本文共 11405 字,大约阅读时间需要 38 分钟。
0x01 backward_convolutional_layer
void backward_convolutional_layer(convolutional_layer l, network net){ int i, j; int m = l.n/l.groups; //每组卷积核的个数 int n = l.size*l.size*l.c/l.groups; //每组卷积核的元素个数 int k = l.out_w*l.out_h; //输出图像的元素个数 gradient_array(l.output, l.outputs*l.batch, l.activation, l.delta); 这里出现了一个gradient_array函数,我们看看这个函数有什么作用。
float gradient(float x, ACTIVATION a){ switch(a){ case LINEAR: return linear_gradient(x); case LOGISTIC: return logistic_gradient(x); case LOGGY: return loggy_gradient(x); case RELU: return relu_gradient(x); case ELU: return elu_gradient(x); case RELIE: return relie_gradient(x); case RAMP: return ramp_gradient(x); case LEAKY: return leaky_gradient(x); case TANH: return tanh_gradient(x); case PLSE: return plse_gradient(x); case STAIR: return stair_gradient(x); case HARDTAN: return hardtan_gradient(x); case LHTAN: return lhtan_gradient(x); } return 0;}void gradient_array(const float *x, const int n, const ACTIVATION a, float *delta){ int i; for(i = 0; i < n; ++i){ delta[i] *= gradient(x[i], a); }} static inline float linear_gradient(float x){ return 1;}static inline float logistic_gradient(float x){ return (1-x)*x;}static inline float relu_gradient(float x){ return (x>0);}static inline float elu_gradient(float x){ return (x >= 0) + (x < 0)*(x + 1);}static inline float relie_gradient(float x){ return (x>0) ? 1 : .01;}static inline float ramp_gradient(float x){ return (x>0)+.1;}static inline float leaky_gradient(float x){ return (x>0) ? 1 : .1;}static inline float tanh_gradient(float x){ return 1-x*x;}static inline float plse_gradient(float x){ return (x < 0 || x > 1) ? .01 : .125;} 这个函数的作用很明显,就是将layer的输出图像,输入到相应的梯度下降算法(计算每一个元素对应激活函数的导数),最后将delta的每个元素乘以激活函数的导数,结果送到delta指向的内存中。
举个例子
m=2 n=3x3=9 k=3x3=9x [95 107 107 95]relu激活delta[0]=95 delta[1]=107 delta[2]=107 delta[3]=105
接着往后
if(l.batch_normalize){ backward_batchnorm_layer(l, net); 出现这个backward_batchnorm_layer函数
0x0101 backward_batchnorm_layer
void backward_batchnorm_layer(layer l, network net){ if(!net.train){ l.mean = l.rolling_mean; l.variance = l.rolling_variance; } backward_bias(l.bias_updates, l.delta, l.batch, l.out_c, l.out_w*l.out_h); backward_scale_cpu(l.x_norm, l.delta, l.batch, l.out_c, l.out_w*l.out_h, l.scale_updates); scale_bias(l.delta, l.scales, l.batch, l.out_c, l.out_h*l.out_w); mean_delta_cpu(l.delta, l.variance, l.batch, l.out_c, l.out_w*l.out_h, l.mean_delta); variance_delta_cpu(l.x, l.delta, l.mean, l.variance, l.batch, l.out_c, l.out_w*l.out_h, l.variance_delta); normalize_delta_cpu(l.x, l.mean, l.variance, l.mean_delta, l.variance_delta, l.batch, l.out_c, l.out_w*l.out_h, l.delta); if(l.type == BATCHNORM) copy_cpu(l.outputs*l.batch, l.delta, 1, net.delta, 1);} 这里面也有很多函数,我们一一分析
void backward_bias(float *bias_updates, float *delta, int batch, int n, int size){ int i,b; for(b = 0; b < batch; ++b){ for(i = 0; i < n; ++i){ bias_updates[i] += sum_array(delta+size*(i+b*n), size); } }}float sum_array(float *a, int n)//计算输入数组的和{ int i; float sum = 0; for(i = 0; i < n; ++i) sum += a[i]; return sum;} bias_updates:指向权重更新的指针delta:指向前面梯度下降得到的累乘值batch:batch大小n:layer的输出通道数目size:输出图像的元素个数
这个函数就是计算偏置的更新值(误差函数对偏置的导数),将delta对应同一个卷积核的项相加。
这个函数想要描述的就是这个公式
- ∂ L ∂ β = ∑ 0 m ∂ L ∂ y i \frac{∂L}{∂\beta}=\sum_0^m\frac{∂L}{∂y_i} ∂β∂L=∑0m∂yi∂L
void backward_scale_cpu(float *x_norm, float *delta, int batch, int n, int size, float *scale_updates){ int i,b,f; for(f = 0; f < n; ++f){ float sum = 0; for(b = 0; b < batch; ++b){ for(i = 0; i < size; ++i){ int index = i + size*(f + n*b); sum += delta[index] * x_norm[index]; } } scale_updates[f] += sum; }} 这个函数想要描述的就是这个公式
- ∂ L ∂ γ = ∑ 0 m ∂ l ∂ y i x i ^ \frac{∂L}{∂\gamma}=\sum_0^m\frac{∂l}{∂y_i}\hat{x_i} ∂γ∂L=∑0m∂yi∂lxi^
void mean_delta_cpu(float *delta, float *variance, int batch, int filters, int spatial, float *mean_delta){ int i,j,k; for(i = 0; i < filters; ++i){ mean_delta[i] = 0; for (j = 0; j < batch; ++j) { for (k = 0; k < spatial; ++k) { int index = j*filters*spatial + i*spatial + k; mean_delta[i] += delta[index]; } } mean_delta[i] *= (-1./sqrt(variance[i] + .00001f)); }} 这个函数想要描述的就是这个公式
- ∂ L ∂ m e a n = ∑ 0 m ∂ L ∂ y i ∂ y i ∂ m e a n = ∑ 0 m ∂ L ∂ y i − 1 v a r + e p s \frac{∂L}{∂mean}=\sum_0^m\frac{∂L}{∂y_i}\frac{∂y_i}{∂mean}=\sum_0^m\frac{∂L}{∂y_i}\frac{−1}{\sqrt{var+eps}} ∂mean∂L=∑0m∂yi∂L∂mean∂yi=∑0m∂yi∂Lvar+eps−1
void variance_delta_cpu(float *x, float *delta, float *mean, float *variance, int batch, int filters, int spatial, float *variance_delta){ int i,j,k; for(i = 0; i < filters; ++i){ variance_delta[i] = 0; for(j = 0; j < batch; ++j){ for(k = 0; k < spatial; ++k){ int index = j*filters*spatial + i*spatial + k; variance_delta[i] += delta[index]*(x[index] - mean[i]); } } variance_delta[i] *= -.5 * pow(variance[i] + .00001f, (float)(-3./2.)); }} 这个函数想要描述的就是这个公式
- ∂ L ∂ v a r = ∑ 0 m ∂ L ∂ y i ( x i − m e a n ) ( − 1 2 ) ( v a r + e p s ) − 3 2 \frac{∂L}{∂var}=\sum_0^m\frac{∂L}{∂y_i}(x_i−mean)(-\frac{1}{2})(var+eps)^{−\frac{3}{2}} ∂var∂L=∑0m∂yi∂L(xi−mean)(−21)(var+eps)−23
void normalize_delta_cpu(float *x, float *mean, float *variance, float *mean_delta, float *variance_delta, int batch, int filters, int spatial, float *delta){ int f, j, k; for(j = 0; j < batch; ++j){ for(f = 0; f < filters; ++f){ for(k = 0; k < spatial; ++k){ int index = j*filters*spatial + f*spatial + k; delta[index] = delta[index] * 1./(sqrt(variance[f] + .00001f)) + variance_delta[f] * 2. * (x[index] - mean[f]) / (spatial * batch) + mean_delta[f]/(spatial*batch); } } }} 这个函数想要描述的就是这个公式
- ∂ L ∂ x i = ∂ L ∂ y i 1 v a r + e p s + ∂ L ∂ v a r ∂ v a r ∂ x i + ∂ L ∂ m e a n ∂ m e a n ∂ x i = ∂ L ∂ y i 1 v a r + e p s + ∂ L ∂ v a r 2 m ( x i − m e a n ) + ∂ L ∂ m e a n 1 m \frac{∂L}{∂x_i}=\frac{∂L}{∂y_i}\frac{1}{\sqrt{var+eps}}+\frac{∂L}{∂var}\frac{∂var}{∂x_i}+\frac{∂L}{∂mean}\frac{∂mean}{∂x_i}=\frac{∂L}{∂y_i}\frac{1}{\sqrt{var+eps}}+\frac{∂L}{∂var}\frac{2}{m}(x_i-mean)+\frac{∂L}{∂mean}\frac{1}{m} ∂xi∂L=∂yi∂Lvar+eps1+∂var∂L∂xi∂var+∂mean∂L∂xi∂mean=∂yi∂Lvar+eps1+∂var∂Lm2(xi−mean)+∂mean∂Lm1
回到backward_convolutional_layer函数
//backward_convolutional_layer if(l.batch_normalize){ backward_batchnorm_layer(l, net); } else { backward_bias(l.bias_updates, l.delta, l.batch, l.n, k); } 如果没有定义batch_normalize的话,直接更新bias就完事了。
接着往后
//backward_convolutional_layer for(i = 0; i < l.batch; ++i){ for(j = 0; j < l.groups; ++j){ float *a = l.delta + (i*l.groups + j)*m*k; float *b = net.workspace; float *c = l.weight_updates + j*l.nweights/l.groups; float *im = net.input+(i*l.groups + j)*l.c/l.groups*l.h*l.w; im2col_cpu(im, l.c/l.groups, l.h, l.w, l.size, l.stride, l.pad, b); gemm(0,1,m,n,k,1,a,k,b,k,1,c,n); if(net.delta){ a = l.weights + j*l.nweights/l.groups; b = l.delta + (i*l.groups + j)*m*k; c = net.workspace; gemm(1,0,n,k,m,1,a,n,b,k,0,c,k); col2im_cpu(net.workspace, l.c/l.groups, l.h, l.w, l.size, l.stride, l.pad, net.delta + (i*l.groups + j)*l.c/l.groups*l.h*l.w); } } }} 首先我们这里先说明一个问题,细心的同学会发现,这里使用的是gemm(0,1...),也就是我在(三)中说过的,我这里对B进行了转置操作。为什么要这样做呢?
先看看参数是什么意思。
int m = l.n/l.groups; //每组卷积核的个数int n = l.size*l.size*l.c/l.groups; //每组卷积核的元素个数int k = l.out_w*l.out_h; //输出图像的元素个数
a指向一个group的l.delta的一行,元素个数为(l.out_c)*(l.out_h*l.out_w);b指向保存结果的内存,大小是(l.c*l.size*l.size)*(l.out_h*l.out_w);c指向一个group的weight的一行,大小是(l.n)*(l.c*l.size*l.size)。gemm描述的是这样一种运算a*b+c。所以根据矩阵运算的原理,这里的b要进行转置操作。
那么这里的卷积作用也就非常明显了,就是就算当前层的权重更新c=alpha*a*b+beta*c。
和之前的forward_convolutional_layer函数参数对比
int m = l.n/l.groups;//一个group的卷积核个数int k = l.size*l.size*l.c/l.groups;//一个group的卷积核元素个数int n = l.out_w*l.out_h;//一个输出图像的元素个数float *a = l.weights + j*l.nweights/l.groups;float *b = net.workspace;float *c = l.output + (i*l.groups + j)*n*m;
接着看后面这个判断语句中的内容
//backward_convolutional_layerif(net.delta){ a = l.weights + j*l.nweights/l.groups;//注意此时权重没有更新,我们上面算的是放在了weight_updates里面 b = l.delta + (i*l.groups + j)*m*k; c = net.workspace; gemm(1,0,n,k,m,1,a,n,b,k,0,c,k); col2im_cpu(net.workspace, l.c/l.groups, l.h, l.w, l.size, l.stride, l.pad, net.delta + (i*l.groups + j)*l.c/l.groups*l.h*l.w);} 我们看看这里的gemm和前面的有什么区别,首先看参数。这里的a对应上面的c,b对应上面的a,c对应上面的b。
a指向weight,大小是(l.n)*(l.c*l.size*l.size);b指向delta,大小是(l.out_c)*(l.out_h*l*out_w);c指向输出存储空间,大小是(l.c*l.size*l.size)*(l.out_h*l.out_w)。那么这里调用gemm(1,0...)就很好理解了,最后完成c=alpha*a*b+beta*c操作,也就是更新workspace的工作。
那么这里这个函数到底有什么意义呢?
通过上面那个c=alpha*a*b+beta*c给我们的直观感受,就是将当前层的delta和上一层weights进行卷积操作,这个得到的结果意义不是很大,但是他经过之前说的gradient_array操作后就有了非常重要的意义,就是上一层的delta。为什么?这就要从bp算法开始说了
0x02 卷积层误差传递
首先举个例子
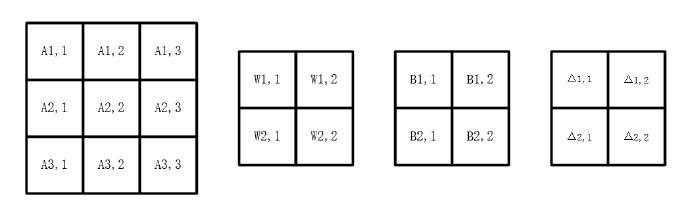
我们假设输入是A,卷积核是W,输出是C,激活函数是f,偏向是B,我们可以知道
-
o u t = W ∗ A + B out=W*A+B out=W∗A+B
-
C = f ( o u t ) C=f(out) C=f(out)
我们假设损失函数是L,那么可以计算出误差项 Δ \Delta Δ
- Δ = ∂ L ∂ o u t \Delta=\frac{∂L}{∂out} Δ=∂out∂L
好的现在我们要求解l-1层的 Δ \Delta Δ
- Δ l − 1 = ∂ L ∂ o u t l − 1 = ∂ L ∂ C l − 1 ∂ C l − 1 ∂ o u t l − 1 = ∂ L ∂ C l − 1 f ′ ( o u t l − 1 ) \Delta^{l-1}=\frac{∂L}{∂out^{l-1}}=\frac{∂L}{∂C^{l-1}}\frac{∂C^{l-1}}{∂out^{l-1}}=\frac{∂L}{∂C^{l-1}}f^\prime(out^{l-1}) Δl−1=∂outl−1∂L=∂Cl−1∂L∂outl−1∂Cl−1=∂Cl−1∂Lf′(outl−1)
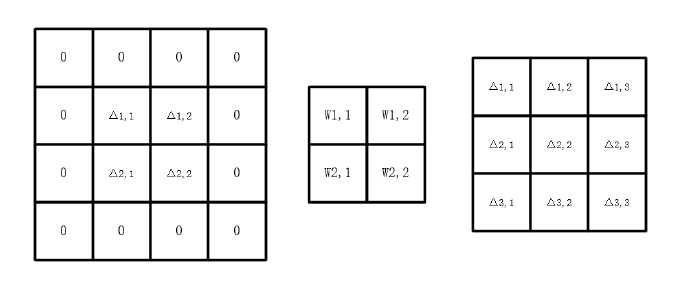
由上面这个图不难看出
- ∂ L ∂ C l − 1 = Δ l ∗ W \frac{∂L}{∂C^{l-1}}=\Delta^l*W ∂Cl−1∂L=Δl∗W
所以
- Δ l − 1 = Δ l ∗ W ∘ f ′ ( o u t l − 1 ) \Delta^{l-1}=\Delta^l*W\circ f^\prime(out^{l-1}) Δl−1=Δl∗W∘f′(outl−1)
回到backward_convolutional_layer这个函数
//backward_convolutional_layer col2im_cpu(net.workspace, l.c/l.groups, l.h, l.w, l.size, l.stride, l.pad, net.delta + (i*l.groups + j)*l.c/l.groups*l.h*l.w);
最后这个函数col2im_cpu的作用就是将net.workspace重排,类似于(三)中的im2col_cpu,只是这里反过来了。
0x03 update_convolutional_layer
void update_convolutional_layer(convolutional_layer l, update_args a){ float learning_rate = a.learning_rate*l.learning_rate_scale; float momentum = a.momentum; float decay = a.decay; int batch = a.batch; axpy_cpu(l.n, learning_rate/batch, l.bias_updates, 1, l.biases, 1); scal_cpu(l.n, momentum, l.bias_updates, 1); if(l.scales){ axpy_cpu(l.n, learning_rate/batch, l.scale_updates, 1, l.scales, 1); scal_cpu(l.n, momentum, l.scale_updates, 1); } axpy_cpu(l.nweights, -decay*batch, l.weights, 1, l.weight_updates, 1); axpy_cpu(l.nweights, learning_rate/batch, l.weight_updates, 1, l.weights, 1); scal_cpu(l.nweights, momentum, l.weight_updates, 1);} 这个函数很容易理解了,就是用来更新网络参数的。其中axpy_cpu和scal_cpu这两个函数我在(三)中也讲过。
至此这三个重要的函数就分析完了,下一章我们会回到make_convolutional_layer函数
文章全部
由于本人水平有限,文中有不对之处,希望大家指出,谢谢_!
转载地址:https://coordinate.blog.csdn.net/article/details/78865475 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
