本文共 4551 字,大约阅读时间需要 15 分钟。
1.字典字符集的笛卡尔乘积
问题描述:
对于给定的由字典字符集组合而成的表达式,求该表达式构成的所有元素。例如表达式[0-9][a-z],其中0-9表示10个数字,a-z表示26个小写字母,构成的所有元素就是0a,0b,…,0z,1a,1b,…9z。字典字符集的笛卡尔乘积示意如下: 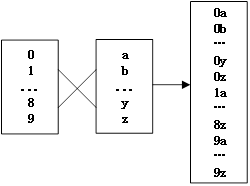
问题分析:
对于任意的一个字典字符集构成的表达式[dic0][dic1]...[dicn],从左至右可以看作按照高位到低位的一个由字典元素组成的一个“数”,这样比较符合我们日常表示数值的高低位的习惯。比如如果字典都是[0-9],那么表达式[0-9][0-9]表示的就是一个数值字符串00~99。笛卡尔乘积的空间是各个字典高度的乘积,给定其空间中的任意一个元素下标,就可以对应到每个字典中的元素下标。比如[0-9[0-9]的笛卡尔乘积的空间是各个字典高度的乘积10*10=100,空间中第0个元素就是00,第99个元素就是99。 每一个字典元素都有一个位权重。表达式[0-9[0-9] 从左至右第一个字典的位权重w=10,第二个字典的位权重w=1。我们平常所说的个位、十位、百位,就是根据数值位的位权重来称呼它。位权重的意义在于,数值是其位权重的多少倍,那么它就取第几个元素。比如第99个元素(下标从0开始),那么数值99是十位的位权重w=10的9倍,所以元素为字符‘9’,对数值99取w=10的余数得9,同理9是个位的位权重w=1的9倍,所以元素为字符’9’,所以构成了字符串99。
实现示例:
对表达式[0-9][a-z[A-Z],其实现笛卡尔乘积的具体过程可以描述如下: (1)对从左至右(高位到低位)将各个字典字符集的所在数位的计算单位计算出来,由当前字典右边的字典的高度相乘得到,如[0-9]的计数单位w=26*26=676,[a-z]的计数单位w=26*1=26,[A-Z]的计数单位w=1。 (2)给定笛卡尔乘积空间的元素下标i,根据i找到各个字典内的元素下标的过程如下,从高位开始查找,即从左开始查找。 (2.1)查找字典[0-9]中的元素下标:[0-9].index=i/[0-9].w; (2.2)查找字典[a-z]中的元素下标[a-z].index:i=i%[0-9].w; [a-z].index=i/[a-z].w; (2.3)查找字典[A-Z]中的元素下标[A-Z].index:i=i%[a-z].w;[A-Z].index=i/1=i。 (3)将i=0递增至笛卡尔乘积的空间大小减一,即10*26*26-1,重复步骤2,即可完成表达式[0-9][a-z[A-Z]的笛卡尔乘积。 例如给定第677个笛卡尔乘积的元素,那么[0-9].index=1,所以取[0-9]内的素‘1’,[a-z].index=671%676/26=0,所以取出元素‘a’,[a-z].index=1/1=1,所以取出元素‘B’,所以第677个元素就是“1aB”。
2.源码
以下代码在Linux平台编译运行,稍作修改可移植到Windows平台。其功能是完成多个字典字符集的笛卡尔乘积。并通过OpenMP并行加速。正确性已在实际项目中通过验证。
#include#include #include #include
3.优化
写毕业论文的时候,经实验室的小伙伴提醒,发现其实不用事先求出各个字典所在数位的计数单位,也可以根据给定的笛卡尔乘积的元素下标唯一的找到各个字典中对应的元素。为了避免与论文查重时重复,只贴出图片。具体实现已经抽象为如下算法:

算法中注释中的热词就是上文提到字典,其实现的原理是从表达式的低位到高位计算每一个字典的元素下标,上面未优化的方法是从高位到低位顺序计算。从低位到高位来计算的话,无需事先求出各个字典位的计数单位。因为:当字典位的计数单位的为w=1时,可以通过笛卡尔乘积的元素下标i对其高度h取余,即得到最低字典位字典内的元素下标。当对下一个字典求其元素下标时,需要将下一个字典位的计数单位w’变为1,具体做法就是i除以当前字典的高度向下取整。依次类推,就可以求出各个字典内的元素下标了。具体描述见上面的算法。
以表达式[0-9][a-z[A-Z],求笛卡尔乘积中第677个(从0开始)元素的各个字典内的元素下标的过程描述如下:
4.再优化
仔细阅读上面的算法描述,你会发现算法的内层循环存在重复的字典元素拷贝,比如笛卡尔乘积元素下标0~25对应的字典[0-9]和[a-z]内的元素下标始终是0,那么就重复拷贝了[0-9]和[a-z]中元素25次。针对该问题,可以对上面的算法做进一步的优化。
以一次字典元素拷贝作为基本操作, 那么第二小节和第三小节的时间复杂度是O(hn),h为笛卡尔乘积空间大小,n为字典个数。
再优化算法描述如下:

再优化步骤描述如下:
(1)选取高度最高的字典 Sk ; (2)循环h次,h为其它字典高度的乘积; (2.1)将其它字典元素拼接在一起; (2.2)循环最高字典高度 Hk 次,k为最高字典的下标,将元素填充到临时字符串s中后,将s加入笛卡尔乘积集合。时间复杂度为O( h0 (n-1)+ h0h1 )=O( h0 ( h1+n−1 ))。其中 h0 为非最高字典高度乘积, h1 为最高字典高度,n为字典个数, n≥2 。上文中未优化的时间复杂度是优化后的倍数 t=h0h1nh0(h1+n−1)=n1+n−1h1 ,可见,n和 h1 越大,优化效果越明显。假设 h1 很大,那么优化的倍数大约为字典的个数。
转载地址:https://dablelv.blog.csdn.net/article/details/50083895 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
