本文共 15840 字,大约阅读时间需要 52 分钟。
机器学习算法之多项式回归
目录:
- 1.多项式回归简介
- 2.编程实验多项式回归
- 3.过拟合和欠拟合
- 4.学习曲线
- 5.验证数据集与交叉验证
- 6.偏差方差均衡
- 7.模型正则化
一、多项式回归简介
考虑下面的数据,虽然我们可以使用线性回归来拟合这些数据,但是这些数据更像是一条二次曲线,相应的方程是y=ax2+bx+c,这个式子虽然可以理解为二次方程,但是我们呢可以从另外一个角度来理解这个式子:
如果将x2理解为一个特征,将x理解为另外一个特征,换句话说,本来我们的样本只有一个特征x,现在我们把他看成有两个特征的一个数据集。多了一个特征x2,那么从这个角度来看,这个式子依旧是一个线性回归的式子,但是从x的角度来看,他就是一个二次的方程

多项式回归:相当于为样本添加了一些特征,这些特征是原来样本的多项式项,增加了这些特征之后,我们可以使用线性回归的思路更好的拟合我们的数据。
二、编程实验多项式回归
1.模拟多项式回归的数据集
import numpy as npimport matplotlib.pyplot as plt%matplotlib inlinex = np.random.uniform(-3,3,size=100)X = x.reshape(-1,1)y = 0.5*x**2 + x + 2+np.random.normal(0,1,size=100)plt.scatter(x,y)
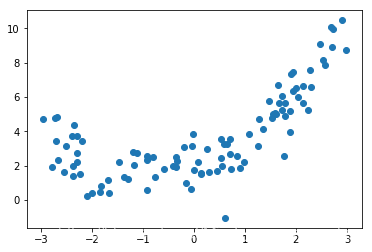
2.使用线性回归拟合数据
from sklearn.linear_model import LinearRegressionlin_reg = LinearRegression()lin_reg.fit(X,y)y_predict = lin_reg.predict(X)plt.scatter(x,y)plt.plot(X,y_predict,color="r")
[]
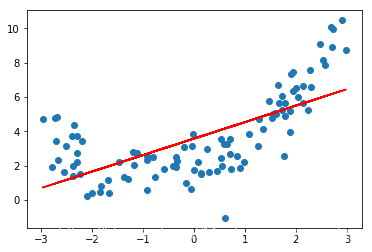
很明显,用一条直线来拟合有弧度的曲线,效果是不好的。
3.解决方案,添加一个特征
原来的数据都在X中,现在对X中每一个数据都进行平方
再将得到的数据集与原数据集进行拼接
再用新的数据集进行线性回归
(X**2).shape
(100, 1)
X2 = np.hstack([X,X**2])
lin_reg2 = LinearRegression()lin_reg2.fit(X2,y)y_predict2 = lin_reg2.predict(X2)plt.scatter(x,y)plt.plot(np.sort(x),y_predict2[np.argsort(x)],color="r")
[]
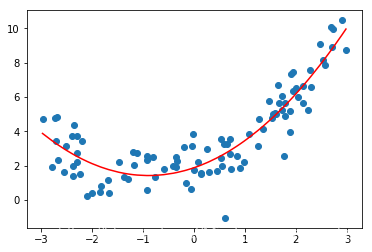
总之:
多项式回归在机器学习算法上并没有新的地方,完全是使用线性回归的思路
它的关键在于为原来的样本,添加新的特征,而我们得到新的特征的方式在在原有特征的多项式的组合。
采用这样的方式,我们就可以解决一些非线性的问题。
与此同时需要注意,PCA是对我们的数据机芯降维处理,而多项式回归是让数据升维,在升维之后使得算法可以更好的拟合高纬度的数据
4.sklearn中的多项式回归
# 数据进行处理from sklearn.preprocessing import PolynomialFeaturespoly = PolynomialFeatures()poly.fit(X)X3 = poly.transform(X)X3[:5]
array([[ 1. , 2.4708992 , 6.10534284], [ 1. , -1.28689158, 1.65608995], [ 1. , 0.70399937, 0.49561511], [ 1. , -0.91605936, 0.83916474], [ 1. , 1.36063097, 1.85131664]])
# 调用LinearRegression对X2进行预测lin_reg3 = LinearRegression()lin_reg3.fit(X3,y)y_predict3 = lin_reg3.predict(X3)plt.scatter(x,y)plt.plot(np.sort(x),y_predict3[np.argsort(x)],color="r")
[]
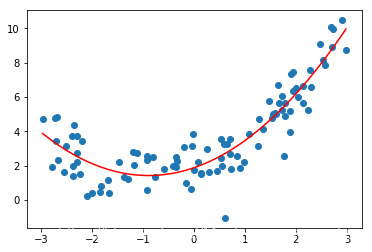
5.使用Pipline来实现多项式回归的过程
pipline的英文名字是管道,那么如何使用管道呢,先考虑我们的多项式回归的过程
- 1.使用
PolynomialFeatures生成多项式特征的数据集 - 2.如果生成数据幂特别的大,那么特征之间的差距就会很大,导致我们的搜索非常慢,这时候就需要
数据归一化 - 3.进行线性回归
pipline的作用就是把上面的三个步骤合并,使得我们不用一直重复这三步
# 准备数据x = np.random.uniform(-3,3,size=100)X = x.reshape(-1,1)y = 0.5*x**2 + x + 2+np.random.normal(0,1,size=100)
# piplinefrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.preprocessing import StandardScalerfrom sklearn.pipeline import Pipeline# 传入每一步的对象名和类的实例化poly_reg = Pipeline([ ("poly",PolynomialFeatures(degree=2)), ("std_scaler",StandardScaler()), ("lin_reg",LinearRegression())]) # 预测及绘图展示poly_reg.fit(X,y)y_predict = poly_reg.predict(X)plt.scatter(x,y)plt.plot(np.sort(x),y_predict[np.argsort(x)],color="r")
[]
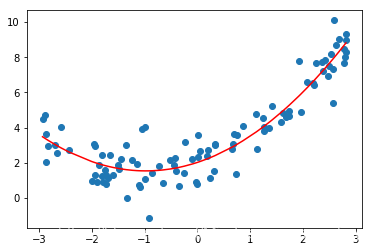
三、过拟合和欠拟合
1.什么是过拟合和欠拟合
# 数据准备import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegressionx = np.random.uniform(-3,3,size=100)X = x.reshape(-1,1)y = 0.5*x**2 + x + 2+np.random.normal(0,1,size=100)
a.线性回归
lin_reg = LinearRegression()lin_reg.fit(X,y)y_predict = lin_reg.predict(X)plt.scatter(x,y)plt.plot(X,y_predict,color='r')
[]
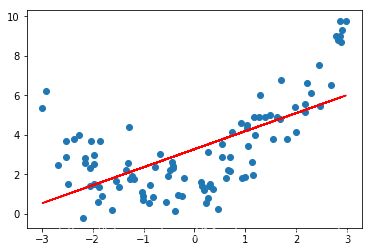
from sklearn.metrics import mean_squared_errory_predict = lin_reg.predict(X)mean_squared_error(y,y_predict)
3.3341226155406303
2.使用多项式回归
# 使用Pipeline构建多项式回归def PolynomialRegression(degree): poly_reg = Pipeline([ ('poly',PolynomialFeatures(degree=degree)), ('std_scaler',StandardScaler()), ('lin_reg',LinearRegression()) ]) return poly_regpoly_reg2 = PolynomialRegression(2)poly_reg2.fit(X,y)y2_predict = poly_reg2.predict(X)# 显然使用多项式回归得到的结果是更好的mean_squared_error(y,y2_predict) 1.111897309325084
plt.scatter(x,y)plt.plot(np.sort(x),y2_predict[np.argsort(x)],color='r')
[]
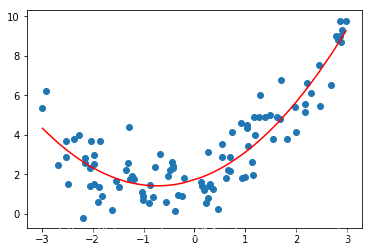
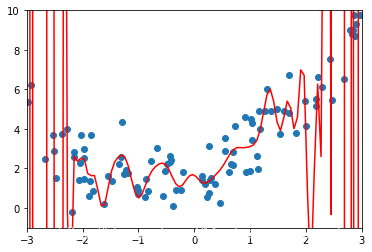
3.使用更高的维度进行多项式回归
a.使用10个维度
# 使用10个维度poly_reg10 = PolynomialRegression(10)poly_reg10.fit(X,y)y10_predict = poly_reg10.predict(X)mean_squared_error(y,y10_predict)
0.9427318831233271
plt.scatter(x,y)plt.plot(np.sort(x),y10_predict[np.argsort(x)],color='r')
[]
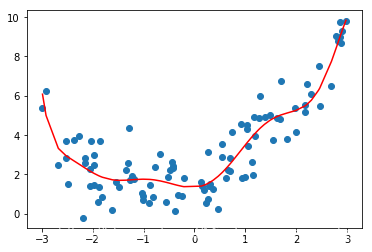
b.使用100个维度
poly_reg100 = PolynomialRegression(100)poly_reg100.fit(X,y)y100_predict = poly_reg100.predict(X)# 显然使用多项式回归得到的结果是更好的mean_squared_error(y,y100_predict)
0.5566399955159339
plt.scatter(x,y)plt.plot(np.sort(x),y100_predict[np.argsort(x)],color='r')
[]
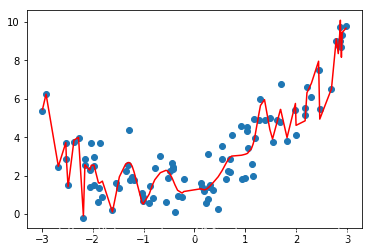
X_plot = np.linspace(-3,3,100).reshape(100,1)y_plot = poly_reg100.predict(X_plot)plt.scatter(x,y)plt.plot(X_plot,y_plot,color='r')plt.axis([-3 , 3 , -1,10 ])
[-3, 3, -1, 10]
总结
degree从2到10到100的过程中,虽然均方误差是越来越小的,从均方误差的角度来看是更加小的
但是他真的能更好的预测我们数据的走势吗,例如我们选择2.5到3的一个x,使用上图预测出来的y的大小(0或者-1之间)显然不符合我们的数据- 换句话说,我们使用了一个非常高的数据,虽然使得我们的样本点获得了更小的误差,但是这条曲线完全不是我们想要的样子,它为了拟合我们所有的样本点,变得太过于复杂了,这种情况就是
过拟合 - 相反,在最开始,我们直接使用一根直线来拟合我们的数据,也没有很好的拟合我们的样本特征,当然它犯的错误不是太过于复杂,而是太过简单,这种情况就是
欠拟合。

对于上述这样的一个图,会有两条曲线:
- 一个是对于训练数据集来说的,模型越复杂,模型准确率越高,因为模型越复杂,对训练数据集的拟合就越好,相应的模型准确率就越高
- 对于测试数据集来说,在模型很简单的时候,模型的准确率也比较低,随着模型逐渐变复杂,对测试数据集的准确率在逐渐的提升,提升到一定程度后,如果模型继续变复杂,那么我们的模型准确率将会进行下降(欠拟合->正合适->过拟合)
欠拟合和过拟合的标准定义
- 欠拟合:算法所训练的模型不能完整表述数据关系
- 过拟合:算法所训练的模型过多的表达了数据间的噪音关系
四、学习曲线
1.什么是学习曲线
随着训练样本的逐渐增大,算法训练出的模型的表现能力
import numpy as npimport matplotlib.pyplot as pltnp.random.seed(666)x = np.random.uniform(-3,3,size=100)X = x.reshape(-1,1)y = 0.5 * x**2 + x + 2 + np.random.normal(0,1,size=100)plt.scatter(x,y)
2.实际编程实现学习曲线
from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(X,y,random_state=10)print(X_train.shape,type(X_train))print(X_test.shape,type(X_test))print(y_train.shape,type(y_train))print(y_test.shape,type(y_test))
(75, 1)(25, 1) (75,) (25,)
a.观察线性回归的学习曲线
观察线性回归的模型,随着训练数据集增加,性能的变化
from sklearn.linear_model import LinearRegressionfrom sklearn.metrics import mean_squared_errordef plot_learning_curve(algo,X_train,X_test,y_train,y_test): train_score = [] test_score = [] # 计算学习曲线数据 for i in range(1,len(X_train)+1): algo.fit(X_train[:i],y_train[:i]) y_train_predict = algo.predict(X_train[:i]) train_score.append(mean_squared_error(y_train[:i],y_train_predict)) y_test_predict = algo.predict(X_test) test_score.append(mean_squared_error(y_test,y_test_predict)) # 绘制学习曲线 plt.plot([i for i in range(1,len(X_train)+1)],np.sqrt(train_score),label = 'train') plt.plot([i for i in range(1,len(X_train)+1)],np.sqrt(test_score),label = 'test') plt.axis([0,len(X_train)+1,0,4]) plt.legend() plot_learning_curve(LinearRegression(),X_train,X_test,y_train,y_test)
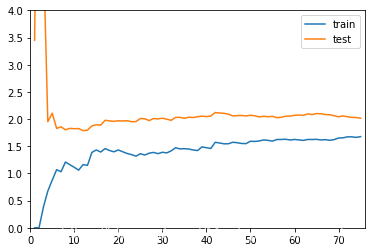
从趋势上看:
- 在训练数据集上,误差是逐渐升高的。这是因为我们的训练数据越来越多,我们的数据点越难得到全部的累积,不过整体而言,在刚开始的时候误差变化的比较快,后来就几乎不变了
- 在测试数据集上,在使用非常少的样本进行训练的时候,刚开始我们的测试误差非常的大,当训练样本大到一定程度以后,我们的测试误差就会逐渐减小,减小到一定程度后,也不会小太多,达到一种相对稳定的情况
- 在最终,测试误差和训练误差趋于相等,不过测试误差还是高于训练误差一些,这是因为,训练数据在数据非常多的情况下,可以将数据拟合的比较好,误差小一些,但是泛化到测试数据集的时候,还是有可能多一些误差
b.观察多项式回归的学习曲线
from sklearn.preprocessing import StandardScalerfrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.pipeline import Pipeline# 使用Pipline构建多项式回归模型def PolynomialRegression(degree): return Pipeline([ ("poly",PolynomialFeatures(degree=degree)), ("std_scaler",StandardScaler()), ("lin_reg",LinearRegression()) ])# 使用二阶多项式回归poly2_reg = PolynomialRegression(2)plot_learning_curve(poly2_reg,X_train,X_test,y_train,y_test) 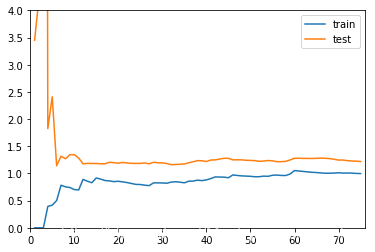
首先整体从趋势上,和线性回归的学习曲线是类似的
仔细观察,和线性回归曲线的不同在于,线性回归的学习曲线1.5,1.8左右;2阶多项式回归稳定在了1.0,0.9左右,2阶多项式稳定的误差比较低,说明使用二阶线性回归的性能是比较好的
# 使用20阶多项式回归poly20_reg = PolynomialRegression(20)plot_learning_curve(poly20_reg,X_train,X_test,y_train,y_test)
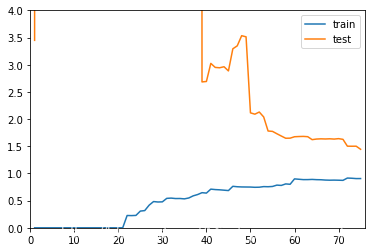
在使用20阶多项式回归训练模型的时候可以发现,在数据量偏多的时候,我们的训练数据集拟合的是比较好的,但是测试数据集的误差相对来说增大了很多,离训练数据集比较远,通常这就是过拟合的结果,他的泛化能力是不够的
五、验证数据集与交叉验证
使用分割训练数据集合测试数据集来判断我们的机器学习性能的好坏,虽然是一个非常好的方案,但是会产生一个问题:针对特定测试数据集过拟合
我们每次使用测试数据来分析性能的好坏,一旦发现结果不好,我们就换一个参数(可能是degree也可能是其他超参数)重新进行训练。这种情况下,我们的模型在一定程度上围绕着测试数据集打转。也就是说我们在寻找一组参数,使得这组参数训练出来的模型在测试结果集上表现的最好。但是由于这组测试数据集是已知的,我们相当于在针对这组测试数据集进行调参,那么他也有可能产生过拟合的情况,也就是我们得到的模型针对测试数据集过拟合了
那么怎么解决这个问题呢?
解决的方式就是:我们需要将我们的数据集分为三部分,这三部分分别是训练数据集,验证数据集,测试数据集。
我们使用训练数据集训练好模型之后,将验证数据集送给这个模型,看看这个训练数据集训练的效果是怎么样的,如果效果不好,我们重新换参数,重新训练模型,直到我们的模型针对验证数据集已经达到最优。
这样我们的模型达到最优之后,再将测试数据集送给模型,这样才能作为衡量模型最终的性能。
换句话说我们的测试数据集是不参与模型的创建的,而其他两个数据集都参与了训练。但是我们的测试数据集对于模型是完全不可知的,相当于我们在模型这个模型完全不知道的数据

这种方法还会有一个问题。由于我们的模型可能会针对验证数据集过拟合,而我们只有一份验证数据集,一旦我们的数据集里有比较极端的情况,那么模型的性能就会下降很多,那么为了解决这个问题,就有了交叉验证。
1.交叉验证
交叉验证相对来说是比较正规的、比较标准的在我们调整我们的模型参数的时候看我们的性能的方式
交叉验证:在训练模型的时候,通常把数据分成k份,例如分成3份(ABC)(分成k分,k属于超参数),这三份分别作为验证数据集和训练数据集。这样组合后可以分别产生三个模型,这三个模型,每个模型在测试数据集上都会产生一个性能的指标,这三个指标的平均值作为当前这个算法训练处的模型衡量的标准是怎样的。
由于我们有一个求平均的过程,所以不会由于一份验证数据集中有比较极端的数据而导致模型有过大的偏差,这比我们只分成训练、验证、测试数据集要更加准确
2.编程实现
import numpy as npfrom sklearn import datasets
digits = datasets.load_digits()X = digits.datay = digits.target
from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state =666)
from sklearn.neighbors import KNeighborsClassifierbest_score,best_k,best_p = 0,0,0# k为k近邻中的寻找k个最近元素for k in range(2,10): # p为明科夫斯基距离的p for p in range(1,5): knn_clf = KNeighborsClassifier(weights='distance',n_neighbors=k,p=p) knn_clf.fit(X_train,y_train) score = knn_clf.score(X_test,y_test) if score > best_score: best_score,best_k,best_p = score,k,pprint("Best_score = ",best_score)print("Best_k = ",best_k)print("Best_p = ",best_p) Best_score = 0.9860917941585535Best_k = 3Best_p = 4
3.交叉验证
# 使用sklearn提供的交叉验证from sklearn.model_selection import cross_val_score# 使用交叉验证的方式来进行调参的过程best_score,best_k,best_p = 0,0,0# k为k近邻中的寻找k个最近元素for k in range(2,10): # p为明科夫斯基距离的p for p in range(1,5): knn_clf = KNeighborsClassifier(weights='distance',n_neighbors=k,p=p) scores = cross_val_score(knn_clf,X_train,y_train) score = np.mean(scores) if score > best_score: best_score,best_k,best_p = score,k,pprint("Best_score = ",best_score)print("Best_k = ",best_k)print("Best_p = ",best_p) Best_score = 0.9823599874006478Best_k = 2Best_p = 2
通过观察两组调参过程的结果可以发现
- 1.两组调参得出的参数结果是不同的,通常这时候我们更愿意详细使用交叉验证的方式得出的结果。 因为使用train_test_split很有可能只是过拟合了测试数据集得出的结果
- 2.使用交叉验证得出的最好分数0.982是小于使用分割训练测试数据集得出的0.986,因为在交叉验证的 过程中,通常不会过拟合某一组的测试数据,所以平均来讲这个分数会稍微低一些
但是使用交叉验证得到的最好参数Best_score并不是真正的最好的结果,我们使用这种方式只是为了拿到
一组超参数而已,拿到这组超参数后我们就可以训练处我们的最佳模型knn_clf = KNeighborsClassifier(weights='distance',n_neighbors=2,p=2)# 用我们找到的k和p。来对X_train,y_train整体fit一下,来看他对X_test,y_test的测试结果knn_clf.fit(X_train,y_train)# 注意这个X_test,y_test在交叉验证过程中是完全没有用过的,也就是说我们这样得出的结果是可信的knn_clf.score(X_test,y_test)
0.980528511821975
4.网格搜索
我们上面的操作,实际上在网格搜索的过程中已经进行了,只不过这个过程是sklean的网格搜索自带的一个过程
# GridSearchCV里的cv实际上就是交叉验证的方式from sklearn.model_selection import GridSearchCVparam_grid = [{ "weights":['distance'],"n_neighbors":[i for i in range(2,10)],"p":[i for i in range(1,6)]}]knn_clf = KNeighborsClassifier()# cv默认为3,可以修改改参数,修改修改不同分数的数据集grid_search = GridSearchCV(knn_clf,param_grid,verbose=1,cv=3)grid_search.fit(X_train,y_train) Fitting 3 folds for each of 40 candidates, totalling 120 fits[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.[Parallel(n_jobs=1)]: Done 120 out of 120 | elapsed: 1.5min finishedGridSearchCV(cv=3, error_score='raise-deprecating', estimator=KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=None, n_neighbors=5, p=2, weights='uniform'), fit_params=None, iid='warn', n_jobs=None, param_grid=[{'weights': ['distance'], 'n_neighbors': [2, 3, 4, 5, 6, 7, 8, 9], 'p': [1, 2, 3, 4, 5]}], pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=1) grid_search.best_score_# 和我们上面得到的best_score 是吻合的
0.9823747680890538
grid_search.best_params_
{'n_neighbors': 2, 'p': 2, 'weights': 'distance'} best_knn_clf = grid_search.best_estimator_best_knn_clf.fit(X_train,y_train)best_knn_clf.score(X_test,y_test)
0.980528511821975
5.总结

虽然整体速度慢了,但是这个结果却是可信赖的
极端情况下,K-folds cross validation可以叫做留一法
六、偏差方差均衡
模型误差=偏差(Bias)均差(Variance)+不可避免的误差
1.偏差

2.方差
模型没有完全的学到数据的中心,而学习到了噪音。

机器学习的主要调整来源于方差(这是站在算法的角度上,而不是问题的角度上,比如对金融市场的理解,很多人尝试用历史的数据预测未来的金融走势,这样的尝试通常都不太理想。很有可能因为历史的金融趋势不能很好的反应未来的走向,这种预测方法本身带来的非常大的偏差)换句话说,我们很容易让模型变的很复杂,从而降低模型的偏差,但是由于这样的模型的方差非常的大,最终也没有很好的性能。
3.解决高方差的通常手段
- 1.降低模型复杂度
- 2.减少数据维度;降噪;
- 3.增加样本数
- 4.使用验证集
- 5.模型正则化
七、模型正则化
1.模型正则化
下面是我们之前使用多项式回归过拟合一个样本的例子,可以看到这条模型曲线非常的弯曲,而且非常的陡峭,可以想象这条曲线的一些θ系数会非常的大。
模型正则化需要做的事情就是限制这些系数的大小。

2.模型正则化基本原理

3.岭回归Ridge Regression

编程实现岭回归
import numpy as npimport matplotlib.pyplot as plt# 模型样本np.random.seed(42)x = np.random.uniform(-3.0,3.0,size=100)X = x.reshape(-1,1)y = 0.5 * x + 3 + np.random.normal(0,1,size=100)# 绘制样本曲线plt.scatter(x,y)
from sklearn.preprocessing import PolynomialFeaturesfrom sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LinearRegressionfrom sklearn.pipeline import Pipeline# 定义多项式回归函数def PolynomialRegression(degree): return Pipeline([ ("poly",PolynomialFeatures(degree=degree)), ("std_scaler",StandardScaler()), ("lin_reg",LinearRegression()) ]) from sklearn.model_selection import train_test_split# 分割数据集np.random.seed(666)X_train,X_test,y_train,y_test = train_test_split(X,y)
from sklearn.metrics import mean_squared_error# 多项式回归对样本进行训练,使用20个维度poly20_reg = PolynomialRegression(20)poly20_reg.fit(X_train,y_train)y20_predict = poly20_reg.predict(X_test)mean_squared_error(y_test,y20_predict)
167.9401085999025
# 定义绘图模型def plot_module(module): X_plot = np.linspace(-3,3,100).reshape(100,1) y_plot = module.predict(X_plot) plt.scatter(x,y) plt.plot(X_plot[:,0],y_plot,color='r') plt.axis([-3,3,0,6])
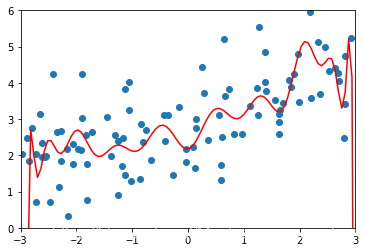
# 绘制模型曲线--过拟合(非常的完全,两段有极端的情况)plot_module(poly20_reg)
from sklearn.linear_model import Ridgedef RidgeRegression(degree,alpha): return Pipeline([ ("poly",PolynomialFeatures(degree=degree)), ("std_scaler",StandardScaler()), ("ridge_reg",Ridge(alpha=alpha)) ]) # 注意alpha后面的参数是所有theta的平方和,而对于多项式回归来说,岭回归之前得到的θ都非常大# 所以为了限制让他们比较小,我们前面系数可以取的小一些ridge1_reg = RidgeRegression(degree=20,alpha=0.00001)ridge1_reg.fit(X_train,y_train)ridge1_predict = ridge1_reg.predict(X_test)mean_squared_error(y_test,ridge1_predict)
1.3874378026530747
# 通过使用岭回归,使得我们的均方误差小了非常多,曲线也缓和了非常多plot_module(ridge1_reg)
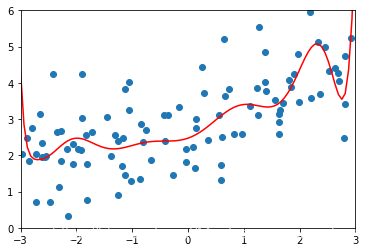
ridge2_reg = RidgeRegression(degree=20,alpha=1)ridge2_reg.fit(X_train,y_train)ridge2_predict = ridge2_reg.predict(X_test)mean_squared_error(y_test,ridge2_predict)
1.1888759304218461
# 让ridge2_reg 的alpha值等于1,均差误差更加的缩小,并且曲线越来越趋近于一根倾斜的直线plot_module(ridge2_reg)
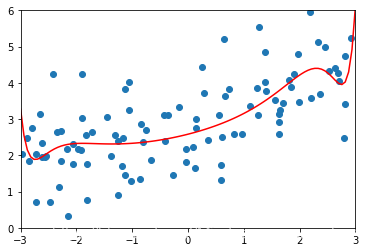
ridge3_reg = RidgeRegression(degree=20,alpha=100)ridge3_reg.fit(X_train,y_train)ridge3_predict = ridge3_reg.predict(X_test)mean_squared_error(y_test,ridge3_predict)
1.3196456113086197
# 得到的误差依然是比较小,但是比之前的1.18大了些,说明正则化做的有些过头了plot_module(ridge3_reg)
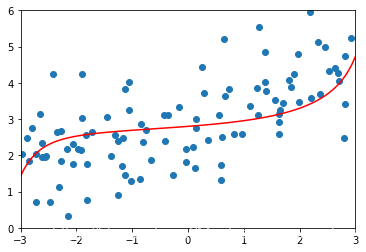
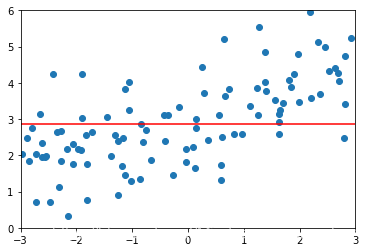
ridge4_reg = RidgeRegression(degree=20,alpha=100000)ridge4_reg.fit(X_train,y_train)ridge4_predict = ridge4_reg.predict(X_test)mean_squared_error(y_test,ridge4_predict)# 当alpha非常大,我们的模型实际上相当于就是在优化θ的平方和这一项,使得其最小(因为MSE的部分相对非常小)# 而使得θ的平方和最小,就是使得每一个θ都趋近于0,这个时候曲线就趋近于一根直线了plot_module(ridge4_reg)
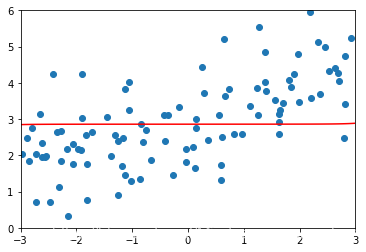
4.LASSO

编程实现LASSO
import numpy as npimport matplotlib.pyplot as plt# 模型样本np.random.seed(42)x = np.random.uniform(-3.0,3.0,size=100)X = x.reshape(-1,1)y = 0.5 * x + 3 + np.random.normal(0,1,size=100)# 绘制样本曲线plt.scatter(x,y)
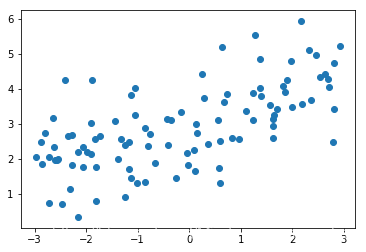
from sklearn.linear_model import Lassodef LassoRegression(degree,alpha): return Pipeline([ ("poly",PolynomialFeatures(degree=degree)), ("std_scatter",StandardScaler()), ("lasso_reg",Lasso(alpha=alpha)) ]) # 这里的alpha起始值比岭回归的时候大了很多,是由于现在是绝对值lasso1_reg = LassoRegression(degree=20,alpha=0.01)lasso1_reg.fit(X_train,y_train)lasso1_predict = lasso1_reg.predict(X_test)mean_squared_error(lasso1_predict,y_test)
1.149608084325997
plot_module(lasso1_reg)
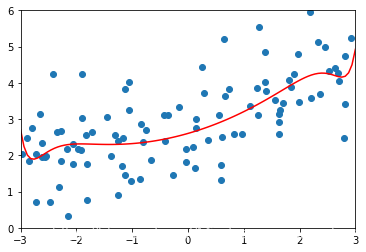
# 增大alpha继续试验lasso2_reg = LassoRegression(degree=20,alpha=0.1)lasso2_reg.fit(X_train,y_train)lasso2_predict = lasso2_reg.predict(X_test)mean_squared_error(lasso2_predict,y_test)
1.1213911351818648
# 非常接近一根直线plot_module(lasso2_reg)
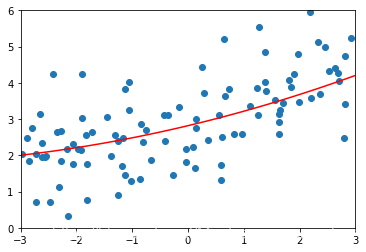
# 增大alpha继续试验lasso3_reg = LassoRegression(degree=20,alpha=1)lasso3_reg.fit(X_train,y_train)lasso3_predict = lasso3_reg.predict(X_test)mean_squared_error(lasso3_predict,y_test)
1.8408939659515595
# alpha=1的时候正则化已经过头了plot_module(lasso3_reg)
5.总结


转载地址:https://codingchaozhang.blog.csdn.net/article/details/90145322 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
