大数据时代的Serverless工作负载预测-排名80_0.313
发布日期:2021-06-29 19:49:23
浏览次数:2
分类:技术文章
本文共 33675 字,大约阅读时间需要 112 分钟。
赛题名:大数据时代的Serverless工作负载预测
背景:云计算时代,Serverless软件架构可根据业务工作负载进行弹性资源调整,这种方式可以有效减少资源在空闲期的浪费以及在繁忙期的业务过载,同时给用户带来极致的性价比服务。在弹性资源调度的背后,对工作负载的预测是一个重要环节。如何快速感知业务的坡峰波谷,是一个实用的Serverless服务应该考虑的问题。 任务:传统的资源控制系统以阈值为决策依据,只关注当前监控点的取值,缺少对历史数据以及工作负载趋势的把控,不能提前做好资源的调整,具有很长的滞后性。近年来,随着企业不断上云,云环境的工作负载预测成为一个经典且极具挑战的难题。
上图简单模拟一个不同业务的工作负载变化。业务A、B、C在0-4时刻具有相同的变化趋势,但是其任务类型、监控数据指标并不相同,从而导致了后续的工作负载也呈现了不同的趋势。如果仅根据0-4时刻的单一指标进行判断,可能得出工作负载将会上升的结论,增加资源(Workload C)。但实际业务也可能正趋于饱和(Workload A),或者减少(Workload B)。造成了资源的浪费。
本赛题从实际的应用场景出发,提供对业务工作负载的监控数据,希望参赛者可以针对历史的时序数据信息,对未来的用户工作负载做出预测。
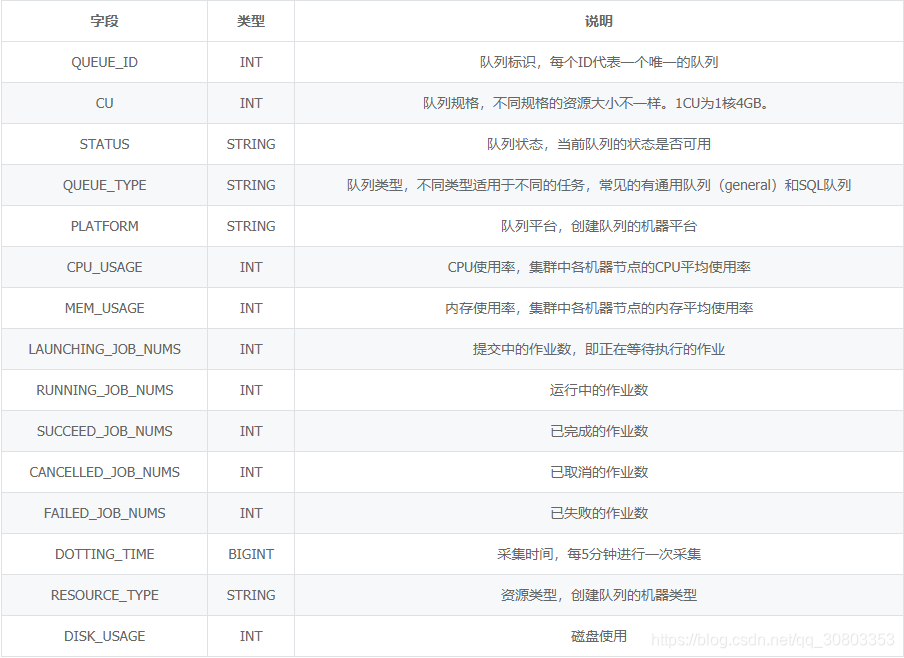
数据说明:
难度与挑战:
1.模型的准确性。模型的度量指标; 2.模型的抗干扰能力。能应对异常数据的干扰; 3.模型的通用性。不依靠堆叠模型提升效果。 出题单位:华为比赛链接:
解题思路一:
- 将非数值型域转换为数值型
- 缺失值填充,填充0比较合理
- 把DOTTINGTIME转换为一天之内的时间也可转为时间戳
- 统计聚合函数的特征
- 生成时间窗数据
- 对于每个QUEUE_ID,丢弃最后10条有NAN值的数据
- 加上历史使用的CPU和内存特征,添加将要执行的任务数
- 去掉无用的列
- 使用lgb进行训练和预测
解题思路二:
- 将DOTTING_TIME转成时间戳
- 筛选 [‘STATUS’, ‘PLATFORM’, ‘RESOURCE_TYPE’]
- 将非数值型域转换为数值型 {‘general’: 0, ‘sql’: 1, ‘spark’: 2}
- 移除高于50的running job,两个样本
- 移除重复的时间戳
- 同一个QUEUE_ID 和DOTTING_TIME进行agg,不同的列agg方式不同
- 将不连续的时间戳标记为None,方便后面移除
- 计算相邻两次的DOTTING_TIME 间隔
- 间隔大于7 或者小于3,就认为是异常
- 提取训练集和测试集QUEUE_ID 分布相同的样本 11. 统计之后继续agg
- 筛选特征,发现RandomForest 最稳定,lightgbm效果不好,RFECV会把特征降到很少比如30,最终选择RFE
特征工程思路:
1.队列状态 2.作业是运行在队列上的 3.SelectKBest特征选择 4.异常失败:内存过多,或者写错SQL 5.时间特征 6.交叉特征 7.分箱特征 8.可以做一些新特征,比如将两个原有特征相加 9.相对于每个queue_id的最高最低,然后进行一个增加或者减少的一个划分 10.进行时间窗的一个划分 11.考虑时间的时序特征,对日期、星期、小时进行编码 12.构建统计特征 median mean 13.考虑网上活动对Serverless服务的影响 14.(1)指出传统静态聚类方法的不足之处,将静态聚类方法K-means应用于进化聚类的框架下,对云负载进行聚类分析,为预测提供依据。(2)提出一种改进的短期云负载预测方法,将ARIMA与BP神经网络结合起来,将ARIMA预测后的残差部分运用BP神经网络进行残差预测,最终将两部分的预测结果进行集成,预测效果与ARIMA相比具有更高准确性。(3)考虑长期负载预测的时间成本问题,将负载预测模型转换为一种可以提前训练的模型。将时间序列按窗口划分样本,对每个窗口内的时间序列进行特征提取。运用改进的Adboost集成方法进行样本学习。实验通过3条不同时序片段进行对比,验证改进模型的有效性。(4)设计基于Spark的预测系统,分别从数据接收,数据存储及查询,预测分析功能,界面展示等功能进行设计。系统可以实时分析云负载的变化情况,并通过图表显示分析结果。 15.模型思路:
1、Temporal Pattern Attention (TPA) TPA (时间模式注意力): 一种用于多变量时间序列预测的新的注意力机制,使用时间模式 (Temporal Pattern) 来指代任何跨多个时间步的时间不变模式。在 TPA 中, 机器会学习去选择相关的时间序列 (Time Series) ,而不是像传统的注意机制 那样选择相关的时间步 (Time Steps) 。 在 TPA 中,引入卷积神经网络 (CNN) 来从每个单独的变量中提取时间模 式信息。 2、多变量时间序列预测模型 3、Proposed Attention Mechanism 注意力机制提交结果如下图:
特征工程代码如下:
# -*- coding: utf-8 -*-import osimport timeimport pandas as pdfrom sklearn.preprocessing import LabelEncoderdef make_label(data): data['CPU_USAGE_1'] = data.CPU_USAGE.shift(-1) data['CPU_USAGE_2'] = data.CPU_USAGE.shift(-2) data['CPU_USAGE_3'] = data.CPU_USAGE.shift(-3) data['CPU_USAGE_4'] = data.CPU_USAGE.shift(-4) data['CPU_USAGE_5'] = data.CPU_USAGE.shift(-5) data['CPU_USAGE_fu1'] = data.CPU_USAGE.shift(1) data['CPU_USAGE_fu2'] = data.CPU_USAGE.shift(2) data['CPU_USAGE_fu3'] = data.CPU_USAGE.shift(3) data['CPU_USAGE_fu4'] = data.CPU_USAGE.shift(4) # data['CPU_USAGE_fu5']=data.CPU_USAGE.shift(5) data['LAUNCHING_JOB_NUMS_1'] = data.LAUNCHING_JOB_NUMS.shift(-1) data['LAUNCHING_JOB_NUMS_2'] = data.LAUNCHING_JOB_NUMS.shift(-2) data['LAUNCHING_JOB_NUMS_3'] = data.LAUNCHING_JOB_NUMS.shift(-3) data['LAUNCHING_JOB_NUMS_4'] = data.LAUNCHING_JOB_NUMS.shift(-4) data['LAUNCHING_JOB_NUMS_5'] = data.LAUNCHING_JOB_NUMS.shift(-5) data['LAUNCHING_JOB_NUMS_fu1'] = data.LAUNCHING_JOB_NUMS.shift(1) data['LAUNCHING_JOB_NUMS_fu2'] = data.LAUNCHING_JOB_NUMS.shift(2) data['LAUNCHING_JOB_NUMS_fu3'] = data.LAUNCHING_JOB_NUMS.shift(3) data['LAUNCHING_JOB_NUMS_fu4'] = data.LAUNCHING_JOB_NUMS.shift(4) # data['LAUNCHING_JOB_NUMS_fu5']=data.LAUNCHING_JOB_NUMS.shift(5) return data.dropna()def make_history(data): data['CPU_USAGE_fu1'] = data.CPU_USAGE.shift(1) data['CPU_USAGE_fu2'] = data.CPU_USAGE.shift(2) data['CPU_USAGE_fu3'] = data.CPU_USAGE.shift(3) data['CPU_USAGE_fu4'] = data.CPU_USAGE.shift(4) data['LAUNCHING_JOB_NUMS_fu1'] = data.LAUNCHING_JOB_NUMS.shift(1) data['LAUNCHING_JOB_NUMS_fu2'] = data.LAUNCHING_JOB_NUMS.shift(2) data['LAUNCHING_JOB_NUMS_fu3'] = data.LAUNCHING_JOB_NUMS.shift(3) data['LAUNCHING_JOB_NUMS_fu4'] = data.LAUNCHING_JOB_NUMS.shift(4) return datadef process(df): df.DOTTING_TIME /= 1000 df.DOTTING_TIME = list(map(lambda x: time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(x)), df.DOTTING_TIME)) df = df.sort_values(['QUEUE_ID', 'DOTTING_TIME']) df['DOTTING_TIME'] = pd.to_datetime(df.DOTTING_TIME) return dfos.chdir(r'E:\项目文件\大数据时代的Serverless工作负载预测/')submission = pd.read_csv('submit_example.csv')train = pd.read_csv('train.csv')test = pd.read_csv('evaluation_public.csv')train = process(train)test = process(test)# 将之后五个时间点的数值作为labeltrain = train.groupby('QUEUE_ID').apply(make_label)test = test.groupby(['ID', 'QUEUE_ID']).apply(make_history)del train['STATUS']del train['PLATFORM']del train['RESOURCE_TYPE']# del train['CANCELLED_JOB_NUMS']# del train['FAILED_JOB_NUMS']del test['STATUS']del test['PLATFORM']del test['RESOURCE_TYPE']# del test['CANCELLED_JOB_NUMS']# del test['FAILED_JOB_NUMS']train = train.reset_index(drop=True)# 特征值转化encode_STATUS = LabelEncoder()encode_QUEUE_TYPE = LabelEncoder()encode_PLATFORM = LabelEncoder()encode_RESOURCE_TYPE = LabelEncoder()# train.STATUS=encode_STATUS.fit_transform(train.STATUS)# test.STATUS=encode_STATUS.transform(test.STATUS)train.QUEUE_TYPE = encode_QUEUE_TYPE.fit_transform(train.QUEUE_TYPE)test.QUEUE_TYPE = encode_QUEUE_TYPE.transform(test.QUEUE_TYPE)# train.PLATFORM=encode_PLATFORM.fit_transform(train.PLATFORM)# test.PLATFORM=encode_PLATFORM.transform(test.PLATFORM)# train.RESOURCE_TYPE=encode_RESOURCE_TYPE.fit_transform(train.RESOURCE_TYPE)# test.RESOURCE_TYPE=encode_RESOURCE_TYPE.transform(test.RESOURCE_TYPE)train.drop(['DOTTING_TIME'], axis=1, inplace=True)test.drop(['DOTTING_TIME'], axis=1, inplace=True)train['used_cpu'] = train['CU'] * train['CPU_USAGE'] / 100train['used_mem'] = train['CU'] * 4 * train['MEM_USAGE'] / 100test['used_cpu'] = test['CU'] * test['CPU_USAGE'] / 100test['used_mem'] = test['CU'] * 4 * test['MEM_USAGE'] / 100train['to_run_jobs'] = train['LAUNCHING_JOB_NUMS'] + train['RUNNING_JOB_NUMS']test['to_run_jobs'] = test['LAUNCHING_JOB_NUMS'] + test['RUNNING_JOB_NUMS']train['used_cpu_diff1'] = train.groupby(['QUEUE_ID'])['used_cpu'].diff(1).fillna(0)train['used_mem_diff1'] = train.groupby(['QUEUE_ID'])['used_mem'].diff(1).fillna(0)train['used_disk_diff1'] = train.groupby(['QUEUE_ID'])['DISK_USAGE'].diff(1).fillna(0)train['to_run_jobs_diff1'] = train.groupby(['QUEUE_ID'])['to_run_jobs'].diff(1).fillna(0)train['launching_diff1'] = train.groupby(['QUEUE_ID'])['LAUNCHING_JOB_NUMS'].diff(1).fillna(0)train['running_diff1'] = train.groupby(['QUEUE_ID'])['RUNNING_JOB_NUMS'].diff(1).fillna(0)train['succeed_diff1'] = train.groupby(['QUEUE_ID'])['SUCCEED_JOB_NUMS'].diff(1).fillna(0)train['cancelled_diff1'] = train.groupby(['QUEUE_ID'])['CANCELLED_JOB_NUMS'].diff(1).fillna(0)train['failed_diff1'] = train.groupby(['QUEUE_ID'])['FAILED_JOB_NUMS'].diff(1).fillna(0)# train['used_cpu_diff-1'] = train.groupby(['QUEUE_ID'])['used_cpu'].diff(-1).fillna(0)# train['used_mem_diff-1'] = train.groupby(['QUEUE_ID'])['used_mem'].diff(-1).fillna(0)# # train['used_disk_diff-1'] = train.groupby(['QUEUE_ID'])['DISK_USAGE'].diff(-1).fillna(0)# train['to_run_jobs_diff-1'] = train.groupby(['QUEUE_ID'])['to_run_jobs'].diff(-1).fillna(0)# train['launching_diff-1'] = train.groupby(['QUEUE_ID'])['LAUNCHING_JOB_NUMS'].diff(-1).fillna(0)# train['running_diff-1'] = train.groupby(['QUEUE_ID'])['RUNNING_JOB_NUMS'].diff(-1).fillna(0)# train['succeed_diff-1'] = train.groupby(['QUEUE_ID'])['SUCCEED_JOB_NUMS'].diff(-1).fillna(0)# train['cancelled_diff-1'] = train.groupby(['QUEUE_ID'])['CANCELLED_JOB_NUMS'].diff(-1).fillna(0)# train['failed_diff-1'] = train.groupby(['QUEUE_ID'])['FAILED_JOB_NUMS'].diff(-1).fillna(0)test['used_cpu_diff1'] = test.groupby(['QUEUE_ID'])['used_cpu'].diff(1).fillna(0)test['used_mem_diff1'] = test.groupby(['QUEUE_ID'])['used_mem'].diff(1).fillna(0)test['used_disk_diff1'] = test.groupby(['QUEUE_ID'])['DISK_USAGE'].diff(1).fillna(0)test['to_run_jobs_diff1'] = test.groupby(['QUEUE_ID'])['to_run_jobs'].diff(1).fillna(0)test['launching_diff1'] = test.groupby(['QUEUE_ID'])['LAUNCHING_JOB_NUMS'].diff(1).fillna(0)test['running_diff1'] = test.groupby(['QUEUE_ID'])['RUNNING_JOB_NUMS'].diff(1).fillna(0)test['succeed_diff1'] = test.groupby(['QUEUE_ID'])['SUCCEED_JOB_NUMS'].diff(1).fillna(0)test['cancelled_diff1'] = test.groupby(['QUEUE_ID'])['CANCELLED_JOB_NUMS'].diff(1).fillna(0)test['failed_diff1'] = test.groupby(['QUEUE_ID'])['FAILED_JOB_NUMS'].diff(1).fillna(0)# test['used_cpu_diff-1'] = test.groupby(['QUEUE_ID'])['used_cpu'].diff(-1).fillna(0)# test['used_mem_diff-1'] = test.groupby(['QUEUE_ID'])['used_mem'].diff(-1).fillna(0)# # test['used_disk_diff-1'] = test.groupby(['QUEUE_ID'])['DISK_USAGE'].diff(-1).fillna(0)# test['to_run_jobs_diff-1'] = test.groupby(['QUEUE_ID'])['to_run_jobs'].diff(-1).fillna(0)# test['launching_diff-1'] = test.groupby(['QUEUE_ID'])['LAUNCHING_JOB_NUMS'].diff(-1).fillna(0)# test['running_diff-1'] = test.groupby(['QUEUE_ID'])['RUNNING_JOB_NUMS'].diff(-1).fillna(0)# # test['succeed_diff-1'] = test.groupby(['QUEUE_ID'])['SUCCEED_JOB_NUMS'].diff(-1).fillna(0)# # test['cancelled_diff-1'] = test.groupby(['QUEUE_ID'])['CANCELLED_JOB_NUMS'].diff(-1).fillna(0)# # test['failed_diff-1'] = test.groupby(['QUEUE_ID'])['FAILED_JOB_NUMS'].diff(-1).fillna(0)targets_names = ['CPU_USAGE_1', 'LAUNCHING_JOB_NUMS_1', 'CPU_USAGE_2', 'LAUNCHING_JOB_NUMS_2', 'CPU_USAGE_3', 'LAUNCHING_JOB_NUMS_3', 'CPU_USAGE_4', 'LAUNCHING_JOB_NUMS_4', 'CPU_USAGE_5', 'LAUNCHING_JOB_NUMS_5']targets = []train.to_csv('train_x.csv', index=False)for i in targets_names: targets.append(train[i]) train.drop(i, axis=1, inplace=True)test = test.drop_duplicates(subset=['ID'], keep='last')test_id = test.IDtest.to_csv('test.csv', index=False)test.drop('ID', axis=1, inplace=True)# # from catboost import CatBoostRegressorfrom lightgbm import LGBMRegressorfrom sklearn.model_selection import train_test_splitdf = pd.DataFrame()df['ID'] = test_iddf = df.reset_index(drop=True)model = LGBMRegressor(n_estimators=100000, eval_metric='mae')for i in targets: train_x, test_x, train_y, test_y = train_test_split(train, i, test_size=0.2, random_state=100) model.fit(train_x, train_y, eval_set=(test_x, test_y), early_stopping_rounds=50, verbose=100) df[i.name] = model.predict(test, num_iteration=model.best_iteration_)columns1 = ['CPU_USAGE_1', 'LAUNCHING_JOB_NUMS_1', 'CPU_USAGE_2', 'LAUNCHING_JOB_NUMS_2', 'CPU_USAGE_3', 'LAUNCHING_JOB_NUMS_3', 'CPU_USAGE_4', 'LAUNCHING_JOB_NUMS_4', 'CPU_USAGE_5', 'LAUNCHING_JOB_NUMS_5']# from sklearn.datasets import make_regression# from sklearn.multioutput import RegressorChain# from sklearn.svm import LinearSVR# from sklearn.ensemble import RandomForestRegressor# targets_names=['CPU_USAGE_1','LAUNCHING_JOB_NUMS_1','CPU_USAGE_2','LAUNCHING_JOB_NUMS_2','CPU_USAGE_3','LAUNCHING_JOB_NUMS_3',# 'CPU_USAGE_4','LAUNCHING_JOB_NUMS_4','CPU_USAGE_5','LAUNCHING_JOB_NUMS_5']# train.columns# X_train = train[['QUEUE_ID', 'CU', 'STATUS', 'QUEUE_TYPE', 'PLATFORM', 'CPU_USAGE',# 'MEM_USAGE', 'LAUNCHING_JOB_NUMS', 'RUNNING_JOB_NUMS',# 'SUCCEED_JOB_NUMS', 'CANCELLED_JOB_NUMS', 'FAILED_JOB_NUMS',# 'RESOURCE_TYPE', 'DISK_USAGE']].reset_index(drop=True)# Y_train = train[['CPU_USAGE_1','LAUNCHING_JOB_NUMS_1','CPU_USAGE_2',# 'LAUNCHING_JOB_NUMS_2','CPU_USAGE_3','LAUNCHING_JOB_NUMS_3',# 'CPU_USAGE_4','LAUNCHING_JOB_NUMS_4','CPU_USAGE_5',# 'LAUNCHING_JOB_NUMS_5']].reset_index(drop=True)# model = RandomForestRegressor()# # fit model# # wrapper = RegressorChain(model)# # fit model# # wrapper.fit(X, y)# model.fit(X_train, Y_train)# # make a prediction# yhat = model.predict(test)# yhat = pd.DataFrame(yhat)# yhat.insert(0, 'ID', 1)# yhat.columns=submission.columns# yhat['ID']=df['ID']df_1 = df.copy()for i in columns1: df_1[i] = df_1[i].apply(lambda x: 0 if x < 0 else x) df_1[i] = (df_1[i]).astype(int)df_1 = df_1.sort_values(by=['ID']).reset_index(drop=True)df_1.to_csv('lgb.csv', index=False) 模型一:sklearn中的lgb、etr、rf融合,评分0.219
import osimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom serverless.models import stacking_traindef pdReadCsv(file, sep): try: data = pd.read_csv(file, sep=sep,encoding='utf-8',error_bad_lines=False,engine='python') return data except: data = pd.read_csv(file,sep=sep,encoding='gbk',error_bad_lines=False,engine='python') return dataos.chdir(r'E:\项目文件\大数据时代的Serverless工作负载预测/')train = 'train_x.csv'test = 'test.csv'train = pdReadCsv(train, ',')test = pdReadCsv(test, ',')targets_names = ['CPU_USAGE_1', 'LAUNCHING_JOB_NUMS_1', 'CPU_USAGE_2', 'LAUNCHING_JOB_NUMS_2', 'CPU_USAGE_3', 'LAUNCHING_JOB_NUMS_3', 'CPU_USAGE_4', 'LAUNCHING_JOB_NUMS_4', 'CPU_USAGE_5', 'LAUNCHING_JOB_NUMS_5']targets = []for i in targets_names: targets.append(train[i]) train.drop(i, axis=1, inplace=True)test_id = test.IDdf = pd.DataFrame()df['ID'] = test_iddf = df.reset_index(drop=True)test.drop('ID', axis=1, inplace=True)for y in targets: x_train, x_val, y_train, y_val = train_test_split(train, y, test_size=0.1, random_state=100) df[y.name] = stacking_train(x_train, y_train, x_val, y_val, test)columns1 = ['CPU_USAGE_1', 'LAUNCHING_JOB_NUMS_1', 'CPU_USAGE_2', 'LAUNCHING_JOB_NUMS_2', 'CPU_USAGE_3', 'LAUNCHING_JOB_NUMS_3', 'CPU_USAGE_4', 'LAUNCHING_JOB_NUMS_4', 'CPU_USAGE_5', 'LAUNCHING_JOB_NUMS_5']df_1 = df.copy()for i in columns1: df_1[i] = df_1[i].apply(lambda x: 0 if x < 0 else x) df_1[i] = (df_1[i]).astype(int)df_1 = df_1.sort_values(by=['ID']).reset_index(drop=True)src = r'E:\项目文件\大数据时代的Serverless工作负载预测\提交\\'df_1.to_csv(src+'lgb_etr_rf.csv', index=False) models.py
from lightgbm import LGBMRegressorfrom sklearn.ensemble import RandomForestRegressor, ExtraTreesRegressorfrom sklearn.metrics import mean_absolute_error, mean_squared_errorfrom sklearn.model_selection import GridSearchCVimport pandas as pdfrom utils.read_write import writeOneCsvsrc = r'E:\项目文件\大数据时代的Serverless工作负载预测\\'def build_model_rf(x_train, y_train): estimator = RandomForestRegressor(criterion='mse') param_grid = { 'max_depth': range(33, 44, 9), 'n_estimators': range(73, 88, 9), } model = GridSearchCV(estimator, param_grid, cv=3) model.fit(x_train, y_train) print('rf') print(model.best_params_) writeParams('rf', model.best_params_) return modeldef build_model_etr(x_train, y_train): # 极端随机森林回归 n_estimators 即ExtraTreesRegressor最大的决策树个数 estimator = ExtraTreesRegressor(criterion='mse') param_grid = { 'max_depth': range(33, 44, 9), 'n_estimators': range(96, 111, 9), } model = GridSearchCV(estimator, param_grid) model.fit(x_train, y_train) print('etr') print(model.best_params_) writeParams('etr', model.best_params_) return modeldef build_model_lgb(x_train, y_train): estimator = LGBMRegressor() param_grid = { 'learning_rate': [0.15,0.2], 'n_estimators': range(86, 88, 9), 'num_leaves': range(64, 66, 9) } gbm = GridSearchCV(estimator, param_grid) gbm.fit(x_train, y_train) print('lgb') print(gbm.best_params_) writeParams('lgb', gbm.best_params_) return gbmdef stacking_train(x_train, y_train, x_val, y_val, test): model_lgb = build_model_lgb(x_train, y_train) val_lgb = model_lgb.predict(x_val) model_etr = build_model_etr(x_train, y_train) val_etr = model_etr.predict(x_val) model_rf = build_model_rf(x_train, y_train) val_rf = model_rf.predict(x_val) # Starking 第一层 train_etr_pred = model_etr.predict(x_train) print('etr训练集,mse:', mean_squared_error(y_train, train_etr_pred)) write_mse('etr', '训练集', mean_squared_error(y_train, train_etr_pred)) train_lgb_pred = model_lgb.predict(x_train) print('lgb训练集,mse:', mean_squared_error(y_train, train_lgb_pred)) write_mse('lgb', '训练集', mean_squared_error(y_train, train_lgb_pred)) train_rf_pred = model_rf.predict(x_train) print('rf训练集,mse:', mean_squared_error(y_train, train_rf_pred)) write_mse('rf', '训练集', mean_squared_error(y_train, train_rf_pred)) Stacking_X_train = pd.DataFrame() Stacking_X_train['Method_1'] = train_rf_pred Stacking_X_train['Method_2'] = train_lgb_pred Stacking_X_train['Method_3'] = train_etr_pred Stacking_X_val = pd.DataFrame() Stacking_X_val['Method_1'] = val_rf Stacking_X_val['Method_2'] = val_lgb Stacking_X_val['Method_3'] = val_etr # 第二层 model_Stacking = build_model_etr(Stacking_X_train, y_train) train_pre_Stacking = model_Stacking.predict(Stacking_X_train) score_model(Stacking_X_train, y_train, train_pre_Stacking, model_Stacking, '训练集') val_pre_Stacking = model_Stacking.predict(Stacking_X_val) score_model(Stacking_X_val, y_val, val_pre_Stacking, model_Stacking, '验证集') subA_etr = model_etr.predict(test) subA_etr1 = model_lgb.predict(test) subA_etr2 = model_rf.predict(test) Stacking_X_test = pd.DataFrame() Stacking_X_test['Method_1'] = subA_etr Stacking_X_test['Method_2'] = subA_etr1 Stacking_X_test['Method_3'] = subA_etr2 pred = model_Stacking.predict(Stacking_X_test) return preddef scatter_line(y_val, y_pre): import matplotlib.pyplot as plt xx = range(0, len(y_val)) plt.scatter(xx, y_val, color="red", label="Sample Point", linewidth=3) plt.plot(xx, y_pre, color="orange", label="Fitting Line", linewidth=2) plt.legend() plt.show()def score_model(train, test, predict, model, data_type): score = model.score(train, test) print(data_type + ",R^2,", round(score, 6)) writeOneCsv(['staking', data_type, 'R^2', round(score, 6)], src + '调参记录.csv') mae = mean_absolute_error(test, predict) print(data_type + ',MAE,', mae) writeOneCsv(['staking', data_type, 'MAE', mae], src + '调参记录.csv') mse = mean_squared_error(test, predict) print(data_type + ",MSE,", mse) writeOneCsv(['staking', data_type, 'MSE', mse], src + '调参记录.csv')def writeParams(model, best): if model == 'lgb': writeOneCsv([model, best['num_leaves'], best['n_estimators'], best['learning_rate']], src + '调参记录.csv') else: writeOneCsv([model, best['max_depth'], best['n_estimators'], 0], src + '调参记录.csv')def write_mse(model, data_type, mse): writeOneCsv([model, data_type, 'mse', mse], src + '调参记录.csv') 模型二:lstm+cnn 效果暂未测试
# coding:utf-8import osimport numpy as npimport pandas as pdfrom keras import Input, Modelfrom keras.initializers import he_normalfrom keras.layers import LSTM, Dense, Conv1D, LeakyReLU, Concatenatefrom keras.optimizers import Adamfrom sklearn.preprocessing import MinMaxScaler# 定义多通道特征组合模型def build_multi_cr_lstm_model(ts, fea_dim): # 定义输入 inputs = Input(shape=(ts, fea_dim)) # filters:卷积核的数目(即输出的维度) kernel_size:卷积核的空域或时域窗长度 # strides:为卷积的步长 kernel_initializer 权值矩阵的初始化器 cnn_left_out1 = Conv1D(filters=50, kernel_size=6, strides=3, kernel_initializer=he_normal(seed=3))(inputs) act_left_out1 = LeakyReLU()(cnn_left_out1) # 输出维度 return_sequences:若为True则返回整个序列,否则仅返回输出序列的最后一个输出 lstm_left_out1 = LSTM(64, activation='sigmoid', dropout=0.1, return_sequences=False, kernel_initializer=he_normal(seed=10))(act_left_out1) # cnn层&lstm层2 cnn_right_out1 = Conv1D(filters=50, kernel_size=12, strides=3, kernel_initializer=he_normal(seed=3))(inputs) act_right_out1 = LeakyReLU()(cnn_right_out1) lstm_right_out1 = LSTM(64, activation='sigmoid', dropout=0.1, return_sequences=False, kernel_initializer=he_normal(seed=10))(act_right_out1) # cnn层&lstm层3 cnn_mid_out1 = Conv1D(filters=50, kernel_size=6, strides=2, kernel_initializer=he_normal(seed=3))(inputs) act_mid_out1 = LeakyReLU()(cnn_mid_out1) lstm_mid_out1 = LSTM(64, activation='sigmoid', dropout=0.1, return_sequences=False, kernel_initializer=he_normal(seed=10))(act_mid_out1) # Concatenate 连接三个数组 concat_output = Concatenate(axis=1)([lstm_left_out1, lstm_mid_out1, lstm_right_out1]) # 上层叠加新的dense层 units:代表该层的输出维度 outputs = Dense(units=1)(concat_output) model_func = Model(inputs=inputs, outputs=outputs) model_func.compile(loss='mse', optimizer=Adam(lr=0.002, decay=0.01), metrics=['mse']) return model_func# 构建训练集、预测集,训练和预测分别transformdef start(): src050 = r'E:\项目文件\大数据时代的Serverless工作负载预测\\' train_all_file = src050 + 'train_x.csv' test_file = src050 + 'test.csv' train = pd.read_csv(train_all_file, engine='python') ts = 1112 test = pd.read_csv(test_file, engine='python') targets_names = ['CPU_USAGE_1', 'LAUNCHING_JOB_NUMS_1', 'CPU_USAGE_2', 'LAUNCHING_JOB_NUMS_2', 'CPU_USAGE_3', 'LAUNCHING_JOB_NUMS_3', 'CPU_USAGE_4', 'LAUNCHING_JOB_NUMS_4', 'CPU_USAGE_5', 'LAUNCHING_JOB_NUMS_5'] targets = [] for i in targets_names: targets.append(train[i]) train.drop(i, axis=1, inplace=True) test_id = test.ID df = pd.DataFrame() df['ID'] = test_id df = df.reset_index(drop=True) test.drop('ID', axis=1, inplace=True) for y in targets: # 训练数据进行归一化 train_x = scalar_x.fit_transform(train) train_y = scalar_y.fit_transform(y.values.reshape((y.shape[0], 1))) # 预测数据归一化 test_x = scalar_x.transform(test) # ############# 构建训练和预测集 ################### ts_train_x = np.array([]) ts_train_y = np.array([]) ts_test_x = np.array([]) # 构建训练数据集 print('训练数据的原始shape:', train_x.shape) for i in range(train_x.shape[0]): if i + ts == train_x.shape[0]: break ts_train_x = np.append(ts_train_x, train_x[i: i + ts, :]) ts_train_y = np.append(ts_train_y, train_y[i + ts]) # 构建预测数据集 print('预测数据的原始shape:', test_x.shape) for i in range(test_x.shape[0]): if i + ts == test_x.shape[0]: break ts_test_x = np.append(ts_test_x, test_x[i: i + ts, :]) x_train, y_train, x_test = ts_train_x.reshape((train_x.shape[0] - ts, ts, train_x.shape[1])), ts_train_y, \ ts_test_x.reshape((test_x.shape[0] - ts, ts, test_x.shape[1])) # 构建model lstm_model = build_multi_cr_lstm_model(1112, 15) lstm_model.fit(x_train, y_train, epochs=1, batch_size=30) # 预测结果 pred_y = lstm_model.predict(x_test) # 转换为真实值 pred_y_inverse = scalar_y.inverse_transform(pred_y) df[y.name] = pd.DataFrame(pred_y_inverse) df_1 = df.copy() for i in targets_names: df_1[i] = df_1[i].apply(lambda x: 0 if x < 0 else x) df_1[i] = (df_1[i]).astype(int) df_1 = df_1.sort_values(by=['ID']).reset_index(drop=True) src = r'E:\项目文件\大数据时代的Serverless工作负载预测\提交\\' df_1.to_csv(src + 'cnn_lstm_15.csv', index=False) # 把涨跌记录做成一个序列,去匹配距离最近的序列if __name__ == '__main__': os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # 超参设置 data_dim = 15 # 归一化 scalar_x = MinMaxScaler(feature_range=(0, 1)) scalar_y = MinMaxScaler(feature_range=(0, 1)) # 获取训练和预测数据 start() 模型三:svr, lsvr, lgbm, nn的模型融合,效果暂未测试
# -*- coding: utf-8 -*-import numpy as npimport pandas as pdimport xgboostfrom keras.layers import Densefrom keras.models import Sequentialfrom keras.wrappers.scikit_learn import KerasRegressorfrom sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clonefrom sklearn.ensemble import ExtraTreesRegressorfrom sklearn.kernel_ridge import KernelRidgefrom sklearn.linear_model import ElasticNet, Lasso, LinearRegressionfrom sklearn.metrics import mean_squared_errorfrom sklearn.model_selection import KFold, cross_val_score, GridSearchCVfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import MinMaxScalerfrom sklearn.svm import SVR, LinearSVRseed = 2018# Stackingclass StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin): def __init__(self, base_models, meta_model, n_folds=5): self.base_models = base_models self.meta_model = meta_model self.n_folds = n_folds # 我们再次拟合原始模型的克隆数据 def fit(self, X, y): self.base_models_ = [list() for x in self.base_models] self.meta_model_ = clone(self.meta_model) kfold = KFold(n_splits=self.n_folds, shuffle=True) # 训练克隆的基础模型,然后创建非折叠预测 # 培养克隆元模型所需的 out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models))) for i, clf in enumerate(self.base_models): for train_index, holdout_index in kfold.split(X, y): instance = clone(clf) self.base_models_[i].append(instance) instance.fit(X[train_index], y[train_index]) y_pred = instance.predict(X[holdout_index]) out_of_fold_predictions[holdout_index, i] = y_pred # 现在使用不可折叠的预测来训练克隆的元模型 print(out_of_fold_predictions.shape) self.meta_model_.fit(out_of_fold_predictions, y) return self def predict(self, X): meta_features = np.column_stack([ np.column_stack([model.predict(X) for model in base_models]).mean(axis=1) for base_models in self.base_models_]) return self.meta_model_.predict(meta_features)# 简单模型融合class AveragingModels(BaseEstimator, RegressorMixin, TransformerMixin): def __init__(self, models): self.models = models # 遍历所有模型 def fit(self, X, y): self.models_ = [clone(x) for x in self.models] for model in self.models_: model.fit(X, y) return self # 预估,并对预估结果值做average def predict(self, X): predictions = np.column_stack([ model.predict(X) for model in self.models_ ]) return np.mean(predictions, axis=1)def build_nn(): model = Sequential() # head_feature_num参数需要和input_dim参数大小一致,都代表特征数量 model.add(Dense(units=128, activation='linear', input_dim=12)) model.add(Dense(units=32, activation='linear')) model.add(Dense(units=8, activation='linear')) model.add(Dense(units=1, activation='linear')) model.compile(loss='mse', optimizer='adam') return modeldef build_model(): svr = make_pipeline(SVR(kernel='linear')) line = make_pipeline(LinearRegression()) lasso = make_pipeline(Lasso(alpha=0.0005, random_state=1)) ENet = make_pipeline(ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3)) KRR1 = KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5) lsvr = LinearSVR(C=2) # KRR2 = KernelRidge(alpha=1.5, kernel='linear', degree=2, coef0=2.5) # lgbm = lightgbm.LGBMRegressor() etr = ExtraTreesRegressor(criterion='mse', max_depth=38) xgb = xgboost.XGBRegressor(booster='gbtree', colsample_bytree=0.8, gamma=0.1, min_child_weight=0.8, reg_alpha=0, reg_lambda=1, subsample=0.8, random_state=seed, nthread=2) nn = KerasRegressor(build_fn=build_nn, nb_epoch=500, batch_size=32, verbose=2) return svr, line, lasso, ENet, KRR1, lsvr, etr, xgb, nndef rmsle_cv(model=None, X_train_head=None, y_train=None): n_folds = 5 kf = KFold(n_folds, shuffle=True, random_state=seed).get_n_splits(X_train_head) rmse = -cross_val_score(model, X_train_head, y_train, scoring="neg_mean_squared_error", cv=kf) return (rmse)def main(): src050 = r'E:\项目文件\大数据时代的Serverless工作负载预测\\' train_all_file = src050 + 'train_x.csv' test_file = src050 + 'test.csv' head_feature_num = 12 data = pd.read_csv(train_all_file, engine='python') test = pd.read_csv(test_file) targets_names = ['CPU_USAGE_1', 'LAUNCHING_JOB_NUMS_1', 'CPU_USAGE_2', 'LAUNCHING_JOB_NUMS_2', 'CPU_USAGE_3', 'LAUNCHING_JOB_NUMS_3', 'CPU_USAGE_4', 'LAUNCHING_JOB_NUMS_4', 'CPU_USAGE_5', 'LAUNCHING_JOB_NUMS_5'] targets = [] for i in targets_names: targets.append(data[i]) data.drop(i, axis=1, inplace=True) test_id = test.ID df = pd.DataFrame() df['ID'] = test_id df = df.reset_index(drop=True) test.drop('ID', axis=1, inplace=True) for y in targets: X_train, y_train = data, y print("X_train shape", X_train.shape) print("y_train shape", y_train.shape) all_data = pd.concat([X_train, test]) print(all_data.shape) print("Load done.") # 标准化 from sklearn import preprocessing scaler = MinMaxScaler(feature_range=(0, 1)) all_data = pd.DataFrame(scaler.fit_transform(all_data), columns=all_data.columns) print("Scale done.") scaled = pd.DataFrame(preprocessing.scale(all_data), columns=all_data.columns) X_train = scaled.loc[0:len(X_train) - 1] X_test = scaled.loc[len(X_train):] # 特征选择 from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_regression X_scored = SelectKBest(score_func=f_regression, k='all').fit(X_train, y_train) feature_scoring = pd.DataFrame({ 'feature': X_train.columns, 'score': X_scored.scores_ }) feat_scored_headnum = feature_scoring.sort_values('score', ascending=False).head(head_feature_num)['feature'] print(feat_scored_headnum) X_train_head = X_train[X_train.columns[X_train.columns.isin(feat_scored_headnum)]] X_test_head = X_test[X_test.columns[X_test.columns.isin(feat_scored_headnum)]] print(X_test_head.columns) print(X_train_head.shape) print(y_train.shape) print(X_test_head.shape) print("Start training......") svr, line, lasso, ENet, KRR1, lsvr, etr, xgb, nn = build_model() feat_scored_headnum = feature_scoring.sort_values('score', ascending=False).head(head_feature_num)['feature'] X_train_head5 = X_train[X_train.columns[X_train.columns.isin(feat_scored_headnum)]] score = rmsle_cv(nn, X_train_head5, y_train) print("NN 得分: {:.4f} ({:.4f})\n".format(score.mean(), score.std())) nn.fit(X_train_head, y_train) score = rmsle_cv(svr, X_train_head, y_train) print("SVR rmse: {:.4f} 标准差: {:.4f}\n".format(score.mean(), score.std())) svr.fit(X_train_head, y_train) score = rmsle_cv(line, X_train_head, y_train) print("Line rmse: {:.4f} 标准差: {:.4f}\n".format(score.mean(), score.std())) # line.fit(X_train_head, y_train) score = rmsle_cv(lasso, X_train_head, y_train) print("Lasso rmse: {:.4f} 标准差: {:.4f}\n".format(score.mean(), score.std())) # lasso.fit(X_train_head, y_train) score = rmsle_cv(ENet, X_train_head, y_train) print("ElasticNet rmse: {:.4f} 标准差: {:.4f}\n".format(score.mean(), score.std())) # ENet.fit(X_train_head, y_train) # ============================================================================= score = rmsle_cv(KRR1, X_train_head, y_train) print("Kernel Ridge1 rmse: {:.4f} 标准差: {:.4f}\n".format(score.mean(), score.std())) # KRR1.fit(X_train_head, y_train) score = rmsle_cv(lsvr, X_train_head, y_train) print("Kernel Ridge2 rmse: {:.4f} 标准差: {:.4f}\n".format(score.mean(), score.std())) lsvr.fit(X_train_head, y_train) feat_scored_headnum = feature_scoring.sort_values('score', ascending=False).head(head_feature_num)['feature'] X_train_head3 = X_train[X_train.columns[X_train.columns.isin(feat_scored_headnum)]] score = rmsle_cv(xgb, X_train_head3, y_train) print("Xgboost rmse: {:.4f} 标准差: {:.4f}\n".format(score.mean(), score.std())) param_grid = { 'learning_rate': [0.02], 'max_depth': range(5, 9, 5), 'n_estimators': range(433, 444, 50), } xgb = GridSearchCV(xgb, param_grid) xgb.fit(X_train_head, y_train) print('xgb') print(xgb.best_params_) # head_feature_num = 13 feat_scored_headnum = feature_scoring.sort_values('score', ascending=False).head(head_feature_num)['feature'] print(feat_scored_headnum) X_train_head4 = X_train[X_train.columns[X_train.columns.isin(feat_scored_headnum)]] score = rmsle_cv(etr, X_train_head4, y_train) print("LGBM 得分: {:.4f} ({:.4f})\n".format(score.mean(), score.std())) param_grid = { # 'learning_rate': [0.01], 'n_estimators': range(333, 338, 50), # 'num_leaves': range(31, 33, 2) } lgbm = GridSearchCV(etr, param_grid) lgbm.fit(X_train_head, y_train.ravel()) print('lgb') print(lgbm.best_params_) averaged_models = AveragingModels(models=(svr, lsvr, lgbm, nn)) score = rmsle_cv(averaged_models, X_train_head, y_train) print("对基模型集成后的得分: {:.6f} ({:.6f})\n".format(score.mean(), score.std())) averaged_models.fit(X_train_head, y_train) stacking_models = StackingAveragedModels(base_models=(svr, lsvr, lgbm, nn), meta_model=xgb) stacking_models.fit(X_train_head.values, y_train.values) stacked_train_pred = stacking_models.predict(X_train_head) score = mean_squared_error(y_train.values, stacked_train_pred) print("Stacking Averaged models predict score: {:.6f}".format(score)) print(X_test_head) stacked_test_pred = stacking_models.predict(X_test_head) df[y.name] = pd.DataFrame(stacked_test_pred) df_1 = df.copy() for i in targets_names: df_1[i] = df_1[i].apply(lambda x: 0 if x < 0 else x) df_1[i] = (df_1[i]).astype(int) df_1 = df_1.sort_values(by=['ID']).reset_index(drop=True) src = r'E:\项目文件\大数据时代的Serverless工作负载预测\提交\\' df_1.to_csv(src + 'svr_lsvr_lgbm_nn_12.csv', index=False)main() 特征工程后的数据已上传到我的下载:
鱼佬工作负载预测baseline下载链接如下:
链接: https://pan.baidu.com/s/19aILKM9I8_DSwKFcwOn60w 提取码: k1f8转载地址:https://data-mining.blog.csdn.net/article/details/109729469 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
不错!
[***.144.177.141]2024年04月07日 07时01分05秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
什么是 C# 分部类(partia)
2019-04-30
在web.config中配置session的生命周期
2019-04-30
Oracle随机函数
2019-04-30
ASP.NET Application_Error错误日志写入
2019-04-30
asp.net错误日志写入
2019-04-30
C#如何使用转义字符来正确的表示双引号、单引号等字符串
2019-04-30
使用FILEUPLOAD控件将EXCEL文导入并保存至数据库
2019-04-30
ASP.NET 2.0个性化配置(profile)
2019-04-30
ASP.NET之:序列化
2019-04-30
Asp.Net 构架(HttpModule 介绍) - Part.3
2019-04-30
深入浅出分析C#接口的作用
2019-04-30
免费的天气预报webservice接口
2019-04-30
Server.Transfer VS Response.Redirect
2019-04-30
asp.net页面出错时常用的处理方法
2019-04-30
ASP.NET State Service
2019-04-30
web.config中的InProc模式 与 StateServer模式
2019-04-30
C#泛型集合揽胜
2019-04-30
如何选择书籍
2019-04-30
linux下清空文件内容
2019-04-30
Linux查看某目录占用空间以及其下有多少个文件
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310342713 位访客
访问时间: 2024-05-03 14:27:29
访问IP: 3.134.90.44
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版