[Java爬虫] 使用 HtmlUnit + Xpath 模拟点击、动态获取信息
发布日期:2021-06-30 16:50:43
浏览次数:4
分类:技术文章
本文共 1266 字,大约阅读时间需要 4 分钟。
一、前言

此时的爬虫就不再是之前的一个页面的信息了:
二、代码
package com.cun.test;import java.util.List;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.HtmlElement;import com.gargoylesoftware.htmlunit.html.HtmlInput;import com.gargoylesoftware.htmlunit.html.HtmlPage;/** * 模拟点击,动态获取页面信息 * @author linhongcun * */public class JsoupHttpClient { public static void main(String[] args) throws Exception { // 创建webclient WebClient webClient = new WebClient(); // 取消 JS 支持 webClient.getOptions().setJavaScriptEnabled(false); // 取消 CSS 支持 webClient.getOptions().setCssEnabled(false); // 获取指定网页实体 HtmlPage page = (HtmlPage) webClient.getPage("https://www.so.com/"); // 获取搜索输入框 HtmlInput input = (HtmlInput) page.getHtmlElementById("input"); // 往输入框 “填值” input.setValueAttribute("larger5"); // 获取搜索按钮 HtmlInput btn = (HtmlInput) page.getHtmlElementById("search-button"); // “点击” 搜索 HtmlPage page2 = btn.click(); // 选择元素 List spanList=page2.getByXPath("//h3[@class='res-title']/a"); for(int i=0;i 三、效果

四、源码与原网页
1、搜索页
①界面
②源码

2、搜索结果页
①界面
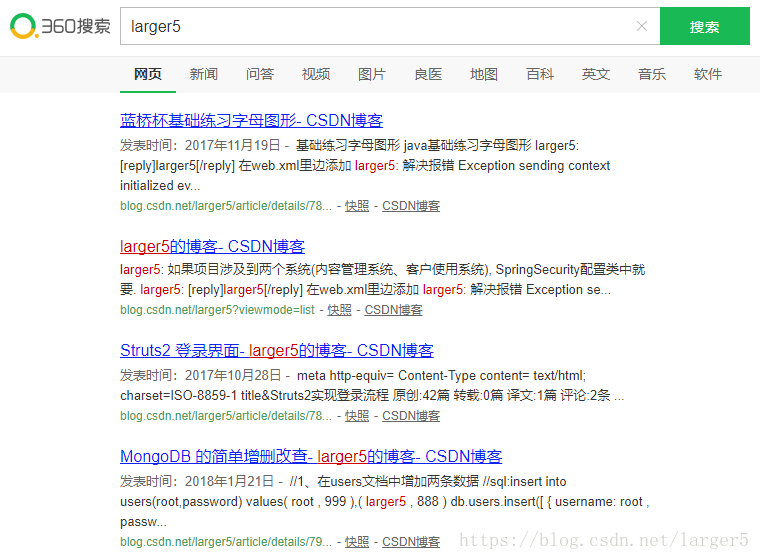
②源码

转载地址:https://larger5.blog.csdn.net/article/details/79683048 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
初次前来,多多关照!
[***.217.46.12]2024年04月11日 15时41分59秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
COMP7404 Machine Learing——KNN
2019-04-30
COMP7404 Machine Learing——SVM
2019-04-30
COMP7404 Machine Learing——ROC
2019-04-30
Python量子计算qiskit
2019-04-30
Python的多线程不是真的多线程(GIL全局解释器锁)
2019-04-30
Python手动读取MNIST数据集
2019-04-30
Python手动读取CIFAR-10数据集
2019-04-30
Pytorch(十一) —— 分布式(多GPU)训练
2019-04-30
Deeplab v3
2019-04-30
NLP 之 Perplexity困惑度
2019-04-30
tensor/矩阵/图片等更换通道,调整size
2019-04-30
本地和colab 中 改变tensorflow的版本
2019-04-30
Camera-ready ddl
2019-04-30
CUB-200鸟类数据集
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310878366 位访客
访问时间: 2024-05-04 23:51:35
访问IP: 3.147.104.120
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版