[Java爬虫] 使用 Jsoup + HttpClient 爬取网页图片
发布日期:2021-06-30 16:50:40
浏览次数:3
分类:技术文章
本文共 2946 字,大约阅读时间需要 9 分钟。
一、前言
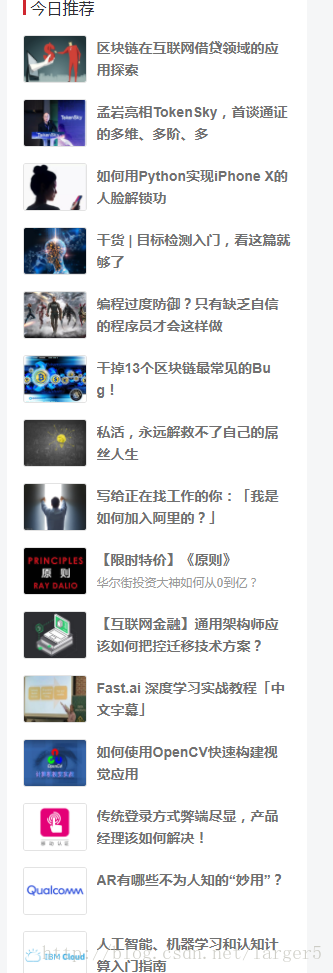
把一篇图文并茂的优秀文章全部爬取下来,就少不了 Java 爬虫里边的 图片爬取 技术了。很多人都用来爬取美女图片,但是笔者觉得这有伤大雅。下面笔者使用它来爬取 CSDN 【今日推荐】文章附带的图片
二、代码、依赖
笔者对本代码经过多次修订,逻辑可以说是最简单的了,但性能上可能就算不上是最优的了,基本用法都注释在代码里边,该注意的地方都打 ✔ 了
①目录
(使用 SpringBoot 创建的工程,当然也可以使用 Java Project、web Project、Maven Project)
② 代码
package com.cun.test;import java.io.File;import java.io.IOException;import java.io.InputStream;import org.apache.commons.io.FileUtils;import org.apache.http.HttpEntity;import org.apache.http.client.ClientProtocolException;import org.apache.http.client.methods.CloseableHttpResponse;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.CloseableHttpClient;import org.apache.http.impl.client.HttpClients;import org.apache.http.util.EntityUtils;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;/** * 1、使用 HttpClient 获取网页文档对象 * 2、使用 Jsoup 获取所需的信息 * 3、不足:没有判断图片类型,但是没什么影响 * @author linhongcun * */public class JsoupHttpClient { public static void main(String[] args) throws ClientProtocolException, IOException { // 创建httpclient实例 CloseableHttpClient httpclient = HttpClients.createDefault(); // 创建httpget实例 HttpGet httpget = new HttpGet("https://www.csdn.net/"); // 执行get请求 CloseableHttpResponse response = httpclient.execute(httpget); HttpEntity entity = response.getEntity(); // 获取返回实体 String content = EntityUtils.toString(entity, "utf-8"); // 解析网页 得到文档对象 Document doc = Jsoup.parse(content); // 获取指定的 ![]() Elements elements = doc.select(".img_box img"); for (int i = 0; i < 15; i++) { Element element = elements.get(i); // 获取
Elements elements = doc.select(".img_box img"); for (int i = 0; i < 15; i++) { Element element = elements.get(i); // 获取 ![]() 的 src String url = element.attr("src"); // 再发请求最简单了,并由于该链接是没有 https:开头的,得人工补全 ✔ HttpGet PicturehttpGet = new HttpGet("https:" + url); CloseableHttpResponse pictureResponse = httpclient.execute(PicturehttpGet); HttpEntity pictureEntity = pictureResponse.getEntity(); InputStream inputStream = pictureEntity.getContent(); // 使用 common-io 下载图片到本地,注意图片名不能重复 ✔ FileUtils.copyToFile(inputStream, new File("C://LLLLLLLLLLLLLLLLLLL//imagesTest//" + i + ".jpg")); pictureResponse.close(); // pictureResponse关闭 } response.close(); // response关闭 httpclient.close(); // httpClient关闭 }}
的 src String url = element.attr("src"); // 再发请求最简单了,并由于该链接是没有 https:开头的,得人工补全 ✔ HttpGet PicturehttpGet = new HttpGet("https:" + url); CloseableHttpResponse pictureResponse = httpclient.execute(PicturehttpGet); HttpEntity pictureEntity = pictureResponse.getEntity(); InputStream inputStream = pictureEntity.getContent(); // 使用 common-io 下载图片到本地,注意图片名不能重复 ✔ FileUtils.copyToFile(inputStream, new File("C://LLLLLLLLLLLLLLLLLLL//imagesTest//" + i + ".jpg")); pictureResponse.close(); // pictureResponse关闭 } response.close(); // response关闭 httpclient.close(); // httpClient关闭 }} ③ pom 依赖
org.apache.httpcomponents httpclient 4.5.5 org.jsoup jsoup 1.11.2 commons-io commons-io 2.5
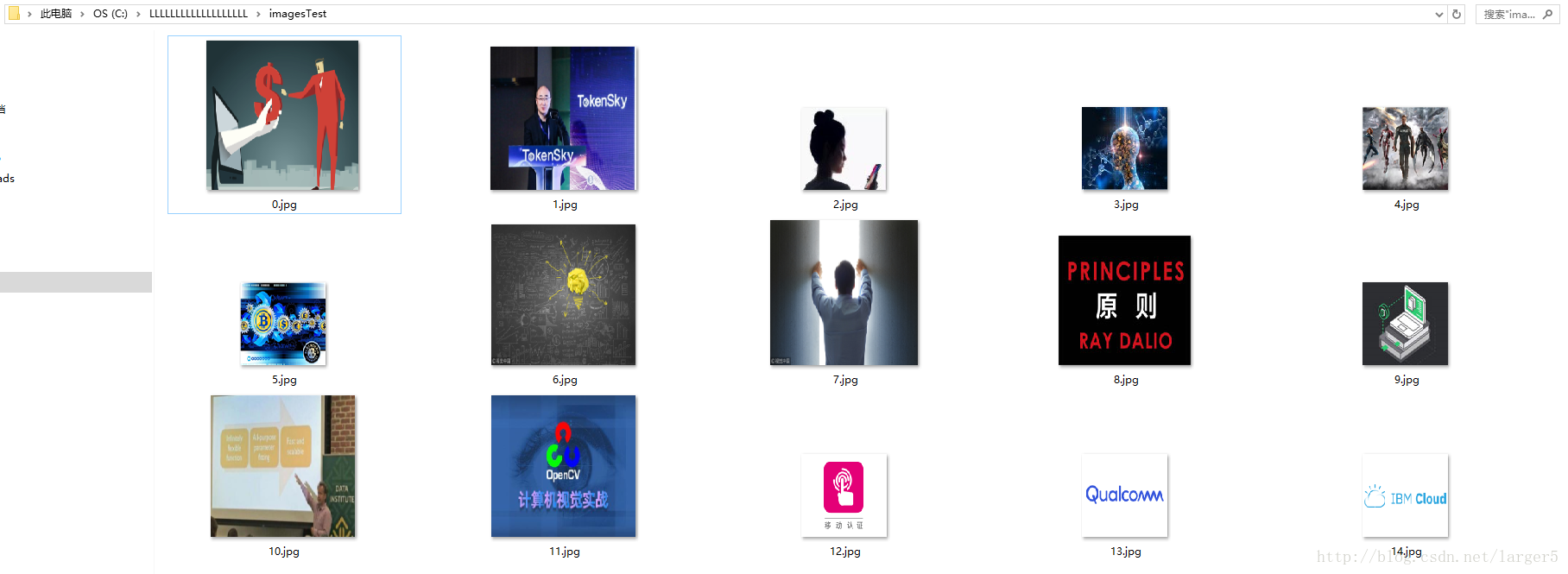
三、效果
四、小结
1、优化:
可以根据图片的后缀 .jpg、.png、.gif 保存相应格式的图片到本地,不要一味 .jpg 结尾保存
2、附上 CSDN 主页部分源码

3、爬虫资源先放到本地,再放到服务器,否则对服务器 CPU 消耗巨大,服务器成本高
转载地址:https://larger5.blog.csdn.net/article/details/79620389 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
表示我来过!
[***.240.166.169]2024年04月23日 07时11分06秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
nginx访问控制、基于用户认证、https配置
2019-04-30
用zabbix监控nginx
2019-04-30
SaltStack
2019-04-30
Jenkins 控制台输出中的奇怪字符
2019-04-30
Linux添加系统调用
2019-04-30
linux内存的寻址方式
2019-04-30
ubunut16.04的pip3出现问题,重新安装pip3
2019-04-30
how2heap-double free
2019-04-30
how2heap-fastbin_dup_consolidate
2019-04-30
orw_shellcode_模板
2019-04-30
[fmt+shellcode]string
2019-04-30
fmt在bss段(neepusec_easy_format)
2019-04-30
[double free] 9447 CTF : Search Engine
2019-04-30
python 函数式编程
2019-04-30
python编码
2019-04-30
scala maven plugin
2019-04-30
flink 1-个人理解
2019-04-30
redis cli
2019-04-30
redis api
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310776366 位访客
访问时间: 2024-05-04 19:39:54
访问IP: 18.189.2.122
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版