[Java爬虫] 使用 Xpath + HtmlUnit 爬取网页基本信息

发布日期:2021-06-30 16:50:40
浏览次数:4
分类:技术文章
本文共 2259 字,大约阅读时间需要 7 分钟。
一、前言
使用 Jsoup + HttpClient (组合一)基本可以爬取很多我们需要的信息了,Xpath + HtmlUnit (组合二)的组合更是强大,无论是从选择上,还是从解析上,都可以胜任组合一的。下面列举一个简单的例子,主要展示了其主要的技术:①模拟浏览器、②使用代理IP、③取消CSS、JS解析、④Xpath的简单使用
Ⅰ、其他基础:
① 使用Xpath的一个例子: ② Xpath 基本知识:Ⅱ、联系之前:
①Jsoup+HttpClient:
二、需求
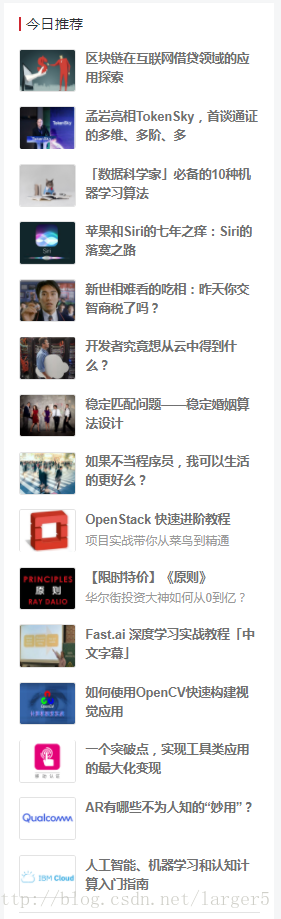
现在要爬取 CSDN 的【今日推荐】的文章标题(实际应用上,应该是爬取整篇文章,很多 IT 社区就是这样建立起来的)
三、代码
package com.cun.test;import java.io.IOException;import java.net.MalformedURLException;import java.util.List;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.HtmlElement;import com.gargoylesoftware.htmlunit.html.HtmlPage;/** * 核心技术: * 1、HtmlUnit 基本使用架构 * 2、HtmlUnit 模拟浏览器 * 3、使用代理 IP * 4、静态网页爬取,取消 CSS、JS 支持,提高速度 * @author linhongcun * */public class JsoupHttpClient { public static void main(String[] args) { // 实例化Web客户端、①模拟 Chrome 浏览器 ✔ 、②使用代理IP ✔ WebClient webClient = new WebClient(BrowserVersion.CHROME, "118.114.77.47", 8080); webClient.getOptions().setCssEnabled(false); // 取消 CSS 支持 ✔ webClient.getOptions().setJavaScriptEnabled(false); // 取消 JavaScript支持 ✔ try { HtmlPage page = webClient.getPage("https://www.csdn.net/"); // 解析获取页面 /** * Xpath:级联选择 ✔ * ① //:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 * ② h3:匹配标签 * ③ [@class='company_name']:属性名为class的值为company_name * ④ a:匹配标签 */ List spanList=page.getByXPath("//h3[@class='company_name']/a"); for(int i=0;i innerHTML ✔ System.out.println(i+1+"、"+spanList.get(i).asText()); } } catch (FailingHttpStatusCodeException e) { e.printStackTrace(); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { webClient.close(); // 关闭客户端,释放内存 } }}
pom.xml依赖
net.sourceforge.htmlunit htmlunit 2.29
四、效果

怎样,是不是觉得很简单?
——————————2018.3.22—————————
后来才发现少了网页的源码,这样使用 Xpath 的那部分代码就有点难以理解 今天就补上去吧,虽然今日推荐已经改了,但是标签结构是不变的转载地址:https://larger5.blog.csdn.net/article/details/79641404 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
不错!
[***.144.177.141]2024年05月03日 01时12分53秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
POJ-3304 Segments(计算几何)
2019-04-30
UVA-11538 Chess Queen(数学)
2019-04-30
UVA-11401 Triangle Counting(数学优化)
2019-04-30
Codeforces Round #369 (Div. 2)
2019-04-30
UVA 11426 GCD - Extreme (II)(欧拉函数)
2019-04-30
HDU-2838 Cow Sorting(树状数组)
2019-04-30
POJ-2299 Ultra-QuickSort(树状数组)(离散化)
2019-04-30
基于SSM的兼职论坛系统的设计与实现
2019-04-30
基于java的图书管理系统的设计与实现
2019-04-30
基于java的SSM框架理财管理系统的设计与实现
2019-04-30
基于java的ssm框架就业信息管理系统的设计
2019-04-30
基于java的ssm框架的旅游网站设计与实现
2019-04-30
基于java的SSM框架的流浪猫救助网站的设计与实现
2019-04-30
基于java的SSM框架的教务关系系统的设计与实现
2019-04-30
别再问我什么是A/B测试了!
2019-04-30
如何用同期群分析模型提升留存?(Tableau实战)
2019-04-30
爱了,吹爆这个高颜值的流程图工具!
2019-04-30
一个数据项目
2019-04-30
基于JAVA_JSP电子书下载系统
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310845981 位访客
访问时间: 2024-05-04 22:34:29
访问IP: 3.138.174.174
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版