本文共 6145 字,大约阅读时间需要 20 分钟。
前言
本人大数据专业初入大三刚刚接触机器学习这一课程,最近在学习这本书《机器学习实战》,第三章的内容就是决策树,概念非常简单,但是实现的话根据不同聚类情况要做出不同调整会有些许难。当然初入一些算法和机器学习的一些库还不是很熟练掌握,有待提升自己的编程结合能力。在此领域本人有诸多不明确疑问,可能文章会有些许错误,望大家在评论区指正,本篇文章错误将会不断更正维护。
提示:以下是本篇文章正文内容,下面案例可供参考
一、决策树概述
决策树(Decision Tree)是在已知各种情况发生概率的上,通过构成决策树来求取净现值的值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。
分类树(决策树)是一种十分常用的分类方法。他是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
从数据产生决策树的机器学习技术叫做决策树学习, 通俗说就是决策树。
一个决策树包含三种类型的节点:
-
决策节点:通常用矩形框来表示
-
机会节点:通常用圆圈来表示
-
终结点:通常用三角形来表示
决策树学习也是资料探勘中一个普通的方法。在这里,每个决策树都表述了一种树型结构,它由它的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据库的分割进行数据测试。这个过程可以递归式的对树进行修剪。 当不能再进行分割或一个单独的类可以被应用于某一分支时,过程就完成了。另外,分类器将许多决策树结合起来以提升分类的正确率。
概述一般看文字有点难懂,那让我们来理解一下它的工作原理就很好理解了。
二、工作原理及特点
决策树的工作原理与你问我答缩小范围类似,用户输入一系列数据,然后给出自己偏好。有点像以前学C的小算法猜闰年相似。

决策树的主要优势就在于数据形式非常容易理解。因此决策树可以使用不熟悉的数据集合,并从中提取出一系列规则。
决策树的特点:
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配的问题
- 适用数据类型:数值型和标称型
三、决策树的构造
在构造决策树时,我们要抓住问题,也就是得到答案的关键性问题,划分出最好的结果。因此我们必须评估每个特征,找出最优的划分结果。根据决策树伪代码可知:

从中分析可知该算法是一个递归分类算法,有三种情况会导致递归返回:
1.该分支下的数据的属性标签全为一类,则停止划分。
2.当询问完所有问题特征后,特征列表为空,则停止划分,选举属性标签出现频率最多的为叶节点。
3.当前节点包含的样本集合为空,标记当前节点为叶节点,并将其类别设为父节点所含样例最多的类别。
四、信息增益
了解完决策树基本工作原理和构造方法后,现在要了解如何处理数据使得数据更有利用效率被决策树使用。划分数据集的大原则是:将无需的数据变得更加有序。我们得找出划分数据集最关键的特征,也就是询问别人最高效区分类别的问题。首先我们得要有一个关于如何度量信息有序程度的变量。
信息熵:这里不作过多关于热力学方面的解释,仅针对信息。信息熵定位为信息的期望值。假定当前样本集合D中第k类样本所占的比例为pk(k = 1,2,...,|Y|),则D的信息熵定义为:
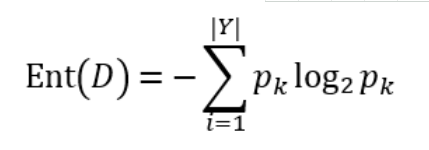
对于底数之所以取2,一般的理解是,因为信息按照计算机表示采用的是二进制形式。由定义可推知,Ent(D)的值越小,则D的纯度越高。
在理解信息增益之前,要明确——条件熵
信息增益表示得知特征X的信息而使得类Y的信息不确定性减少的程度。
条件熵H ( Y ∣ X ) H(Y|X)H(Y∣X)表示在已知随机变量X的条件下随机变量Y的不确定性,随机变量X给定的条件下随机变量Y的条件熵(conditional entropy) H(Y|X),定义X给定条件下Y的条件概率分布的熵对X的数学期望:
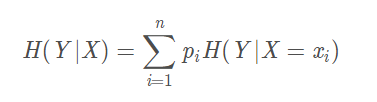
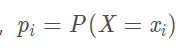
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的分别为经验熵和经验条件熵,此时如果有0概率,令0log0=0.
在此基础上,给出“信息增益”(information gain)的定义:
假定离散属性a有V种不同的取值{a1, a2, ..., aV},使用a对D进行划分,则会产生V个分支节点,其中第v个分支节点包含D中属性值为av的样本,记为Dv,则用属性a对样本集D进行划分所获得的信息增益定义为:
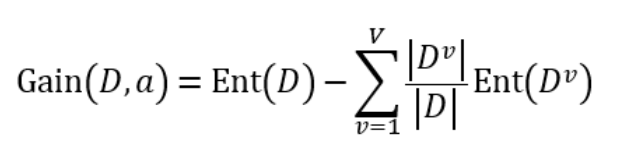
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的纯度提升越大。于是,我们便可以按信息增益来选择决策树的划分属性。相关的算法有著名的ID3算法[Quinlan, 1986]。
然而事实上,信息增益对可取值数目较多的属性有所偏好。这种偏好可能会降低模型的泛化能力。为减少这种偏好带来的不利影响,著名的C4.5决策树算法[Quinlan, 1993]不直接使用信息增益,而使用“增益率”(gain ratio)来划分最优属性。下面引入增益率的概念。()
由于本篇仅使用信息增益划分数据集,另外两种度量方式增益率和基尼系数不作过多解释,有兴趣的可以看上面大佬博客。
五、决策树实现
了解了上面基础知识差不多可以构建树了,决策树的剪枝处理和连续与缺失值等优化问题先不作讨论。
这里我们模拟小部分数据:

根据这些数据我们来慢慢构造决策树,最后实现其主要功能。
1.构造数据集
将上述数据转为列表,当然例子数据比较简单,其他数据做不同处理。
def createDataSet(): dataSet = [[1,1,'yes'], [1,1,'yes'], [1,0,'no'], [0,1,'no'], [0,1,'no']] labels = ['no surfacing ','flippers'] return dataSet,labels
2.计算熵值
为该类数据分类最好使用数据字典来保存分类结果。
def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCounts = {} #创建记录不同分类标签结果多少的字典 #为所有可能分类保存 #该字典key:label value:label的数目 for featVec in dataSet: currentLabel = featVec[-1] if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0 labelCounts[currentLabel] += 1 shannonEnt = 0.0 for key in labelCounts: prob = float(labelCounts[key])/numEntries #标签发生概率p(xi)的值 shannonEnt -= prob * log(prob,2) return shannonEnt #熵 代码实现和上述熵计算一致。测试该数据集未分类之前的熵:
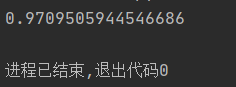
当然可以根据改动原有数据集标签来测试熵值的波动:

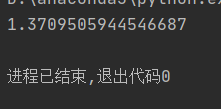
可发现数据越混乱熵值越高。
3.按特征划分数据
def splitDataSet(dataSet , axis ,value):#axis代表第几个特征 value为结果 #避免修改原始数据集创建新数据集 retDataSet = [] #抽取符合特征的数据集 for featVec in dataSet: if featVec[axis] == value: reducedFeatVec = featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet
可以说就是挑选出符合特征的数据集然后将自身特征值抛出列表。
我们可以试试效果:
a=splitDataSet(dataSet,1,0)print(a)[[1, 'yes'], [1, 'yes'], [0, 'no']]
没问题。
4.选择最优划分算法
如何就是决策树的重点,如何选择最优的划分方式,也就是选择信息增益最大化的方式,通过for循环对不同的特征值进行划分,计算每种方式的信息熵,然后取得最大信息增益划分方式,计算最好的信息增益,返回最好特征划分的索引值。
#选择最好的数据集划分方式def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0])-1 #全部特征 baseEntropy = calcShannonEnt(dataSet) #基础熵 bestInfoGain = 0.0 bestFeature = -1 for i in range(numFeatures): #创建唯一的分类标签列表 featList = [example[i] for example in dataSet] uniqueVals = set(featList) #建立列表同特征下不同回答 newEntropy = 0.0 #计算每种划分方式的信息熵 for value in uniqueVals: subDataSet = splitDataSet(dataSet,i,value) #划分 prob = len(subDataSet)/float(len(dataSet)) #同特征下不同回答所占总回答比率 newEntropy += prob * calcShannonEnt(subDataSet) #该特征划分下的信息熵 infoGain = baseEntropy - newEntropy #信息增益 if ( infoGain > bestInfoGain ): bestInfoGain =infoGain bestFeature = i return bestFeature
MydDat,labels=createDataSet()print(chooseBestFeatureToSplit(MydDat))0
得知最好的划分特征为第一个特征,所以第一次以第一个特征进行询问。
5.构造决策树
给张图更好理解:

在构造树之前对于递归返回条件第二条:当询问完所有问题特征后,特征列表为空,则停止划分,选举属性标签出现频率最多的为叶节点。当遍历完所有特征时,要返回出现次数最多的分类名称。因此要构造选举函数:
def majorityCnt(classList): classCount={} for vote in classList: if vote not in classCount.key():classCount[vote] = 0 classCount[vote] +=1 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) return sortedClassCount[0][0] 之后递归构造决策树:
def createTree(dataSet,labels): classList = [example[-1] for example in dataSet] #保存标签 if classList.count(classList[0]) == len(classList): #如果类别完全相同则停止划分 return classList[0] #返回出现次数最多的标签 if len(dataSet[0]) == 1: #遍历完所有特征时返回出现次数最多的类别 return majorityCnt(classList) bestFeat = chooseBestFeatureToSplit(dataSet) bestFeatLabel = labels[bestFeat] myTree= {bestFeatLabel:{}} del(labels[bestFeat])#使用完该特征划掉#得到列表包含的所有属性值 featValues = [example[bestFeat] for example in dataSet] uniqueVals = set(featValues) for value in uniqueVals: subLabels = labels[:]#划分后特征组 myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels) return myTree 输出结果为:
{'no surfacing ': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
决策树构造完成。
总结
但仅仅是用数据字典表示还是不能很好的直观展示决策树,我将在下一篇文章写道如何使用Matplotlib注解绘制树形图以及决策树实例运用。
这里十分推荐大家参阅其他博客:
能补充很多关于决策树的优化和其他知识。
如果学到了或者用到了~~~求个赞吖~~
转载地址:https://jxnuxwt.blog.csdn.net/article/details/109022300 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
