本文共 30733 字,大约阅读时间需要 102 分钟。
文章目录
一、kafka介绍
1. kafka基本认识
官网翻译:
介绍 Apache Kafka® is a distributed streaming platform. What exactly does that mean? Apache Kafka®是一个分布式流平台。这到底是什么意思?流平台有三个关键功能:
- 发布和订阅记录流,类似于消息队列或企业消息系统。
- 以容错、持久的方式存储记录流。
- 处理流记录,当他们发生时。
卡夫卡通常用于两大类应用:
- 构建实时流数据管道,在系统或应用程序之间可靠地获取数据
- 构建对数据流进行转换或响应的实时流应用程序
总结:kafka 既从上游系统接收数据,也会给下游系统输送数据:既提供消息的流转服务,也用于数据的持久化存储。承接上下游子系统 。
1.1 kafka 4个核心API
[推荐]Kafka的API那么多,到底该怎么选?
参考URL: https://baijiahao.baidu.com/s?id=1617641679231240954&wfr=spider&for=pc-
Producer API: 支持应用将数据流发送到Kafka集群的主题。
应用程序直接生成数据(如点击流、日志、物联网); -
Consumer API: API支持应用从Kafka集群的主题中读取数据流。
Kafka Consumer API: 读取流并以此为依据实时执行动作(如发送电子邮件); -
Streams API / KSQL: API支持数据流从输入主题转化到输出主题。
流API允许应用程序充当流处理器,使用来自一个或多个主题的输入流,并将输出流生成到一个或多个输出主题,从而有效地将输入流转换为输出流。
Kafka Streams API / KSQL :从 Kafka 消费并把生成的数据传回 Kafka 的应用程序,也称为流处理。如果你认为你只需要编写类似 SQL 的实时任务,则可以使用 KSQL;如果你认为你需要编写复杂的任务逻辑,则可以使用 Kafka Streams API。
- Connector API: 连接器API允许构建和运行可重用的生产者或消费者,将Kafka主题连接到现有的应用程序或数据系统。例如,关系数据库的连接器可能捕获表的每个更改。
- Kafka Connect Source API: 应用程序连接我们无法控制的数据存储和 Kafka(如 CDC、Postgres、MongoDB、Twitter、REST API);
**Kafka Connect Source API 是一个构建在 Producer API 之上的完整框架。**它主要是为了让开发人员能够有一个更好的 API:1)用于 Producer 任务分发以进行并行处理,2)提供 Producer 恢复的简单机制。最后一个好处是提供了各种各样的连接器,你现在可以利用它们从大多数源传输数据,而无需编写一行代码。
- Kafka Connect Sink API: 读取流,并将其保存到目标存储(如 Kafka 到 S3、Kafka 到 HDFS、Kafka 到 PostgreSQL、Kafka 到 MongoDB 等)。
与 Kafka Connect Source API 类似,Kafka Connect Sink API 允许你利用现有的 Kafka 连接器生态系统来执行流 ETL,而无需编写一行代码。Kafka Connect Sink API 是构建在 Consumer API 之上的,但是看起来和它没有什么不同。
如果你想要进入流处理的世界,即实时读取来自 Kafka 的数据,并在处理之后将其写回 Kafka,那么,如果你把 Kafka Consumer API 和 Kafka Producer API 链接在一起使用的话,你很可能陷入麻烦之中。值得庆幸的是,Kafka 项目现在提供了 Kafka Streams API (可用于 Java 和 Scala),让你可以编写高级 DSL(类似于函数式编程 / Apache Spark 类型的程序)或低级 API(和 Apache Storm 更为相似)。使用 Kafka Streams API 确实需要编写代码,但完全隐藏了维护生产者和消费者的复杂性,使你可以专注于流处理器的逻辑。它还具有连接、聚合和只执行一次处理的特性。
总结: Kafka Connect是一种用于Kafka和其他数据系统之间进行数据传输的工具。Kafka connect有两个概念,一个source,另一个是sink。source是把数据从一个系统拷贝到kafka里,sink是从kafka拷贝到另一个系统里。
在Kafka中,客户机和服务器之间的通信是通过一个简单、高性能、语言无关的TCP协议来完成的。此协议已版本化,并保持与旧版本的向后兼容性。我们为卡夫卡提供Java客户端,但客户端可以用多种语言提供。
2. 各版本变化说明
| 版 本 | 功能变化 | 说 明 |
|---|---|---|
| 0.10.0.x | 增加了 Kafka Streams 组件 | 自 0.10.0 版本开始, K且fka 正式转型成为分布式流式处理平台 |
| 1.0.0 | 优化了 Kafka Streams AP!以及各种监控指标的完善 | 自 l .0.0 版本开始, Kafka 正式进入到 1.0 稳定版本 |
2.1 不同 Kafka 版本之间服务器和客户端的适配性
kafka-broker-api-versions 脚本
这个脚本的主要目的是验证不同 Kafka 版本之间服务器和客户端的适配性。如果你想了解你的客户端版本与服务器端版本的兼容性,那么最好使用这个命令来检验一下。值得注意的是,在 0.10.2.0 之前,Kafka 是单向兼容的,即高版本的 Broker 能够处理低版本 Client 发送的请求,反过来则不行。自 0.10.2.0 版本开始,Kafka 正式支持双向兼容,也就是说,低版本的 Broker 也能处理高版本 Client 的请求了
二、kafka入门
1. kafka基本术语概念
- topic topic 只是一个逻辑概念,代表了一类消息,也可以认为是消息被发送到 的地方。通常我们可以使用 topic 来区分实际业务,比如业务 A 使用一个 topic,业务 B 使用另外一个 topic 。
- partition Kafka 并不是 topicmessage 的两级结构,而是采用了 topic-partition-message 的三级结构来分散负载。从本质上说 ,每个 Kafka topic 都由若干个 partition 组成。
Kafka 的 partition 是不可修改的有序消息序列,也可以说是
有序的消息日志。每个 partition 有自己专属的 partition 号,通常是从 0 开始的。用户对partition 唯一能做的操作就是在消息序列的尾部追加写入消息。 partition 上的每条消息都会被分配一个唯一的序列号一一按照 Kafka 的术语来讲,该序列号被称为位移( offset ) 该位移值是从 0 开始顺序递增的整数。位移信息可以唯一定位到某 partition 下的一条消息。Kafka 的 partition 没有太多的业务含义,它的引入就是单纯地为了提升系统的吞吐量,因此在创建 Kafka topic 的时候可以根据集群实际配置设置具体的partition 数, 实现整体性能的最大化 。
- offset topic partition 下的每条消息都被分配一个位移值。实际上 , Kafka 消费者端也有位移( offset)的概念,但一定要注意这两个 offset 属于不同的概念。
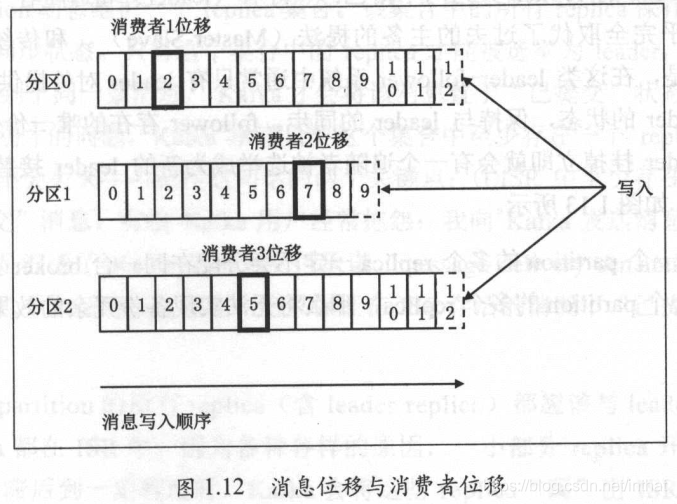 * replica partition 是有序消息日志,那么一定不能只保存这一份日志,否则一旦保 存 partition 的 Kafka 服务器挂掉了,其上保存的消息也就都丢失了。分布式系统必然要实现高可靠性,而目前实现的主要途径还是依靠冗余机制一一简单地说,就是备份多份日志 。 这些备份日志在 Kafka 中被称为副本( replica ),它们存在的唯一目的就是防止数据丢失
* replica partition 是有序消息日志,那么一定不能只保存这一份日志,否则一旦保 存 partition 的 Kafka 服务器挂掉了,其上保存的消息也就都丢失了。分布式系统必然要实现高可靠性,而目前实现的主要途径还是依靠冗余机制一一简单地说,就是备份多份日志 。 这些备份日志在 Kafka 中被称为副本( replica ),它们存在的唯一目的就是防止数据丢失 - leader 和 follower
Kafka 的 replica 分为两个角色:领导者( leader)和追随者( follower ) 。 如今
这种角色设定几乎完全取代了过去的主备的提法( Master-Slave )。和传统主备系统(比如MySQL )不同的是,在这类 leader-follower 系统中通常只有 leader 对外提供服务, fo llower 只是被动地追随 leader 的状态,保持与 leader 的同步。 follower 存在的唯一价值就是充当 leader的候补:一旦 leader 挂掉立即就会有一个追随者被选举成为新的 leader 接替它的工作。 Kafka就是这样的设计**Kafka 保证同 一个 partition 的多个 replica 一定不会分配在同一台 broker 上 。**毕竟如果同一个 broker 上有同一个 partition 的多个 replica,那么将无法实现备份冗余的效果。
假设副本因子是3,Kafka会为每个分区创建3个副本并将它们放置在不同的broker上。
2. kafka消息设计
Kafka 在消息设计时特意避开了繁重的 Java 堆上内存分配,直接使用紧凑二进制字节
数组 ByteBuffer 而不是独立的对象,因此我们至少能够访问多一倍的可用内存。如果使用 ByteBuffer 来保存同样的消息,只需要 24 字节,比起纯 Java 堆
的实现减少了 40%的空间占用,好处不言而喻。这种设计的好处还包括加入了扩展的可能性。 同时,大量使用页缓存而非堆内存还有一个好处一一当出现 Kafka broker 进程崩溃时,堆内存上的数据也一并消失,但页缓存的数据依然存在。下次 Kafka broker 重启后可以继续提供服务,不需要再单独“热”缓存了。2.1 消息压缩
Kafka 是如何压缩消息的呢?要弄清楚这个问题,就要从 Kafka 的消息格式说起了。目前 Kafka 共有两大类消息格式,社区分别称之为 V1 版本和 V2 版本。V2 版本是 Kafka 0.11.0.0 中正式引入的。
V2 版本的做法是对整个消息集合进行压缩。
在 Kafka 中,压缩可能发生在两个地方:生产者端和 Broker 端。生产者程序中配置 compression.type 参数即表示启用指定类型的压缩算法。
Producer 启动后生产的每个消息集合都是经 GZIP 压缩过的,故而能很好地节省网络传输带宽以及 Kafka Broker 端的磁盘占用。
在一个生产环境中,Kafka 集群中同时保存多种版本的消息格式(V1版本、V2 版本)非常常见。为了兼容老版本的格式,Broker 端会对新版本消息执行向老版本格式的转换。这个过程中会涉及消息的解压缩和重新压缩。一般情况下这种消息格式转换对性能是有很大影响的,除了这里的压缩之外,它还让 Kafka 丧失了引以为豪的 Zero Copy 特性。
在 Kafka 2.1.0 版本之前,Kafka 支持 3 种压缩算法:GZIP、Snappy 和 LZ4。从 2.1.0 开始,Kafka 正式支持 Zstandard 算法(简写为 zstd)。它是 Facebook 开源的一个压缩算法,能够提供超高的压缩比(compression ratio)。
三、kafka connect
官网参考: https://docs.confluent.io/2.0.0/connect/connectors.html
[推荐]基于Kafka Connect的应用实践——打造实时数据集成平台 参考URL: https://cloud.tencent.com/developer/news/217133 kafka connect 参考URL: https://blog.csdn.net/helihongzhizhuo/article/details/80335931 Kafka Connect 概念 参考URL: https://www.jianshu.com/p/fae25cc63997Kafka是一个使用越来越广的消息系统,尤其是在大数据开发中(实时数据处理和分析)。为何集成其他系统和解耦应用,经常使用Producer来发送消息到Broker,并使用Consumer来消费Broker中的消息。Kafka Connect是到0.9版本才提供的并极大的简化了其他系统与Kafka的集成。Kafka Connect运用用户快速定义并实现各种Connector(File,Jdbc,Hdfs等),这些功能让大批量数据导入/导出Kafka很方便。
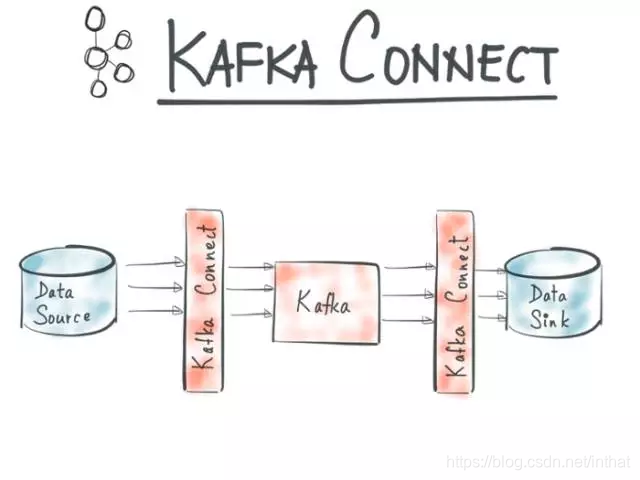
Kafka Connect用于在Kafka和Hadoop等其他数据系统之间移动数据。
Kafka客户机,用于从您自己的应用程序中读取和写入来自/到Kafka的数据。主要的概念:
-
Connectors:通过管理task来协调数据流的高级抽象
Kafka Connect中的connector定义了数据应该从哪里复制到哪里。connector实例是一种逻辑作业,负责管理Kafka与另一个系统之间的数据复制。 -
Tasks:如何将数据复制到Kafka或从Kafka复制数据的实现
Task是Connect数据模型中的主要处理数据的角色。每个connector实例协调一组实际复制数据的task。通过允许connector将单个作业分解为多个task,Kafka Connect提供了内置的对并行性和可伸缩数据复制的支持,只需很少的配置。这些任务没有存储任何状态。任务状态存储在Kafka中的特殊主题config.storage.topic和status.storage.topic中。因此,可以在任何时候启动、停止或重新启动任务,以提供弹性的、可伸缩的数据管道。 -
Workers:执行Connector和Task的运行进程
- Standalone Workers Standalone模式是最简单的模式,用单一进程负责执行所有connector和task。
- Distributed Workers 分布式模式为Kafka Connect提供了可扩展性和自动容错能力。在分布式模式下,你可以使用相同的组启动许多worker进程。它们自动协调以跨所有可用的worker调度connector和task的执行。如果你添加一个worker、关闭一个worker或某个worker意外失败,那么其余的worker将检测到这一点,并自动协调,在可用的worker集重新分发connector和task。
-
Converters: 用于在Connect和外部系统发送或接收数据之间转换数据的代码
在向Kafka写入或从Kafka读取数据时,Converter是使Kafka Connect支持特定数据格式所必需的。task使用转换器将数据格式从字节更改为连接内部数据格式,反之亦然。 默认提供以下converters: AvroConverter(建议):与Schema Registry一起使用 JsonConverter:适合结构数据 StringConverter:简单的字符串格式 ByteArrayConverter:提供不进行转换的“传递”选项 -
Transforms:更改由连接器生成或发送到连接器的每个消息的简单逻辑
对单个消息进行简单且轻量的修改。这对于小数据的调整和事件路由十分方便,且可以在connector配置中将多个转换链接在一起。然而,应用于多个消息的**更复杂的转换最好使用KSQL和Kafka Stream实现。**转换是一个简单的函数,输入一条记录,并输出一条修改过的记录。Kafka Connect提供许多转换,它们都执行简单但有用的修改。可以使用自己的逻辑定制实现转换接口,将它们打包为Kafka Connect插件,将它们与connector一起使用。 当转换与source connector一起使用时,Kafka Connect通过第一个转换传递connector生成的每条源记录,第一个转换对其进行修改并输出一个新的源记录。将更新后的源记录传递到链中的下一个转换,该转换再生成一个新的修改后的源记录。最后更新的源记录会被转换为二进制格式写入到kafka。 转换也可以与sink connector一起使用。
1. Kafka Connect测试
[写的很好-强烈推荐]深入理解 Kafka Connect:转换器和序列化
参考URL: https://blog.csdn.net/D55dffdh/article/details/84929263 Kafka Connect 实现MySQL增量同步 参考URL: https://www.jianshu.com/p/46b6fa53cae41.1 Kafka Connect jdbc
JDBC source and sink connectors允许您在关系数据库和Kafka之间交换数据。JDBC源连接器允许您从任何带有JDBC驱动程序的关系数据库中导入数据到Kafka主题中。
通过使用JDBC,这个连接器可以支持各种各样的数据库,而不需要为每个数据库定制代码。通过定期执行SQL查询并为结果集中的每一行创建输出记录来加载数据。
默认情况下,数据库中的所有表都会被复制,每个表都有自己的输出主题。对数据库进行监视,以查找新表或已删除表,并自动进行调整。
从表中复制数据时,连接器只能通过指定应使用哪些列来检测新的或修改过的数据来加载新的或修改过的行。
JDBC接收器连接器允许您使用JDBC驱动程序将数据从Kafka主题导出到任何关系数据库。通过使用JDBC,这个连接器可以支持各种各样的数据库,而不需要为每个数据库都提供专用的连接器。连接器根据主题订阅从Kafka轮询数据以写入数据库。
1.1.1 Kafka Connect jdbc (mysql 根据id新增记录 写到 文件中 demo)
去官网下载JDBC的插件,官网地址:https://www.confluent.io/connector/kafka-connect-jdbc/
- connect的配置文件在config目录下,connect-distributed.properties connect-standalone.properties,前者是多节点的配置文件,后者是单节点的配置文件。
编辑config/connect-standalone.properties
bootstrap.servers 这里是broker的地址; plugin.path 这是插件的目录-
添加插件
去官网下载JDBC的插件,官网地址:https://www.confluent.io/connector/kafka-connect-jdbc/ 下载下来应该是个ZIP包,解压到插件目录 JDBC包默认只支持sqlite和PG,所以需要添加mysql-connector-java-x.x.x.jar驱动到 confluentinc-kafka-connect-jdbc-5.3.0/lib 目录下 -
启动Connector http服务
/bin/connect-standalone.sh -daemon ./config/connect-standalone.properties 注意: 这里可以把source connet配置文件和sink connect配置跟在这条命令后面,这条命名讲启动connect http服务并且新建你的这两个connect。 也可以这里不跟。启动connnect http服务后使用restful api接口创建源连接和sink连接。
创建具体的source connect 和sink connect
source-mysql.properties
name=mysql-sourceconnector.class=io.confluent.connect.jdbc.JdbcSourceConnectortasks.max=1connection.url=jdbc:mysql://localhost:3306/A?user=***&password=***# incrementing 自增mode=incrementing# 自增字段 pidincrementing.column.name=pid# 白名单表 persontable.whitelist=person# topic前缀 topic.prefix:mysql.,表示写到kafka的主题为mysql-表名 (它会自动创建该主题)topic.prefix=mysql-
post请求 http://kafka服务IP:8083/connectors
{"name":"mysql-source","config":{"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector","connection.url":"jdbc:mysql://mksql数据库ip:3306/test?user=root&password=root","tasks.max":1,"table.whitelist":"t_task_log","incrementing.column.name": "id","catalog.pattern" : "test","mode":"incrementing","topic.prefix": "mysql-"}} 文件sink connect post请求内容,
{"name":"local-file-sink","config":{"connector.class":"FileStreamSink","tasks.max": 1,"file" : "/home/kafka/test.sink.txt","topics":"mysql-t_task_log"}} - 根据上面的connect,从mysql读取,根据id读取 增量记录,写入到文件中。
2. 通过rest api管理connector
因为kafka connect的意图是以服务的方式去运行,所以它提供了REST API去管理connectors,默认的端口是8083,你也可以在启动kafka connect之前在配置文件中添加rest.port配置。
GET /connectors – 返回所有正在运行的connector名
POST /connectors – 新建一个connector; 请求体必须是json格式并且需要包含name字段和config字段,name是connector的名字,config是json格式,必须包含你的connector的配置信息。 GET /connectors/{name} – 获取指定connetor的信息 GET /connectors/{name}/config – 获取指定connector的配置信息 PUT /connectors/{name}/config – 更新指定connector的配置信息 GET /connectors/{name}/status – 获取指定connector的状态,包括它是否在运行、停止、或者失败,如果发生错误,还会列出错误的具体信息。 GET /connectors/{name}/tasks – 获取指定connector正在运行的task。 GET /connectors/{name}/tasks/{taskid}/status – 获取指定connector的task的状态信息 PUT /connectors/{name}/pause – 暂停connector和它的task,停止数据处理知道它被恢复。 PUT /connectors/{name}/resume – 恢复一个被暂停的connector POST /connectors/{name}/restart – 重启一个connector,尤其是在一个connector运行失败的情况下比较常用 POST /connectors/{name}/tasks/{taskId}/restart – 重启一个task,一般是因为它运行失败才这样做。 DELETE /connectors/{name} – 删除一个connector,停止它的所有task并删除配置。四、 Kafka Streams
Kafka Streams
参考URL: https://www.orchome.com/335随着 Kafka 的不断演进, Kafka 开发团队日益发现经
Kafka 交由下游数据处理平台做的事情 Kafka 自己也可以做,因此在 Kafka 0.10.0.0 版本正式推出了 Kafka Streams,即流式处理组件 。自 此 Kafka 正式成为了 一个流式处理框架,而不仅仅是消息引擎了。Kafka Streams是一个客户端程序库,用于处理和分析存储在Kafka中的数据,并将得到的数据写回Kafka或发送到外部系统。Kafka Stream基于一个重要的流处理概念。
Kafka Streams 擅长的是从 Kafka topic 中获取输入数据,然后对这些数据进行转换,最后发送到目标 topic 中。
应用场景总结: 客户端通过订阅Kafka收集的数据,然后由Kafka Streams程序可以简单的进行实时数据的分析。
1. 什么是流式计算
一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算。
批量处理模型中,一般先有全量数据集,然后定义计算逻辑,并将计算应用于全量数据。特点是全量计算,并且计算结果一次性全量输出。
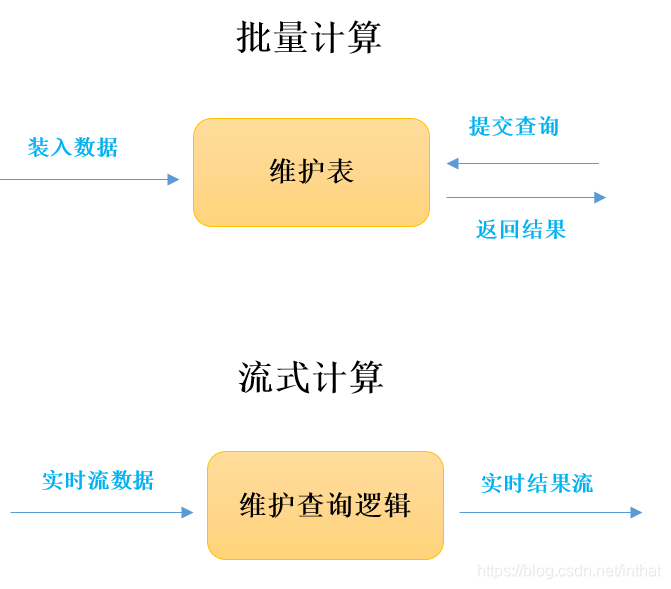 (1) 与批量计算那样慢慢积累数据不同,流式计算将大量数据平摊到每个时间点上,连续地进行小批量的进行传输,数据持续流动,计算完之后就丢弃。
(1) 与批量计算那样慢慢积累数据不同,流式计算将大量数据平摊到每个时间点上,连续地进行小批量的进行传输,数据持续流动,计算完之后就丢弃。 (2) 批量计算是维护一张表,对表进行实施各种计算逻辑。流式计算相反,是必须先定义好计算逻辑,提交到流失计算系统,这个计算作业逻辑在整个运行期间是不可更改的。
(3) 计算结果上,批量计算对全部数据进行计算后传输结果,流式计算是每次小批量计算后,结果可以立刻投递到在线系统,做到实时化展现。
2. 关键概念
流是Kafka Stream提出的最重要的抽象概念:**它表示一个无限的,不断更新的数据集。**流是一个有序的,可重放(反复的使用),不可变的容错序列,数据记录的格式是键值对(key-value)。
一个流处理器(stream processor)是处理拓扑(processor topologies)中的一个节点,它代表了拓扑中的处理步骤。一个流处理器从它所在的拓扑上游接受数据,通过Kafka Streams提供的流处理的基本方法,如map()、filter()、join()以及聚合等方法,对数据进行处理,然后将处理后的一个或多个输出结构发送给下游处理器。一个拓扑中的数据处理器当中有Source处理器和Sink处理器两个特殊的流处理器。
- Source处理器(Source Processor):**在一个处理拓扑中该处理器没有任何上游处理器。**该处理器从Kafka的一个或多个主题消费数据作为处理拓扑的输入流,将该输入流发送到下游处理器。
- Sink处理器:**sink处理器是一个没有下游流处理器的特殊类型的流处理器。**它接收上游流处理器的消息发送到一个指定的Kafka主题。
总结:1. 一个流处理应用,用Kafka Streams开发,定义了经过若干个处理拓扑(processor topologies)的计算逻辑,每个处理拓扑是一个通过流(线,edge)连接到流处理实例(点,node)的图。
2. 一个流处理实例(processor)是一个处理拓扑的节点;其含义是,通过从拓扑图中它的上游处理节点每次接收一条输入记录,执行一步流数据的变换,可能是请求操作流数据,也有可能随后生产若干条记录给到下游处理实例。 3. Kafka Streams 包含了ConsumerAPI 和ProducerAPI的功能,并且增强了功能,就是流处理的功能。3. streams api官方描述
文档 https://docs.confluent.io/current/streams-ksql.html
官方示例的代码: https://github.com/confluentinc/kafka-streams-examples https://github.com/apache/kafka/blob/2.3/streams/examples/src/main/java/org/apache/kafka/streams/examplesKafka Streams API允许您创建支持核心业务的实时应用程序。它是处理存储在Kafka中的数据的最简单但最强大的技术。它建立在流处理的重要概念之上。
A key motivation of the Kafka Streams API is to bring stream processing out of the Big Data niche into the world of mainstream application development, and to radically improve the developer and operations experience by making stream processing simple and easy. Using the Kafka Streams API you can implement standard Java applications to solve your stream processing needs – whether at small or at large scale – and then run these applications on client machines at the perimeter of your Kafka cluster. Your applications are fully elastic: you can run one or more instances of your application, and they will automatically discover each other and collaboratively process the data.
Kafka Streams API的一个关键动机是将流处理从大数据领域带到主流应用程序开发的世界中,并通过简化流处理从根本上改善开发人员和操作经验。使用卡夫卡流API,您可以实现标准的Java应用程序来解决流处理需求——无论是小规模的还是大规模的,然后在客户机上运行这些应用程序在您的卡夫卡集群的外围。您的应用程序是完全弹性的:您可以运行应用程序的一个或多个实例,它们将自动发现彼此并协作处理数据。
总结: Kafka Streams API的这种轻量级和集成的方法——“构建应用程序,而不是基础设施!”–与其他流处理工具形成鲜明对比。 它是个java 库,可以用于流处理。
-
轻量
No processing cluster required 不需要处理集群 No external dependencies other than Kafka 没有额外的依赖除了kafak -
完全集成;
- 100%兼容kafka0.11.0和1.0.0
- 易于集成到现有应用程序和微服务中
- 与数据库集成: 通过Kafka Connect执行的持续变更数据捕获
- 实时
- 毫秒处理延迟
- 一次处理一条记录(非一次处理小批量)
- 无缝处理延迟到达和无序数据
- 高吞吐
3.1 Streams API demo测试步骤
This quick start follows these steps:
- Start a Kafka cluster on a single machine. 后台启动:
bin/kafka-server-start.sh -daemon config/server.properties
- Write example input data to a Kafka topic, using the so-called console producer included in Kafka. 1)使用kafka自带脚本,执行如下命令创建一个输入主题、一个输出主题。
# Create the input topic ./bin/kafka-topics.sh --create \ --zookeeper localhost:2181 \ --replication-factor 1 \ --partitions 1 \ --topic streams-plaintext-input# Create the output topic ./bin/kafka-topics.sh --create \ --zookeeper localhost:2181 \ --replication-factor 1 \ --partitions 1 \ --topic streams-wordcount-output
2)写要发的消息到文件 /tmp/file-input.txt
echo -e "all streams lead to kafka\nhello kafka streams\njoin kafka summit" > /tmp/file-input.txt
3) 发送该消息到输入主题
cat /tmp/file-input.txt | ./bin/kafka-console-producer.sh --broker-list kafka服务IP:9092 --topic streams-plaintext-input
生产者程序kafka-console-producer.sh逐行从stdin读取数据,并将每行作为单独的Kafka消息发布到主题流纯文本输入,其中消息键为空,消息值为相应的行,例如所有流都指向Kafka,编码为字符串。
- Process the input data with a Java application that uses the Kafka Streams library. Here, we will leverage a demo application included in Kafka called WordCount.
现在我们已经生成了一些输入数据,我们可以运行基于Java的第一个基于卡夫卡流的应用程序。
我们将运行包含在Kafka中的wordcount演示应用程序。它实现了wordcount算法,该算法根据输入文本计算单词出现直方图。**但是,与您以前看到的对有限的有界数据进行操作的其他wordcount示例不同,wordcount演示应用程序的行为略有不同,因为它设计用于对无限的、无边界的输入数据流进行操作。与有界变量类似,它是一种有状态的算法,用于跟踪和更新字数。但是,由于它必须假定潜在的无边界输入数据,因此它将定期输出其当前状态和结果,同时继续处理更多的数据,因为它不知道何时处理了“全部”输入数据。**这是在无界数据流上操作的一类算法和批处理算法(如Hadoop MapReduce)之间的典型区别。一旦我们稍后检查实际输出数据,就更容易理解这种差异
运行官方demo代码
\kafka-streams-examples-5.3.0-post\src\main\java\io\confluent\examples\streams\WordCountLambdaExample.javawordcount demo应用程序将从输入主题流中读取纯文本输入,对输入数据执行wordcount算法的计算,并将其当前结果连续写入输出主题。
- Inspect the output data of the application, using the so-called console consumer included in Kafka. 使用控制台消费者程序查看,输出主题数据。
./bin/kafka-console-consumer.sh --bootstrap-server kafka服务ip:9092 \ --topic streams-wordcount-output \ --from-beginning \ --formatter kafka.tools.DefaultMessageFormatter \ --property print.key=true \ --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \ --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
- Stop the Kafka cluster.
3.2 KafkaStreams类 配置常用参数props说明
KafkaStreams globalStreams = new KafkaStreams(builder.build(), props);
- StreamsConfig.BOOTSTRAP_SERVERS_CONFIG 这个参数用于高速kafka生产者怎么连接kafka
bootstrap.serversvalue. Example:127.0.0.1:9092. - public static final String STATE_DIR_CONFIG = “state.dir”; private static final String STATE_DIR_DOC = “Directory location for state store.”;
3.3 Stream API 使用总结
流 API 提供一个主题到另一个主题的转换。 也就是从一个输入主题到一个输出主题的流数据转换。
它的主要类就是 : Class KafkaStreams
可以通过使用TopologyBuilder来定义一个处理器的DAG拓扑结构,或者使用提供高级DSL来定义转换的KStreamBuilder来指定计算逻辑。
一个KafkaStreams可以包含一个或多个在configs中指定的线程,用于处理工作。可以通过相同的 APP ID 来协调其它的实例,不管是在同一进程中,还是在这台机器上的其他进程上,还是在远程机器上,都可以作为一个流处理 APP。这些实例将根据输入主题分区的分配来划分工作,从而使所有分区都被消耗。如果添加或失败实例,所有(剩余)实例将重新平衡分区分配,以平衡处理负载,并确保所有输入主题分区都被处理。
在内部,一个流实例包含了一个正常的 kafkaProducer 和 kafkaConsumer 实例,他们用做读输入和写输出。3.4 KStream和KTable
KStream和KTable是Kafka Streams里内建的两个最重要的抽象,分别对应数据流和数据库。
KStream和KTable相应地都提供了一系列转换操作。每个操作可产生一或多个KStream和KTable对象,可被翻译成一或多个相连的处理器。KStream
数据流(data stream),即是一段顺序的,可以无限长,不断更新的数据集。 数据流中比较常记录的是事件(stream of events),这些事件可以是一次鼠标点击(click),一次交易,或是传感器记录的位置数据。 KStream负责抽象的,就是数据流。与Kafka自身topic中的数据一样,类似日志,每一次操作都是向其中插入(insert)新数据。 KStream的构建方法: builder.stream()KTable
传统数据库,包含了各种存储了大量状态(state)的表格。KTable负责抽象的,就是表状数据。每一次操作,都是更新插入(upsert)。
KTable的构建方法:
builder.table()
3.5 窗口(TODO)
窗口概念?TODO
3.6 连接操作(TODO)
连接操作是通过键将两个流的记录合并,并生成新的流;
Kafka Streams将流抽象为Kstream和Ktable两种类型,因此连接操作也是这两类流之间的操作。即Kstream与Kstream、Ktable和Ktable,Kstream和Ktable之间的连接;常见问题
1. 为什么我的应用程序从一开始就在重新处理数据?
Why is my application re-processing data from the beginning?
卡夫卡通过在一个特殊主题中存储消费者offset来。偏移量是由Kafka broker分配给消息的数字,指示消息到达broker的顺序。通过记住应用程序最后提交的偏移量,应用程序将只处理新到达的消息。
配置设置offsets.retention.minutes控制Kafka在特殊主题中记住偏移的时间。默认值为10080分钟(7天)。请注意,旧版本中的默认值仅为1440分钟(24小时)。
如果您的应用程序暂时停止(尚未连接到Kafka群集),您可能会在应用程序重新启动时开始重新处理数据,因为broker同时删除了偏移量。实际的启动行为取决于可以设置为"earliest", “latest”, or “none”.的auto.offset.reset配置。
为避免此问题,建议将offsets.retention.minutes增加到适当的大值。
2. 应用程序的最大并行性?可以运行的应用程序实例的最大数量?
应用程序运行时的最大并行性由应用程序在其处理拓扑中读取的输入主题的最大分区数决定。输入分区的数量决定了Kafka流将为应用程序创建多少个流任务,流任务的数量是应用程序并行性的上限。
举个例子。假设您的应用程序正在从一个包含5个分区的输入主题中读取。我们可以在这里运行多少个应用程序实例?
简而言之,我们最多可以运行5个应用程序实例,因为应用程序的最大并行性为5。如果我们运行的应用程序实例超过5个,那么“多余”的应用程序实例将成功启动,但保持空闲状态。如果其中一个繁忙实例停机,其中一个空闲实例将恢复前者的工作。
3. 官方demo 都是同一个kafka一个主题写到另一个主题?如何从一个kafka的一个主题写到另一个kafka主题?
kafkaStream如何从一个kafka集群的topic消费数据然后发送到另一个kafka集群的topic里面?
参考URL: https://www.orchome.com/910根据网上信息,以及目前测试结果,你创建KafkaStreams配置的props参数只有bootstrap.servers参考key没有区分生产者和消费者,并且StreamsConfig
KafkaStreams streams = new KafkaStreams(builder.build(), props);
因此,建议分别 使用消费者、生产者,完成该业务需求。
五、kafka环境搭建
- 安装启动zookeeper
./zkServer.sh start
- 官网下载kafka http://kafka.apache.org/downloads.html 下载的版本已经编译,直接解压到想要的目录就算安装好了
tar -zxvf kafka_2.12-2.3.0.tgz
- 配置单结点kafka
vim conf/server.properties
server.properties重要参数说明:
- broker.id=0//This must be set to a unique integer for each broker
- advertised.listeners=PLAINTEXT://192.168.0.108:9092:远程连接需要配置下(0.9.0.1版本没有这个问题)
- log.dirs=/usr/local/kafka_2.11-0.9.0.1/kafka-logs//默认的是不会持久化存储的,这里必须更改下
- zookeeper.connect=//zookeeper的连接地址:根据实际进行配置
- 启动karfka bin/kafka-server-start.sh config/server.properties 后台启动: bin/kafka-server-start.sh -daemon config/server.properties 注释:一个server.properties其实,就可以当做一个broker
六、kafka基本使用
1. kafka常用命令
- 启动karfka
bin/kafka-server-start.sh config/server.properties &
后台启动:
bin/kafka-server-start.sh -daemon config/server.properties
注:一个server.properties其实,就可以当做一个broker
- 停止karfka
bin/kafka-server-stop.sh
- 查看当前服务器中的所有topic(查看主题) kafka-topics.sh --list --zookeeper zk服务IP:2181
bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --list
- 创建主题 /kafka-topics.sh --create --zookeeper zk服务IP:2181 --replication-factor 1 --partitions 1 --topic she
bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic she
–zookeeper 连接zk集群
–create 创建 –replication-factor 副本 –partitions 分区 –topic 主题名 5. 查看topic的详细信息 ./kafka-topics.sh -zookeeper zk服务IP:2181 -describe -topic shebin/kafka-topics.sh -zookeeper 127.0.0.1:2181 -describe -topic she
-
删除topic
kafka-topics.sh --zookeeper zk服务IP:2181 --delete --topic she 注:不能真正删除topic只是把这个topic标记为删除(marked for deletion) -
发送消息
Kafka 默认提供了脚本工具可以不断地接收标准输入并将它们发送到 Kafka 的某个 topic 上 。
kafka-console-producer.sh --broker-list kafka服务IP:9092 --topic she
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic she
注意: kafka服务IP 为server.properties中配置的监听ip
- 接受消息 Kafka 也提供了一个对应的脚本用于消费某(些) topic 下的消息并打印到标准输 出 。 这对于我们测试、调试消息消费非常方便 。
bin/kafka-console-consumer.sh --bootstrap-server karfka服务ip:9092 --topic test --from-beginning
2. 命令使用问题总结
1)报错:Error while fetching metadata with correlation id
报错:Error while fetching metadata with correlation id 67 : {alarmHis=LEADER_NOT_AVAILABLE}
参考URL: http://www.mamicode.com/info-detail-2685225.html报错背景:
单机安装了kafka,创建完成主题,启动生产者的时候产生报错现象。报错时持续不断打印日志信息。 报错原因: 获取相关ID为xx的元数据时出错。 报错解决: vim server.properties 解决:# listeners = PLAINTEXT://your.host.name:9092
去掉注释,将需要监听的ip替换“your.host.name”,重启后恢复正常。
2)消费消息报错zookeeper is not a recognized option
老版本使用 --zookeeper 新版本 使用 --bootstrap-server
查阅资料后发现是kafka的版本问题,低版本的kafka可以使用以上的命令,但是在高版本的kafka中需要使用如下命令才行:
bin/kafka-console-consumer.sh --bootstrap-server karfka服务ip:9092 --topic test --from-beginning
从 Kafka 2.2 版本开始,社区推荐用 --bootstrap-server 参数替换 --zookeeper 参数,并且显式地将后者标记为“已过期”,因此,如果你已经在使用 2.2 版本了,那么创建主题请指定 --bootstrap-server 参数。
为什么改成了–bootstrap-server?
–zookeepe 直接与zookeeper连接,没有安全认证体系约束, --bootstrap-server会走kafka认证相关约束。比如获取主题列表命令:
如果指定了 --bootstrap-server,那么这条命令就会受到安全认证体系的约束,即对命令发起者进行权限验证,然后返回它能看到的主题。否则,如果指定 --zookeeper 参数,那么默认会返回集群中所有的主题详细数据。基于这些原因,我建议你最好统一使用 --bootstrap-server 连接参数。注:命令行脚本很多都是通过连接 ZooKeeper 来提供服务的。目前,社区已经越来越不推荐任何工具直连 ZooKeeper 了,因为这会带来一些潜在的问题,比如这可能会绕过 Kafka 的安全设置。
最后,运行这些脚本需要使用 Kafka 内部的类实现,也就是 Kafka服务器端的代码。实际上,社区还是希望用户只使用 Kafka客户端代码,通过现有的请求机制来运维管理集群。这样的话,所有运维操作都能纳入到统一的处理机制下,方便后面的功能演进。
六、关于Kafka Consumer
优雅的使用Kafka Consumer
参考URL: https://www.jianshu.com/p/abbc09ed6703 [推荐]Kafka Consumer 消费数据你要考虑哪些问题? 参考URL: http://generalthink.github.io/2019/05/06/kafka-consumer-use/ [推荐]Kafka消费者:读消息从Kafka 参考URL: https://blog.csdn.net/zhangmy12138/article/details/88559187kafka 的消费者 和 消费者组
一般来说都是采用 消费者组 来消费数据,而不会是 单消费者 来消费数据的。这里值得我们注意的是:- 一个topic 可以被 多个 消费者组 消费,但是每个 消费者组 消费的数据是 互不干扰 的,也就是说,每个 消费组 消费的都是 完整的数据 。
- 一个分区只能被 同一个消费组内 的一个 消费者 消费,而 不能拆给多个消费者 消费
1. 重平衡(rebalance)
[强烈推荐]Kafka Rebalance机制分析
参考URL: https://www.cnblogs.com/yoke/p/11405397.htmlRebalance 本质上是一种协议,规定了一个 Consumer Group 下的所有 consumer 如何达成一致,来分配订阅 Topic 的每个分区。
例如:某 Group 下有 20 个 consumer 实例,它订阅了一个具有 100 个 partition 的 Topic 。正常情况下,kafka 会为每个 Consumer 平均的分配 5 个分区。这个分配的过程就是 Rebalance。
重平衡是Kafka一个很重要的性质,这个性质保证了高可用和水平扩展。不过也需要注意到,在重平衡期间,所有消费者都不能消费消息,因此会造成整个消费组短暂的不可用。而且,将分区进行重平衡也会导致原来的消费者状态过期,从而导致消费者需要重新更新状态,这段期间也会降低消费性能。
消费者通过定期发送心跳(hearbeat)到一个作为组协调者(group coordinator)的broker来保持在消费组内存活。这个broker不是固定的,每个消费组都可能不同。当消费者拉取消息或者提交时,便会发送心跳。
**如果消费者超过一定时间没有发送心跳,那么它的会话(session)就会过期,组协调者会认为该消费者已经宕机,然后触发重平衡。**可以看到,从消费者宕机到会话过期是有一定时间的,这段时间内该消费者的分区都不能进行消息消费;通常情况下,我们可以进行优雅关闭,这样消费者会发送离开的消息到组协调者,这样组协调者可以立即进行重平衡而不需要等待会话过期
**在0.10.1版本,Kafka对心跳机制进行了修改,将发送心跳与拉取消息进行分离,这样使得发送心跳的频率不受拉取的频率影响。**另外更高版本的Kafka支持配置一个消费者多长时间不拉取消息但仍然保持存活,这个配置可以避免活锁(livelock)。活锁,是指应用没有故障但是由于某些原因不能进一步消费。
分区再均衡 期间该 消费组 是不可用的,并且作为一个 被消费者,分区数的改动将影响到每一个消费者组 ,所以在创建 topic 的时候,我们就应该考虑好分区数。
如果某consumer group中consumer数量少于partition数量,则至少有一个consumer会消费多个partition的数据,如果consumer的数量与partition数量相同,则正好一个consumer消费一个partition的数据,而如果consumer的数量多于partition的数量时,会有部分consumer无法消费该topic下任何一条消息。
1.1 Rebalance 的触发条件
Rebalance 的触发条件有3个。
- 组成员个数发生变化。例如有新的 consumer 实例加入该消费组或者离开组。
- 订阅的 Topic 个数发生变化。
- 订阅 Topic 的分区数发生变化。
Rebalance 发生时,Group 下所有 consumer 实例都会协调在一起共同参与,kafka 能够保证尽量达到最公平的分配。但是 Rebalance 过程对 consumer group 会造成比较严重的影响。在 Rebalance 的过程中 consumer group 下的所有消费者实例都会停止工作,等待 Rebalance 过程完成。
1.2 如何避免不必要 Rebalance
- 组成员数量发生变化
- 订阅主题数量发生变化
- 订阅主题的分区数发生变化 后两个我们大可以人为的避免,发生rebalance最常见的原因是消费组成员的变化。
第一类非必要 Rebalance 是因为未能及时发送心跳,导致 Consumer 被 “踢出”Group 而引发的。
这种情况下我们可以设置 session.timeout.ms 和 heartbeat.interval.ms 的值,来尽量避免rebalance的出现。- 设置 session.timeout.ms = 6s。
- 设置 heartbeat.interval.ms = 2s。
- 要保证 Consumer 实例在被判定为 “dead” 之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。 将 session.timeout.ms 设置成 6s 主要是为了让 Coordinator 能够更快地定位已经挂掉的 Consumer,早日把它们踢出 Group。
第二类非必要 Rebalance 是 Consumer 消费时间过长导致的。此时,max.poll.interval.ms 参数值的设置显得尤为关键。如果要避免非预期的 Rebalance,你最好将该参数值设置得大一点,比你的下游最大处理时间稍长一点。
总之,要为业务处理逻辑留下充足的时间。这样,Consumer 就不会因为处理这些消息的时间太长而引发 Rebalance 。2. push 还是 pull
Kafka Consumer采用的是主动拉取broker数据进行消费的。一般消息中间件存在推送(server推送数据给consumer)和拉取(consumer主动取服务器取数据)两种方式,这两种方式各有优劣。
如果是选择推送的方式最大的阻碍就是服务器不清楚consumer的消费速度,如果consumer中执行的操作又是比较耗时的,那么consumer可能会不堪重负,甚至会导致系统挂掉。而采用拉取的方式则可以解决这种情况,consumer根据自己的状态来拉取数据,可以对服务器的数据进行延迟处理。但是这种方式也有一个劣势就是服务器没有数据的时候可能会一直轮询,不过还好Kafka在poll()有参数允许消费者请求在“长轮询”中阻塞,等待数据到达(并且可选地等待直到给定数量的字节可用以确保传输大小)。
4. Kafka重复消费原因
平台搭建—Kafka使用—Kafka重复消费和丢失数据
参考URL: https://blog.csdn.net/qingqing7/article/details/80054281底层根本原因:已经消费了数据,但是offset没提交。
原因1:强行kill线程,导致消费后的数据,offset没有提交。 原因2:设置offset为自动提交,关闭kafka时,如果在close之前,调用 consumer.unsubscribe() 则有可能部分offset没提交,下次重启会重复消费。例如: try { consumer.unsubscribe(); } catch (Exception e) { }try {
consumer.close(); } catch (Exception e) { }上面代码会导致部分offset没提交,下次启动时会重复消费。
原因3(重复消费最常见的原因):消费后的数据,当offset还没有提交时,partition就断开连接。比如,通常会遇到消费的数据,处理很耗时,导致超过了Kafka的session timeout时间(0.10.x版本默认是30秒),那么就会re-blance重平衡,此时有一定几率offset没提交,会导致重平衡后重复消费。
原因4:当消费者重新分配partition的时候,可能出现从头开始消费的情况,导致重发问题。
原因5:当消费者消费的速度很慢的时候,可能在一个session周期内还未完成,导致心跳机制检测报告出问题。4.1 kafka重复消费解决方案
1.关闭spring-kafka的自动提交
2.延长session-time-out,权衡max.poll.records减少poll()中返回的批次的最大大小来解决此问题,//一次从kafka中poll出来的数据条数 3.权衡自动提交的时间点,ps最好不要使用这种方式,无法尽量避免重复 4.完美解决的话,只有每次都判断消息是否重复消费过了,不过此方式性能开销比较大,严重影响QPS,根据场景取舍总结:只要保证处理消息和提交 offset 得操作是原子操作,就可以做到不重复消费。我们可以自己管理 committed offset, 而不让 kafka 来进行管理。
比如如下使用方式:
- 如果消费的数据刚好需要存储在数据库,那么可以把 offset 也存在数据库,就可以就可以在一个事物中提交这两个结果,保证原子操作。
- 借助搜索引擎,把 offset 和数据一起放到索引里面,比如 Elasticsearch
每条记录都有自己的 offset, 所以如果要管理自己的 offset 还得要做下面事情
- 设置 enable.auto.commit=false
- 使用每个 ConsumerRecord 提供的 offset 来保存消费的位置。
- 在重新启动时使用 seek(TopicPartition, long) 恢复上次消费的位置。
4.2 具体案例
- 场景描述 onsumer消费一条数据平均需要200ms的时间,并且在某个时刻,producer会在短时间内产生大量的数据丢进kafka的broker里面(假设平均1s中内丢入了5w条需要消费的消息,这个情况会持续几分钟)。
对于这种情况,kafka的consumer的行为会是:
- kafka的consumer会从broker里面取出一批数据,给消费线程进行消费。 由于取出的一批消息数量太大,consumer在session.timeout.ms时间之内没有消费完成
- consumer coordinator 会由于没有接受到心跳而挂掉,并且出现一些日志 日志的意思大概是coordinator挂掉了,然后自动提交offset失败,然后重新分配partition给客户端
- 由于自动提交offset失败,导致重新分配了partition的客户端又重新消费之前的一批数据
- 接着consumer重新消费,又出现了消费超时,无限循环下去。
- 解决方案 方法一:
- 提高了partition的数量,从而提高了consumer的并行能力,从而提高数据的消费能力
- 对于单partition的消费线程,增加了一个固定长度的阻塞队列和工作线程池进一步提高并行消费的能力
- 由于使用了spring-kafka,则把kafka-client的enable.auto.commit设置成了false,表示禁止kafka-client自动提交offset,因为就是之前的自动提交失败,导致offset永远没更新,从而转向使用spring-kafka的offset提交机制。并且spring-kafka提供了多种提交策略: 这些策略保证了在一批消息没有完成消费的情况下,也能提交offset,从而避免了完全提交不上而导致永远重复消费的问题。
方法二
- 可以根据消费者的消费速度对session.timeout.ms的时间进行设置,适当延长
- 或者减少每次从partition里面捞取的数据分片的大小,提高消费者的消费速度。
5. 订阅 / 取消主题
- 订阅主题 使用 subscribe() 方法订阅主题 使用 assign() 方法订阅确定主题和分区
通过 subscribe()方法订阅主题具有消费者自动再均衡 (reblance) 的功能,存在多个消费者的情况下可以根据分区分配策略来自动分配各个消费者与分区的关系。当组内的消费者增加或者减少时,分区关系会自动调整。实现消费负载均衡以及故障自动转移。使用 assign()方法订阅则不具有该功能。
ListpartitionInfoList = consumer.partitionsFor("topic1");if(null != partitionInfoList) { for(PartitionInfo partitionInfo : partitionInfoList) { consumer.assign(Collections.singletonList( new TopicPartition(partitionInfo.topic(), partitionInfo.partition()))); }}
- 取消主题
consumer.unsubscribe();consumer.subscribe(new ArrayList<>());consumer.assign(new ArrayList());
6. 提交策略如何选择
Kafka 提供了 3 种提交 offset 的方式
- 自动提交
// 自动提交,默认trueprops.put("enable.auto.commit", "true");// 设置自动每1s提交一次props.put("auto.commit.interval.ms", "1000"); - 手动同步提交 offset
consumer.commitSync();
- 手动异步提交 offset
consumer.commitAsync();
七、关于Kafka 拦截器
Kafka 拦截器分为生产者拦截器和消费者拦截器。
- 生产者拦截器允许你在发送消息前以及消息提交成功后植入你的拦截器逻辑。
- 消费者拦截器支持在消费消息前以及提交位移后编写特定逻辑。
这两种拦截器都支持链的方式,即你可以将一组拦截器串连成一个大的拦截器,Kafka 会按照添加顺序依次执行拦截器逻辑。
1. 生产者拦截器
Properties props = new Properties();Listinterceptors = new ArrayList<>();interceptors.add("com.yourcompany.kafkaproject.interceptors.AddTimestampInterceptor"); // 拦截器 1interceptors.add("com.yourcompany.kafkaproject.interceptors.UpdateCounterInterceptor"); // 拦截器 2props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);……
你自己编写的所有 Producer 端拦截器实现类都要继承 org.apache.kafka.clients.producer.ProducerInterceptor 接口。
覆写方法:- onSend:该方法会在消息发送之前被调用。
- onAcknowledgement:该方法会在消息成功提交或发送失败之后被调用。 onAcknowledgement 的调用要早于生成程序发送消息的 callback 的调用。 值得注意的是,这个方法和 onSend 不是在同一个线程中被调用的,因此如果你在这两个方法中调用了某个共享可变对象,一定要保证线程安全哦。还有一点很重要,这个方法处在 Producer 发送的主路径中,所以最好别放一些太重的逻辑进去,否则你会发现你的 Producer TPS 直线下降。
2. 消费者拦截器
具体的实现类要实现 org.apache.kafka.clients.consumer.ConsumerInterceptor 接口,这里面也有两个核心方法。
- onConsume:该方法在消息返回给 Consumer 程序之前调用。也就是说在开始正式处理消息之前,拦截器会先拦截,交给你处理。
- onCommit:Consumer 在提交位移之后调用该方法。通常你可以在该方法中做一些记账类的动作,比如打日志等。
八、常见问题整理
1. 消息丢失问题
消息丢失可以总结为以下两个方面:
- 生产者程序丢失数据
Producer 永远要使用带有回调通知的发送 API,也就是说不要使用 producer.send(msg),而要使用 producer.send(msg, callback)
它能准确地告诉你消息是否真的提交成功了,你就可以有针对性地进行处理。- 消费者程序丢失数据
消费者程序需要先消费消息,再更新位移的顺序。这样就能保证消息不丢失。
Consumer 程序不要开启自动提交位移,而是要应用程序手动提交位移。2. kafka如何建立tcp连接
2.1 生产者代码是什么时候创建 TCP 连接的?
是在创建KfkaProducer实例时创建的连接还是在调该对象send方法时建立TCP连接?
答案:在创建 KafkaProducer 实例时,生产者应用会在后台创建并启动一个名为 Sender 的线程,该 Sender 线程开始运行时首先会创建与 Broker 的连接。
TCP 连接是在创建 KafkaProducer 实例时建立连接。但也有其他情况,如: 如果 Producer 端发送消息到某台 Broker 时发现没有与该 Broker 的 TCP 连接,那么也会立即创建连接。如果不调用 send 方法,这个 Producer 都不知道给哪个主题发消息,它又怎么能知道连接哪个 Broker 呢?难不成它会连接 bootstrap.servers 参数指定的所有 Broker 吗?嗯,是的,Java Producer 目前还真是这样设计的。
在实际使用过程中,我并不建议把集群中所有的 Broker 信息都配置到 bootstrap.servers 中,通常你指定 3~4 台就足以了。因为 Producer 一旦连接到集群中的任一台 Broker,就能拿到整个集群的 Broker 信息,故没必要为 bootstrap.servers 指定所有的 Broker。
2.2 生产者何时关闭 TCP 连接?
Producer 端关闭 TCP 连接的方式有两种:
一种是用户主动关闭;一种是 Kafka 自动关闭- producer.close() 方法来关闭
- Kafka 帮你关闭 这与 Producer 端参数 connections.max.idle.ms 的值有关。默认情况下该参数值是 9 分钟,即如果在 9 分钟内没有任何请求“流过”某个 TCP 连接,那么 Kafka 会主动帮你把该 TCP 连接关闭。用户可以在 Producer 端设置 connections.max.idle.ms=-1 禁掉这种机制。一旦被设置成 -1,TCP 连接将成为永久长连接。当然这只是软件层面的“长连接”机制,由于 Kafka 创建的这些 Socket 连接都开启了 keepalive,因此 keepalive 探活机制还是会遵守的。
2.3 消费者代码是什么时候创建 TCP 连接的?
和生产者不同的是,构建 KafkaConsumer 实例时是不会创建任何 TCP 连接的。
,也就是说,当你执行完 new KafkaConsumer(properties) 语句后,你会发现,没有 Socket 连接被创建出来。这一点和 Java 生产者是有区别的,主要原因就是生产者入口类 KafkaProducer 在构建实例的时候,会在后台默默地启动一个 Sender 线程,这个 Sender 线程负责 Socket 连接的创建。如果 Socket 不是在构造函数中创建的,那么是在 KafkaConsumer.subscribe 或 KafkaConsumer.assign 方法中创建的吗?严格来说也不是。TCP 连接是在调用 KafkaConsumer.poll 方法时被创建的。
2.4 消费者代码何时关闭 TCP 连接?
和生产者类似,消费者关闭 Socket 也分为主动关闭和Kafka 自动关闭。
- Kafka 自动关闭 消费者端参数 connection.max.idle.ms控制的,该参数现在的默认值是 9 分钟,即如果某个 Socket 连接上连续 9 分钟都没有任何请求“过境”的话,那么消费者会强行“杀掉”这个 Socket 连接。
不过,和生产者有些不同的是,如果在编写消费者程序时,你使用了循环的方式来调用 poll 方法消费消息,那么上面提到的所有请求都会被定期发送到 Broker,因此这些 Socket 连接上总是能保证有请求在发送,从而也就实现了“长连接”的效果。
参考
《KAFKA官方文档》5.2 APIs
参考URL: http://ifeve.com/kafka-apis/ 什么是流式计算 | 另一个世界系列 参考URL: https://www.sohu.com/a/214248082_294584 为什么说,大数据是从流式计算开始切入的? 参考URL: http://www.dostor.com/p/54907.html 手把手教你写Kafka Streams程序 参考URL: https://www.cnblogs.com/huzixia/p/10384912.html转载地址:https://docker.blog.csdn.net/article/details/100049899 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
