本文共 8533 字,大约阅读时间需要 28 分钟。
目录
1.jvm相关问题
1.1 JVM内存结构

方法区和堆是线程共享的,java stack和本地方法stack和程序计数器都是线程私有的。
1.2 JVM内存模型


注意:内存区域分为Young,Old,Permanenet区。我们讨论的Eden和两个S区都在Young区
- Eden区满后发生一次minor GC,Eden区到对象80%都是短生命周期短,很容易消亡(大对象直接进入老年代)。此时复制对象到Survivor0区。
- 当Eden再次满,发生minorGC的时候,复制eden和s0区对象到s1,为了保证内存连续,不产生内存碎片。然后清空edge和s0
- s0和s1进行交换,当eden再次发生minorGC当时候,复制eden对象和s0中当对象到s1中,如此循环,16次之后就会送入老年代
1.3 类加载机制

- 加载,查找并加载类的二进制数据,在Java堆中也创建一个java.lang.Class类的对象
- 连接,连接又包含三块内容:验证、准备、初始化。1)验证,文件格式、元数据、字节码、符号引用验证;2)准备,为类的静态变量分配内存,并将其初始化为默认值;3)解析,把类中的符号引用转换为直接引用
- 初始化,为类的静态变量赋予正确的初始值
- 使用,new出对象程序中使用
- 卸载,执行垃圾回收

1.4 GC算法
GC最基础的算法有三种:标记 -清除算法、复制算法、标记-压缩算法,我们常用的垃圾回收器一般都采用分代收集算法。
- 标记 -清除算法,“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
- 复制算法,“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
- 标记-压缩算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
- 分代收集算法,“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法
“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或“标记-整理”算法来进行回收
1.5 垃圾回收器
Serial收集器:新生代复制算法,老年代标记-压缩算法,会出现stop the world
ParNew收集器:Serial收集器的多线程版本。新生代并行,老年代串行;新生代复制算法、老年代标记-压缩
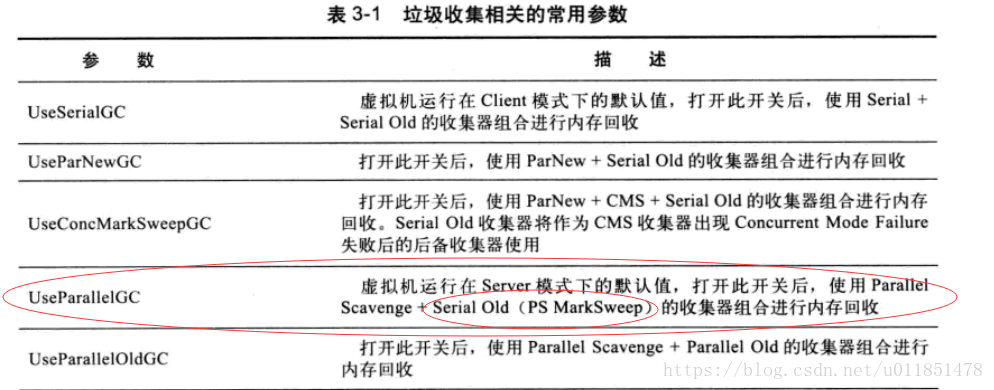
Parallel Scavenge收集器:更关注系统的吞吐量。可以通过参数来打开自适应调节策略,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或最大的吞吐量;也可以通过参数控制GC的时间不大于多少毫秒或者比例;新生代复制算法、老年代标记-压缩
CMS(老年代收集器):CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分的Java应用都集中在互联网站或B/S系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验。
bogon:big-goose-card hanruikai$ java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=268435456 -XX:MaxHeapSize=4294967296 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC java version "1.8.0_151" Java(TM) SE Runtime Environment (build 1.8.0_151-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode) bogon:big-goose-card hanruikai$参考文章:
1.6 调优命令
Sun JDK监控和故障处理命令有jps jstat jmap jhat jstack jinfo
- jps,JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。
- jstat,JVM statistics Monitoring是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
- jmap,JVM Memory Map命令用于生成heap dump文件
- jhat,JVM Heap Analysis Tool命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看
- jstack,用于生成java虚拟机当前时刻的线程快照。
- jinfo,JVM Configuration info 这个命令作用是实时查看和调整虚拟机运行参数。
常用调优工具分为两类,jdk自带监控工具:jconsole和jvisualvm,第三方有:MAT(Memory Analyzer Tool)、GChisto。
- jconsole,Java Monitoring and Management Console是从java5开始,在JDK中自带的java监控和管理控制台,用于对JVM中内存,线程和类等的监控
- jvisualvm,jdk自带全能工具,可以分析内存快照、线程快照;监控内存变化、GC变化等。
- MAT,Memory Analyzer Tool,一个基于Eclipse的内存分析工具,是一个快速、功能丰富的Java heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗
- GChisto,一款专业分析gc日志的工具
1.5 JDK1.8在jvm有什么优化
1.8同1.7比,最大的差别就是:元数据区取代了永久代。元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元数据空间并不在虚拟机中,而是使用本地内存。那么,Java 8 中 PermGen 为什么被移出 HotSpot JVM 了?我总结了两个主要原因(详见:):
- 由于 PermGen 内存经常会溢出,引发恼人的 java.lang.OutOfMemoryError: PermGen,因此 JVM 的开发者希望这一块内存可以更灵活地被管理,不要再经常出现这样的 OOM
- 移除 PermGen 可以促进 HotSpot JVM 与 JRockit VM 的融合,因为 JRockit 没有永久代
使用本地内存有什么好处呢?最直接的表现就是OOM问题将不复存在,因为默认的类的元数据分配只受本地内存大小的限制,也就是说本地内存剩余多少,理论上Metaspace就可以有多大(貌似容量还与操作系统的虚拟内存有关?这里不太清楚),这解决了空间不足的问题。不过,让 Metaspace 变得无限大显然是不现实的,因此我们也要限制 Metaspace 的大小:使用 -XX:MaxMetaspaceSize 参数来指定 Metaspace 区域的大小。JVM 默认在运行时根据需要动态地设置 MaxMetaspaceSize 的大小。
除此之外,它还有以下优点:
- Take advantage of Java Language Specification property : Classes and associated metadata lifetimes match class loader’s
- Linear allocation only
- No individual reclamation (except for RedefineClasses and class loading failure)
- No GC scan or compaction
- No relocation for metaspace objects
如果Metaspace的空间占用达到了设定的最大值,那么就会触发GC来收集死亡对象和类的加载器。根据JDK 8的特性,G1和CMS都会很好地收集Metaspace区(一般都伴随着Full GC)。
为了减少垃圾回收的频率及时间,控制吞吐量,对Metaspace进行适当的监控和调优是非常有必要的。如果在Metaspace区发生了频繁的Full GC,那么可能表示存在内存泄露或Metaspace区的空间太小了。
新增的 JVM 参数
- -XX:MetaspaceSize 是分配给类元数据空间(以字节计)的初始大小(Oracle逻辑存储上的初始高水位,the initial high-water-mark ),此值为估计值。MetaspaceSize的值设置的过大会延长垃圾回收时间。垃圾回收过后,引起下一次垃圾回收的类元数据空间的大小可能会变大。
- -XX:MaxMetaspaceSize 是分配给类元数据空间的最大值,超过此值就会触发Full GC,此值默认没有限制,但应取决于系统内存的大小。JVM会动态地改变此值。
- -XX:MinMetaspaceFreeRatio 表示一次GC以后,为了避免增加元数据空间的大小,空闲的类元数据的容量的最小比例,不够就会导致垃圾回收。
- -XX:MaxMetaspaceFreeRatio 表示一次GC以后,为了避免增加元数据空间的大小,空闲的类元数据的容量的最大比例,不够就会导致垃圾回收。
参考资料:
2.并发与锁
2.1 countdownlatch和cyclic barrier
- CountDownLatch: 服务依赖场景,比如服务启动时,依赖其他多个服务启动,使用过并发控制。
- CyclicBarrier:从名字可以看出,Cyclic指的是可以重复使用,Barrier指的是等待同一个点,一起继续执行。和countdownlatch区别有:第一可以重复使用,第二可以指定到达barrier后实现特定逻辑(某一个线程实现,不是所有线程),在构造方法传入runnable实现。parties是参与线程数,构造方法如下:
public CyclicBarrier(int parties, Runnable barrierAction) {} public CyclicBarrier(int parties) {} -
CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
代码举例:
注意点:使用场景,线程之间协作之后各自执行自己对逻辑。CyclicBarrier构造方法注入对Runnable实现,只有一个线程执行,这个例子里面是分发护照和签证。
/** * 旅行线程 * Created by jiapeng on 2018/1/7. */public class TravelTask implements Runnable{ private CyclicBarrier cyclicBarrier; private String name; private int arriveTime;//赶到的时间 public TravelTask(CyclicBarrier cyclicBarrier,String name,int arriveTime){ this.cyclicBarrier = cyclicBarrier; this.name = name; this.arriveTime = arriveTime; } @Override public void run() { try { //模拟达到需要花的时间 Thread.sleep(arriveTime * 1000); System.out.println(name +"到达集合点"); cyclicBarrier.await(); System.out.println(name +"开始旅行啦~~"); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } }} /** * 导游线程,都到达目的地时,发放护照和签证 * Created by jiapeng on 2018/1/7. */public class TourGuideTask implements Runnable{ @Override public void run() { System.out.println("****导游分发护照签证****"); try { //模拟发护照签证需要2秒 Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } }} /** * Created by jiapeng on 2018/1/7. */public class Client { public static void main(String[] args) throws Exception{ CyclicBarrier cyclicBarrier = new CyclicBarrier(3,new TourGuideTask()); Executor executor = Executors.newFixedThreadPool(3); //登哥最大牌,到的最晚 executor.execute(new TravelTask(cyclicBarrier,"哈登",5)); executor.execute(new TravelTask(cyclicBarrier,"保罗",3)); executor.execute(new TravelTask(cyclicBarrier,"戈登",1)); }} 
代码摘自:
2.2 Synchronize和lock
1. Synchronized
- Synchronized锁住的是对象!
之所以锁住的是对象,一个对象包括,对象头部,实例数据,对齐填充等。因为java中每个对象实例都会有一个 monitor。其中monitor可以与对象一起创建、销毁;亦或者当线程试图获取对象锁时自动生成。
被锁对象的头部有个指针指向monitor对象,monitor对象内部结构如下:
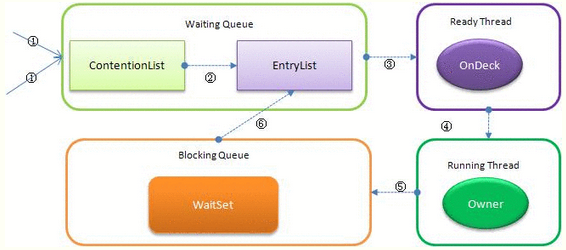
- JDK1.5之后优化
自旋锁:如果没有获取到锁,自旋一会,类似于做一些无用的事情,避免线程切换的开销。一直自旋影响cpu性能,所以一般设置次数为10次
锁消除:
偏向锁:
参考文章:
3.stringbuffer和string builder
4. hashmap concurrenthashmap
5. 为什么用spring boot? 和spring mvc什么关系?
6 mybatis缓存,分页,性能问题
7 Rabbitmq基础
7.1如何保证消息发送到MQ
发送方确认模式,异步回调。成功失败与否都会回调,如果ack为false,那么不更改消息记录表状态,依靠分布式定时任务进行消息重发补偿。
7.2 如何保证消费者接收到消息
消费者确认模式。只有消费者确认了消息,MQ才会把消息移除。假如消费者和MQ断开连接,MQ会认为没有收到消息,尝试重新发送。如果连接没有断开,但是一直没有回复ACK,MQ会认为消费者处理忙,不再分发新的消息。
只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息
7.3 消息幂等性
利用订单号,流水号等业务去重
7.4 什么是channel
很明显MQ肯定是基于TCP连接传输的,但是tcp连接数有限,并且受到系统配置的限制,无法支持高并发。所以Channel就是基于TCP虚拟出来的连接,并且一个TCP连接上可以创建无数个channel。看下文官方描述:
Some applications need multiple logical connections to the broker. However, it is undesirable to keep many TCP connections open at the same time because doing so consumes system resources and makes it more difficult to configure firewalls. AMQP 0-9-1 connections are multiplexed with channels that can be thought of as "lightweight connections that share a single TCP connection".
7.5 消息如何分发
如果一个队列有多个消费者,round-robin的方式进行分发,如果某个消费者无法正常确认,除外,mq将把消费发给其他消费者。
7.6 消息如何路由

可以没有exchange吗?如果exchage为空串,会利用默认的exchange。
In previous parts of the tutorial we knew nothing about exchanges, but still were able to send messages to queues. That was possible because we were using a default exchange, which we identify by the empty string ("").

Fanout模式,exchange接收到消息,分发给所有它知道到队列

Direct模式,exchange接收到消息,按照routing key分发给队列

Topic模式,exchange接收到消息,按照routing key分发,可以利用通配符,多个消息到达同一个队列,但是性能要考虑!
常用的交换器主要分为一下三种:
- direct:如果路由键完全匹配,消息就被投递到相应的队列
- fanout:如果交换器收到消息,将会广播到所有绑定的队列上
- topic:可以使来自不同源头的消息能够到达同一个队列。 使用topic交换器时,可以使用通配符,比如:“*” 匹配特定位置的任意文本, “.” 把路由键分为了几部分,“#” 匹配所有规则等。特别注意:发往topic交换器的消息不能随意的设置选择键(routing_key),必须是由"."隔开的一系列的标识符组成。
7.7 Rabbitmq作用
异步,解耦,流量削峰
7.8 Queue 中存放的 message 是否有数量限制?
可以认为是无限制,因为限制取决于机器的内存,但是消息过多会导致处理效率的下降
8 redis为什么单线程而且快?比较Cassandra和mongodb
9 比较mysql和postgresql
10,为什么用docker?优缺点
11 比较maven和gradle
转载地址:https://kerry.blog.csdn.net/article/details/88378232 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
