本文共 3065 字,大约阅读时间需要 10 分钟。
文章目录
1. RMQ问题
RMQ(Range Minimum/Maximum Query) 区间最小/大值问题。给定一个 n n n 个元素的数组 A 1 , A 2 , A 3 , … , A n A_1, A_2, A_3, \dots, A_n A1,A2,A3,…,An ,设计一个数据结构,支持区间查询操作 QueryMin(L,R) :计算 min { A L , A L + 1 , … , A R } \min \{A_L, A_{L+1}, \dots, A_R\} min{ AL,AL+1,…,AR} ,也可以支持 QueryMax(L,R) (注意:这里的区间都是离散意义下的,只包含整数)。
如果每次用循环计算显然不够快, m m m 次的查询需要 O ( m n ) O(mn) O(mn) 的时间复杂度。而前缀和的思想也不能提升效率,因为这不是一个可加性信息。怎么办呢?
2. Sparse-Table
实践中最常用的是 Tarjan 的 Sparse-Table 算法,或者说ST表(稀疏表),一种简单的数据结构,主要用于处理RMQ问题。它使用倍增的思想,可以 O ( n log n ) O(n\log n) O(nlogn) 预处理, O ( 1 ) O(1) O(1) 查询,而且常数很小。最重要的是,这个算法非常还写,不易写错。
ST表使用一个二维数组 dp[][] ,对于范围内的所有 dp[a][b] ,先进行预处理,计算并存储 min i ∈ [ a , a + 2 b ) ( A i ) \min\limits_{i\in[a,\ a+2^b)}(A_i) i∈[a, a+2b)min(Ai) 。查询时,再利用这些子区间算出待求区间的最值。
(1) 预处理(动态规划)
为了减少时间,用动态规划进行预处理。我们让 dp[i][j] 表示从 i i i 开始的,长度为 2 j 2^j 2j 的一段元素中的最小值。基准条件是:dp[i][0] = A[i] ,此时区间 [i, i) 中最小值就是 A i A_i Ai 。
然后就可以用递推的方式计算 dp[i][j] : d p [ i ] [ j ] = min { d p [ i ] [ j − 1 ] , d p [ i + 2 j − 1 ] [ j − 1 ] } dp[i][j] = \min\{dp[i][j-1], dp[i+2^{j-1}][ j - 1]\} dp[i][j]=min{ dp[i][j−1],dp[i+2j−1][j−1]} 。原理如下图:


把长度为 2 j 2^j 2j 的区间 [ i , i + 2 j − 1 ] [i, i + 2^j - 1] [i,i+2j−1] 分成 [ i , i + 2 j − 1 − 1 ] [i, i + 2^{j-1} - 1] [i,i+2j−1−1] 和 [ i + 2 j − 1 , i + 2 j − 1 ] [i + 2^{j-1}, i + 2^j - 1] [i+2j−1,i+2j−1] 两个部分。于是按照定义,dp[i][j] 就等于前半段的最小值 dp[i][j - 1] 和后半段的最小值 dp[i + (1 << (j - 1))][j - 1] 这两者中更小者。
注意 2 j ≤ n 2^j \le n 2j≤n ,于是 dp[][] 数组的元素个数不超过 n log n n\log n nlogn ,每一项都可以在常数时间计算完成,因此总时间为 O ( n log n ) O(n\log n) O(nlogn) 。代码如下:
int dp[MAXN[21]; //第二维度的大小根据数据范围确定,不小于log(MAXN)//元素编号从1~n,因为区间从1~nint RMQ_init() { for (int i = 1; i <= n; ++i) dp[i][0] = A[i]; //读入数据,基准 for (int j = 1; (1 << j) <= n; ++j) for (int i = 1; i + (1 << j) - 1 <= n; ++i) dp[i][j] = min(dp[i][j - 1], dp[i + (1 << (j - 1))][j - 1]);} (2) 区间查询
查询操作很简单,令 k k k 为满足 2 k ≤ R − L + 1 2^k \le R-L+1 2k≤R−L+1 的最大整数,则以 L L L 开头、以 R R R 结尾的两个长度为 2 k 2^k 2k 的区间合起来则覆盖了查询区间 [ L , R ] [L, R] [L,R] 。由于取最值,有些元素重复考虑也没关系(如果是区间累加,重复元素是不允许的)。如下图:
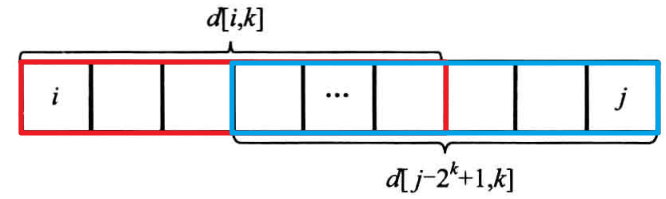 所以我们只要找到两个 [ L , R ] [L,R] [L,R] 的子区间,它们的并集恰好是 [ L , R ] [L, R] [L,R] ,可以相交但是不可以超出区间范围。这两个区间的长度都为 k k k ,分别是 [ L , L + 2 k − 1 ] [L, L + 2^k - 1] [L,L+2k−1] 和 [ R − 2 k + 1 , R ] [R - 2^k + 1, R] [R−2k+1,R] ,前一个子区间的右端点尽可能接近 R R R ,后一个子区间的左端点尽可能接近 L L L 。可知: L + 2 k − 1 = R L + 2^k - 1 = R L+2k−1=R 时,有 k = log 2 ( R − L + 1 ) k = \log_2(R-L+1) k=log2(R−L+1) ,这时 R − 2 k + 1 = L R - 2^k + 1 = L R−2k+1=L 也成立。
所以我们只要找到两个 [ L , R ] [L,R] [L,R] 的子区间,它们的并集恰好是 [ L , R ] [L, R] [L,R] ,可以相交但是不可以超出区间范围。这两个区间的长度都为 k k k ,分别是 [ L , L + 2 k − 1 ] [L, L + 2^k - 1] [L,L+2k−1] 和 [ R − 2 k + 1 , R ] [R - 2^k + 1, R] [R−2k+1,R] ,前一个子区间的右端点尽可能接近 R R R ,后一个子区间的左端点尽可能接近 L L L 。可知: L + 2 k − 1 = R L + 2^k - 1 = R L+2k−1=R 时,有 k = log 2 ( R − L + 1 ) k = \log_2(R-L+1) k=log2(R−L+1) ,这时 R − 2 k + 1 = L R - 2^k + 1 = L R−2k+1=L 也成立。 最后不忘取整,所以 k = ⌊ log 2 ( R − L + 1 ) ⌋ k = \lfloor \log_2(R - L+1) \rfloor k=⌊log2(R−L+1)⌋ 。另外,每次计算log有点费事,这里对log也进行一次递推预处理:
for (int i = 2; i <= n; ++i) Log2[i] = Log2[i / 2] + 1;
这两个区间对应的 dp[][] 分别是 dp[L][k] 和 dp[R - (1 << k) + 1][k] 。所以代码很好写:
int RMQ(int L, int R) { //int k = 0; //while ((1 << (k + 1)) <= R - L + 1) ++k; int k = Log2[R - L + 1]; return min(dp[L][k], dp[R - (1 << k) + 1][k]);} 3. 扩展
ST不仅能够处理最大值或者最小值,凡是符合结合律且可重复贡献的信息查询,都可以使用ST表高效处理。
可重复贡献意为:一个二元运算 f ( x , y ) f(x, y) f(x,y) ,满足 f ( a , a ) = a f(a, a) = a f(a,a)=a ,则 f f f 是可重复贡献的。显然,最大值、最小值、最大公因数、最小公倍数、按位或、按位与都符合这个条件。它的意义在于:能够对两个交集不为空的区间进行信息合并。
4. 题目
转载地址:https://memcpy0.blog.csdn.net/article/details/108374025 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
