Pandas入门1(DataFrame+Series读写/Index+Select+Assign)
2.4.1 布尔符号
2.4.2 Pandas内置符号
发布日期:2021-07-01 03:25:43
浏览次数:2
分类:技术文章
本文共 4825 字,大约阅读时间需要 16 分钟。
文章目录
learn from
下一篇:
1. Creating, Reading and Writing
1.1 DataFrame 数据框架
- 创建
DataFrame,它是一张表,内部是字典,key :[value_1,...,value_n]
#%%# -*- coding:utf-8 -*-# @Python Version: 3.7# @Time: 2020/5/16 21:10# @Author: Michael Ming# @Website: https://michael.blog.csdn.net/# @File: pandasExercise.ipynb# @Reference: https://www.kaggle.com/learn/pandasimport pandas as pd#%%pd.DataFrame({ 'Yes':[50,22],"No":[131,2]}) 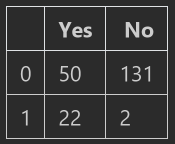
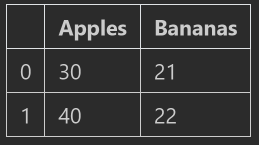
fruits = pd.DataFrame([[30, 21],[40, 22]], columns=['Apples', 'Bananas'])
- 字典内的
value也可以是:字符串
pd.DataFrame({ "Michael":['handsome','good'],"Ming":['love basketball','coding']}) 
- 给数据加索引
index,index=['index1','index2',...]
pd.DataFrame({ "Michael":['handsome','good'],"Ming":['love basketball','coding']}, index=['people1 say','people2 say']) 
1.2 Series 序列
Series是一系列的数据,可以看成是 list
pd.Series([5,2,0,1,3,1,4])0 51 22 03 14 35 16 4dtype: int64
- 也可以把数据赋值给Series,只是Series没有列名称,只有总的名称
- DataFrame本质上是多个Series
粘在一起
pd.Series([30,40,50],index=['2018销量','2019销量','2020销量'], name='博客访问量') 2018销量 302019销量 402020销量 50Name: 博客访问量, dtype: int64
1.3 Reading 读取数据
- 读取csv(
"Comma-Separated Values")文件,pd.read_csv('file'),存入一个DataFrame
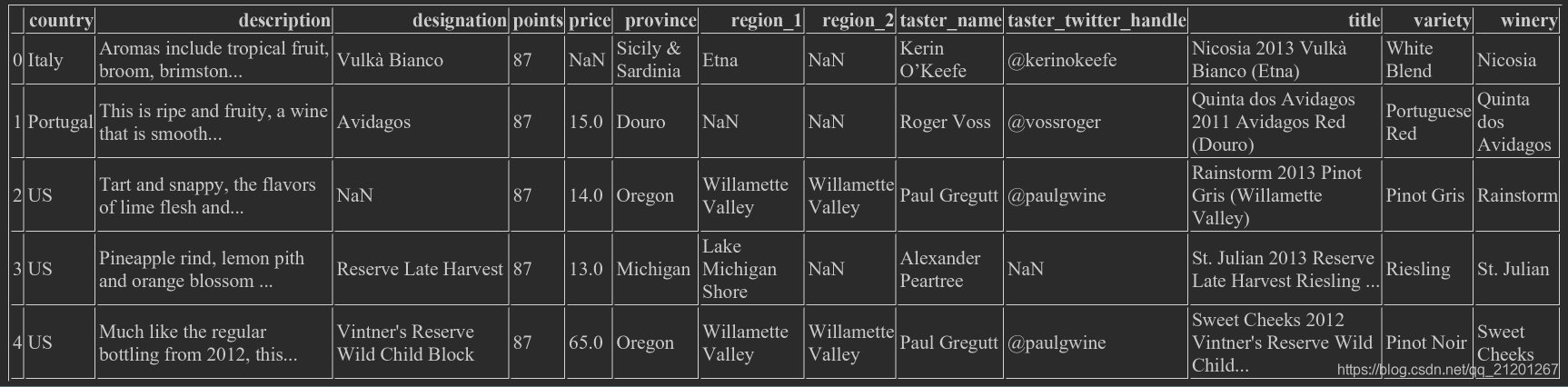
wine_rev = pd.read_csv("winemag-data-130k-v2.csv") wine_rev.shape # 大小(129971, 14)
wine_rev.head() # 查看头部5行
- 可以自定义索引列,
index_col=, 可以是列的序号,或者是列的 name
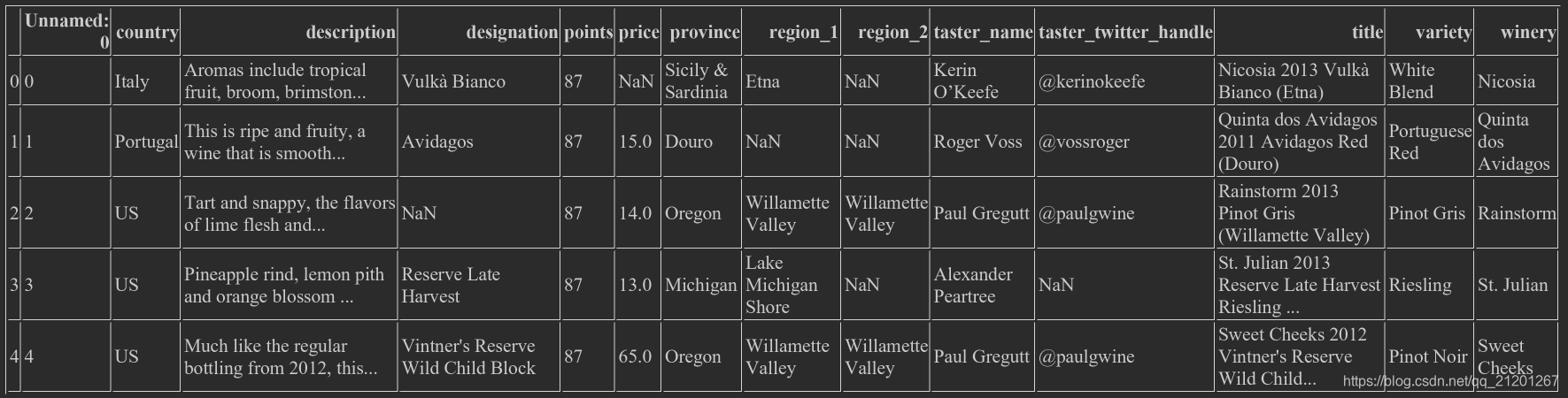
wine_rev = pd.read_csv("winemag-data-130k-v2.csv", index_col=0)wine_rev.head() (下图比上面少了一列,因为定义了index列为0列)
- 保存,
to_csv('xxx.csv')
wine_rev.to_csv('XXX.csv') 2. Indexing, Selecting, Assigning
2.1 类python方式的访问
item.col_name # 缺点,不能访问带有空格的名称的列,[]操作可以item['col_name']
wine_rev.countrywine_rev['country']0 Italy1 Portugal2 US3 US4 US ... 129966 Germany129967 US129968 France129969 France129970 FranceName: country, Length: 129971, dtype: object
wine_rev['country'][0] # 'Italy',先取列,再取行wine_rev.country[1] # 'Portugal'
2.2 Pandas特有的访问方式
2.2.1 iloc 基于index访问
-
要选择DataFrame中的第一行数据,我们可以使用以下代码:
-
wine_rev.iloc[0]
country Italydescription Aromas include tropical fruit, broom, brimston...designation Vulkà Biancopoints 87price NaNprovince Sicily & Sardiniaregion_1 Etnaregion_2 NaNtaster_name Kerin O’Keefetaster_twitter_handle @kerinokeefetitle Nicosia 2013 Vulkà Bianco (Etna)variety White Blendwinery NicosiaName: 0, dtype: object
loc和iloc都是行第一,列第二,跟上面python操作是相反的
wine_rev.iloc[:,0],获取第一列,:表示所有的
0 Italy1 Portugal2 US3 US4 US ... 129966 Germany129967 US129968 France129969 France129970 FranceName: country, Length: 129971, dtype: object
wine_rev.iloc[:3,0],:3 表示 [0:3)行 0,1,2
0 Italy1 Portugal2 USName: country, dtype: object
- 也可以用离散的
list,来取行,wine_rev.iloc[[1,2],0]
1 Portugal2 USName: country, dtype: object
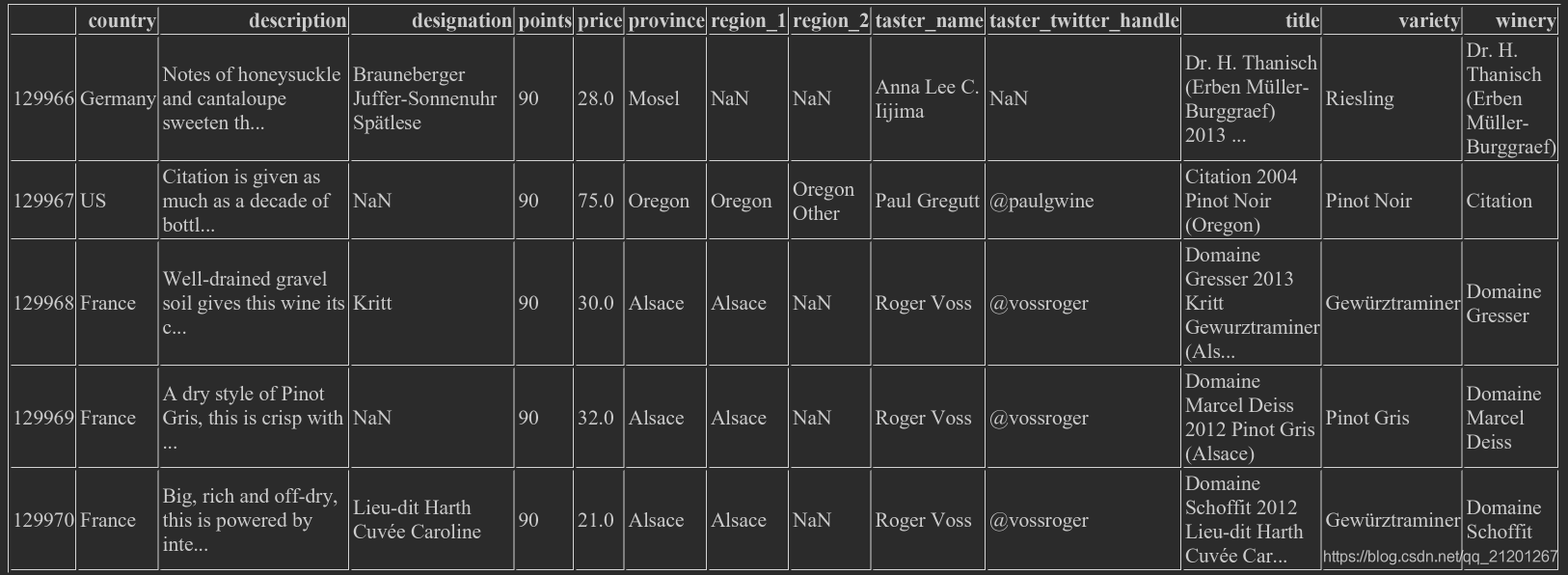
- 取最后几行,
wine_rev.iloc[-5:],倒数第5行到结束
2.2.2 loc 基于label标签访问
wine_rev.loc[0, 'country'],行也可以使用[0,1]表示离散行,列不能使用index
'Italy'
wine_rev.loc[ : 3, 'country'],跟iloc不一样,这里包含了3号行,loc包含末尾的
0 Italy1 Portugal2 US3 USName: country, dtype: object
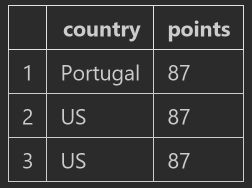
wine_rev.loc[ 1 : 3, ['country','points']],多列用 list 括起来
loc的优势,例如有用字符串 index 的行,df.loc['Apples':'Potatoes']可以选取
2.3 set_index() 设置索引列
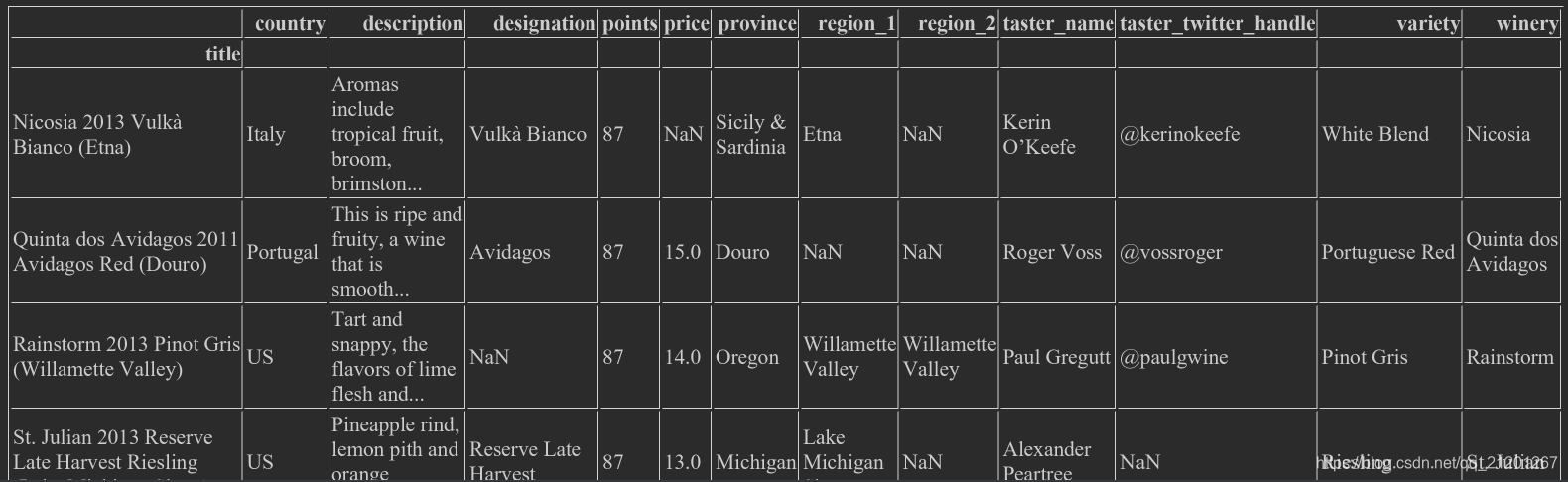
set_index()可以重新设置索引,wine_rev.set_index("title")
2.4 Conditional selection 按条件选择
2.4.1 布尔符号 &,|,==
wine_rev.country == 'US',按国家查找, 生成了Seriesof True/False,可用于loc
0 False1 False2 True3 True4 True ... 129966 False129967 True129968 False129969 False129970 FalseName: country, Length: 129971, dtype: bool
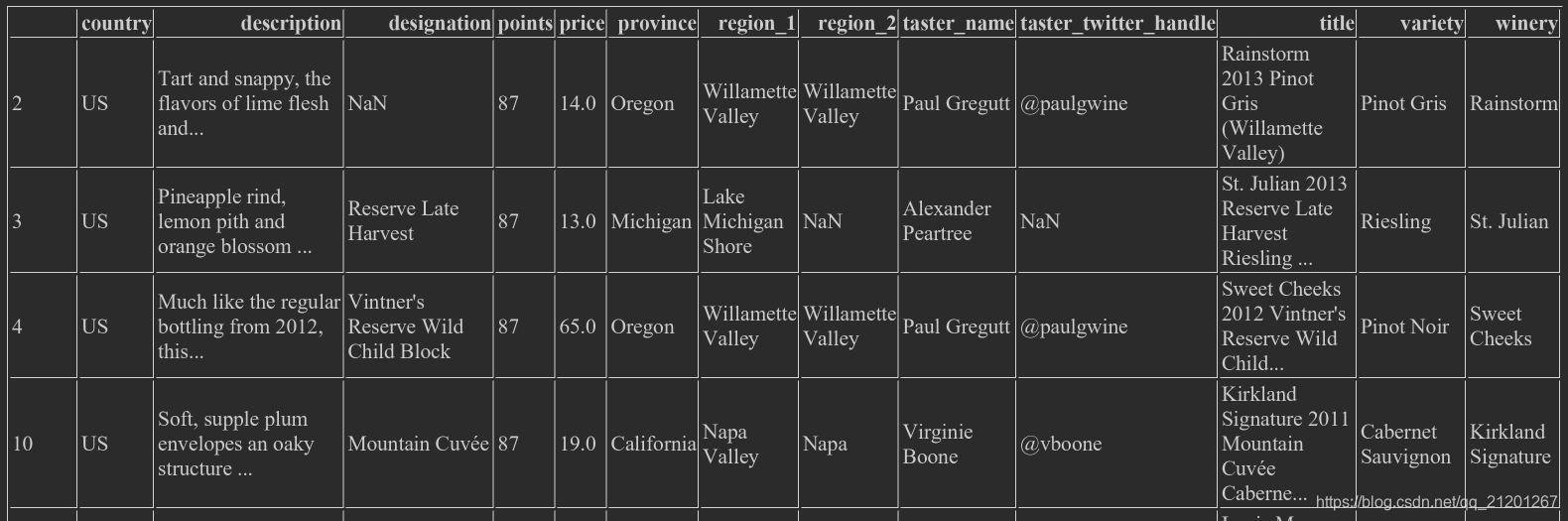
wine_rev.loc[wine_rev.country == 'US'],把 US 的行全部选出来
wine_rev.loc[(wine_rev.country == 'US') & (wine_rev.points >= 90)],US的&且得分90以上的- 还可以用
|表示或(像C++的位运算符号)
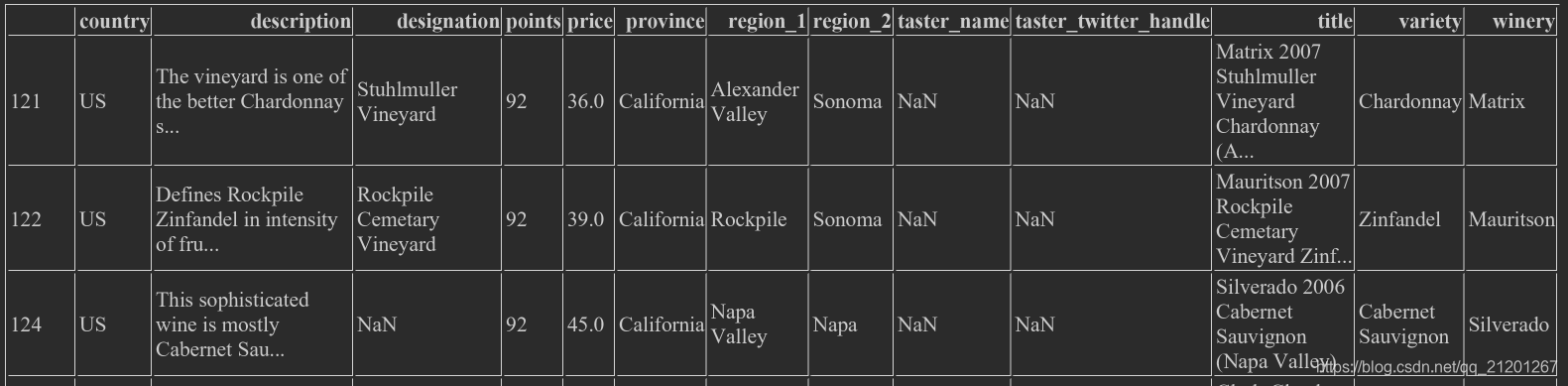
2.4.2 Pandas内置符号 isin,isnull、notnull
wine_rev.loc[wine_rev.country.isin(['US','Italy'])],只选 US 和 Italy 的行
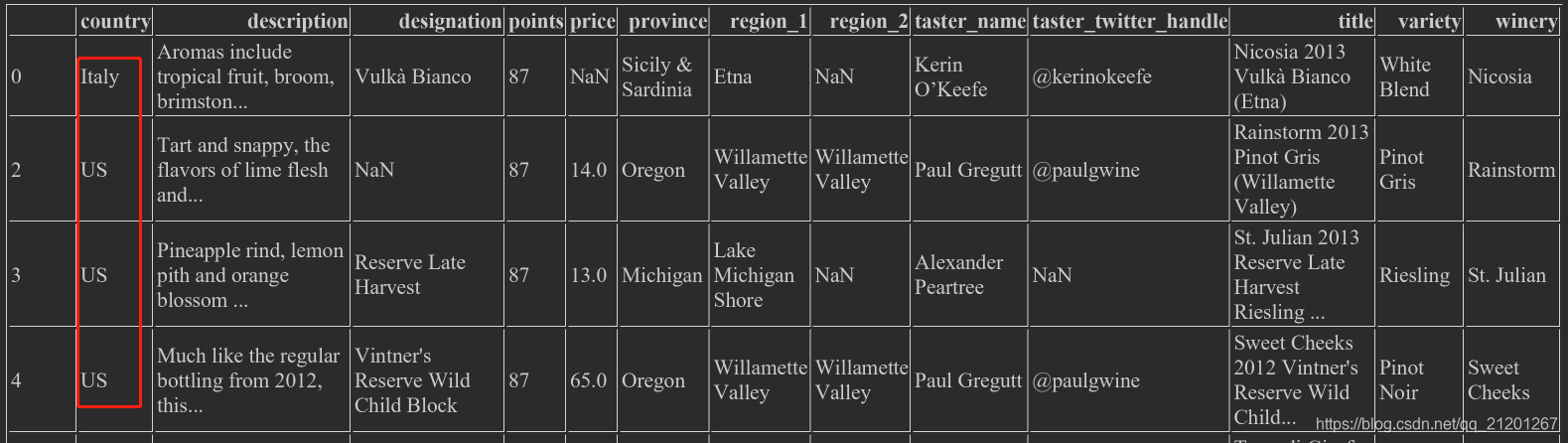
wine_rev.loc[wine_rev.price.notnull()],价格不为空的wine_rev.loc[wine_rev.price.isnull()],价格为NaN的
2.5 Assigning data 赋值
2.5.1 赋值常量
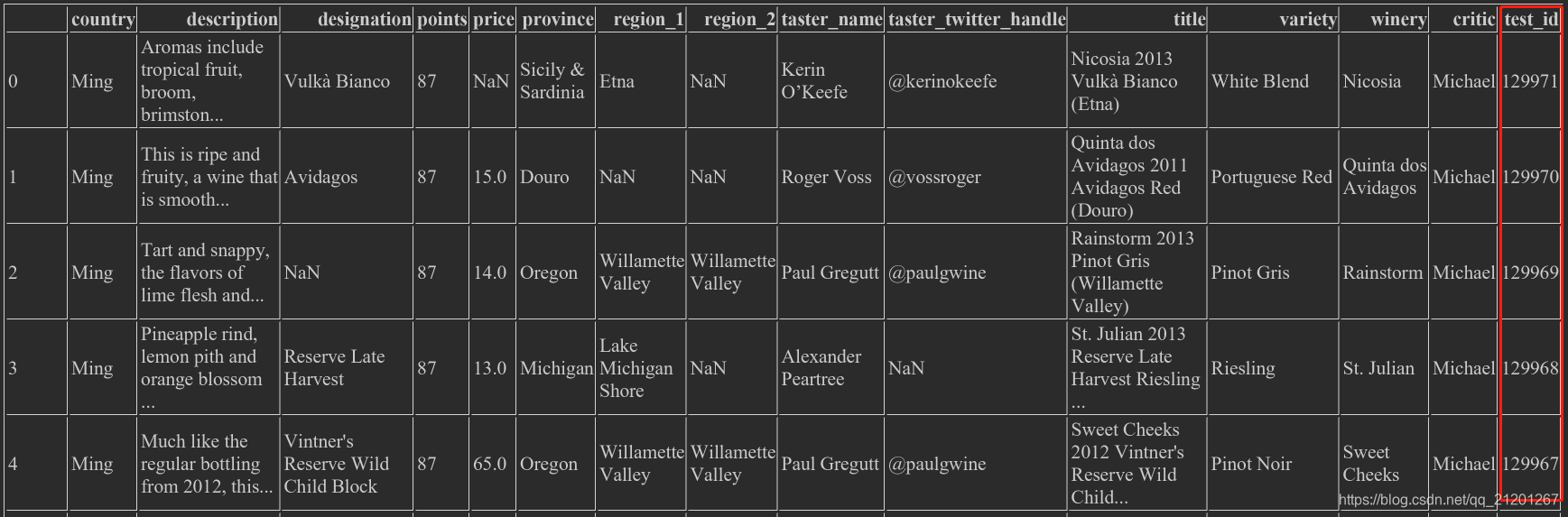
wine_rev['critic'] = 'Michael',新加了一列wine_rev.country = 'Ming',已有的列的value会直接被覆盖

2.5.2 赋值迭代的序列
wine_rev['test_id'] = range(len(wine_rev),0,-1)
下一篇:
转载地址:https://michael.blog.csdn.net/article/details/106164829 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过,博主的博客真漂亮。。
[***.116.15.85]2024年04月18日 00时21分10秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Spring Cloud构建微服务架构:分布式服务跟踪(入门)【Dalston版】
2019-05-03
Spring Cloud构建微服务架构:消息驱动的微服务(消费组)【Dalston版】
2019-05-03
TestNG系列-第四章 testNG之命令行运行及参数详解
2019-05-03
TestNG系列-第五章 测试方法、测试类和测试分组
2019-05-03
TestNG系列-第五章 测试方法、测试类和测试分组(续1)
2019-05-03
TestNG系列-第五章 测试方法、测试类和测试分组(续2)-参数
2019-05-03
ExecutorService中submit和execute的区别
2019-05-03
Zookeeper学习
2019-05-03
Dubbo教程
2019-05-03
Timer和ScheduledThreadPoolExecutor
2019-05-03
java多线程之-ScheduleExecutorService方法
2019-05-03
TestNG 学习总结 - 套件测试(七)
2019-05-03
TestNG 学习总结 - 忽略测试(八)
2019-05-03
TestNG 学习总结 - 分组执行测试(九)
2019-05-03
TestNG 学习总结 - 异常测试(十)
2019-05-03
TestNG 学习总结 - 依赖测试(十一)
2019-05-03
TestNG 学习总结 - 参数化测试(十二)
2019-05-03
TestNG 学习总结 - TestNG运行JUnit测试(十三)
2019-05-03
TestNG 学习总结 - 测试结果报告(十四)
2019-05-03
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311895153 位访客
访问时间: 2024-05-08 04:11:34
访问IP: 3.15.27.232
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版