[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
发布日期:2021-06-30 16:51:06
浏览次数:2
分类:技术文章
本文共 816 字,大约阅读时间需要 2 分钟。
一、前言
之前使用原生的 Python 库去爬取网页信息,经常要使用正则表达式,笔者记性不是很好,经常经常忘记相关符号及其作用。
Scrapy 框架去爬取信息,感觉太笨重了,特别是一个项目开发到一半,要引入爬虫功能,再使用 Scrapy,就不是那么友好了,其本身就是一个 Web Project。 近来使用一个和之前 Java 爬虫特别简单好使的 Jsoup 框架极其类似的 Beautiful Soup
引入也很简单:
# Python 2+pip install beautifulsoup4# Python 3+pip3 install beautifulsoup4
使用 Python 爬虫体验当然是比 Java 要好,java开发有点 “做作” —— 每一步都极其格式化(面向对象),Python 则运用自如。
二、需求
现在要爬取 的今日推荐的 文章 标题 及其 链接,
2.1.这是网页目标内容
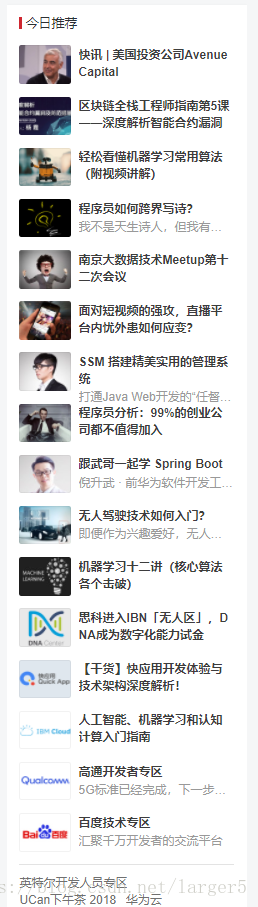
2.2.这是网页目标内容对应的源码

三、实践
你猜需要多少行代码,没错,就这几行,就是这么牛逼。
因力求精简,笔者为此费了几个小时通读官方 API 文档数遍。3.1.代码
from bs4 import BeautifulSoupfrom urllib.request import urlopenhtml = urlopen("https://www.csdn.net/").read().decode('utf-8')soup = BeautifulSoup(html,"html.parser")titles=soup.select("h3[class='company_name'] a") # CSS 选择器for title in titles: print(title.get_text(),title.get('href'))# 标签体、标签属性 3.2.效果

四、小结
参考文献:
转载地址:https://larger5.blog.csdn.net/article/details/81150647 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
逛到本站,mark一下
[***.202.152.39]2024年04月15日 06时29分18秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
基于MATLAB的二进制数字调制与解调信号的仿真——2FSK
2019-04-30
基于MATLAB的二进制数字调制与解调信号的仿真——2PSK
2019-04-30
基于MATLAB的模拟调制信号与解调的仿真——AM
2019-04-30
基于MATLAB的模拟调制信号与解调的仿真——DSB
2019-04-30
基于MATLAB的模拟调制信号与解调的仿真——SSB
2019-04-30
操作系统实验之生产者和消费者程序
2019-04-30
操作系统实验之猴子过桥问题的模拟程序
2019-04-30
POJ - 3067 Japan (树状数组 思维)
2019-04-30
POJ - 2352 Stars (树状数组 入门题)
2019-04-30
HDU - 1166 敌兵布阵 (树状数组模板题/线段树模板题)
2019-04-30
CodeForces - 761C Dasha and Password (思维 暴力)
2019-04-30
POJ - 2481 Cows (树状数组 入门题)
2019-04-30
ACM-ICPC 2018 焦作赛区网络预赛 I. Save the Room
2019-04-30
CodeForces - 987C Three displays (暴力/dp)
2019-04-30
计蒜客 NAIPC 2016 F. Mountain Scenes(dp)
2019-04-30
牛客国庆集训派对Day4——I 连通块计数(思维)
2019-04-30
牛客国庆集训派对Day4——G 区间权值(找规律,双重前缀和)
2019-04-30
牛客国庆集训派对Day5——L 数论之神(找规律/数论)
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310900449 位访客
访问时间: 2024-05-05 00:58:06
访问IP: 3.16.69.143
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版