本文共 14852 字,大约阅读时间需要 49 分钟。
XML解析技术概述
XML解析的两种方式:DOM解析和SAX解析

DOM解析和SAX解析之间的区别
此处,要非常清楚地知道DOM解析和SAX解析之间的区别,因为面试题常考。

DOM解析和SAX解析的原理
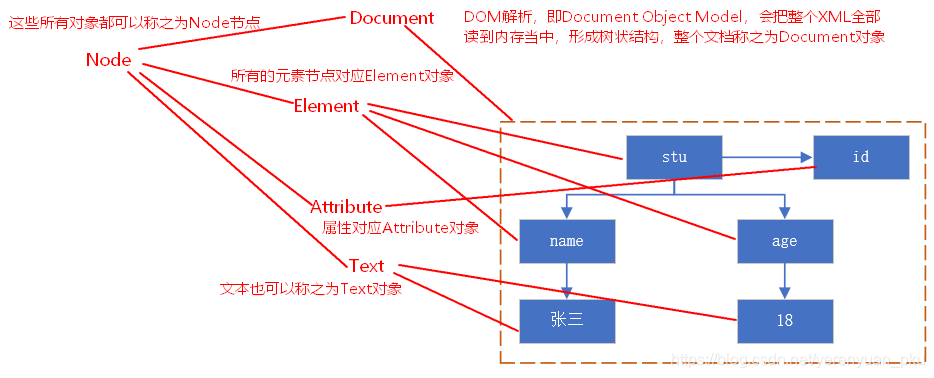
先来看DOM解析的原理。有root.xml文档如下:
张三 18
对其进行DOM解析,如图:
 DOM解析有其优缺点,
DOM解析有其优缺点, - 优点:十分便于进行增删改查的操作,只须解析一次拿到Document对象后,就可以重复使用此对象,减少解析的次数;
- 缺点:解析过程比较慢,需要将整个文档都解析完成后才能进行操作。需要将整个树的内容都加载进内存中来,比较耗费内存,当文档过大时,这种解析方式对内存的损耗非常的严重。
再来看一下SAX解析的原理。还是对以上文档进行SAX解析,如图:
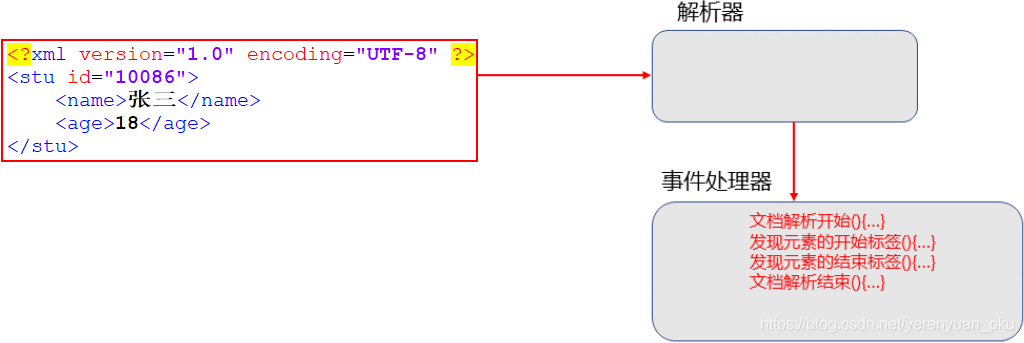 SAX解析也有其优缺点,
SAX解析也有其优缺点, - 优点:不需要等待整个XML加载到内存,当解析到某一部分时,自动触发到对应的方法去做处理,处理的效率比较高;不需要将整个XML文档加载到内存中,对内存的损耗比较少,无论多大的XML,理论上都可以解析;
- 缺点:每次解析都只能处理一次,下次再想处理还要重新解析,且只能进行查询不能进行增删改的操作。
XML解析器
XML解析器有如下几类:
- Crimson(SUN,JDK自带);
- Xerces(IBM最好的解析器);
- Aelfred2(DOM4J)
使用哪种解析器对程序员基本上没有什么影响,我们学习的是解析开发包,解析开发包调用什么样的解析器对程序员没有意义。
XML解析开发包
XML解析开发包也有如下几类:
- JAXP(SUN公司的);
- JDOM(不推荐使用);
- DOM4J(比较不错);
- Pull(Android的SDK自带,它使用的是另外的解析方式streaming api for xml,即STAX)
使用JAXP对XML文档进行解析
JAXP概述
JAXP(Java API for xml Processing),是SUN提供的一套XML解析API,JAXP很好地支持了DOM和SAX解析方式。
JAXP开发包是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax包及其子包组成。在javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对XML文档进行解析的DOM或SAX的解析器对象。获得JAXP中的DOM解析器
首先,查阅API可知,javax.xml.parsers包中的DocumentBuilderFactory用于创建DOM模式的解析器对象,DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance方法,这个方法会根据本地平台默认安装的解析器,自动创建一个工厂的对象并返回。如此一来,调用DocumentBuilderFactory.newInstance()方法可得到创建DOM解析器的工厂。
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
然后,调用工厂对象的newDocumentBuilder方法得到DOM解析器对象。
DocumentBuilder builder = factory.newDocumentBuilder();
最后,调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象,进而可以利用DOM特性对整个XML文档进行操作了。
Document document = builder.parse("src/book.xml"); DOM解析
DOM模型(document object model)
DOM解析器在解析XML文档时,会把文档中的所有元素,按照其出现的层次关系,解析成一个个Node对象(节点),在DOM中,节点之间关系如下:
- 位于一个节点之上的节点是该节点的父节点(parent);
- 一个节点之下的节点是该节点的子节点(children);
- 同一层次,具有相同父节点的节点是兄弟节点(sibling);
- 一个节点的下一个层次的节点集合是节点后代(descendant);
- 父、祖父节点及所有位于节点上面的,都是节点的祖先(ancestor)。
节点类型可参考以下列表。
| 类型名 | 说明 |
|---|---|
| Node | 表示所有类型值的统一接口,此接口中提供了很多增删改查节点的方法,所有的文档树中的对象都实现过此接口 |
| Document | 表示文档类型 |
| Element | 表示元素节点类型 |
| Text | 表示文本节点类型 |
| CDATASection | 表示CDATA区域类型 |
| DocumentType | 表示文档声明类型 |
| DocumentFragment | 表示文档片段类型 |
| Attr | 表示属性节点类型 |
Node对象
Node对象提供了一系列常量来代表节点的类型,当开发人员获得某个Node类型后,就可以把Node节点转换成相应的节点对象(Node的子类对象),以便于调用其特有的方法。Node对象还提供了相应的方法去获得它的父节点或子节点。编程人员通过这些方法就可以读取整个XML文档的内容,或添加、修改、删除XML文档的内容了。
注意:DOM解析下,XML文档的每一个组成部分都会用一个对象表示,例如标签用Element,属性用Attr,但不管什么对象,都是Node的子类,所以在开发中可以把获取到的任意节点都当作Node对待。DOM方式解析XML文件
例如,有book.xml文档如下:
<书架> <书> <书名 name="xxxxx"> Java就业培训教程 <作者> 张孝祥 <售价> 39.00元 <书> <书名> JavaScript网页开发 <作者> 张孝祥 <售价> 28.00元
下面我会使用DOM解析方式对以上XML文档进行增删改查(CRUD)的操作。
读取
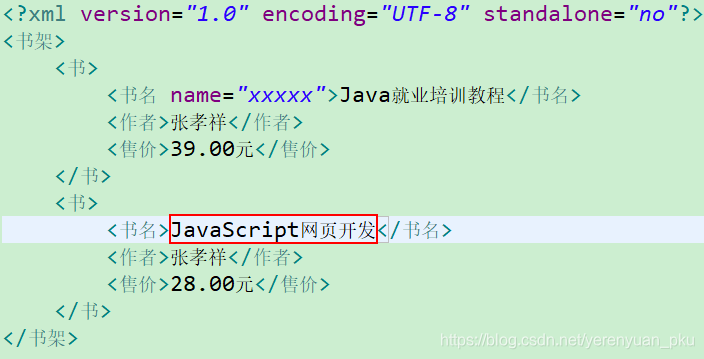
需求:读取book.xml文档中书名元素(标签)<书名>JavaScript网页开发</书名>中封装的内容,如图。
package cn.liayun.xml;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import org.junit.Test;import org.w3c.dom.Document;import org.w3c.dom.Node;import org.w3c.dom.NodeList;public class Demo { //读取xml文档中: <书名> JavaScript网页开发 节点中的值 @Test public void read() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); NodeList list = document.getElementsByTagName("书名"); //获取到书名元素(标签) Node node = list.item(1); String content = node.getTextContent(); //获取到书名元素(标签)中封装的内容 System.out.println(content); //输出:JavaScript网页开发 }} 如果要求我们得到book.xml文档中的所有标签,那么又该怎么实现这个需求呢?这里肯定是要用到递归的编程思想的,除此之外,还应知道如下方法。
| 方法 | 描述 |
|---|---|
| NodeList getChildNodes() | 包含此节点的所有子节点的NodeList。如果不存在子节点,则这是不包含节点的NodeList |
public class Demo { //得到xml文档中的所有标签 @Test public void read1() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); //得到根节点 Node root = document.getElementsByTagName("书架").item(0); list(root); } private void list(Node node) { if (node instanceof Element) { //判断node是否为标签 System.out.println(node.getNodeName()); }// System.out.println(node.getNodeName()); NodeList list = node.getChildNodes(); for (int i = 0; i < list.getLength(); i++) { Node child = list.item(i); list(child); } }} 如果大家不知道递归是怎么遍历的,那么可以断点调试跟踪,理解其原理。千万注意:对于XML标签中出现的所有空格和换行,XML解析程序都会当作标签内容进行处理。
最后一个需求,得到book.xml文档中标签<书名 name="xxxx">Java就业培训教程</书名>中属性的值,如图。 
public class Demo { //得到xml文档中标签属性的值: <书名 name="xxxx"> Java就业培训教程 @Test public void read3() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); Element bookname = (Element) document.getElementsByTagName("书名").item(0); String value = bookname.getAttribute("name"); System.out.println(value); }} 创建
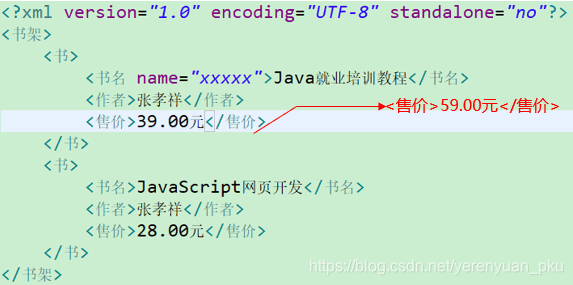
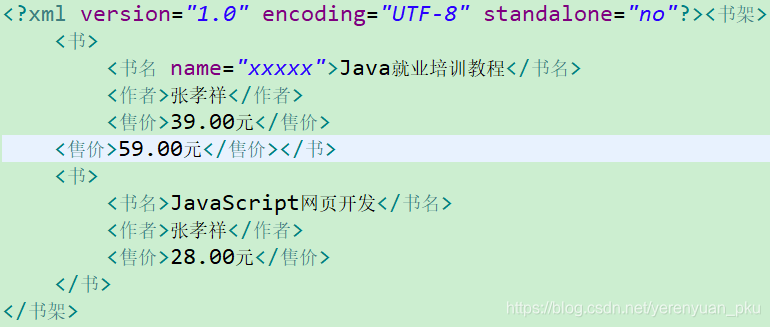
需求:向book.xml文档中添加一个节点——<售价>59.00元</售价>,如下图。
 首先,我们要获得JAXP中的DOM解析器,调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象;然后,创建一个节点;最后,把创建的节点挂到第一本书上。
首先,我们要获得JAXP中的DOM解析器,调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象;然后,创建一个节点;最后,把创建的节点挂到第一本书上。 public class Demo { //向xml文档中添加节点: <售价> 59.00元 @Test public void add() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); //创建节点 Element price = document.createElement("售价");//就是创建一个标签 price.setTextContent("59.00元"); //把创建的节点挂到第一本书上 Element book = (Element) document.getElementsByTagName("书").item(0); book.appendChild(price); }} 运行以上测试方法,发现我们创建的售价节点并没有挂到第一本书上,这是为什么呢?因为还没更新XML文档,即没把更新后的内存树写回到XML文档中。那么如何更新XML文档呢?javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把XML文件应用样式表后转成一个HTML文档。利用这个对象,当然也可以把Document对象又重新写入到一个XML文件中。Transformer对象通过TransformerFactory获得。Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地,我们可以通过:
- javax.xml.transform.dom.DOMSource类来关联要转换的Document对象;
- 用javax.xml.transform.stream.StreamResult对象来表示数据的目的地。

 如果要求我们向book.xml文档中的指定位置上添加节点——
如果要求我们向book.xml文档中的指定位置上添加节点——<售价>59.00元</售价>,那么又该怎么实现这个需求呢?可按以下分析的步骤来编写代码。 我是这样分析的:
- 获得JAXP中的DOM解析器,调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象;
- 创建节点;
- 得到参考节点;
- 得到要挂崽的节点;
- 往要挂崽的节点的指定位置插崽;
- 把更新后的内存树写回到xml文档。
public class Demo { //向xml文档中的指定位置上添加节点: <售价> 59.00元 @Test public void add2() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); //创建节点 Element price = document.createElement("售价");//就是创建一个标签 price.setTextContent("59.00元"); //得到参考节点 Element refNode = (Element) document.getElementsByTagName("售价").item(0); //得到要挂崽的节点 Element book = (Element) document.getElementsByTagName("书").item(0); //往book节点的指定位置插崽 book.insertBefore(price, refNode); //把更新后的内存写回到xml文档 TransformerFactory tfFactory = TransformerFactory.newInstance(); Transformer tf = tfFactory.newTransformer(); tf.transform(new DOMSource(document), new StreamResult(new FileOutputStream("src/book.xml"))); }} 这样,添加后book.xml的内容变为如下。
 再看最后一个需求,向book.xml文档节点上添加属性,如向
再看最后一个需求,向book.xml文档节点上添加属性,如向<书名>Java就业培训教程</书名>上添加name="xxx"属性。为了不要混淆视听,先把原book.xml文档中<书名>Java就业培训教程</书名>元素中的name属性删除掉。 public class Demo { //向xml文档节点上添加属性: <书名> Java就业培训教程 上添加name="xxx"属性 @Test public void addAttr() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); Element bookname = (Element) document.getElementsByTagName("书名").item(0); bookname.setAttribute("name", "xxx"); //把更新后的内存写回到xml文档 TransformerFactory tfFactory = TransformerFactory.newInstance(); Transformer tf = tfFactory.newTransformer(); tf.transform(new DOMSource(document), new StreamResult(new FileOutputStream("src/book.xml"))); }} 添加name="xxx"属性之后的book.xml内容为:
 注意:以上方式添加的元素都没有格式上的缩进。
注意:以上方式添加的元素都没有格式上的缩进。 删除
假设book.xml文档的内容修改为如下:
<书架> <书> <书名 name="xxxxx"> Java就业培训教程 <作者> 张孝祥 <售价> 59.00元 <售价> 39.00元 <书> <书名> JavaScript网页开发 <作者> 张孝祥 <售价> 28.00元
需求:删除以上XML文档中的标签——<售价>59.00元</售价>。删除该售价标签,共有两种方式,第一种方式如下。
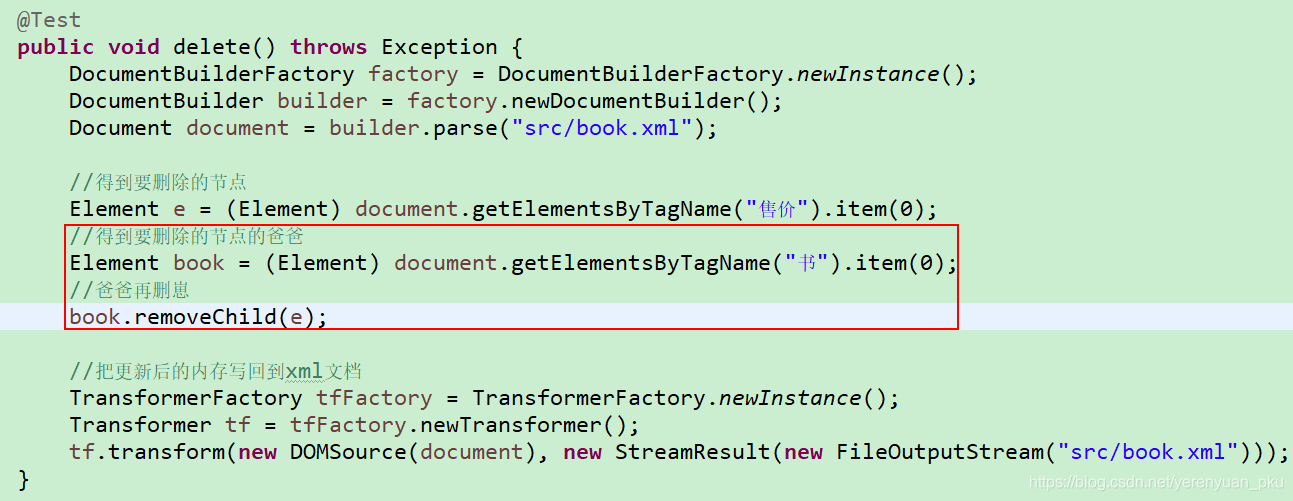 再来看第二种方式。
再来看第二种方式。 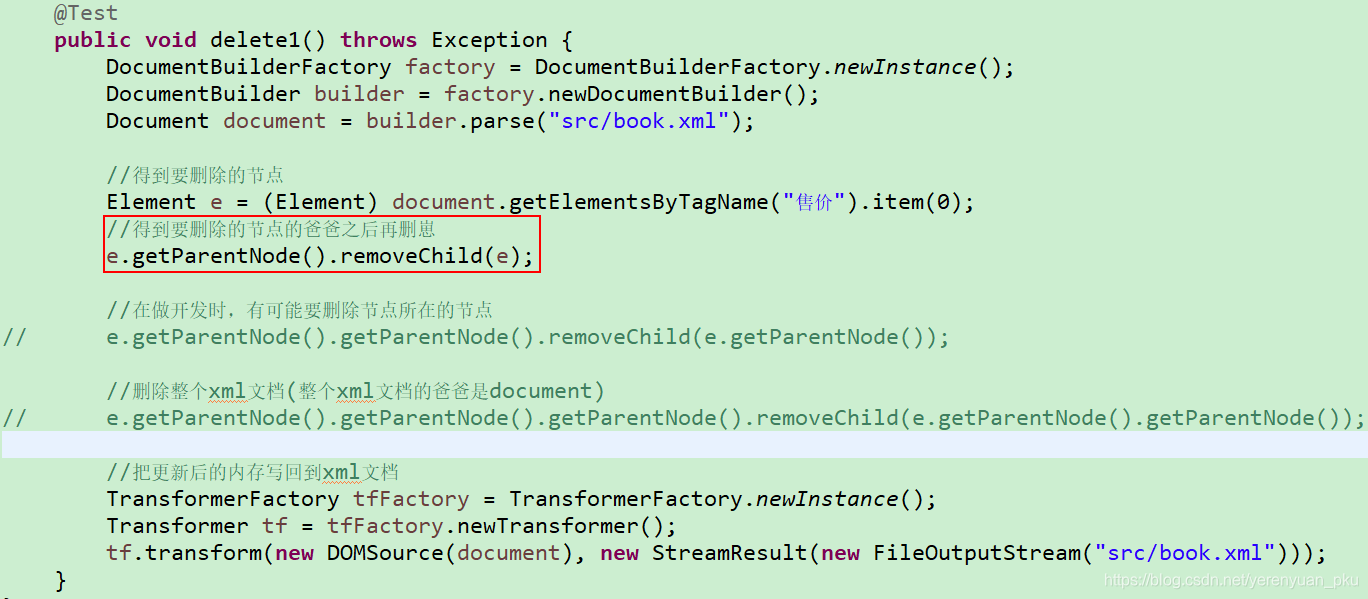 删除该售价标签之后book.xml内容为:
删除该售价标签之后book.xml内容为: 
修改
需求:更新节点<售价>59.00元</售价>中的售价。
public class Demo { //更新价格 @Test public void update() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); //得到要更新的节点 Element e = (Element) document.getElementsByTagName("售价").item(0); e.setTextContent("109元"); //把更新后的内存写回到xml文档 TransformerFactory tfFactory = TransformerFactory.newInstance(); Transformer tf = tfFactory.newTransformer(); tf.transform(new DOMSource(document), new StreamResult(new FileOutputStream("src/book.xml"))); }} 修改售价之后book.xml文档的内容为:

SAX解析
在使用DOM解析XML文档时,需要读取整个XML文档,在内存中构架代表整个DOM树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果XML文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出;而SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会对文档进行操作,这样就能够避免内存溢出的情况了。使用SAX解析这种方式的缺点就是它只能实现对XML文档的读取操作。该解析方式也是DOM4J的解析方式。
SAX方式解析XML文件
SAX采用事件处理的方式解析XML文件,利用SAX解析XML文档,涉及两个部分:解析器和事件处理器。
- SAX解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定它去解析某个XML文档;
- 解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的XML文件内容作为方法的参数传递给事件处理器;
- 事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到SAX解析器解析到的数据,从而可以决定如何对数据进行处理。
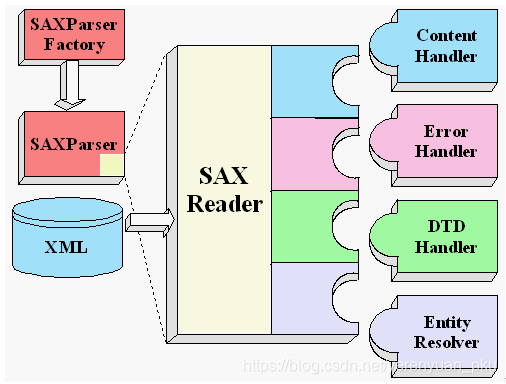
 现在有这样一个book.xml文档,
现在有这样一个book.xml文档, <书架> <书> <书名> Java就业培训教程 <作者> 张孝祥 <售价> 109元 <书> <书名 name="xxxx"> JavaScript网页开发 <作者> 黎明 <售价> 28.00元
给到我们的需求是得到该XML文档的所有内容。解决这个需求之前,还需要对ContentHandler(内容处理器)有一定的认识。它是一个接口,我们可以自己写一个类实现这个接口,其中提供了如下重要的方法:
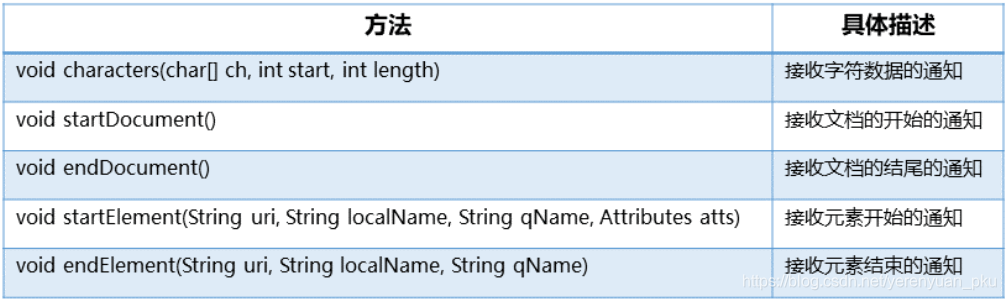 现在来编写一个类ListHandler实现ContentHandler接口,其作用是得到book.xml文档中的所有内容。
现在来编写一个类ListHandler实现ContentHandler接口,其作用是得到book.xml文档中的所有内容。 //得到xml文档的所有内容class ListHandler implements ContentHandler { /* * 解析器只要解析到开始标签,就会调用startElement()方法 * 会通过方法的参数告诉你解析到的当前标签名称是什么 */ @Override public void startElement(String uri, String localName, String qName, Attributes atts) throws SAXException { System.out.println("<" + qName + ">"); //获取标签上的属性 for (int i = 0; atts != null && i < atts.getLength(); i++) { //有可能标签上没有属性,那么atts有可能为null,所以就有可能会抛空指针异常。 String attName = atts.getQName(i);//得到属性名称 String attValue = atts.getValue(i);//得到属性的值 System.out.println(attName + "=" + attValue); } } @Override public void characters(char[] ch, int start, int length) throws SAXException { System.out.println(new String(ch, start, length)); } @Override public void endElement(String uri, String localName, String qName) throws SAXException { System.out.println("<" + qName + ">"); } @Override public void setDocumentLocator(Locator locator) { // TODO Auto-generated method stub } @Override public void startDocument() throws SAXException { // TODO Auto-generated method stub } @Override public void startPrefixMapping(String prefix, String uri) throws SAXException { // TODO Auto-generated method stub } @Override public void endPrefixMapping(String prefix) throws SAXException { // TODO Auto-generated method stub } @Override public void ignorableWhitespace(char[] ch, int start, int length) throws SAXException { // TODO Auto-generated method stub } @Override public void processingInstruction(String target, String data) throws SAXException { // TODO Auto-generated method stub } @Override public void skippedEntity(String name) throws SAXException { // TODO Auto-generated method stub } @Override public void endDocument() throws SAXException { // TODO Auto-generated method stub } } 可发现ContentHandler接口中的方法都要一一实现,未免麻烦。幸好还有一个DefaultHandler类,该类实现了某些处理XML文档必须的ContentHandler接口,但是均没有具体的方法,也就是说是空方法,如果想要解析XML文档,需要覆写该方法。
如果想要获取book.xml文档中指定标签的值,如<作者>张孝祥</作者>,那么就可以编写一个类(例如TagValueHandler)实现DefaultHandler类来解决。 package cn.liayun.sax;import java.io.IOException;import javax.xml.parsers.ParserConfigurationException;import javax.xml.parsers.SAXParser;import javax.xml.parsers.SAXParserFactory;import org.xml.sax.Attributes;import org.xml.sax.SAXException;import org.xml.sax.XMLReader;import org.xml.sax.helpers.DefaultHandler;public class Demo2 { /** * sax解析xml文档 * @param args * @throws SAXException * @throws ParserConfigurationException * @throws IOException */ public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { //1.创建解析器工厂 SAXParserFactory factory = SAXParserFactory.newInstance(); //2.得到解析器 SAXParser sp = factory.newSAXParser(); //3.得到读取器 XMLReader reader = sp.getXMLReader(); //4.设置内容处理器 reader.setContentHandler(new TagValueHandler()); //5.读取xml文档内容 reader.parse("src/book.xml");//读取器会调用内容处理器中的方法 }}//只处理某个标签值的处理器,用来获取指定标签的值class TagValueHandler extends DefaultHandler { private String currentTag; //记住当前解析到的是什么标签 private int needNumber = 2; //记住想要获取第几个作者标签的值 private int currentNumber; //记住当前解析到的是第几个 @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { currentTag = qName; if (currentTag.equals("作者")) { currentNumber++; } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { currentTag = null;//解析到结束标签时,将其置为null } @Override public void characters(char[] ch, int start, int length) throws SAXException { if ("作者".equals(currentTag) && currentNumber == needNumber) { System.out.println(new String(ch, start, length)); } } } 在实际开发中,我们是要把book.xml文档中的每一本书封装到一个Book对象中,并把多个Book对象放在一个List集合中返回。那怎么来实现这一需求呢?先将封装数据的JavaBean,即Book类设计出来:
package cn.liayun.sax;public class Book { private String name; private String author; private String price; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getAuthor() { return author; } public void setAuthor(String author) { this.author = author; } public String getPrice() { return price; } public void setPrice(String price) { this.price = price; }} 再编写一个类(例如BeanListHandler)实现DefaultHandler类,把book.xml文档中的每一本书封装到一个Book对象中,并把多个Book对象放在一个List集合中返回。
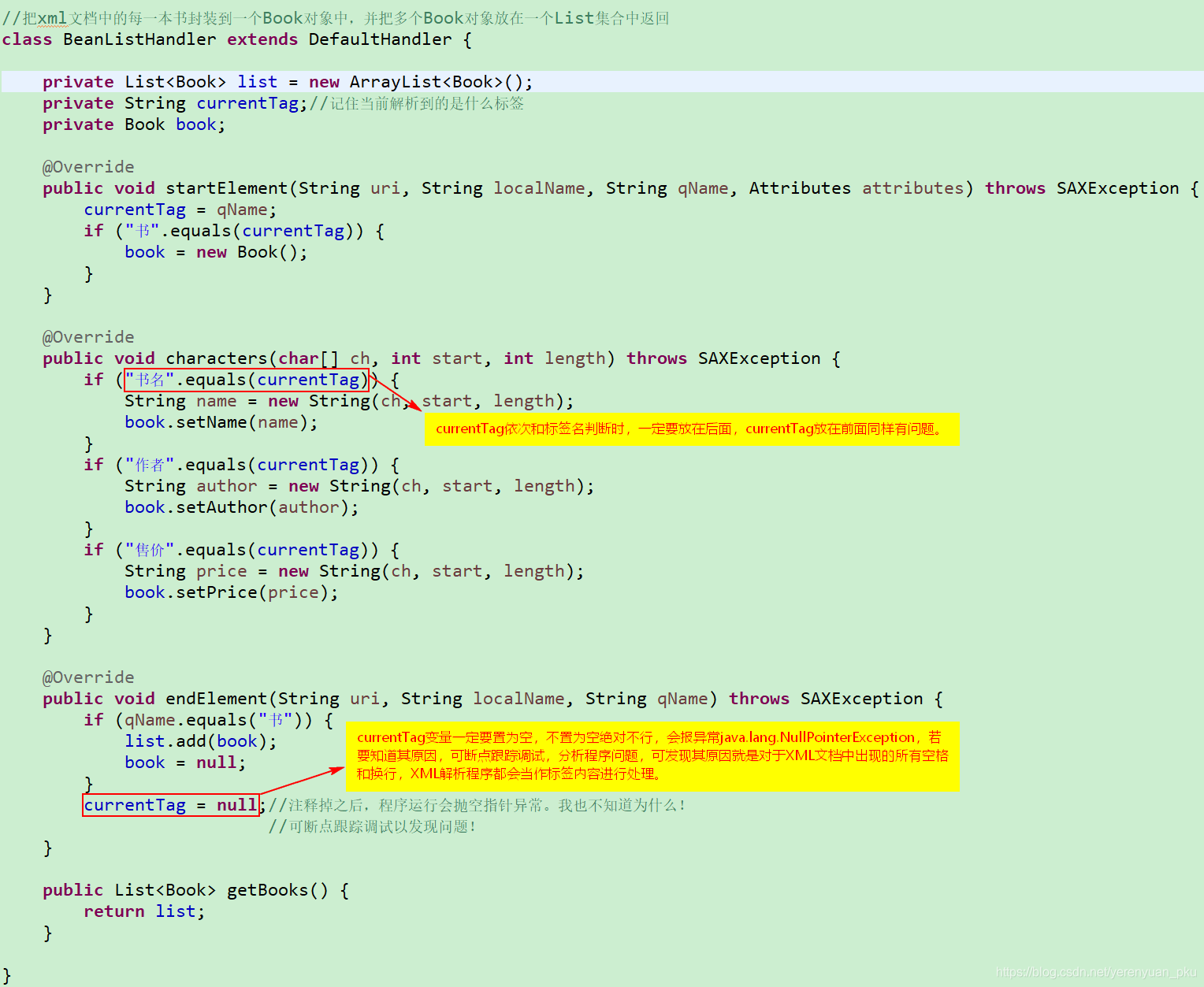 最后,在main方法中测试:
最后,在main方法中测试: public class Demo3 { /** * sax解析xml文档 * @param args * @throws SAXException * @throws ParserConfigurationException * @throws IOException */ public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { //1.创建解析器工厂 SAXParserFactory factory = SAXParserFactory.newInstance(); //2.得到解析器 SAXParser sp = factory.newSAXParser(); //3.得到读取器 XMLReader reader = sp.getXMLReader(); //4.设置内容处理器 BeanListHandler handler = new BeanListHandler(); reader.setContentHandler(handler); //5.读取xml文档内容 reader.parse("src/book.xml");//读取器会调用内容处理器中的方法 List list = handler.getBooks(); System.out.println(list); }} 转载地址:https://liayun.blog.csdn.net/article/details/87572121 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
