Auto-Encoder&VAE_完整代码_CodingPark编程公园


 ⚠️ ELBO-证据下界 代码中有体现
⚠️ ELBO-证据下界 代码中有体现 

发布日期:2021-06-29 15:46:38
浏览次数:2
分类:技术文章
本文共 5845 字,大约阅读时间需要 19 分钟。
Autoencoder 的基本概念
机器学习中包含监督学习和非监督学习,其中非监督学习简单来说就是学习人类没有标记过的数据。
对于没有标记的数据最常见的应用就是通过聚类(Clustering)的方式将数据进行分类。对于这些数据来说通常有非常多的维度或者说Features。如何降低这些数据的维度或者说“压缩”数据,从而减轻模型学习的负担,我们就要用到Autoencoder了。
用Autoencoder 给数据“压缩”和降维不仅能够给机器“减压”,同时也有利于数据的可视化。 Autoencoder 实际上跟普通的神经网络没有什么本质的区别,分为输入层,隐藏层和输出层。唯一比较特殊的是,输入层的输入feature的数量(也就是神经元的数量)要等于输出层。同时要保证输入和输出相等。 结构大概如图所示 ae.py
import torchvisionimport torchfrom torch import nnclass AE(nn.Module): def __init__(self): super(AE, self).__init__() # [b, 784] => [b, 20] self.encoder = nn.Sequential( nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 64), nn.ReLU(), nn.Linear(64, 20), nn.ReLU() ) # [b, 20] => [b, 784] self.decoder = nn.Sequential( nn.Linear(20, 64), nn.ReLU(), nn.Linear(64, 256), nn.ReLU(), nn.Linear(256, 784), nn.Sigmoid() ) def forward(self, x): # param x: [b, 1, 28, 28] batchsz = x.size(0) x = x.view(batchsz, 784) x = self.encoder(x) x = self.decoder(x) x = x.view(batchsz, 1, 28, 28) return x, None
main_ae.py
import torchfrom torch.utils.data import DataLoaderfrom torch import nn, optimfrom torchvision import transforms, datasetsfrom ae import AEimport visdomdef main(): mnist_train = datasets.MNIST('mnist_data', train=True, transform=transforms.Compose([ transforms.ToTensor() ]), download=True) mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True) mnist_test = datasets.MNIST('mnist_data', train=False, transform=transforms.Compose([ transforms.ToTensor() ]), download=True) mnist_test = DataLoader(mnist_test, batch_size=32, shuffle=True) x, _ = next(iter(mnist_train)) print('x:', x.shape) # 训练 model = AE() criteon = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=1e-3) viz = visdom.Visdom() print(model) for epoch in range(1000): for batchid, (x, _) in enumerate(mnist_train): x_hat, kld = model(x) loss = criteon(x_hat, x) optimizer.zero_grad() loss.backward() optimizer.step() print(epoch, 'loss', loss.item()) x, _ = next(iter(mnist_test)) print('好奇next(iter(mnist_test)) 后的x什么样子 print x: ', x) # 看来 next(iter(mnist_test)) 是一下都装完呀 with torch.no_grad(): x_hat, kld = model(x) viz.images(x, nrow=8, win='x', opts=dict(title='x')) viz.images(x_hat, nrow=8, win='x_hat', opts=dict(title='x_hat'))if __name__ == '__main__': main() 结果展示
VAE 的基本概念
KL divergence所表达的就是如果我们用一套最优的压缩机制(compression scheme)来储存Q的分布
相对熵,又称 KL散度( Kullback–Leibler divergence),是描述两个概率分布P和Q差异的一种方法。它是非对称的,这意味着D(P||Q) ≠ D(Q||P)。
所谓KL散度,是指当某分布q(x)被用于近似p(x)时的信息损失。
也就是说,q(x)能在多大程度上表达p(x)所包含的信息,KL散度越大,表达效果越差。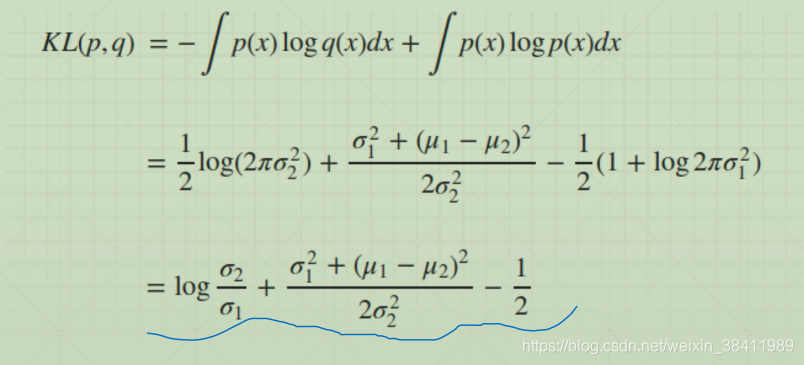
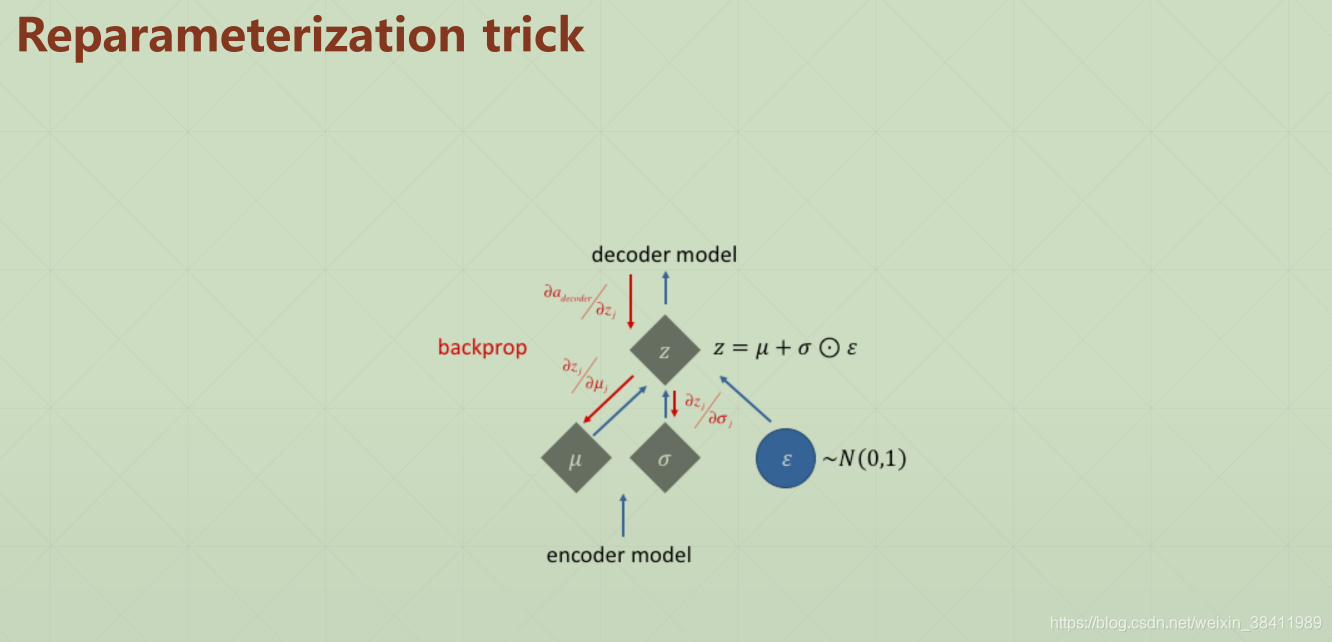
⚠️ ELBO-证据下界 代码中有体现 vae.py
import torchvisionimport torchfrom torch import nnclass VAE(nn.Module): def __init__(self): super(VAE, self).__init__() # [b, 784] => [b, 20] self.encoder = nn.Sequential( nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 64), nn.ReLU(), nn.Linear(64, 20), nn.ReLU() ) # [b, 20] => [b, 784] self.decoder = nn.Sequential( nn.Linear(10, 64), nn.ReLU(), nn.Linear(64, 256), nn.ReLU(), nn.Linear(256, 784), nn.Sigmoid() ) def forward(self, x): # param x: [b, 1, 28, 28] batchsz = x.size(0) # flatten x = x.view(batchsz, 784) # encoder h_ = self.encoder(x) # [b, 20], including mean and sigma mu, sigma = h_.chunk(2, dim=1) # 把encoder后的东西 拆分,[b, 20] => [b, 10] and [b, 10] h = mu + sigma * torch.randn_like(sigma) # reparametrize trick, epison~N(0, 1) # decoder x_hat = self.decoder(h) # reshape x_hat = x_hat.view(batchsz, 1, 28, 28) kld = 0.5 * torch.sum( torch.pow(mu, 2) + torch.pow(sigma, 2) - torch.log(1e-8 + torch.pow(sigma, 2)) - 1 ) / (batchsz * 28 * 28) return x_hat, kld
main_vae.py
import torchfrom torch.utils.data import DataLoaderfrom torch import nn, optimfrom torchvision import transforms, datasets# from ae import AEfrom vae import VAEimport visdomdef main(): mnist_train = datasets.MNIST('mnist_data', train=True, transform=transforms.Compose([ transforms.ToTensor() ]), download=True) mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True) mnist_test = datasets.MNIST('mnist_data', train=False, transform=transforms.Compose([ transforms.ToTensor() ]), download=True) mnist_test = DataLoader(mnist_test, batch_size=32, shuffle=True) x, _ = next(iter(mnist_train)) print('x:', x.shape) # 训练 # model = AE() model = VAE() criteon = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=1e-3) viz = visdom.Visdom() print(model) for epoch in range(1000): for batchid, (x, _) in enumerate(mnist_train): x_hat, kld = model(x) loss = criteon(x_hat, x) if kld is not None: elbo = - loss - 1.0 * kld loss = - elbo optimizer.zero_grad() loss.backward() optimizer.step() print(epoch, 'loss', loss.item(), kld.item()) x, _ = next(iter(mnist_test)) # print('好奇next(iter(mnist_test)) 后的x什么样子 print x: ', x) # 看来 next(iter(mnist_test)) 是一下都装完呀 with torch.no_grad(): x_hat, kld = model(x) viz.images(x, nrow=8, win='x', opts=dict(title='x')) viz.images(x_hat, nrow=8, win='x_hat', opts=dict(title='x_hat'))if __name__ == '__main__': main() 结果展示
👨🏻🔬👩🏻🔬博士说

转载地址:https://codingpark.blog.csdn.net/article/details/106351427 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年04月06日 01时38分35秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
jstl标签详解
2019-04-29
Eclipse中使用SVN的使用
2019-04-29
JSON.parse和eval的区别
2019-04-29
JQuery中$.ajax()方法参数详解
2019-04-29
正则表达式的数字实例
2019-04-29
【转】EasyUI 验证
2019-04-29
Django项目实战---搜索引擎Elasticsearch
2019-04-29
Django实战----页面静态化
2019-04-29
Django实战---商城购物车的增删改、显示和合并购物车
2019-04-29
Django项目实战----订单页面的显示和生成订单、提交订单的逻辑
2019-04-29
Django项目实战----生成订单时高并发问题使用乐观锁
2019-04-29
Django项目实战----添加支付宝支付
2019-04-29
DRF框架---前言(简单使用)
2019-04-29
字符串外面是b“ “的转换 -亲测有效
2019-04-29
单通道和多通道卷积
2019-04-29
npy文件和pkl文件的保存和读取
2019-04-29
middle-判断二分图-深度优先和广度优先
2019-04-29
买卖股票的最佳时机
2019-04-29
AUC粗浅理解笔记记录
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309993465 位访客
访问时间: 2024-05-02 11:14:35
访问IP: 18.224.33.107
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版