【postgresql】数据聚合之PERCENTILE_CONT
发布日期:2021-06-30 21:35:38
浏览次数:2
分类:技术文章
本文共 1204 字,大约阅读时间需要 4 分钟。
在实现性能测试报告聚合的时候,一开始使用的方案是通过数据库查询load出所有数据,然后不同维度数据不同消费者消费聚合对应的数据,这样实现当数据量超过1000w+时下载速度无法解决
因为使用的数据库是TimescaleDB,可以使用数据库直接聚合数据的方式
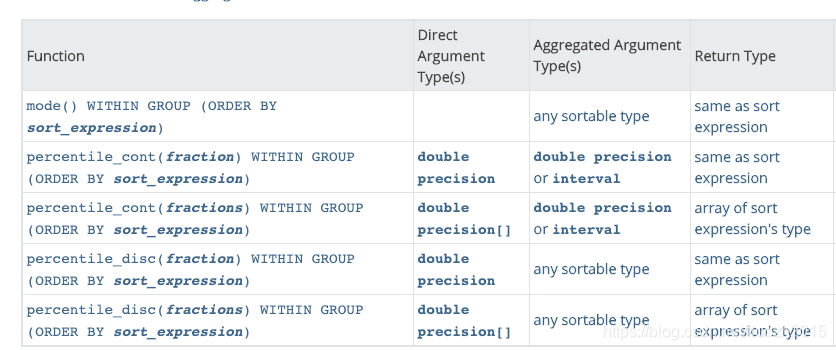
Aggregate Functions
PostgreSQL提供了一系列的
其中我们可以找到有序集合聚合函数 PERCENTILE_CONT
ERCENTILE_CONT 在对值进行排序后计算值之间的线性内插
PERCENTILE_CONT
是一种假定连续分布模型的逆分布函数。该函数具有一个百分比值和一个排序规范,并返回一个在有关排序规范的给定百分比值范围内的内插值
语法
PERCENTILE_CONT ( percentile )WITHIN GROUP (ORDER BY expr)OVER ( [ PARTITION BY expr_list ] )
实际栗子
表名:report_sample
描述:获取执行性能报告数据 主要字段:task_id, seconds, elapsed 字段情况:该表10个字段 数据量:1000w+ 聚合数据量:30w+使用聚合的方式
SELECT labels as transaction, min(elapsed) as elapsed_min, avg(elapsed) as elapsed_avg, percentile_cont(0.5) WITHIN GROUP (ORDER BY elapsed) as elapsed_50pc, percentile_cont(0.9) WITHIN GROUP (ORDER BY elapsed) as elapsed_90pc, percentile_cont(0.95) WITHIN GROUP (ORDER BY elapsed) as elapsed_95pc, percentile_cont(0.99) WITHIN GROUP (ORDER BY elapsed) as elapsed_99pc,FROM report_sampleWHERE task_id = '45eff63a74944f6eb9bef93d8cf04f13'group by labels;
执行3次分别所需时间 495ms、408ms、406ms
直接拉取该30w数据
select * from report_sample where task_id = '45eff63a74944f6eb9bef93d8cf04f13';
执行3次分别所需时间 18140ms、17657ms、17876ms
很明显,直接使用数据库聚合的效率和性能远高于从数据库拉取后消费数据
转载地址:https://lluozh.blog.csdn.net/article/details/107077373 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
逛到本站,mark一下
[***.202.152.39]2024年04月09日 16时26分18秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
查询亿级数据毫秒级返回!Elasticsearch 是如何做到的?
2019-05-01
FastAPI 构建 API 服务,究竟有多快?
2019-05-01
为什么Quora选择用Python语言?
2019-05-01
一劳永逸学编程的方法
2019-05-01
代码整洁之道-编写 Pythonic 代码
2019-05-01
100行python代码,轻松完成贪吃蛇小游戏
2019-05-01
破解百度网盘的Pandownload开发者被捕,让人唏嘘
2019-05-01
如何科学的刷 Leetcode
2019-05-01
树莓派程序开机自启动
2019-05-01
WiFi强力信号连接方案
2019-05-01
连锁门店无线通信方案
2019-05-01
ATM终端无线方案
2019-05-01
工业路由器智能井盖监控方案
2019-05-01
工业路由器农网改造方案
2019-05-01
工业路由器远程空压机系统
2019-05-01
Sco Unixware 7.1.3企业版服务器安装视频教程
2019-05-01
基于Linux平台的Openvas配置使用视频教学
2019-05-01
从程序详解拒绝服务攻击
2019-05-01
轻松八步搞定Cacti配置安装(原创视频)
2019-05-01
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311234805 位访客
访问时间: 2024-05-06 00:35:54
访问IP: 3.14.253.152
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版