本文共 7949 字,大约阅读时间需要 26 分钟。
如何利用情感词典做中文文本的情感分析?
这是本学期在大数据哲学与社会科学实验室做的第四次分享了。
第一次分享的是:
第二次分享的是:
第三次分享的是:
本次给大家分享的是利用情感词典进行中文文本分类的方法,这种方法是对人的记忆和判断思维的最简单的模拟,如图所示。
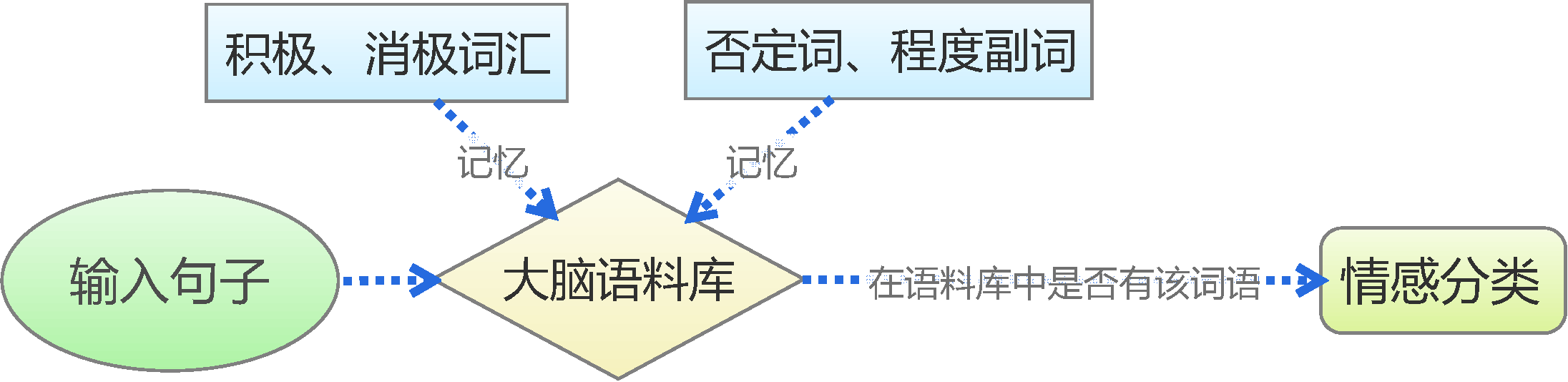
我们首先通过学习来记忆一些基本词汇,如否定词语有“不”,积极词语有“喜欢”、“爱”,消极词语有“讨厌”、“恨”等,从而在大脑中形成一个基本的语料库。
然后,我们再对输入的句子进行最直接的拆分,看看我们所记忆的词汇表中是否存在相应的词语。
接着,根据这个词语的类别来判断情感,比如“我喜欢数学”,“喜欢”这个词在我们所记忆的积极词汇表中,所以我们判断它具有积极的情感。
基于上述思路,我们可以通过以下几个步骤实现基于情感词典的中文文本情感分类:
- Step01:准备各类词典(积极情感词典、消极情感词典、否定词词典、程度副词词典)
- Step02:对句子进行分词
- Step03:进行情感判断
整个过程如下图所示。

1. 准备各类词典
一般来说,词典是文本感情分类最核心的地方。情感词典通常分为四个部分:积极情感词典、消极情感词典、否定词典以及程度副词词典。
目前最常用的词典(微信后台回复“资料下载”可获取这些词典和代码)如下:
- 清华大学李军中文褒贬义词典
- Hownet知网情感词典
- 台湾大学NTUSD
- 大连理工大学中文情感词汇本体库
本文用到的词典如下:

2. 句子分词
Python中比较常用的分词库是“jieba”,俗称“结巴分词”。
安装“jieba”的过程也比较简单,支持Python的pip安装,命令如下:
pip install jieba
“jieba”常用的函数非常少,通常只有一个cut()函数。
cut(sentence, cut_all=False, HMM=True):将包含中文的整个句子分割成单独的词。
sentence:要进行分词的句子。cut_all:模型类型,True表示完整模式,False表示准确模式。HMM:是否使用隐马尔可夫模型。
下面通过简单的例子来讲述如何使用结巴分词。
【例子】利用准确模式分词。
import jiebatext = "中华民族创造了悠久灿烂的中华文明,为人类作出了卓越贡献。"words = list(jieba.cut(text, cut_all=False))print(words)# ['中华民族', '创造', '了', '悠久', '灿烂', '的', '中华文明', ',', '为', '人类', '作出', '了', '卓越贡献', '。']
【例子】利用完整模式分词。
import jiebatext = "中华民族创造了悠久灿烂的中华文明,为人类作出了卓越贡献。"words = list(jieba.cut(text, cut_all=True))print(words)# ['中华', '中华民族', '民族', '创造', '了', '悠久', '灿烂', '的', '中华', '中华文明', '华文', '文明', '', '', '为', '人类', '作出', '了', '卓越', '卓越贡献', '贡献', '', '']
3. 情感判断
基于情感词典的文本情感分类规则比较机械化。
简单起见,我们将每个积极情感词语赋予权重“1”,将每个消极情感词语赋予权重“-1”,并且假设情感值满足线性叠加原理。如果句子分词后的词语向量包含相应的词语,就加上向前的权值,其中,否定词和程度副词会有特殊的判别规则,否定词会导致权值反号,而程度副词则根据修饰的程度加上相应的数值,在本文档中将权重分为1~6,6个档次(感叹号为第2档)。最后,根据总权值的正负性来判断句子的情感。
以下代码用于加载词典:
def loadDict(fileName, score): wordDict = { } with open(fileName) as fin: for line in fin: word = line.strip() wordDict[word] = score return wordDictdef appendDict(wordDict, fileName, score): with open(fileName) as fin: for line in fin: word = line.strip() wordDict[word] = scoredef loadExtentDict(fileName, level): extentDict = { } for i in range(level): with open(fileName + str(i + 1) + ".txt") as fin: for line in fin: word = line.strip() extentDict[word] = i + 1 return extentDict 以下代码用于给词汇赋权值:
postDict = loadDict(u"sentimentDict/积极情感词语.txt", 1) # 积极情感词典negDict = loadDict(u"sentimentDict/消极情感词语.txt", -1) # 消极情感词典inverseDict = loadDict(u"sentimentDict/否定词语.txt", -1) # 否定词词典extentDict = loadExtentDict(u"sentimentDict/程度级别词语", 6)punc = loadDict(u"sentimentDict/标点符号.txt", 1)exclamation = { "!": 2, "!": 2} 以下代码是具体的规则:
totalScore = 0 # 记录最终情感得分lastWordPos = 0 # 记录情感词的位置lastPuncPos = 0 # 记录标点符号的位置i = 0 # 记录扫描到的词的位置for word in wordList: if word in punc: lastPuncPos = i if word in postDict: # 积极情感词语处理的规则 if lastWordPos > lastPuncPos: start = lastWordPos else: start = lastPuncPos score = 1 for word_before in wordList[start:i]: # 前面是否有否定词和副词 if word_before in extentDict: score = score * extentDict[word_before] if word_before in inverseDict: score = score * -1 for word_after in wordList[i + 1:]: # 后面是否带感叹号 if word_after in punc: if word_after in exclamation: score = score + 2 else: break lastWordPos = i totalScore += score elif word in negDict: # 消极情感词语处理的规则 if lastWordPos > lastPuncPos: start = lastWordPos else: start = lastPuncPos score = -1 for word_before in wordList[start:i]: # 前面是否有否定词和副词 if word_before in extentDict: score = score * extentDict[word_before] if word_before in inverseDict: score = score * -1 for word_after in wordList[i + 1:]: # 后面是否带感叹号 if word_after in punc: if word_after in exclamation: score = score - 2 else: break lastWordPos = i totalScore += score i = i + 1
4. 补充说明
在如今的网络信息时代,新词的出现如雨后春笋,其中包括“新构造网络词语”以及“将已有词语赋予新的含义”;另一方面,我们整理的情感词典中,也不可能完全包含已有的情感词语。因此,自动扩充情感词典是保证情感分类模型时效性的必要条件。
目前,通过网络爬虫等手段,我们可以从微博、社区中收集到大量的评论数据,为了从这大批量的数据中找到新的具有情感倾向的词语,可以用无监督学习式的词频统计。
我们的目标是“自动扩充”,因此我们要达到的目的是基于现有的初步模型来进行无监督学习,完成词典扩充,从而增强模型自身的性能,然后再以同样的方式进行迭代,这是一个正反馈的调节过程。虽然我们可以从网络中大量抓取评论数据,但是这些数据是无标注的,我们要通过已有的模型对评论数据进行情感分类,然后在同一类情感(积极或消极)的评论集合中统计各个词语的出现频率,最后将积极、消极评论集的各个词语的词频进行对比。某个词语在积极评论集中的词频相当低,在消极评论集中的词频相当高,那么我们就有把握将该词语添加到消极情感词典中,或者说,赋予该词语负的权值。
举例来说,假设我们的消极情感词典中并没有“黑心”这个词语,但是“可恶”、“讨厌”、“反感”、“喜欢”等基本的情感词语在情感词典中已经存在,那么我们就会能够将下述句子正确地进行情感分类:
| 句子 | 权值 |
|---|---|
| 这个黑心老板太可恶了 | -2 |
| 我很反感这黑心企业的做法 | -2 |
| 很讨厌这家黑心店铺 | -2 |
| 这家店铺真黑心! | 0 |
其中,由于消极情感词典中没有“黑心”这个词语,所以“这家店铺真黑心!”就只会被判断为中性(即权值为0)。分类完成后,对所有词频为正和为负的分别统计各个词频,我们发现,新词语“黑心”在负面评论中出现很多次,但是在正面评论中几乎没有出现,那么我们就将黑心这个词语添加到我们的消极情感词典中,然后更新我们的分类结果:
| 句子 | 权值 |
|---|---|
| 这个黑心老板太可恶了 | -3 |
| 我很反感这黑心企业的做法 | -3 |
| 很讨厌这家黑心店铺 | -3 |
| 这家店铺真黑心! | -2 |
于是我们就通过无监督式的学习扩充了词典,同时提高了准确率,增强了模型的性能。这是一个反复迭代的过程,前一步的结果可以帮助后一步的进行。
5. 总结
基于情感词典的文本情感分类是容易实现的,其核心之处在于对情感词典的积累。
最后,把完整的代码和测试放在这里,方便大家使用。
import jiebadef loadDict(fileName, score): wordDict = { } with open(fileName) as fin: for line in fin: word = line.strip() wordDict[word] = score return wordDictdef appendDict(wordDict, fileName, score): with open(fileName) as fin: for line in fin: word = line.strip() wordDict[word] = scoredef loadExtentDict(fileName, level): extentDict = { } for i in range(level): with open(fileName + str(i + 1) + ".txt") as fin: for line in fin: word = line.strip() extentDict[word] = i + 1 return extentDictdef getScore(content): postDict = loadDict(u"sentimentDict/积极情感词语.txt", 1) # 积极情感词典 negDict = loadDict(u"sentimentDict/消极情感词语.txt", -1) # 消极情感词典 inverseDict = loadDict(u"sentimentDict/否定词语.txt", -1) # 否定词词典 extentDict = loadExtentDict(u"sentimentDict/程度级别词语", 6) punc = loadDict(u"sentimentDict/标点符号.txt", 1) exclamation = { "!": 2, "!": 2} words = jieba.cut(content) wordList = list(words) print(wordList) totalScore = 0 # 记录最终情感得分 lastWordPos = 0 # 记录情感词的位置 lastPuncPos = 0 # 记录标点符号的位置 i = 0 # 记录扫描到的词的位置 for word in wordList: if word in punc: lastPuncPos = i if word in postDict: if lastWordPos > lastPuncPos: start = lastWordPos else: start = lastPuncPos score = 1 for word_before in wordList[start:i]: if word_before in extentDict: score = score * extentDict[word_before] if word_before in inverseDict: score = score * -1 for word_after in wordList[i + 1:]: if word_after in punc: if word_after in exclamation: score = score + 2 else: break lastWordPos = i totalScore += score elif word in negDict: if lastWordPos > lastPuncPos: start = lastWordPos else: start = lastPuncPos score = -1 for word_before in wordList[start:i]: if word_before in extentDict: score = score * extentDict[word_before] if word_before in inverseDict: score = score * -1 for word_after in wordList[i + 1:]: if word_after in punc: if word_after in exclamation: score = score - 2 else: break lastWordPos = i totalScore += score i = i + 1 return totalScore 测试情感分类的代码如下:
content = u"你真的是一个非常好的人!"print(getScore(content)) # 11content = u"这种行为非常的丑陋,无耻!"print(getScore(content)) # -6
参考文献:
- https://kexue.fm/archives/3360
- https://blog.csdn.net/maxMikexu/article/details/106050067
转载地址:https://lsgogroup.blog.csdn.net/article/details/116949249 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
