kaggle研究生招生(下)
 聚类算法比较
聚类算法比较
发布日期:2021-07-01 02:16:49
浏览次数:4
分类:技术文章
本文共 3252 字,大约阅读时间需要 10 分钟。
对于该数据先采用回归算法,再转为分类算法,这次使用聚类算法
聚类算法(无监督机器学习算法)
df = pd.read_csv("../input/Admission_Predict.csv",sep = ",")df=df.rename(columns = {'Chance of Admit ':'ChanceOfAdmit'})serial = df["Serial No."]df.drop(["Serial No."],axis=1,inplace = True)df = (df- np.min(df))/(np.max(df)-np.min(df))y = df.ChanceOfAdmit x = df.drop(["ChanceOfAdmit"],axis=1) 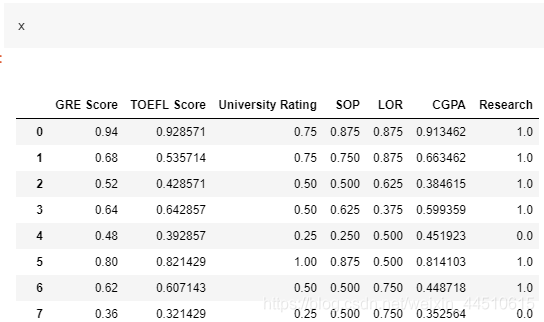
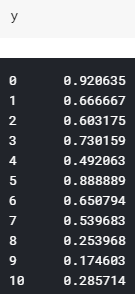
所有特征(x)均采用主成分分析法收集在一个特征中。
PCA
# for data visualizationfrom sklearn.decomposition import PCApca = PCA(n_components = 1, whiten= True ) # whitten = normalizepca.fit(x)x_pca = pca.transform(x)x_pca = x_pca.reshape(400,)dictionary = {"x":x_pca,"y":y}data = pd.DataFrame(dictionary)print("data:")print(data.head())print("\ndf:")print(df.head()) 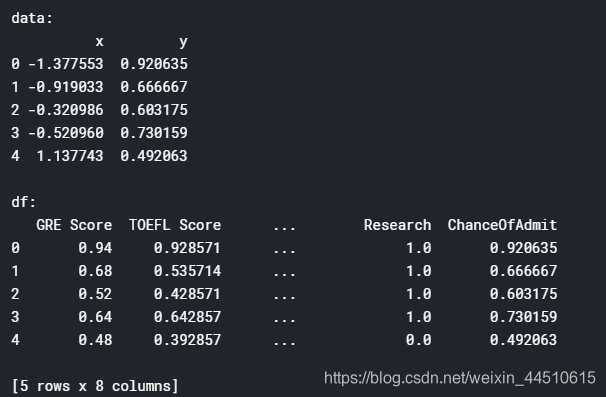
K-means
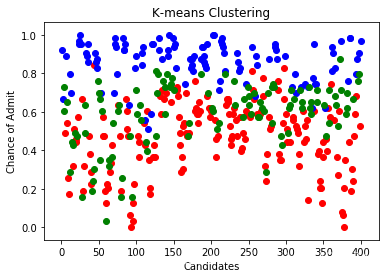
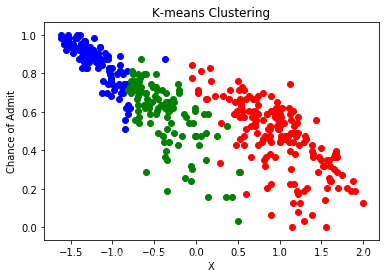
利用肘形法确定K均值聚类的最佳聚类数是3
df["Serial No."] = serialfrom sklearn.cluster import KMeanswcss = []for k in range(1,15): kmeans = KMeans(n_clusters=k) kmeans.fit(x) wcss.append(kmeans.inertia_)plt.plot(range(1,15),wcss)plt.xlabel("k values")plt.ylabel("WCSS")plt.show()kmeans = KMeans(n_clusters=3)clusters_knn = kmeans.fit_predict(x)df["label_kmeans"] = clusters_knnplt.scatter(df[df.label_kmeans == 0 ]["Serial No."],df[df.label_kmeans == 0].ChanceOfAdmit,color = "red")plt.scatter(df[df.label_kmeans == 1 ]["Serial No."],df[df.label_kmeans == 1].ChanceOfAdmit,color = "blue")plt.scatter(df[df.label_kmeans == 2 ]["Serial No."],df[df.label_kmeans == 2].ChanceOfAdmit,color = "green")plt.title("K-means Clustering")plt.xlabel("Candidates")plt.ylabel("Chance of Admit")plt.show()df["label_kmeans"] = clusters_knnplt.scatter(data.x[df.label_kmeans == 0 ],data[df.label_kmeans == 0].y,color = "red")plt.scatter(data.x[df.label_kmeans == 1 ],data[df.label_kmeans == 1].y,color = "blue")plt.scatter(data.x[df.label_kmeans == 2 ],data[df.label_kmeans == 2].y,color = "green")plt.title("K-means Clustering")plt.xlabel("X")plt.ylabel("Chance of Admit")plt.show() 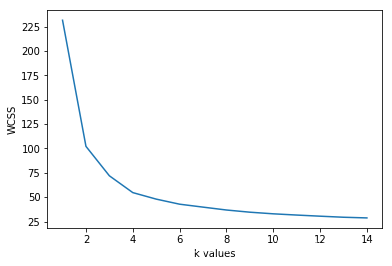
层次聚类
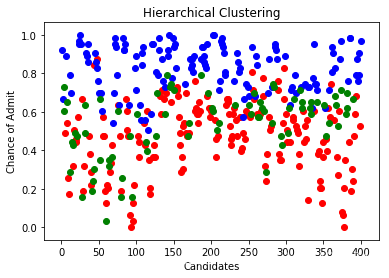
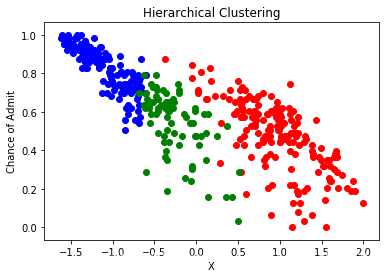
采用树形图方法确定了层次聚类的最佳聚类数又是3
df["Serial No."] = serialfrom scipy.cluster.hierarchy import linkage, dendrogrammerg = linkage(x,method="ward")dendrogram(merg,leaf_rotation = 90)plt.xlabel("data points")plt.ylabel("euclidean distance")plt.show()from sklearn.cluster import AgglomerativeClusteringhiyerartical_cluster = AgglomerativeClustering(n_clusters = 3,affinity= "euclidean",linkage = "ward")clusters_hiyerartical = hiyerartical_cluster.fit_predict(x)df["label_hiyerartical"] = clusters_hiyerarticalplt.scatter(df[df.label_hiyerartical == 0 ]["Serial No."],df[df.label_hiyerartical == 0].ChanceOfAdmit,color = "red")plt.scatter(df[df.label_hiyerartical == 1 ]["Serial No."],df[df.label_hiyerartical == 1].ChanceOfAdmit,color = "blue")plt.scatter(df[df.label_hiyerartical == 2 ]["Serial No."],df[df.label_hiyerartical == 2].ChanceOfAdmit,color = "green")plt.title("Hierarchical Clustering")plt.xlabel("Candidates")plt.ylabel("Chance of Admit")plt.show()plt.scatter(data[df.label_hiyerartical == 0 ].x,data.y[df.label_hiyerartical == 0],color = "red")plt.scatter(data[df.label_hiyerartical == 1 ].x,data.y[df.label_hiyerartical == 1],color = "blue")plt.scatter(data[df.label_hiyerartical == 2 ].x,data.y[df.label_hiyerartical == 2],color = "green")plt.title("Hierarchical Clustering")plt.xlabel("X")plt.ylabel("Chance of Admit")plt.show() 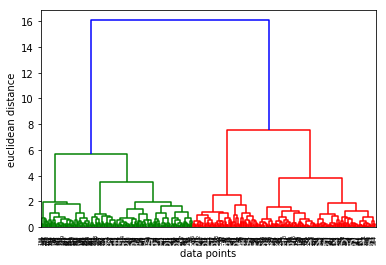
聚类算法比较 k-均值聚类和层次聚类是相似的。
总结
- 任何一个数据都可以进行回归,分类,甚至聚类的算法,关键如何处理数据采用不同种类的算法
转载地址:https://maoli.blog.csdn.net/article/details/92021326 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月18日 13时14分08秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
linux awk 内置变量使用介绍
2021-07-05
MYSQL-- 每半月一个分区,自动维护
2021-07-05
MySQL的表分区
2021-07-05
mysql show processlist分析
2021-07-05
Java Thread 总结
2021-07-05
Jetty的架构
2021-07-05
java多线程
2021-07-05
maven打包可运行的JAR
2021-07-05
linux sar 命令详解
2021-07-05
LINUX 使用管道实现无需落地文件GZIP压缩
2021-07-05
pure-ftp 启用虚拟账户的问题
2021-07-05
ipvsadm 安装配置
2021-07-05
linux下nc的使用
2021-07-05
sed学习---字符替换
2021-07-05
Linux shell脚本的字符串截取
2021-07-05
linux和windows下mysql密码怎样清空!
2021-07-05
mysql logs-slave-updates (A -> B -> C)
2021-07-05
关于Java中split方法对空字符串处理问题
2021-07-05
mysql JDBC URL参数解析
2021-07-05
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311641836 位访客
访问时间: 2024-05-07 07:57:20
访问IP: 18.221.98.71
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版