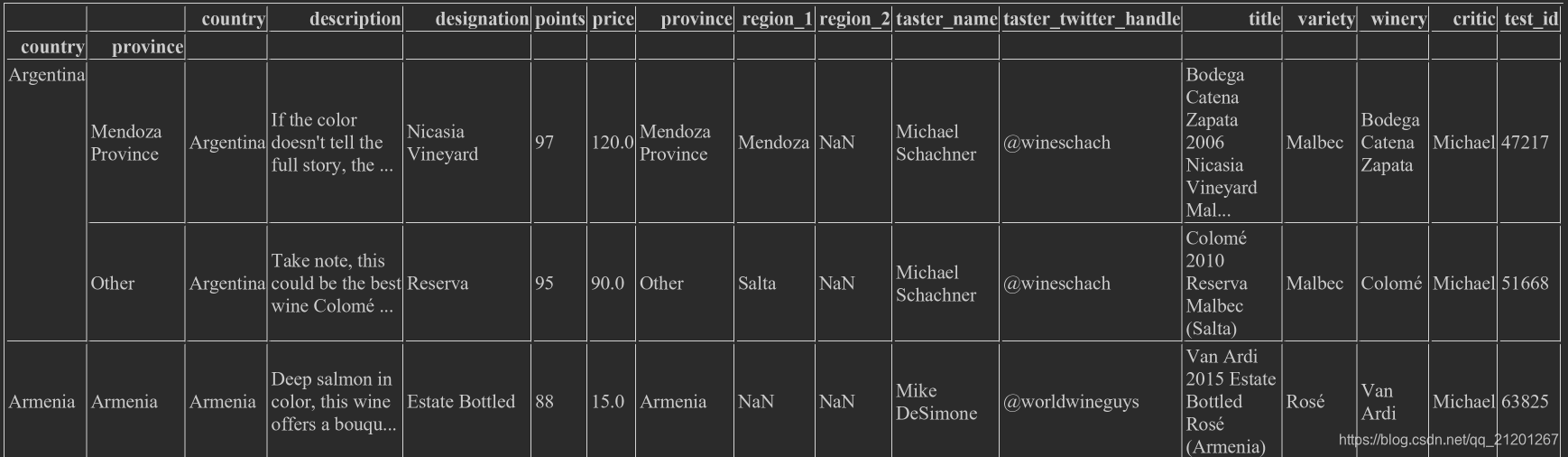
4.1.2 agg()
wine_rev.groupby(['country']).price.agg([len,min,max]),后面可以跟一些统计量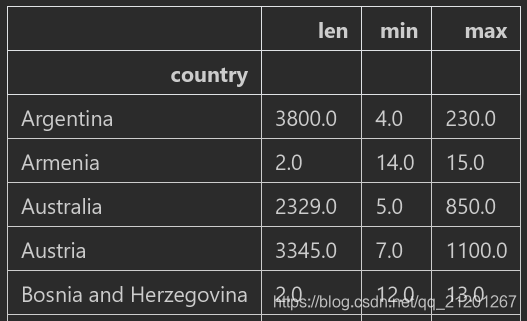
4.1.3 multi_indexes
country_rev = wine_rev.groupby(['country','province']).description.agg([len]),多个特征的分组是多索引的
country_rev.index,MultiIndex
MultiIndex([('Argentina', 'Mendoza Province'), ('Argentina', 'Other'), ( 'Armenia', 'Armenia'), ('Australia', 'Australia Other'), ('Australia', 'New South Wales'), ('Australia', 'South Australia'), ('Australia', 'Tasmania'), ('Australia', 'Victoria'), ('Australia', 'Western Australia'), ( 'Austria', 'Austria'), ... ( 'US', 'Washington'), ( 'US', 'Washington-Oregon'), ( 'Ukraine', 'Ukraine'), ( 'Uruguay', 'Atlantida'), ( 'Uruguay', 'Canelones'), ( 'Uruguay', 'Juanico'), ( 'Uruguay', 'Montevideo'), ( 'Uruguay', 'Progreso'), ( 'Uruguay', 'San Jose'), ( 'Uruguay', 'Uruguay')], names=['country', 'province'], length=425) - 转换多级索引为普通索引,
cr = country_rev.reset_index(),需赋值给一个新的DF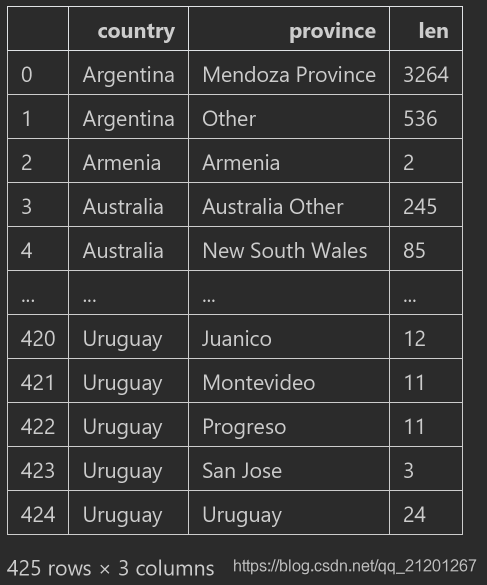
4.2 sort_values() 排序
上面例子可以看出,输出都是按照 index 排序的,我们有时希望按值排序。
cr.sort_values(by='len'),默认升序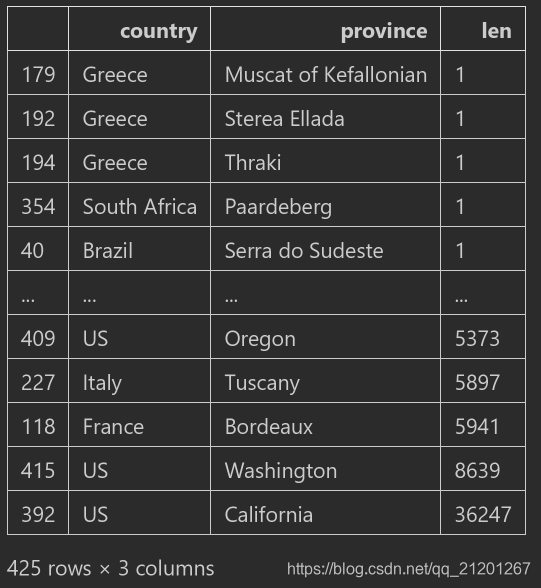
cr.sort_values(by='len',ascending=False),降序(升序=False)cr.sort_index(),恢复按 index 升序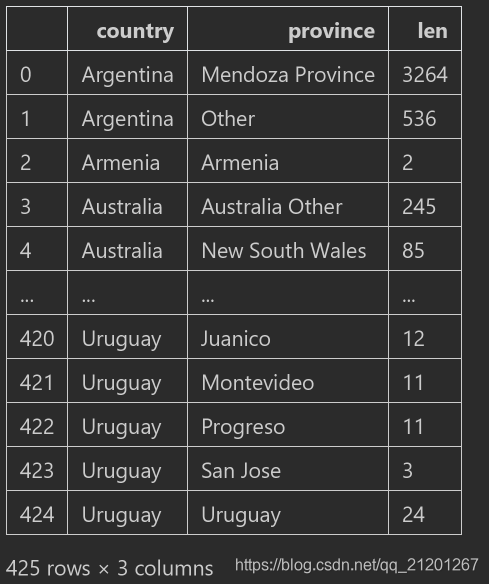
- 按多个值进行排序,
cr.sort_values(by=['country', 'len']),先按国家字符串升序,然后按长度升序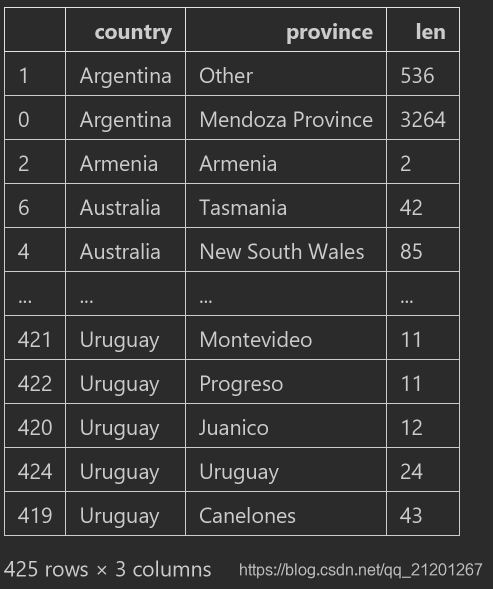
cr.sort_values(by=['country', 'len'],ascending=[False,True]),还可分别指定,每个特征是升序还是降序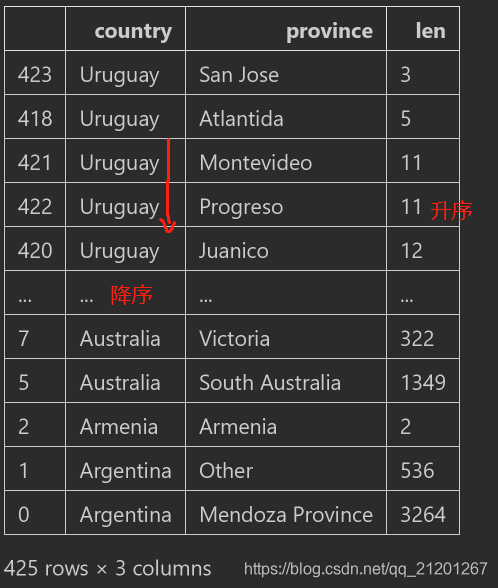
上一篇:
下一篇:转载地址:https://michael.blog.csdn.net/article/details/106182640 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
很好
[***.229.124.182]2024年04月15日 14时07分40秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
CodeForces - 456C Boredom (dp)
2019-04-30
CodeForces - 1042B Vitamins (思维)
2019-04-30
ACM 2013 长沙区域赛 Collision (几何)
2019-04-30
ACM 2014 鞍山区域赛 E - Hatsune Miku (dp)
2019-04-30
反向传播&梯度下降 的直观理解程序(numpy)
2019-04-30
ACM 2017 北京区域赛 J-Pangu and Stones(区间dp)
2019-04-30
java常用类 String面试题
2019-04-30
四线触摸屏原理
2019-04-30
C/C++如何返回一个数组/指针
2019-04-30
腾讯AI语音识别API踩坑记录
2019-04-30
java.net.BindException: 无法指定被请求的地址
2019-05-01
svn服务器安装
2019-05-01
spark 笔记1
2019-05-01
shell dirname basename
2019-05-01
未来已至,5G加持下的云游戏将走向何方?
2019-05-01
计算机网络 —— 网络层 1.
2019-05-01
Android 之 ContentProvider 与 ContentResolver
2019-05-01
【接口自动化】
2019-05-01
推荐一位川大零基础转行 Python 的人生勇士
2019-05-01
Python解惑之:True与False
2019-05-01
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311850783 位访客
访问时间: 2024-05-08 00:41:16
访问IP: 3.144.161.116
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版