本文共 2417 字,大约阅读时间需要 8 分钟。
一、集群安装条件前置
实验spark安装在【】机器上, 已完成安装zookeeper、jdk、hadoop和ssh、网络等配置环境等。
spark所依赖的虚拟机和操作系统配置
环境:ubuntu14 + spark-2.4.4-bin-hadoop2.6 + apache-zookeeper-3.5.6 + jdk1.8+ssh
虚拟机:(vmware10)
二、standalone安装环境设置
(1)下载spark
官网,由于本人使用hadoop2.6,所有下载。

(2)上传到linux系统解压
tar xvf spark-2.4.4-bin-hadoop2.6.tar.gz #放在统一的软件目录下mv spark-2.4.4-bin-hadoop2.6 software/#别名ln -s software/spark-2.4.4-bin-hadoop2.6 spark-2.4.4
(3) 配置spark-env.sh
cd ~/spark-2.4.4/conf/cp spark-env.sh.template spark-env.shvim spark-env.sh
编辑spark-env.sh添加以下内容
#与zk的adminServer端口8080冲突改为8082SPARK_MASTER_WEBUI_PORT="8082"#单机器work的数量SPARK_WORK_INSTANCES="1"#zk选spark主export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181 -Dspark.deploy.zooleeper.dir=/spark"export JAVA_HOME=/home/mk/jdk1.8
(4)配置slaves
cd ~/spark-2.4.4/conf/cp slaves.template slavesvim slaves
编辑slaves添加以下内容
hadoop01hadoop02hadoop03
(5)复制到hadoop02、hadoop03
scp -r /home/mk/software/spark-2.4.4-bin-hadoop2.6 mk@hadoop02:/home/mk/software/scp -r /home/mk/software/spark-2.4.4-bin-hadoop2.6 mk@hadoop03:/home/mk/software/#hadoop02机器别名ln -s software/spark-2.4.4-bin-hadoop2.6 spark-2.4.4#hadoop03机器别名ln -s software/spark-2.4.4-bin-hadoop2.6 spark-2.4.4
三、启动spark
(1)启动zookeeper
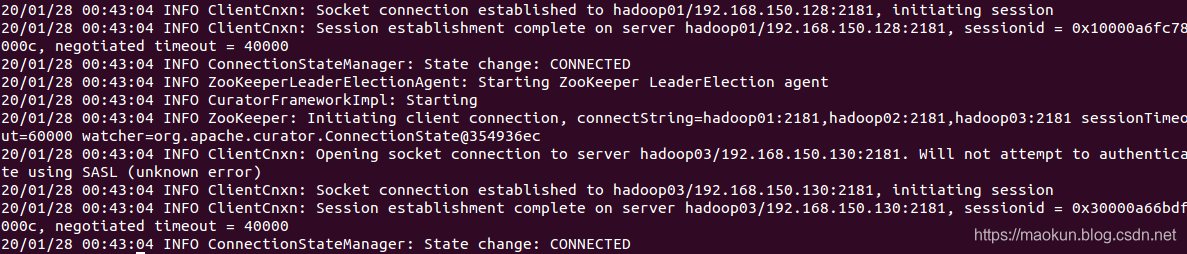
hadoop01、hadoop02、hadoop03分别启动zk
~/software/apache-zookeeper-3.5.6-bin/bin/zkServer.sh start
(2)启动spark master
hadoop01启动master
~/spark-2.4.4/sbin/start-master.sh

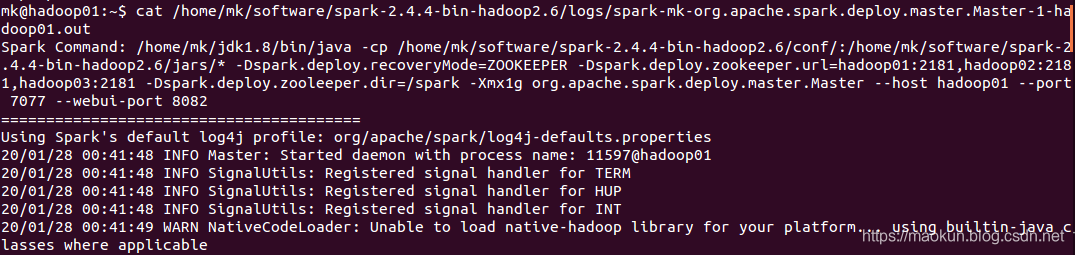
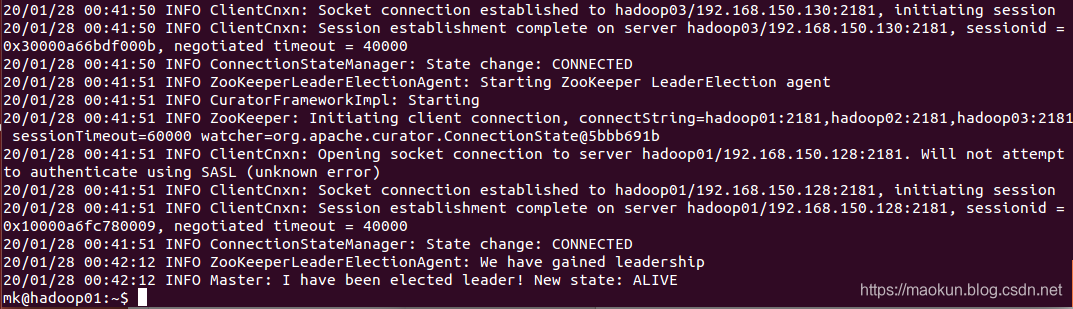
hadoop02启动master


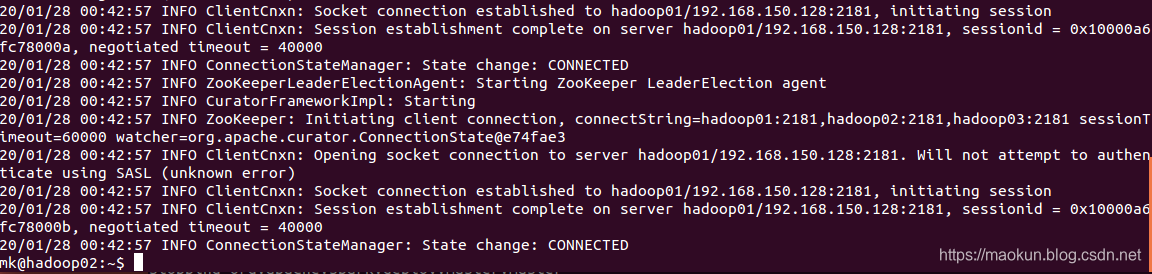
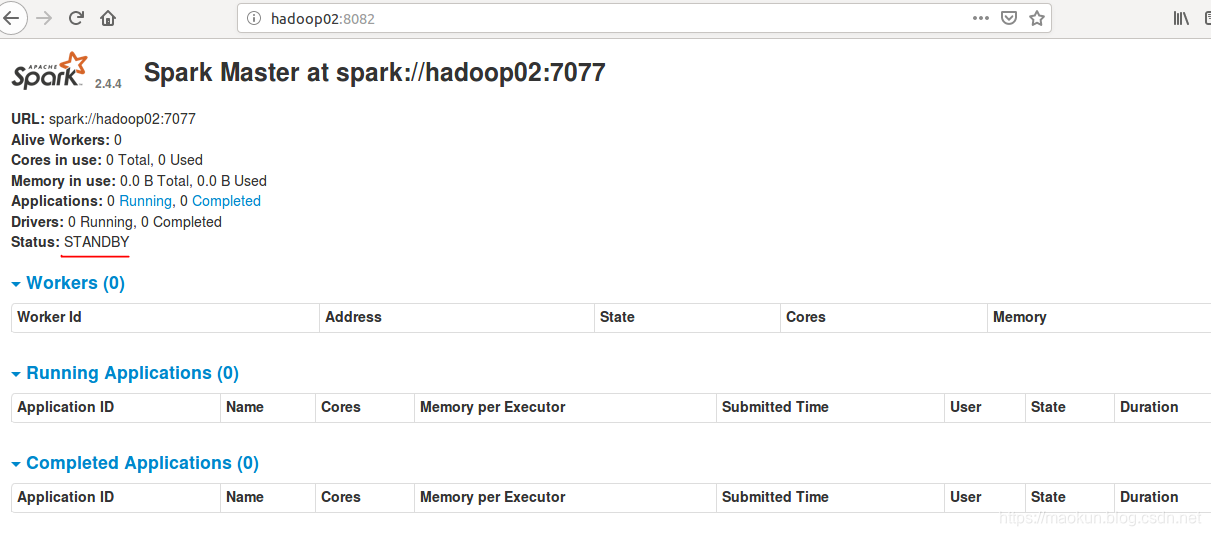
hadoop03启动master



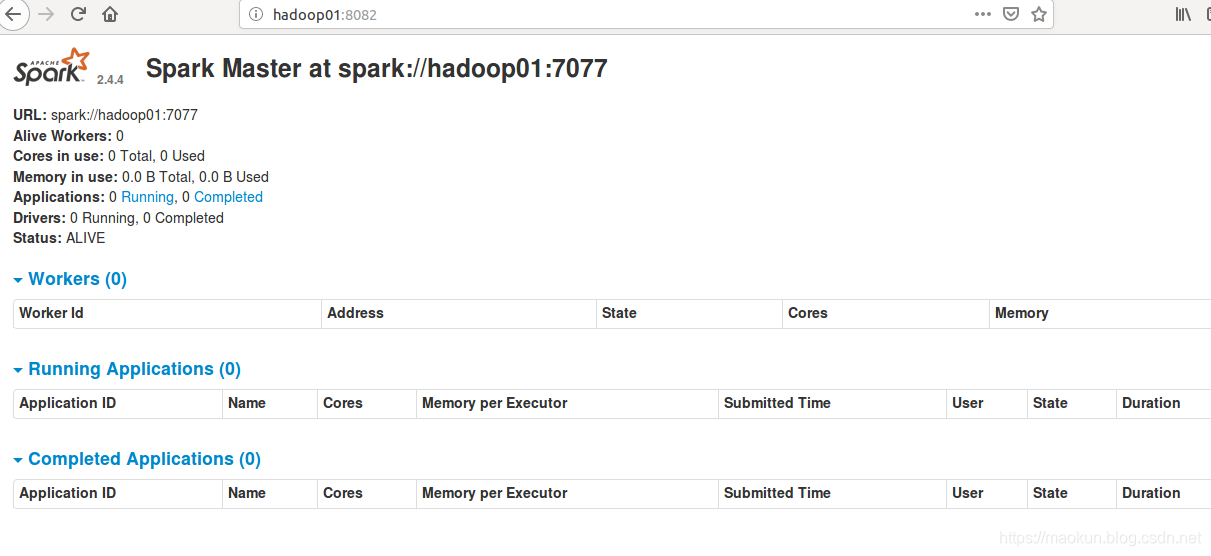
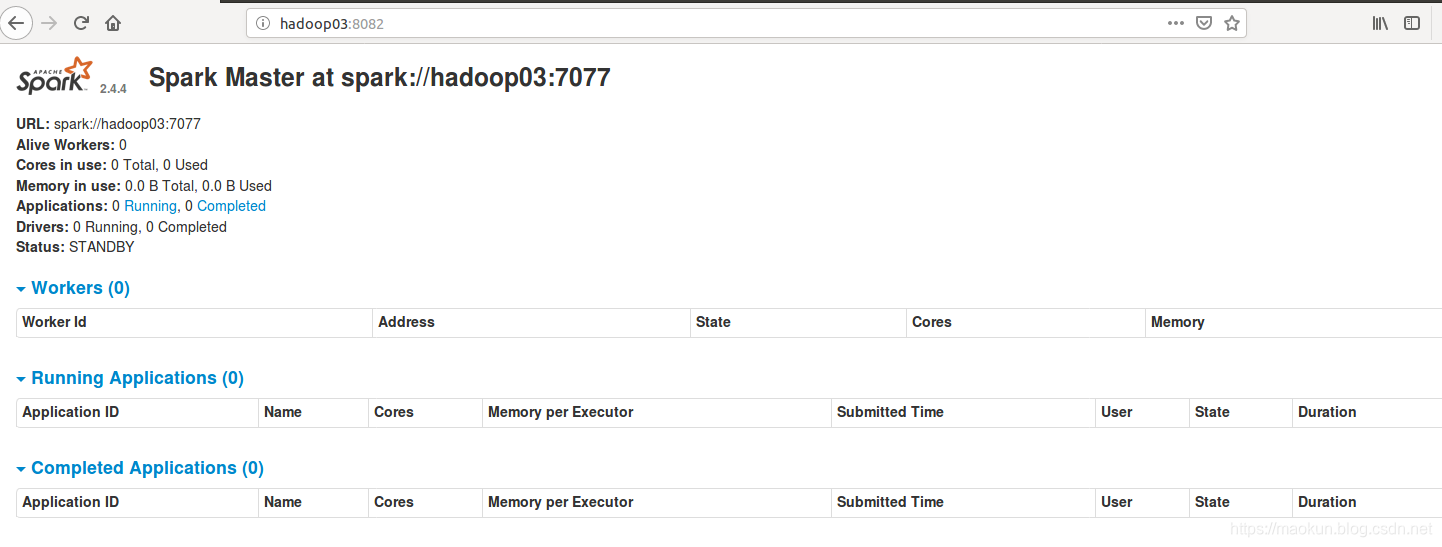
master启动成功。
sparkUI浏览器进行访问
(2)在集群主master启动worker
注意:一定要在主节点上启动worker,否则worker不能注册到主节点。
应该在启动第一个master节点的时候使用start-all.sh代替start-master.sh+start-slaves.sh,避免worker在非主节点启动注册不上

hadoop01检查

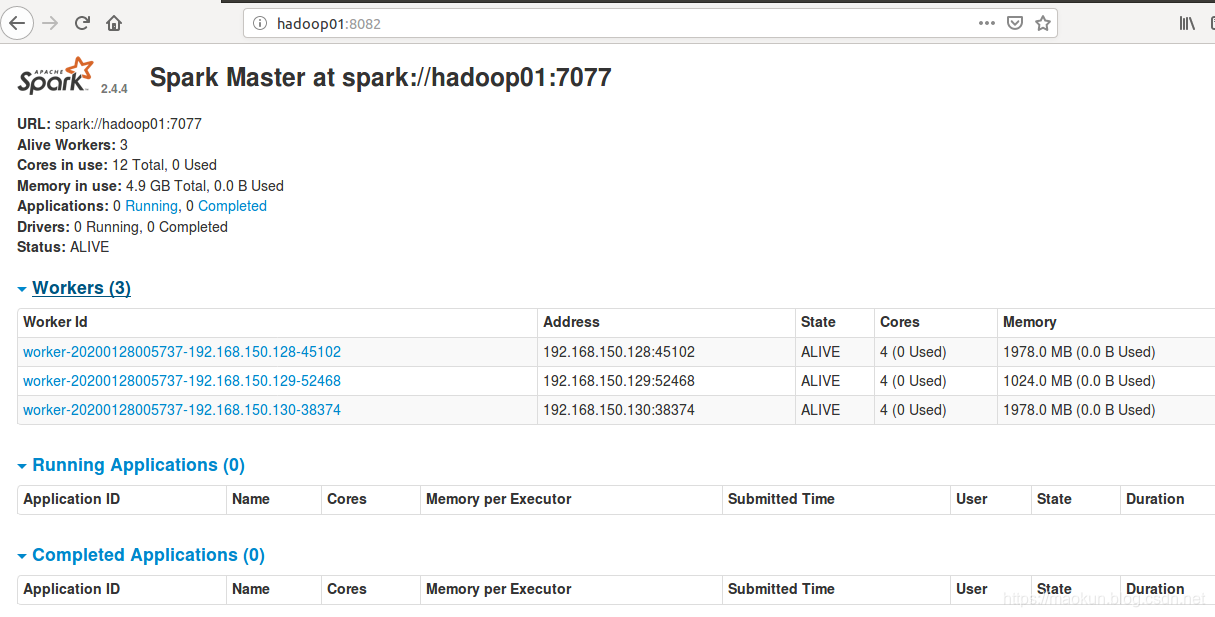
hadoop02检查


hadoop03检查
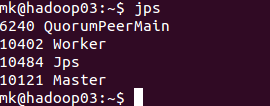
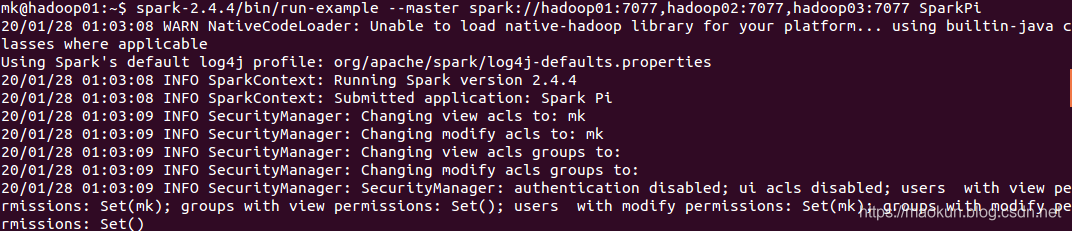
(3)运行spark计算PI例子
~/spark-2.4.4/bin/run-example --master spark://hadoop01:7077,hadoop02:7077,hadoop03:7077 SparkPi
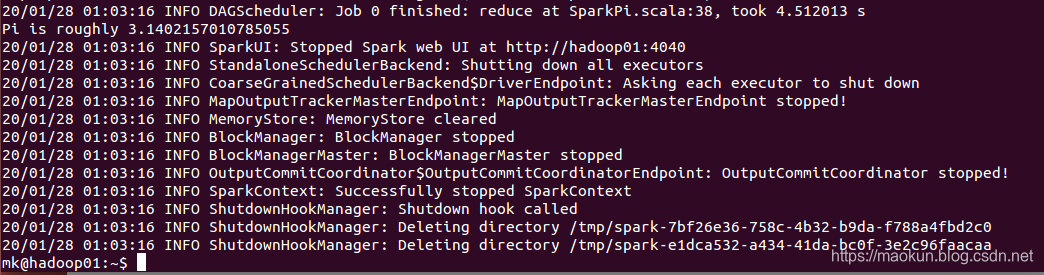
Pi is roughly 3.1402157010785055
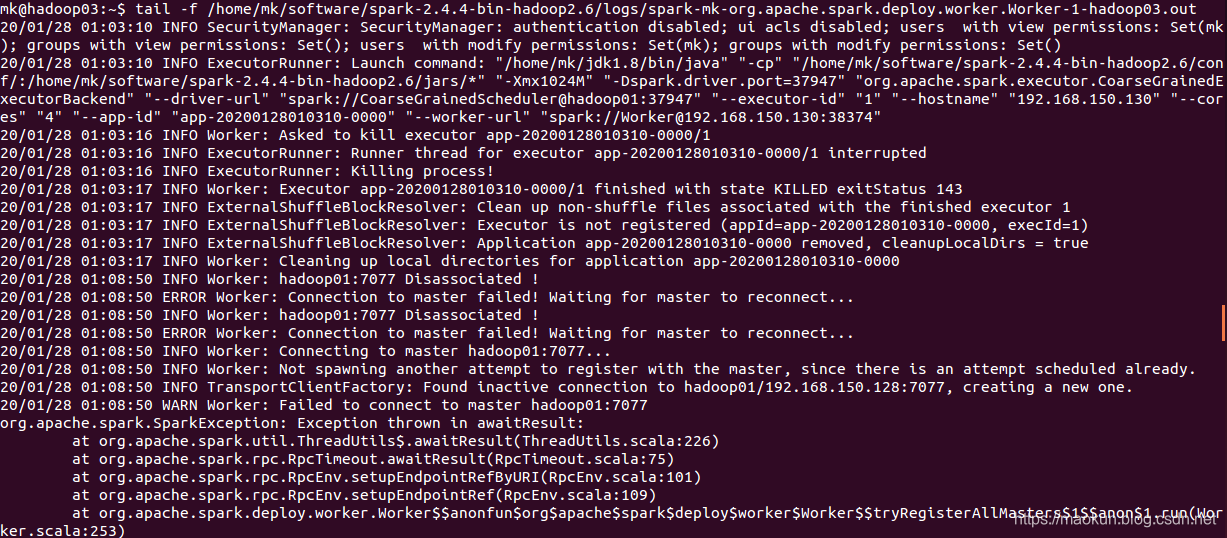
(4)停止hadoop01 master和worker检查主节点切换
#hadoop01停止master和worker~/software/spark-2.4.4-bin-hadoop2.6/sbin/stop-master.sh~/software/spark-2.4.4-bin-hadoop2.6/sbin/stop-slave.sh#hadoop03监听主节点切换日志tail -f /home/mk/software/spark-2.4.4-bin-hadoop2.6/logs/spark-mk-org.apache.spark.deploy.worker.Worker-1-hadoop03.out

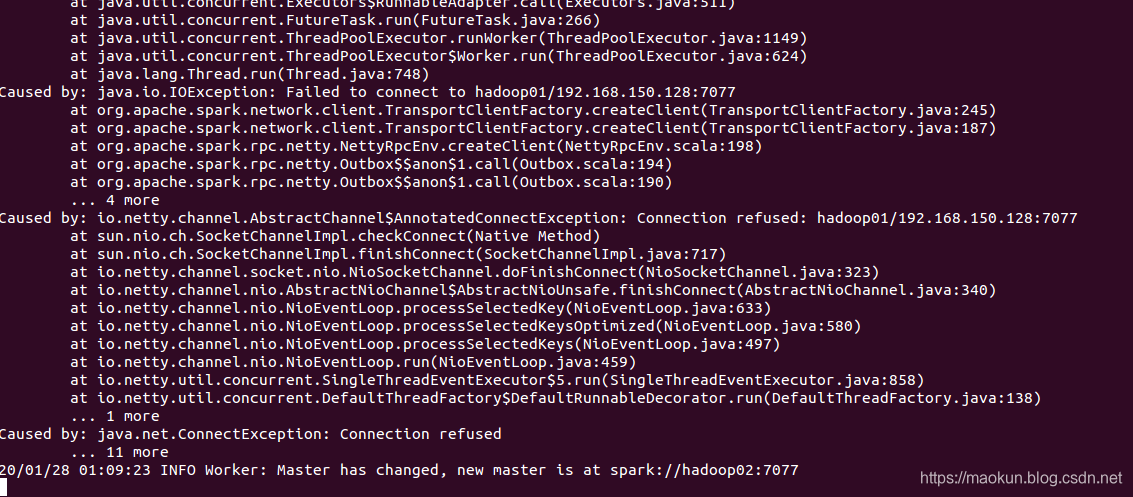
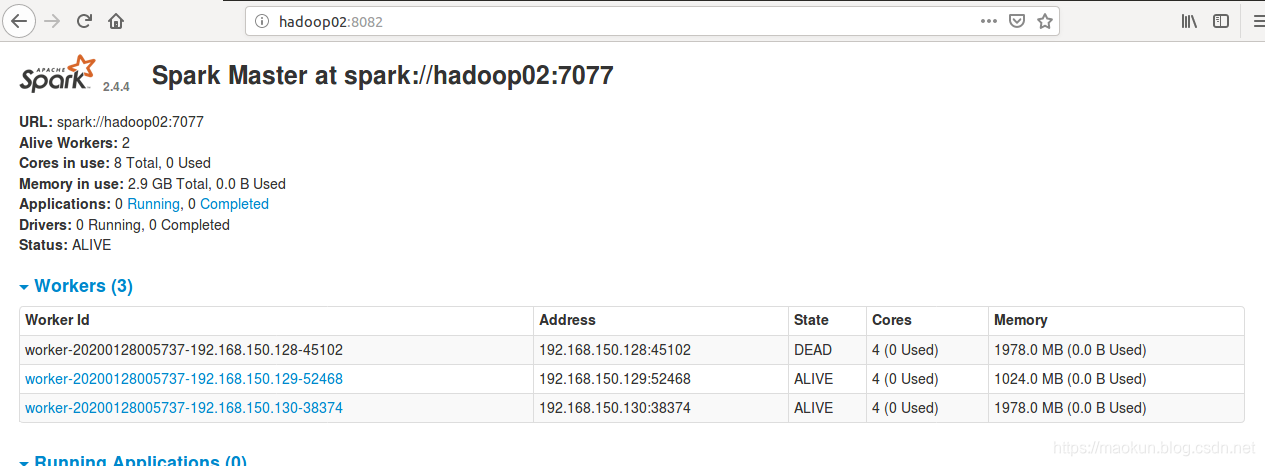
(5)在hadoop01重新执行计算PI
spark-2.4.4/bin/run-example --master spark://hadoop01:7077,hadoop02:7077,hadoop03:7077 SparkPi
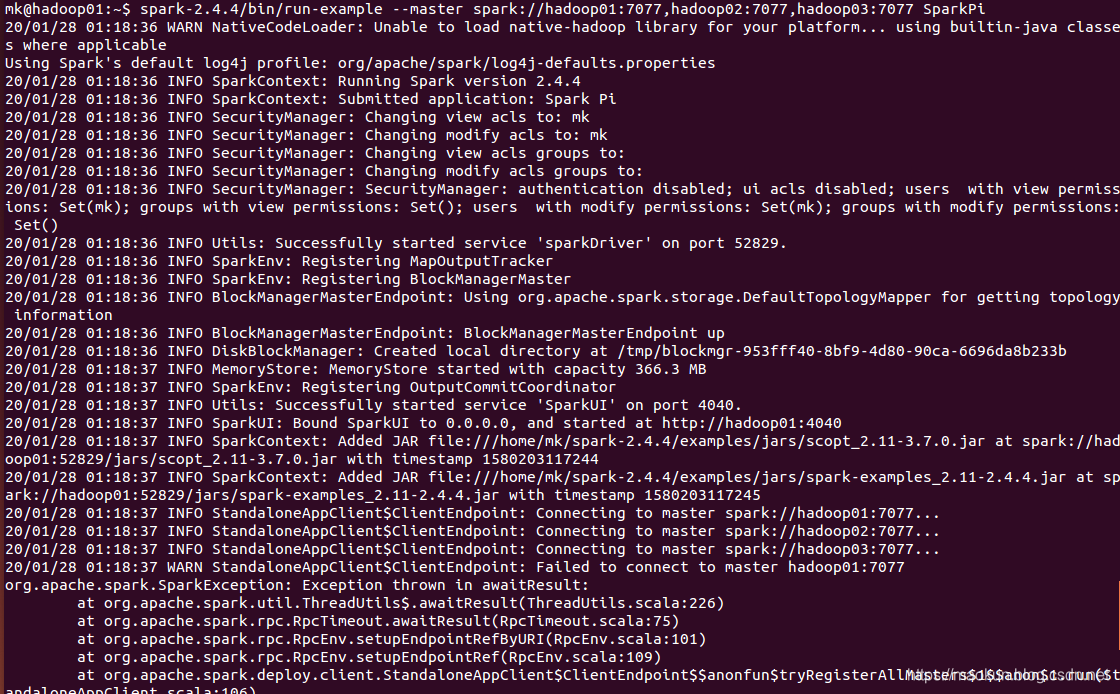
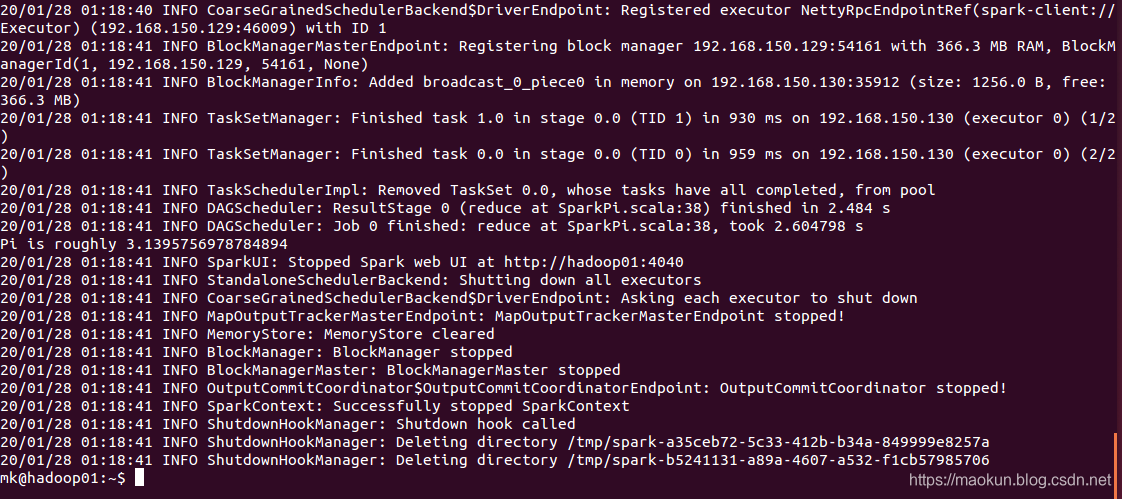
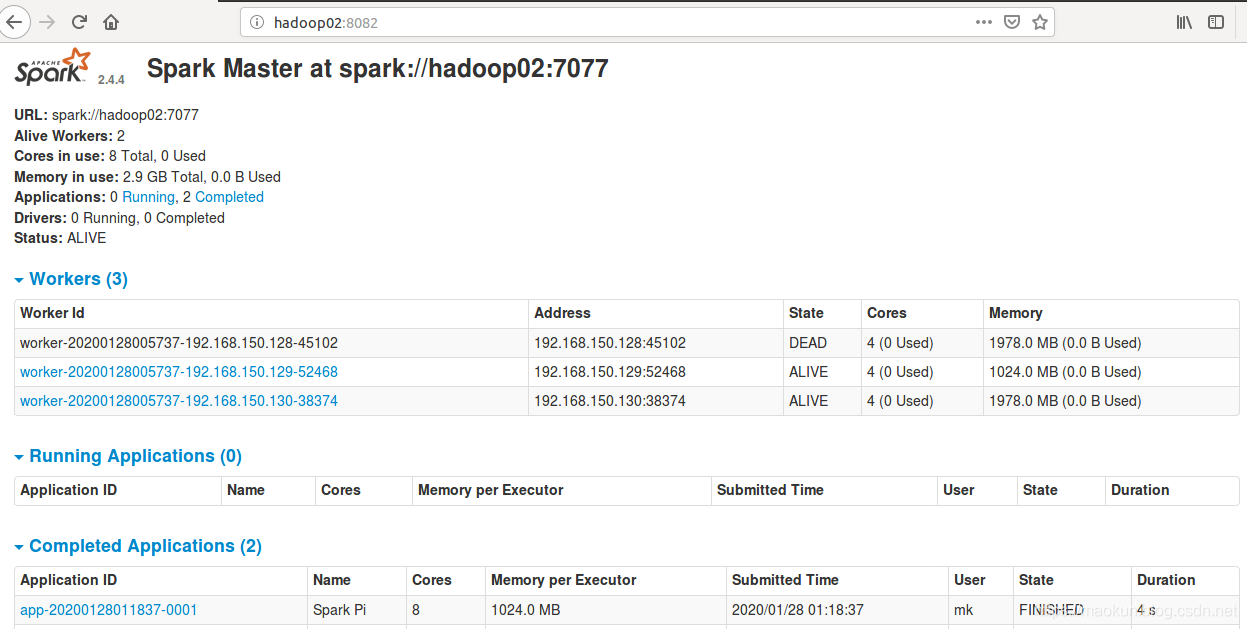
(6)关闭spark
#主节点执行~/spark-2.4.4/sbin/stop-all.sh#或者~/spark-2.4.4/sbin/stop-master.sh~/spark-2.4.4/sbin/stop-slaves.sh#其他master节点执行~/spark-2.4.4/sbin/stop-master.sh
转载地址:https://maokun.blog.csdn.net/article/details/104099237 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
