本文共 4176 字,大约阅读时间需要 13 分钟。
实体(Entity)和值对象(ValueObject)组成聚合(Aggregate),再根据业务将多个聚合划定到同一限界上下文(Bounded Context),并在限界上下文内完成领域建模。
聚合只是单纯将一些共享父类、密切关联的对象聚集成一个对象树吗?
如果是这样,对于存在于这个树中的对象有没有一个实用的数目限制? 既然一个聚合可以引用另一个聚合,是否可以深度遍历下去,并且在此过程中修改对象? 聚合的不变条件和一致性边界究竟什么意思?1 聚合
- 实体一般对应业务对象,具有业务属性和业务行为
- 值对象主要是属性集合,描述实体的状态和特征
但都只是个体化对象,其行为表现出的是个体能力。
1.1 意义
领域模型内的实体和值对象好比个体,而能让实体和值对象协同工作的组织就是聚合,用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性。
聚合就是由业务和逻辑紧密关联的实体和值对象组合而成,聚合是数据修改和持久化的基本单元,每个聚合对应一个仓储,实现数据的持久化。
聚合有一个聚合根和上下文边界:
- 该边界根据业务单一职责和高内聚原则,定义了聚合内部应该包含哪些实体和值对象
- 聚合之间的边界是松耦合的
按这种方式设计出来的微服务自然就是高内聚、低耦合。
聚合属领域层,领域层包含多个聚合,共同实现核心业务逻辑。
聚合内实体以充血模型实现个体业务能力,以及业务逻辑的高内聚。跨多个实体的业务逻辑通过领域服务来实现,跨多个聚合的业务逻辑通过应用服务来实现。比如- 有的业务需同一聚合的A和B两个实体共同完成,就可将这段业务逻辑用领域服务实现
- 有的业务需聚合C和聚合D中的两个服务共同完成,使用应用服务来组合这俩服务
2 聚合根
为避免由于复杂数据模型缺少统一的业务规则控制,而导致聚合、实体之间数据不一致。
传统数据模型中的每一个实体都是同级对等,若任由实体无管控地调用数据修改,可能导致实体之间数据逻辑的不一致。而若使用锁则会增加代码复杂度,降低系统性能。
若把聚合比作组织,则聚合根就是该组织负责人。
聚合根也称为根实体,它不仅是实体,还是聚合的管理者。- 作为实体,拥有实体的属性和业务行为,实现自身的业务逻辑
- 作为聚合的管理者,在聚合内部负责协调实体和值对象按照固定业务规则协同完成共同的业务逻辑
在聚合间,它还是聚合对外的接口人,以聚合根ID关联的方式接受外部任务和请求,在上下文内实现聚合之间的业务协同。即聚合间通过聚合根ID关联引用,若需要访问其它聚合的实体,就要先访问聚合根,再导航到聚合内部实体,外部对象不能直接访问聚合内实体。
2.1 电商案例
电商里面比较典型的几个聚合根,比如:库存、商品、订单等。
以订单为例,订单在聚合里是聚合根,与订单关联的有订单明细和收货地址:
- 订单明细包括商品ID、商品名称、价格及数量等信息。由于订单明细是多个,它是一个集合,它被设计为实体,被订单引用
- 订单只有一个收货地址,收货地址的值源于你的个人中心维护的收货地址,收货地址只能被整体替换,所以设计为值对象
设计聚合
DDD领域建模通常采用事件风暴,采用用例分析、场景分析和用户旅程分析等方法,通过头脑风暴列出所有可能的业务行为和事件,然后找出产生这些行为的领域对象,并梳理领域对象之间的关系,找出聚合根,找出与聚合根业务紧密关联的实体和值对象,再将聚合根、实体和值对象组合,构建聚合。
聚合诞生的完整过程案例
保险的投保业务场景
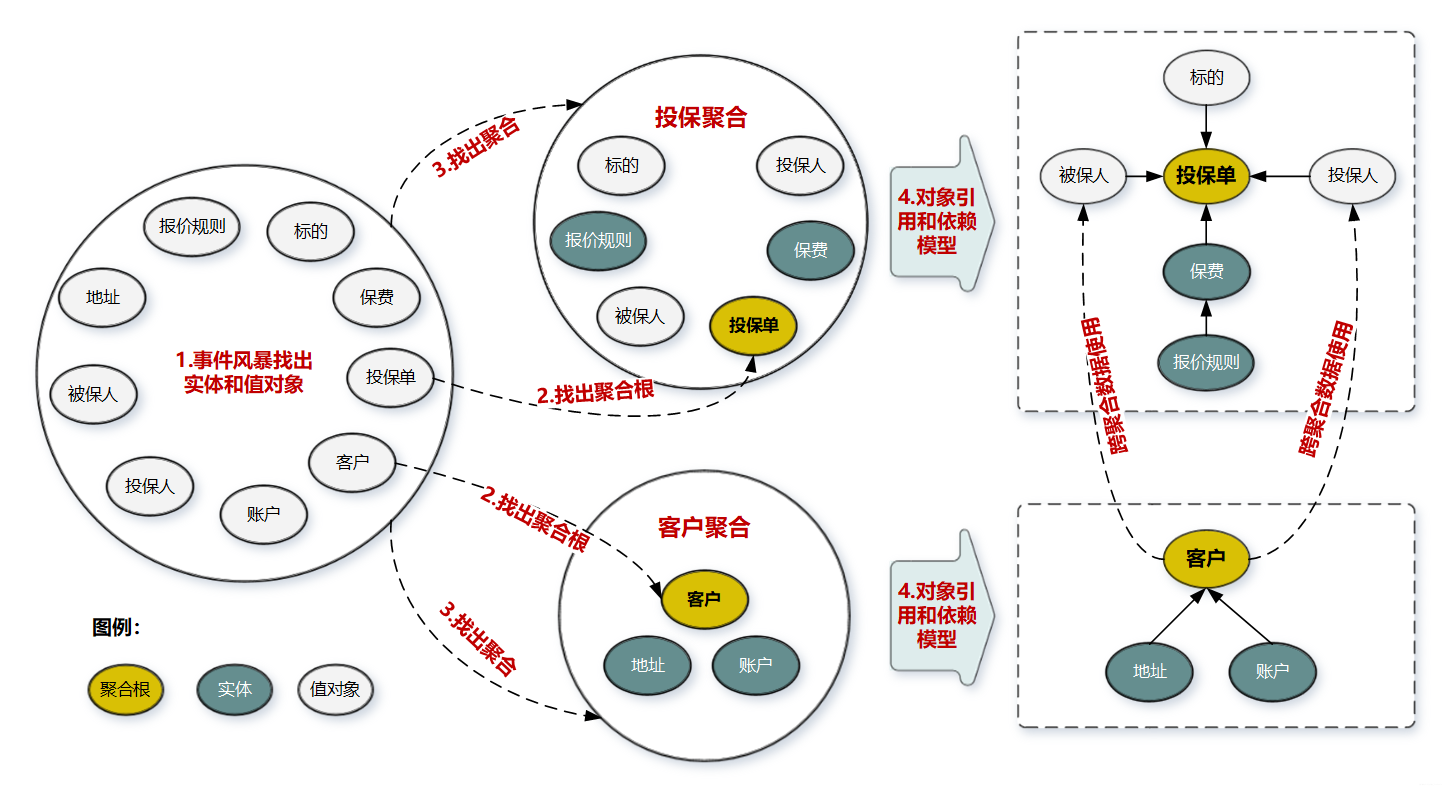
- 采用事件风暴,根据业务行为,梳理出在投保过程中发生这些行为的所有的实体和值对象,如投保单、标的、客户、被保人
- 从众多实体中选出适合作为对象管理者的根实体(聚合根)。判断一个实体是否是聚合根,可分析:是否有独立生命周期?是否有全局唯一ID?是否可创建或修改其它对象?是否有专门模块管这个实体。即投保单和客户聚合根
- 根据业务单一职责和高内聚原则,找出与聚合根关联的所有紧密依赖的实体和值对象。构建出 1 个包含聚合根(唯一)、多个实体和值对象的对象集合,这个集合就是聚合。即客户、投保聚合
- 在聚合内根据聚合根、实体和值对象的依赖关系,画出对象的引用和依赖模型。
投保人和被保人的数据,是通过关联客户ID从客户聚合中获取的,在投保聚合里它们是投保单的值对象,这些值对象的数据是客户的冗余数据,即使未来客户聚合的数据发生了变更,也不会影响投保单的值对象数据。
从图还可看出实体之间的引用关系,比如在投保聚合里投保单聚合根引用了报价单实体,报价单实体则引用了报价规则子实体。
- 多个聚合根据业务语义和上下文一起划分到同一个限界上下文内。
设计原则
在一致性边界内建模真正的不变条件
要从限界上下文中发现聚合,我们需要了解模型中真正的不变条件。这样才能决定什么样的对象可以放在一个聚合。
不变条件表示一个业务规则,该规则应该总是保持一致。存在多种类型的一致性:
- 事务一致性 要求立即性和原子性
- 最终一致性
在讨论不变条件时,我们讨论的是事务一致性。我们可能有以下不变条件:
c = a + b
当a等于2, b等于3时,c必定等于5。根据这条规则,如果c不为5,那么我们便违背了系统的不变条件。为了保持c的一致性,我们应该在模型中为这些属性设计了 一个边界:
AggregateTypel ( int a; int b; int c; operations ...
聚合边界之内的所有内容组成了一套不变的业务规则,任何操作都不能违背这些规则。边界之外的任何东西与该聚合都是不相关的。因此,聚合表达 了与事务一致性边界相同的意思(在该例中,AggregateTypel拥有3个int类型的属 性,任何聚合都可拥有不同类型的属性)。
聚合用来封装真正的不变性,而非简单地组合对象。聚合内有一套不变的业务规则,各实体和值对象按统一业务规则运行以实现对象数据的一致性,边界之外的任何东西都与该聚合无关,这就是聚合能实现高内聚的原因。
设计小聚合
如果聚合设计过大,聚合会因为包含过多实体,导致实体间管理复杂,高频操作时会出现并发冲突或数据库锁,即便我们可以保证事务的成功执行,它依然有可能限制系统的性能和可伸缩性。
小聚合设计则可降低由于业务过大导致聚合重构的可能性,让领域模型更能适应业务变化。
那么,这里的“小”是什么意思呢?最极端的情况是,一个聚合只拥有全局标识和单个属性,当然,这并不是推荐做法(除非这正是需求所在)。好的做法是使用根实体(Root Entity)来表示聚合,其中只包含最小数量的属性或值类型属性。这里的“最小数量”表示所需的最小属性集合,不多也不少。
哪些属性是所需的呢?简单的答案是:那些必须与其他属性保持一致。比如,一个Product拥有name和 description属性,它们需要保持一致,将它们放在两个不同的聚合中显然无意义。当我们修改name,很可能也会同时修改 description,如果你只修改其一,很可能是在修改语法上的错误或使description能够更匹配name。
在聚合中,若认为有些被包含的部分应该建模成实体,怎么办?首先思考该部分是否会随着时间而改变或该部分是否能被全部替换。若可被全部替换,请将其建模成值对象,而非实体。很多情况下建模成实体的概念都可重构成值对象。优先选用值对象并非意味着聚合就是不变的,因为当值对象属性被替换成其他值时,根实体也就随之改变。
将聚合的内部建模成值对象有很多好处。据所选用持久化机制,值 对象可随根实体而序列化,而实体则需单独存储区域予以跟踪。
实体还会带来某些不必要操作,比如,在使用Hibernate时,需对多表联合查询。对单表读取快得多,而使用值对象也更方便安全。由于值对象不变,测试也相对简单。小聚合不仅有性能和可伸缩性上的好处,它还有助于事务成功执行,即可减少事务提交冲突。系统的可用性也得到了增强。在你的领域中,迫使你设计大聚合的不变条件约束并不多。当你遇到这样的情况时,可以考虑添加实 体或者是集合,但无论如何,我们都应该将聚合设计得尽量小。
通过唯一标识引用其它聚合
聚合之间是通过关联外部聚合根ID的方式引用,而不是直接对象引用的方式。外部聚合的对象放在聚合边界内管理,容易导致聚合的边界不清晰,也会增加聚合之间的耦合度。
在边界之外使用最终一致性
聚合内数据强一致性,而聚合间数据最终一致性。
在一次事务中,最多只能更改一个聚合的状态。如果一次业务操作涉及多个聚合状态的更改,应采用领域事件的方式异步修改相关的聚合,实现聚合间解耦。
在不持有对象引用的情况下,不能修改其他聚合,因此我们可以避免在同一个事务中修改多个聚合。但这种方式的缺点在于限制性太强,因为在领域模型中我们总需要对象之间的关联关系来完成一些任务。
那么,此时我们应该怎么办呢?通过应用层实现跨聚合的服务调用
为实现微服务内聚合之间的解耦,以及未来以聚合为单位的微服务组合和拆分,应避免跨聚合的领域服务调用和跨聚合的数据库表关联。
总结
-
聚合的特点
高内聚、低耦合,它是领域模型中最底层的边界,可作为拆分微服务的最小单位,但不推荐过度拆分。在对性能有极致要求的场景中,聚合可独立作为一个微服务,以满足版本的高频发布和弹性伸缩要求。 一个微服务可包含多个聚合,聚合之间的边界是微服务内天然的逻辑边界。有了该逻辑边界,在微服务架构演进时就可以聚合为单位进行拆分和组合。 -
聚合根的特点
聚合根是实体,有实体的特点,具有全局唯一标识,有独立的生命周期。一个聚合只有一个聚合根,聚合根在聚合内对实体和值对象采用直接对象引用的方式进行组织和协调,聚合根与聚合根之间通过ID关联的方式实现聚合之间的协同。 -
实体的特点
有ID标识,通过ID判断相等性,ID在聚合内唯一即可。状态可变,它依附于聚合根,其生命周期由聚合根管理。实体一般会持久化,但与数据库持久化对象不一定是一对一的关系。实体可引用聚合内的聚合根、实体和值对象。 -
值对象的特点
无ID,不可变,无生命周期,用完即扔。值对象之间通过属性值判断相等性。它的核心本质是值,是一组概念完整的属性组成的集合,用于描述实体的状态和特征。值对象尽量只引用值对象。
参考
- 《实现领域驱动设计》
- 聚合和聚合根:怎样设计聚合?
转载地址:https://javaedge.blog.csdn.net/article/details/108922408 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
