本文共 2493 字,大约阅读时间需要 8 分钟。
1.什么是覆盖索引和回表查询
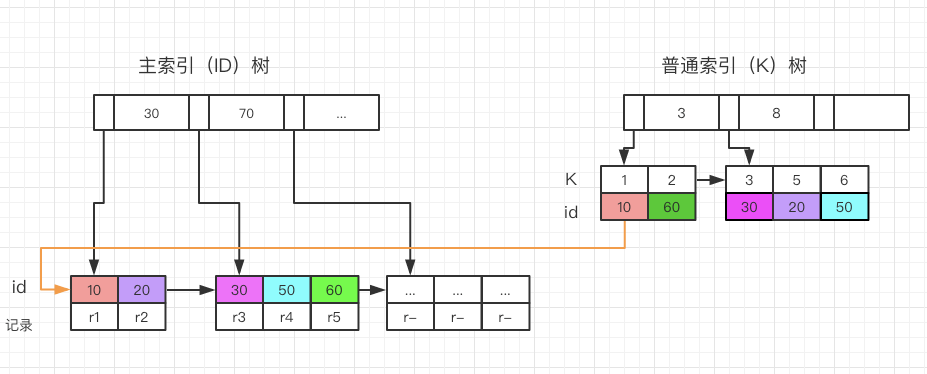
首先,我们看看mysql的索引类型,mysql包括两种索引类型,聚集索引和非聚集索引:
聚集索引(主键索引):
聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的即为整张表的记录数据。
聚集索引的叶子节点称为数据页,聚集索引的这个特性决定了索引组织表中的数据也是索引的一部分。
辅助索引(二级索引):
非主键索引,叶子节点=键值+书签。Innodb存储引擎的书签就是相应行数据的主键索引值。
关于聚集索引说明如下:
- 每个表必须且只能有一个聚集索引,如果设置主键,那么主键就是聚集索引
- 非聚集索引,比如普通索引,都是通过B+ tree的检索后,叶子节点包含主键id,再去聚集索引寻找记录,因为聚集索引的叶子节点,包含所有行记录信息
- 如果没有设置聚集索引,mysql会默认生成rowid作为聚集索引
说到这里,我们来看什么是覆盖索引和回表查询,比如下面的表结构:
create table `t_member` ( `id` int (11), `member_no` varchar (36), `user_name` varchar (384), `register_date` datetime );
如果设置id为主键,member_no为索引,那么根据member_no查询的时候,首先查询member_no的索引树,在查询到叶子节点后,根据节点的主键id,再去主键索引树上面查询具体的行记录,包括所有字段信息。OK,思考下面三个查询语句:
EXPLAIN SELECT t.id,t.user_name from t_member t;EXPLAIN SELECT t.id,t.user_name,t.register_date from t_member t;
区别如下:
- 第一个是查询索引列,第二个是查询索引列和非索引列
- 第一个查询,根据user name查询之后,在user name的索引树上直接就能获取主键id,所以不需要回表查询,直接返回结果
- 第二个查询,在根据user name查询之后,在user name的索引树树获取主键id,然后去主键的非聚集索引树再次查询,查询到行记录,获取register data,存在回表查询行为,效率较低
2. 测试对比
我们通过explain查看是否使用了覆盖索引:
使用覆盖索引的情况(id和user name都有索引的情况,查询的列都有索引的):

未使用覆盖索引的情况(id和user name都有索引的情况,查询的列有的没有索引,全表扫描):

根据explain的耗时也能看出,第一个利用覆盖索引的效率更高,尤其是在大数据量的情况下,第二个全表扫描。
特别注意,extra的内容:
Extra:Using index 表示没有回表查询的过程,实现了索引覆盖
Extra:Using index condition 表示使用的索引方式为二级检索,可以通过建立联合索引的方式,避免回表扫描。
比如如果查询的是(id和user name都有索引的情况,register data没有索引,全表扫描)

此时register data没有索引,所以extra显示是using where。如果我们给register data建立索引,效果如下:

看看二级索引的效果如下(此时三个列都有索引):

如何变为覆盖索引呢?查询列里面 去掉user name,(去掉另外一个register data也可以,都可以避免回表查询)效果如下:

如果必须有user name,怎么办,怎么避免回表查询呢???建立联合索引!!!
修改索引如下:

查询计划如下:

可以看出extra字段跟我们之前的效果一样,利用覆盖索引,避免回表查询。
3. 案例
我们看一下下面的常见sql,利用limit分页,数据量大时显然效率不高:
SELECT * FROM table WHERE campaing_id = 1024 LIMIT N,M
利用覆盖索引,当sql查询是完全命中索引,即返回参数和查询条件都有索引时,利用覆盖索引方式查询性能很高。修改如下:
SELECT * FROM table AS t1 INNER JOIN ( SELECT id FROM table WHERE campaing_id = 1024 LIMIT N,M ) AS t2 ON t1.id = t2.id
item_pool_id和status必须是联合索引,否则无法避免回表查询。
另一个思路:
使用limit大翻页最大的问题是查询前N(即offset)条数据所耗费的时间,在理想的情况下,id是连续自增,可以在where条件中使用id来代替offset,sql即如下所示。
SELECT * FROM table WHERE campaing_id = 1024 and id > N LIMIT M
一般不满足这个场景,但是思路可以优化,有个文章给了一个可能场景的思路,以后研究一下:

图片来源:
4.总结
覆盖索引是一种非常强大的工具,能大大提高查询性能,只需要读取索引而不需要读取数据,有以下优点:
1、索引项通常比记录要小,所以MySQL访问更少的数据。
2、索引都按值得大小存储,相对于随机访问记录,需要更少的I/O。
3、数据引擎能更好的缓存索引,比如MyISAM只缓存索引。
4、覆盖索引对InnoDB尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引包含查询所需的数据,就不再需要在聚集索引中查找了。
限制:
1、覆盖索引也并不适用于任意的索引类型,索引必须存储列的值。
2、Hash和full-text索引不存储值,因此MySQL只能使用BTree。
3、不同的存储引擎实现覆盖索引都是不同的,并不是所有的存储引擎都支持覆盖索引。
4、如果要使用覆盖索引,一定要注意SELECT列表值取出需要的列,不可以SELECT * ,因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降
转载地址:https://kerry.blog.csdn.net/article/details/110955352 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
