本文共 4759 字,大约阅读时间需要 15 分钟。
问题描述
DOM4J对XML文档进行增删改查后,将内存中的Document对象保存到持久化设备生成XML文件后,XML文件无法正常打开,出现乱码。也有可能会报异常:
Xml:org.dom4j.DocumentException: 2字节的UTF-8序列的2无效
产生乱码原因
- 表面原因:因为XML文件的真正格式(即XML文件保存在持久化设备上的编码格式)和XML文档声明的encoding属性值不一致;
- 深层原因:一个没有问题的XML文件(XML文件的真正的编码格式和encoding属性值一致),DOM4J API都可以把这个XML文件正常解析成一个Document对象。不管这个XML文件在读入内存之前是什么编码格式,在内存中形成的Document对象都是UTF-8格式,并且encoding属性值也相应的变成UTF-8。造成XML文件的真正格式和encoding属性值不一致的情况发生在把Document对象写入持久化设备时字符到字节的转换过程或字符流直接存储过程。
乱码原因分析
我试着举例去分析乱码的原因,假设XML文档的编码模式是UTF-8(即encoding=“UTF-8”),比如有这样一个book.xml文件:
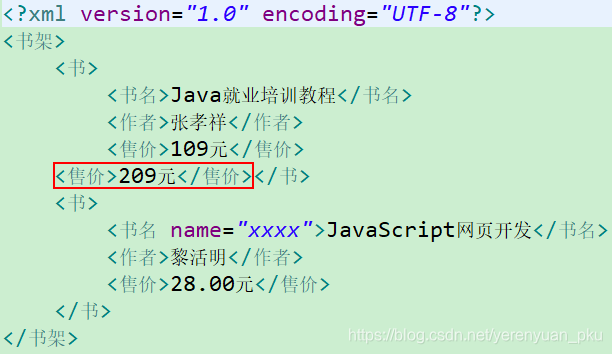
<书架> <书> <书名> Java就业培训教程 <作者> 张孝祥 <售价> 109元 <书> <书名 name="xxxx"> JavaScript网页开发 <作者> 黎活明 <售价> 28.00元
当我们在第一本书中添加一个新的售价,比如<售价>209元</售价>。使用DOM4J API将内存中的Document对象写入到XML文件中,代码如下:
package cn.liayun.dom4j;import java.io.File;import java.io.FileWriter;import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;import org.dom4j.io.XMLWriter;import org.junit.Test;public class Demo { //在第一本书上添加一个新的售价: <售价> 209元 @Test public void add() throws Exception { SAXReader reader = new SAXReader(); //不管你这个XML文档是什么编码,它一读到内存里面去,Document就产生了UTF-8码表 Document document = reader.read(new File("src/book.xml")); Element book = document.getRootElement().element("书"); book.addElement("售价").setText("209元"); //把更新后的Document写回到xml文档里面去 XMLWriter writer = new XMLWriter(new FileWriter("src/book.xml")); writer.write(document); writer.close(); }} 在上面的代码中输出使用的是FileWriter对象进行文件的输出,网上好多的博客都说XML文件无法正常打开,会出现乱码。本着实践是检验真理的唯一标准的思想,我尝试着运行以上测试方法,发现book.xml文档仍然可以正常打开,并没有出现乱码,如下图所示。
 即使是按照网上好多的博客说的,将Document对象写入到XML文件中使用的FileWriter改为转换流写入。
即使是按照网上好多的博客说的,将Document对象写入到XML文件中使用的FileWriter改为转换流写入。 package cn.liayun.dom4j;import java.io.File;import java.io.FileOutputStream;import java.io.OutputStreamWriter;import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;import org.dom4j.io.XMLWriter;import org.junit.Test;public class Demo { //在第一本书上添加一个新的售价: <售价> 209元 @Test public void add() throws Exception { SAXReader reader = new SAXReader(); //不管你这个XML文档是什么编码,它一读到内存里面去,Document就产生了UTF-8码表 Document document = reader.read(new File("src/book.xml")); Element book = document.getRootElement().element("书"); book.addElement("售价").setText("209元"); //把更新后的Document写回到xml文档里面去 XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream("src/book.xml"), "UTF-8")); writer.write(document); writer.close(); }} 也仍然是可以正常打开book.xml文档的,并没有出现乱码的现象。当然了,也有他们所说的原因:
转换流指定了编码格式把内存中的Document对象(UTF-8编码,encoding=“UTF-8”)转换成字节流,如果指定的编码格式是GBK,则此时文件的真正格式为GBK,encoding依旧为UTF-8,故出现乱码。如果将指定的编码格式指定为UTF-8格式,不会出现乱码。
搞了半天,发现都没找到XML文档打开时乱码的现象,那到底什么时候会出现乱码的问题呢?当我们将XML文档的编码模式改为GBK(即encoding=“GBK”)时。
文件头编码格式被改变原因
假设此时XML文档的编码模式是GBK,写回文件的编码格式也是GBK。代码如下:
package cn.liayun.dom4j;import java.io.File;import java.io.FileOutputStream;import java.io.OutputStreamWriter;import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;import org.dom4j.io.XMLWriter;import org.junit.Test;public class Demo { //在第一本书上添加一个新的售价: <售价> 209元 @Test public void add() throws Exception { SAXReader reader = new SAXReader(); //不管你这个XML文档是什么编码,它一读到内存里面去,Document就产生了UTF-8码表 Document document = reader.read(new File("src/book.xml")); Element book = document.getRootElement().element("书"); book.addElement("售价").setText("209元"); //把更新后的Document写回到xml文档里面去 XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream("src/book.xml"), "GBK")); writer.write(document); writer.close(); }} 这个时候,XML文档就会出现乱码问题(你可终于出现了),如下图所示。
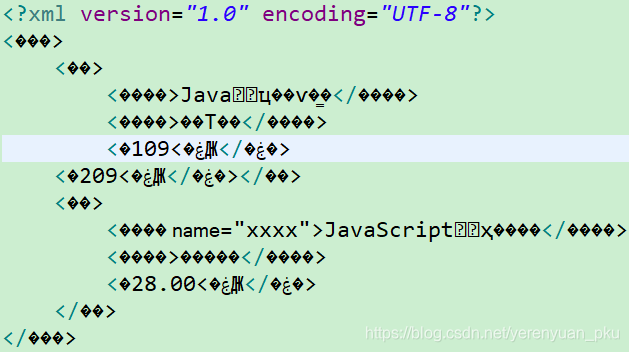 原因:写入数据时使用的是GBK编码表,写入后XML文件头的编码格式被改为了UTF-8。这是因为文档在写回时,文档的头编码格式是根据内存中Document的编码(UTF-8)设定的,则文档解码时使用的是UTF-8来解码,会出现乱码。
原因:写入数据时使用的是GBK编码表,写入后XML文件头的编码格式被改为了UTF-8。这是因为文档在写回时,文档的头编码格式是根据内存中Document的编码(UTF-8)设定的,则文档解码时使用的是UTF-8来解码,会出现乱码。 - 解决方式一:写入数据时使用的是UTF-8编码表即可。

- 解决方式二:也即最佳的解决办法,使用DOM4J提供方的输出格式化类OutputFormat。
 下面我会更详细地介绍这种解决方法。
下面我会更详细地介绍这种解决方法。
最佳解决办法
为了解决保持XML文档编码表不变,DOM4J引入了格式化输出器,通过格式化输出器,能够实现按指定的编码表来编码,也可以把XML文档的码表改为指定的码表。
 生成一个漂亮的格式化输出器(紧凑的格式化输出器也可以)对象format,设置其编码格式为自己想要的任意格式。输出时,format会先把内存中的Document对象的encoding属性值改为设置的编码格式,然后再把Document对象按设置的编码格式格式化字节流。此时XML文件的真正格式和encoding属性值一致,不会出现乱码。不过,有一点特别需要注意,构造XMLWriter对象的输出流对象必须是字节流对象,如果是字符流对象又会导致Document对象多次按不同编码转换,可能又会出现乱码问题。分两种情况讨论。
生成一个漂亮的格式化输出器(紧凑的格式化输出器也可以)对象format,设置其编码格式为自己想要的任意格式。输出时,format会先把内存中的Document对象的encoding属性值改为设置的编码格式,然后再把Document对象按设置的编码格式格式化字节流。此时XML文件的真正格式和encoding属性值一致,不会出现乱码。不过,有一点特别需要注意,构造XMLWriter对象的输出流对象必须是字节流对象,如果是字符流对象又会导致Document对象多次按不同编码转换,可能又会出现乱码问题。分两种情况讨论。 情况一
格式化输出器指定编码与XML文档编码模式相同时(都是GBK的情况下)。
- 使用字符输出流写入
 网上好多人举这个例子,说什么这种写入方式是正确的,XML文件可以正常打开,不会出现乱码。信你这个糟老头子才有鬼呢!乱码的一匹,不信,你看。
网上好多人举这个例子,说什么这种写入方式是正确的,XML文件可以正常打开,不会出现乱码。信你这个糟老头子才有鬼呢!乱码的一匹,不信,你看。  不过,他们倒是有一点说对了,那就是根本不会使用格式化输出器指定的GBK编码表编码,而是查找平台默认的编码表来编码。所以,大家一定要小心啊!
不过,他们倒是有一点说对了,那就是根本不会使用格式化输出器指定的GBK编码表编码,而是查找平台默认的编码表来编码。所以,大家一定要小心啊! - 使用字节输出流写入
 这种,上面就已讲过,这种写入方式是正确的,会按格式化输出器指定的编码表来编码,更新后XML文档的编码表不变。
这种,上面就已讲过,这种写入方式是正确的,会按格式化输出器指定的编码表来编码,更新后XML文档的编码表不变。
情况二
XML文档的编码表(GBK)和格式化输出器指定码表(UTF-8)不相同时。
- 使用字符输出流写入

- 使用字节输出流写入

让人很惊讶!这两种写入方式都正确,并不会出现乱码的现象。但两者都会将原book.xml文档的编码表改为encoding=“UTF-8”。
结论
- 结论一:通过上述分析,可以说明数据写入时使用的码表和解码时使用的码表不同就会造成乱码问题;
- 结论二:通过格式化输出器来指定码表的方式写入数据后,都会将原XML文档的编码表更改为指定的码表。因此只要我们指定的码表与XML文档的码表相同,在写入数据时都不会更改XML文档的默认码表。但是如果使用字符输入流写入数据时,一定要保证平台默认码表与XML文档码表一致,这样写入数据时不会出现乱码。在任何情况下使用字节输入流写入数据都不会出现乱码。
转载地址:https://liayun.blog.csdn.net/article/details/87887910 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
