《利用Python 进行数据分析》 - 笔记(4)





发布日期:2021-06-30 19:50:05
浏览次数:2
分类:技术文章
本文共 10298 字,大约阅读时间需要 34 分钟。
问题导读:
1.读写文本格式的数据
2.二进制数据格式
3.使用HTML和Web API
解决方案:
读写文本格式的数据:
- pandas 提供了一些用于将表格型数据读取为DataFrame对象的函数
- pandas 中的解析函数
- 函数的选项可以划分为以下几个大类
- 索引:将一个或多个列当做返回的DataFrame处理,以及是否从文件、用户获取列名
- 类型推断和数据转换:包括用户定义值的转换、缺失值标记列表等。
- 日期解析:包括组合功能,比如 将分散在多个列的日期信息组合成结果中的单个列
- 迭代:支持对大文件进行逐块迭代
- 不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西
- 类型推断:
- 你不需要指定列的类型到底是数值、整数、布尔值、还是字符串。
- 日期和其他自定义类型的处理需要花点功夫才行。
- 分别用read_csv() 和 read_table() 读取文件
In [17]: !cat ex1.csva,b,c,d,message1,2,3,4,hello5,6,7,8,world9,10,11,12,fooIn [18]: import pandas as pdIn [19]: df = pd.read_csv('ex1.csv')In [20]: dfOut[20]: a b c d message0 1 2 3 4 hello1 5 6 7 8 world2 9 10 11 12 fooIn [21]: pd.read_table('ex1.csv', sep=',')Out[21]: a b c d message0 1 2 3 4 hello1 5 6 7 8 world2 9 10 11 12 foo - 对于没有标题行的文件
In [25]: !cat ex2.csv 1,2,3,4,hello5,6,7,8,world9,10,11,12,fooIn [26]: pd.read_csv('ex2.csv', header = None)Out[26]: 0 1 2 3 40 1 2 3 4 hello1 5 6 7 8 world2 9 10 11 12 fooIn [27]: pd.read_csv('ex2.csv', names = ['a','b','c','d','message'])Out[27]: a b c d message0 1 2 3 4 hello1 5 6 7 8 world2 9 10 11 12 foo - 如果希望将message 列做成DataFrame 的索引
- 明确表示要将该列放到索引4的位置上
- 通过index_col 参数指定
In [28]: names = ['a','b','c','d','message']In [29]: pd.read_csv('ex2.csv', names = names, index_col='message')Out[29]: a b c dmessage hello 1 2 3 4world 5 6 7 8foo 9 10 11 12 - 如果你希望做成层次化索引,只需要传入由列编号或列名组成的列表即可
In [31]: parsed = pd.read_csv('csv_mindex.csv', index_col = ['key1','key2'])In [32]: parsedOut[32]: value1 value2key1 key2 one a 1 2 b 3 4 c 5 6 d 7 8two a 9 10 b 11 12 c 13 14 d 15 16 - 有些表格可能不是用固定的分隔符去分隔字段,对于这种情况我们要用正则表达来作为read_table 的分隔符
In [8]: !cat ex3.txt A B Caaa -0.264438 -1.026059 -0.619500bbb 0.927272 0.302904 -0.032399ccc -0.264273 -0.386314 -0.217601ddd -0.871858 -0.348382 1.100491In [10]: result = pd.read_table('ex3.txt', sep='\s+')In [11]: resultOut[11]: A B Caaa -0.264438 -1.026059 -0.619500bbb 0.927272 0.302904 -0.032399ccc -0.264273 -0.386314 -0.217601ddd -0.871858 -0.348382 1.100491 - 缺失值处理是文件解析任务中的一个重要的组成部分
- 缺失数据是一个空串(什么都没有)
- 用一个标记值来标记(NA,-1.#IND,NULL)
- na_values 参数规定什么样的值是NA 值
In [22]: result = pd.read_csv('ex5.csv')In [23]: resultOut[23]: something a b c d message0 one 1 2 3 4 NaN1 two 5 6 NaN 8 world2 three 9 10 11 12 fooIn [24]: result = pd.read_csv('ex5.csv', na_values=['10','11','12'])In [25]: resultOut[25]: something a b c d message0 one 1 2 3 4 NaN1 two 5 6 NaN 8 world2 three 9 NaN NaN NaN foo - read_csv/read_table 函数的参数
1.逐块读取文本文件
- read_csv 所返回的是个TextParser(文本解析器对象)使你可以根据chunksize 对文件进行逐块迭代
In [27]: chunker = pd.read_csv('ex6.csv', chunksize=1000)In [28]: chunkerOut[28]: - 我们可以迭代处理这个ex6.csv 将值计数聚合到”key“列中
- ex6.py
#!/usr/bin/env python# coding=utf-8import pandas as pdchunker = pd.read_csv('ex6.csv', chunksize=1000)result = pd.Series([])for piece in chunker: result = result.add(piece['key'].value_counts(),fill_value=0)result = result.order(ascending = False) In [37]: pd.read_csv('ex6.csv',nrows=5)Out[37]: one two three four key0 0.467976 -0.038649 -0.295344 -1.824726 L1 -0.358893 1.404453 0.704965 -0.200638 B2 -0.501840 0.659254 -0.421691 -0.057688 G3 0.204886 1.074134 1.388361 -0.982404 R4 0.354628 -0.133116 0.283763 -0.837063 QIn [38]: run ex6.pyIn [39]: result[:10]Out[39]: E 368X 364L 346O 343Q 340M 338J 337F 335K 334H 330dtype: float64 2.将数据写出到文本格式
- DataFrame 的 to_csv方法
- 可以将数据写到文件中(.txt/.csv/...)
- 默认分隔符为‘,’
- 我们可以使用sep 参数控制分隔符
- na_rep 参数处理缺失值
In [20]: data = pd.read_csv('ex5.csv')In [21]: dataOut[21]: something a b c d message0 one 1 2 3 4 NaN1 two 5 6 NaN 8 world2 three 9 10 11 12 fooIn [22]: data.to_csv('out.csv')In [23]: !cat out.csv,something,a,b,c,d,message0,one,1,2,3.0,4,1,two,5,6,,8,world2,three,9,10,11.0,12,fooIn [24]: data.to_csv('out.csv',sep='|')In [25]: !cat out.csv|something|a|b|c|d|message0|one|1|2|3.0|4|1|two|5|6||8|world2|three|9|10|11.0|12|fooIn [27]: data.to_csv('out.csv',sep='|',na_rep='null')In [28]: !cat out.csv|something|a|b|c|d|message0|one|1|2|3.0|4|null1|two|5|6|null|8|world2|three|9|10|11.0|12|foo - 如果没有其他选项,则会写出行和列的标签
- 我们也可以只写出一部分的列,并以我们指定的顺序排列
In [38]: data.to_csv('out.csv',index = False, cols = ['a','b','c'],na_rep = 'null')In [39]: !cat out.csva,b,c1,2,3.05,6,null9,10,11.0 - Series 的 to_csv 方法
In [44]: dates = pd.date_range('1/1/2000',periods=10)In [45]: datesOut[45]: [2000-01-01, ..., 2000-01-10]Length: 10, Freq: D, Timezone: NoneIn [47]: ts = pd.Series(np.arange(10),index=dates)In [48]: ts.to_csv('tseries.csv')In [49]: !cat tseries.csv2000-01-01,02000-01-02,12000-01-03,22000-01-04,32000-01-05,42000-01-06,52000-01-07,62000-01-08,72000-01-09,82000-01-10,9 - Series 的 from_csv 方法
In [50]: data = pd.read_csv('tseries.csv')In [51]: dataOut[51]: 2000-01-01 00 2000-01-02 11 2000-01-03 22 2000-01-04 33 2000-01-05 44 2000-01-06 55 2000-01-07 66 2000-01-08 77 2000-01-09 88 2000-01-10 9In [52]: data = pd.Series.from_csv('tseries.csv')In [53]: dataOut[53]: 2000-01-01 02000-01-02 12000-01-03 22000-01-04 32000-01-05 42000-01-06 52000-01-07 62000-01-08 72000-01-09 82000-01-10 9dtype: int64 3.JSON数据
- pandas 团队正在致力于添加原生的高效的json导出(to_json) 和解码(from_json)功能
- 我们可以通过json.loads 将json 字符串转换成python形式
- 相反,json.dumps则将python对象转换成json格式
- 也可以向DataFrame 构造器传入一组Json 对象,并选取数据字段的子集
In [54]: obj = """ ....: { "programmers": [ ....: ....: { "firstName": "Brett", "lastName":"McLaughlin", "email": "aaaa" }, ....: ....: { "firstName": "Jason", "lastName":"Hunter", "email": "bbbb" }, ....: ....: { "firstName": "Elliotte", "lastName":"Harold", "email": "cccc" } ....: ....: ], ....: ....: "authors": [ ....: ....: { "firstName": "Isaac", "lastName": "Asimov", "genre": "science fiction" }, ....: ....: { "firstName": "Tad", "lastName": "Williams", "genre": "fantasy" }, ....: ....: { "firstName": "Frank", "lastName": "Peretti", "genre": "christian fiction" } ....: ....: ], ....: ....: "musicians": [ ....: ....: { "firstName": "Eric", "lastName": "Clapton", "instrument": "guitar" }, ....: ....: { "firstName": "Sergei", "lastName": "Rachmaninoff", "instrument": "piano" } ....: ....: ] } ....: """In [55]: import jsonIn [56]: result = json.loads(obj)In [57]: resultOut[57]: {u'authors': [{u'firstName': u'Isaac', u'genre': u'science fiction', u'lastName': u'Asimov'}, {u'firstName': u'Tad', u'genre': u'fantasy', u'lastName': u'Williams'}, {u'firstName': u'Frank', u'genre': u'christian fiction', u'lastName': u'Peretti'}], u'musicians': [{u'firstName': u'Eric', u'instrument': u'guitar', u'lastName': u'Clapton'}, {u'firstName': u'Sergei', u'instrument': u'piano', u'lastName': u'Rachmaninoff'}], u'programmers': [{u'email': u'aaaa', u'firstName': u'Brett', u'lastName': u'McLaughlin'}, {u'email': u'bbbb', u'firstName': u'Jason', u'lastName': u'Hunter'}, {u'email': u'cccc', u'firstName': u'Elliotte', u'lastName': u'Harold'}]}In [58]: asjson = json.dumps(result)In [59]: musicians = pd.DataFrame(result['musicians'],columns=['firstName','lastName'])In [60]: musiciansOut[60]: firstName lastName0 Eric Clapton1 Sergei Rachmaninoff 4.xml和html:web信息收集
- 从html中提取 超链接
In [62]: from lxml.html import parseIn [63]: from urllib2 import urlopenIn [64]: parsed = parse(urlopen('http://finance.yahoo.com/q/op?s=AAPL+Options')) In [65]: doc = parsed.getroot()In [66]: links = doc.findall('.//a')In [67]: links[10:20]Out[67]: [ , , , , , , , , , ]In [68]: lnk = links[28]In [69]: lnkOut[69]: In [70]: lnk.get('href')Out[70]: 'https://help.yahoo.com/l/us/yahoo/finance/'In [71]: lnk.text_content()Out[71]: 'Help'In [72]: urls = [lnk.get('href') for lnk in doc.findall('.//a')]In [73]: urls[-10:]Out[73]: ['/q/cf?s=AAPL+Cash+Flow', 'https://mobile.yahoo.com/finance/?src=gta', '/q/op?s=AAPL&date=1463529600', '/q/op?s=AAPL&straddle=true&date=1463529600', None, None, None, None, '/q/op?s=AAPL&strike=20.00', '/q?s=BVZ160518P00020000'] 二进制数据格式:
- HDF5
PyTables和h5py这两个Python项目可以将NumPy的数组数据存储为高效且可压缩的HDF5格式(层次化数据格式)。你可以安全地将好几百GB甚至TB的数据存储为HDF5格式。
PyTables提供了一些用于结构化数组的高级查询功能,而且还能添加列索引以提升查询速度,这跟关系型数据库所提供的表索引功能非常类似。
- 读取 Microsoft Excel 文件
- 创建一个ExcelFile 文件的实例:pd.ExcelFile('filepath')
- 通过parse 传入到DataFrame中:xls_file.parse('Sheet1')
使用HTML和web API:
- 安装requests 包
peerslee@peerslee-ubuntu:~$ sudo apt-get install python-requests[sudo] peerslee 的密码: 正在读取软件包列表... 完成正在分析软件包的依赖关系树 正在读取状态信息... 完成 将会安装下列额外的软件包: python-ndg-httpsclient python-urllib3建议安装的软件包: python-ntlm下列【新】软件包将被安装: python-ndg-httpsclient python-requests python-urllib3升级了 0 个软件包,新安装了 3 个软件包,要卸载 0 个软件包,有 4 个软件包未被升级。需要下载 135 kB 的软件包。解压缩后会消耗掉 648 kB 的额外空间。您希望继续执行吗? [Y/n] Y获取:1 http://mirrors.hust.edu.cn/ubuntu/ wily/main python-ndg-httpsclient all 0.4.0-1 [24.9 kB]获取:2 http://mirrors.hust.edu.cn/ubuntu/ wily/main python-urllib3 all 1.11-1 [56.2 kB]获取:3 http://mirrors.hust.edu.cn/ubuntu/ wily/main python-requests all 2.7.0-3 [53.8 kB]下载 135 kB,耗时 2秒 (46.3 kB/s) 正在选中未选择的软件包 python-ndg-httpsclient。(正在读取数据库 ... 系统当前共安装有 223563 个文件和目录。)正准备解包 .../python-ndg-httpsclient_0.4.0-1_all.deb ...正在解包 python-ndg-httpsclient (0.4.0-1) ...正在选中未选择的软件包 python-urllib3。正准备解包 .../python-urllib3_1.11-1_all.deb ...正在解包 python-urllib3 (1.11-1) ...正在选中未选择的软件包 python-requests。正准备解包 .../python-requests_2.7.0-3_all.deb ...正在解包 python-requests (2.7.0-3) ...正在处理用于 man-db (2.7.4-1) 的触发器 ...正在设置 python-ndg-httpsclient (0.4.0-1) ...正在设置 python-urllib3 (1.11-1) ...正在设置 python-requests (2.7.0-3) ...
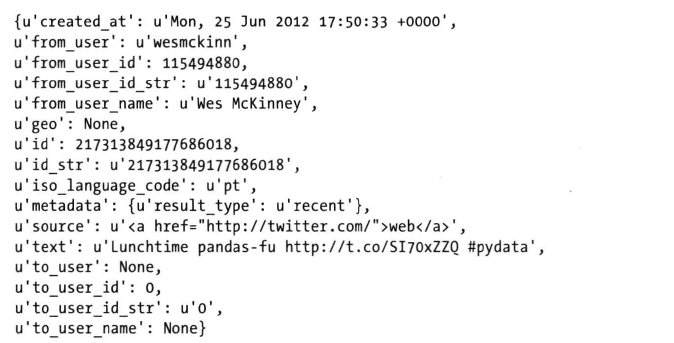
- 发送一个http get请求
- 将GET请求返回的内容加载到一个python 对象中
- 响应的结果中有一组python字典
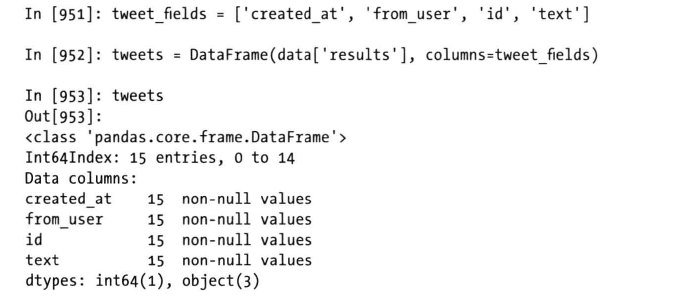
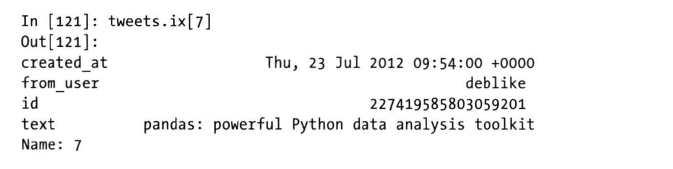
- 截取字段,然后创建DataFrame
- 该DataFrame 中每一行字都是一条来自tweet的数据
- 如果想能够直接得到便于分析的DataFrame对象,只需再多费些精力创建出对常见web API的更高级接口即可
转载地址:https://lipenglin.blog.csdn.net/article/details/51433251 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年05月01日 14时45分40秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Python 之 histogram直方图
2019-04-30
Python 之 Scatter散点图
2019-04-30
Python实现决策树 Desision Tree & 可视化
2019-04-30
决策树 Decision tree
2019-04-30
nominal和ordinal & 数据处理中四种基本数据类型
2019-04-30
Python 实现 Cross-validation
2019-04-30
Grid SearchCV(网格搜索)& Python实现
2019-04-30
ROS相关知识
2019-04-30
单目深度估计 monodepth2模型 代码
2019-04-30
位图索引Bitmap indexes
2019-04-30
YOLO算法(二)—— Yolov2 & yolo9000
2019-04-30
YOLO算法(三)—— Yolov3 & Yolo系列网络优缺点
2019-04-30
Python的__future__模块
2019-04-30
计算机视觉中的cost-volume的概念具体指什么(代价体积)
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310974807 位访客
访问时间: 2024-05-05 04:26:28
访问IP: 3.17.6.75
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版