じゅういち:data yu 处理
发布日期:2021-06-29 18:48:39
浏览次数:2
分类:技术文章
本文共 3031 字,大约阅读时间需要 10 分钟。
文章目录
11。1概述
-
数据有缺失值、数据有重复值,预处理。
-
这里给出数据预处理的常用流程
-
去除唯一属性
-
处理缺失值;
-
属性编码
-
数据标准化、正则化
-
特征选择;
-
主成分分析。
-
主成分介绍过
-
这里主要介绍前面的几个常用流程
- 这章特征和属性的意义相同,不加区分
11.2算法笔记精华
11.2.1去除唯一属性
- 获取的数据集中,经常会遇到唯一属性。
- 这些属性通常是添加的一些id属性,如存放在数据库中自增的主键。
- 不刻画样本自身的分布规律,只需要简单地删除这些属性即可。

11.2 处理缺失值的三方法
- 缺失值产生的原因多种
- 数据存储的失败,存储器损坏,机械故障导致某段时间数据未能收集(对于定时数据采集而言)
- 人为原因: 人主观失误、历史局限或有意隐瞒造成的数据缺失,
- 市场调査中被访人拒绝透露相关问题的答案,
- 回答的问题是无效的,
- 数据输入人员失误漏输了数据
- 直接使用含有缺失值的特征
- 删除含有缺失值的特征
- 缺失值补全。
11.3 Python实践
11.3.1二元化
- Binarizeri能将数据二元化

- 指定了属性國值。低于此阈值的属性转换为0,高于此阈國 值的属性转换为1。

- 为True,则原地修改(节省空间,但是修改了原始数据)。

from sklearn.preprocessing import BinarizerX=[[1,2,3,4,5],[5,4,3,2,1],[3,3,3,3,3,],[1,1,1,1,1]]print("before transform:", X)binarizer=Binarizer(threshold=2.5)print("after transform:" ,binarizer.transform(X))PS C:\Users\ZTZ\Desktop\md\分类> & D:/software/Anaconda3/envs/base_tensorflow/python c:/Users/ZTZ/Desktop/untitled0.pybefore transform: [[1, 2, 3, 4, 5], [5, 4, 3, 2, 1], [3, 3, 3, 3, 3], [1, 1, 1, 1, 1]]after transform: [[0 0 1 1 1] [1 1 1 0 0] [1 1 1 1 1] [0 0 0 0 0]] - 小于2.5的属性的值都转为0:
- 大于2.5的属性的值都转为1。
11.3.2独热码

- 字符串’auto’,或整数,或整数的数组,

- 自动从训练数据中推断属性值取值的上界。
- 指定了所有属性取值的上界。
- 每个元素依次指定了一个属性取值的上界。
- 字符串’all’,或下标的数组,或是一个mask
- 哪些属性要编码独热码。
- 所有的属性都将编码为独热码。
- 指定下标的属性将编码为独热码
- 对应为True的属性将编码为独热码
-
指定了独热码编码的数值类型,默认为np. float
-
布尔值,指定结果是否稀疏。
-
一个字符,数据转换时,遇到了某个集合类型的属性,
-
但该属性未列入 categorical_features时的情形,可以指定为如下。
-
error’:抛出异常
-
ignore’:忽略。
- 属性
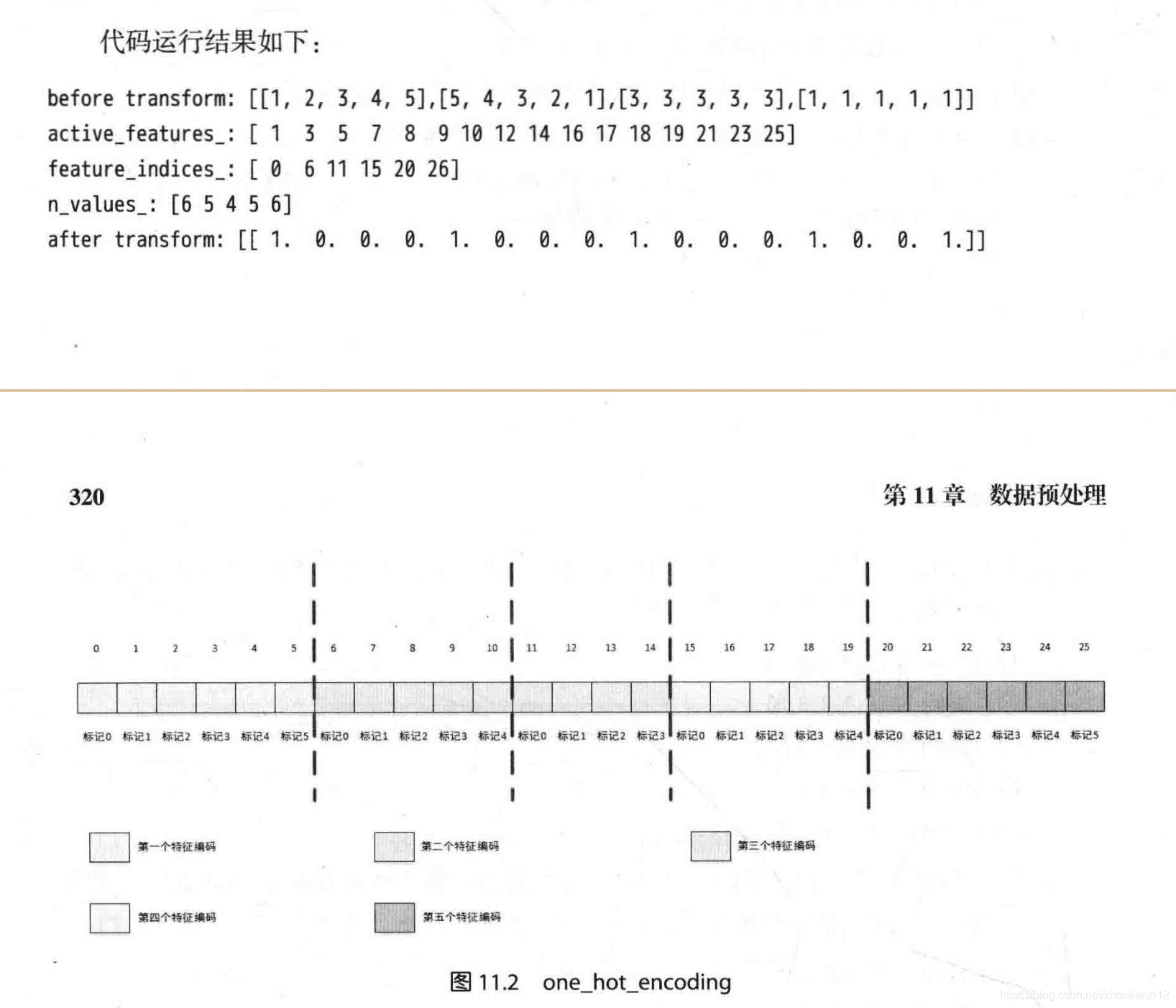
- active_ features_:
- 数组,给出激活特征。
- 如果原始数据的某个属性的某个取值在转换后数据的第 i i i个属性中激活,则i是数组的元素

- feature_ indices_:数组,
- 原始数据的第个属性对应转换后数 据的[ feature_ indices_[i], feature_ indices_[i+11之间的属性
- n_ values_:数组,存放每个属性取值的种类(一般为训练数据中该属性取值的最大值加1,这是因为默认每个属性取值从另开始)。

from sklearn.preprocessing import OneHotEncoderX=[[1,2,3,4,5],[5,4,3,2,1],[3,3,3,3,3],[1,1,1,1,1]]print("before transform:",X)encoder=OneHotEncoder(sparse=False)encoder.fit(X)#print("active_features_: ",encoder.active_features_)#print("feature_indices_: ",encoder.feature_indices_)#print("n_values_:" ,encoder.n_values_)print("after transform: ",encoder.transform([[1, 2,3,4,5]]))before transform: [[1, 2, 3, 4, 5], [5, 4, 3, 2, 1], [3, 3, 3, 3, 3], [1, 1, 1, 1, 1]]after transform: [[1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1.]] 这本书下面在放屁
- 又好像没有放屁



11.3.3 标准化
MinMaxScaler
- min-max标准化,原型

- 元组(min,max),预期变换之后属性的取值范围。
- 为True,则执行原地修改(节省空间,但是修改了原始数据)。
11.3.4 正则化

- norm:字符串
- l1: L1范数正则化
- l2: L2范数正则化
- l ∞ l_{\infty} l∞ 用范数正则化
- copy:为True,则原地修改(节省空间,但修改了原始数据)。

from sklearn.preprocessing import NormalizerX=[[1,2,3,4,5],[5,4,3,2,1],[3,3,3,3,3,],[1,1,1,1,1]]print("before transform:", X)normalizer=Normalizer(norm="l2")print("after transform:" ,normalizer.transform(X))PS C:\Users\ZTZ\Desktop\md\分类> & D:/software/Anaconda3/envs/base_tensorflow/python c:/Users/ZTZ/Desktop/untitled0.pybefore transform: [[1, 2, 3, 4, 5], [5, 4, 3, 2, 1], [3, 3, 3, 3, 3], [1, 1, 1, 1, 1]]after transform: [[0.13483997 0.26967994 0.40451992 0.53935989 0.67419986] [0.67419986 0.53935989 0.40451992 0.26967994 0.13483997] [0.4472136 0.4472136 0.4472136 0.4472136 0.4472136 ] [0.4472136 0.4472136 0.4472136 0.4472136 0.4472136 ]] - 正则化后,每个样本的L2范数为1。
为啥要把每个样本的的几个特征正则化啊
转载地址:https://cyj666.blog.csdn.net/article/details/106783235 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
第一次来,支持一个
[***.219.124.196]2024年04月18日 17时13分20秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
css技巧---位置中间的竖线|垂直居中
2019-04-30
css技巧---电子表体字体引入
2019-04-30
随笔---如何启动Redis
2019-04-30
css技巧---menu菜单加new
2019-04-30
uni-app 开发技巧:复选框list选择后value传多值问题
2019-04-30
ES6数组中删除指定元素
2019-04-30
freemarker模板当标签内的元素为空报错解决方案
2019-04-30
序列化对象
2019-04-30
理解对象意思
2019-04-30
百度地图路书开发---增加路书销毁
2019-04-30
echarts日历自定义月份
2019-04-30
如何解决中文乱码问题
2019-04-30
关于如何彻底卸载SQL SERVER2005 2008
2019-04-30
整理sql2008数据库如何附加到sql2000或sql2005
2019-04-30
Eclipse 简便设置
2019-04-30
Bootstrap修改caret大小
2019-04-30
适应大分辨率显示屏操作
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310362297 位访客
访问时间: 2024-05-03 16:30:08
访问IP: 3.145.111.125
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版