15 Python总结之数据分析与挖掘
发布日期:2021-06-29 15:45:09
浏览次数:2
分类:技术文章
本文共 11109 字,大约阅读时间需要 37 分钟。
数据分析实例之2012美国联邦选举委员会
美国联邦选举委员会发布了有关政治竞选赞助方面的数据。其中包括赞助者的姓名、职业、雇主、地址以及出资额等信息。
这个数据集中一些特征:
contbr_employer:捐款雇主cand_nm:候选人contbr_occupation:捐款人职业contb_receipt_amt:捐款金额
1 前期准备
1.1 使用pandas.read_csv载入数据
import pandas as pdimport matplotlib.pyplot as pltimport numpy as npfec = pd.read_csv('./P00000001-ALL.csv') #加载数据print(fec.info()) RangeIndex: 1001731 entries, 0 to 1001730Data columns (total 16 columns):cmte_id 1001731 non-null objectcand_id 1001731 non-null objectcand_nm 1001731 non-null objectcontbr_nm 1001731 non-null objectcontbr_city 1001712 non-null objectcontbr_st 1001727 non-null objectcontbr_zip 1001620 non-null objectcontbr_employer 988002 non-null objectcontbr_occupation 993301 non-null objectcontb_receipt_amt 1001731 non-null float64contb_receipt_dt 1001731 non-null objectreceipt_desc 14166 non-null objectmemo_cd 92482 non-null objectmemo_text 97770 non-null objectform_tp 1001731 non-null objectfile_num 1001731 non-null int64dtypes: float64(1), int64(1), object(14)memory usage: 122.3+ MBNone
1.2 观察样本记录
print(fec.iloc[123456])
cmte_id C00431445cand_id P80003338cand_nm Obama, Barackcontbr_nm ELLMAN, IRAcontbr_city TEMPEcontbr_st AZcontbr_zip 852816719contbr_employer ARIZONA STATE UNIVERSITYcontbr_occupation PROFESSORcontb_receipt_amt 50contb_receipt_dt 01-DEC-11receipt_desc NaNmemo_cd NaNmemo_text NaNform_tp SA17Afile_num 772372Name: 123456, dtype: object
1.3 使用unique获得所有不同的政治候选人名单
unique_cands = fec.cand_nm.unique() #使用unique获得所有不同的政治候选人名单unique_cands
array(['Bachmann, Michelle', 'Romney, Mitt', 'Obama, Barack', "Roemer, Charles E. 'Buddy' III", 'Pawlenty, Timothy', 'Johnson, Gary Earl', 'Paul, Ron', 'Santorum, Rick', 'Cain, Herman', 'Gingrich, Newt', 'McCotter, Thaddeus G', 'Huntsman, Jon', 'Perry, Rick'], dtype=object)
unique_cands[2]
'Obama, Barack'
1.4 使用相应的字典表示政党背景
parties = { 'Bachmann, Michelle':'Republican', 'Cain, Herman':'Republican', 'Gingrich, Newt':'Republican', 'Huntsman, Jon':'Republican', 'John, Gary Earl':'Republican', 'McCotter, Thaddeus G':'Republican', 'Obama, Barack':'Democrat', 'Paul, Ron':'Republican', 'Pawlenty, Timothy':'Republican', 'Perry, Rick':'Republican', "Roemer, Charles E. 'Buddy' III":'Republican', 'Romney, Mitt':'Republican', 'Santorum, Rick':'Republican'} #表示政党背景的方式之一是使用相应的字典 1.5 在Series对象中使用map方法和上述的映射关系,从候选人姓名中计算出政党的数组
fec.cand_nm[123456:123461]
123456 Obama, Barack123457 Obama, Barack123458 Obama, Barack123459 Obama, Barack123460 Obama, BarackName: cand_nm, dtype: object
fec.cand_nm[123456:123461].map(parties)
123456 Democrat123457 Democrat123458 Democrat123459 Democrat123460 DemocratName: cand_nm, dtype: object
# 将其作为一列加入fec["party"] = fec.cand_nm.map(parties)fec["party"].value_counts()
Democrat 589127Republican 401114Name: party, dtype: int64
1.6 数据准备要点
(fec.contb_receipt_amt > 0).value_counts()
True 991475Name: contb_receipt_amt, dtype: int64
# 分析范围限制在正向贡献中fec = fec[fec.contb_receipt_amt > 0]
# 为主要候选人准备一个仅对他们的竞选有贡献的子集fec_mrbo = fec[fec.cand_nm.isin(['Obama, Barack','Romney, Mitt'])]
2 按职业和雇主的捐献统计
根据职业分析捐献是一个常见的统计分析。例如,律师(法律代理人)倾向于捐更多的前给民主党,而企业主则更倾向于资助共和党。
2.1 首先,获得按职业的捐献总数
fec.contbr_occupation.value_counts()[:10]#获得按职业的捐献总数
RETIRED 233990NOT PROVIDED 57151ATTORNEY 34286HOMEMAKER 29931PHYSICIAN 23432ENGINEER 14334TEACHER 13990CONSULTANT 13273PROFESSOR 12555NOT EMPLOYED 9828Name: contbr_occupation, dtype: int64
2.2 通过将一种工作匹配到另一种来清理工作种类
occ_mapping = { 'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED', 'INFORMATION REQUESTED':'NOT PROVIDED', 'INFORMATION REQUESTED (BEST EFFORTS)':'NOT PROVIDED', 'C.E.O':'CEO'}f = lambda x:occ_mapping.get(x,x) #如果没有映射,则返回xfec.contbr_occupation = fec.contbr_occupation.map(f)emp_mapping = { 'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED', 'INFORMATION REQUESTED':'NOT PROVIDED', 'SELF':'SELF-EMPLOYED', 'SELF EMPLOYED':'SELF-EMPLOYED',}f = lambda x:emp_mapping.get(x,x) #如果没有映射,则返回xfec.contbr_employer = fec.contbr_employer.map(f) 2.3 使用pivot_table按党派和职业聚合数据,然后过滤出至少捐赠200万美元的子集
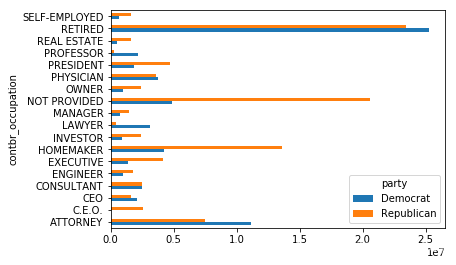
by_occupation = fec.pivot_table('contb_receipt_amt', index = 'contbr_occupation', columns = 'party',aggfunc = 'sum') #按照党派和职业聚合数据over_2mm = by_occupation[by_occupation.sum(1) > 2000000] #过滤出至少捐赠200万美元的子集over_2mm | party | Democrat | Republican |
|---|---|---|
| contbr_occupation | ||
| ATTORNEY | 11141982.97 | 7.463819e+06 |
| C.E.O. | 1690.00 | 2.592983e+06 |
| CEO | 2074284.79 | 1.636258e+06 |
| CONSULTANT | 2459912.71 | 2.530255e+06 |
| ENGINEER | 951525.55 | 1.807054e+06 |
| EXECUTIVE | 1355161.05 | 4.126300e+06 |
| HOMEMAKER | 4248875.80 | 1.362706e+07 |
| INVESTOR | 884133.00 | 2.422579e+06 |
| LAWYER | 3160478.87 | 3.903243e+05 |
| MANAGER | 762883.22 | 1.439982e+06 |
| NOT PROVIDED | 4866973.96 | 2.056547e+07 |
| OWNER | 1001567.36 | 2.406537e+06 |
| PHYSICIAN | 3735124.94 | 3.585995e+06 |
| PRESIDENT | 1878509.95 | 4.714024e+06 |
| PROFESSOR | 2165071.08 | 2.967027e+05 |
| REAL ESTATE | 528902.09 | 1.624752e+06 |
| RETIRED | 25305116.38 | 2.342938e+07 |
| SELF-EMPLOYED | 672393.40 | 1.625303e+06 |
2.4 以条形图的方式进行数据可视化更为简单
import matplotlib.pyplot as plt%matplotlib inlinefig = plt.figure()over_2mm.plot(kind="barh")
2.5 按候选人名称进行分组
def get_top_amounts(group,key,n = 5): totals = group.groupby(key)['contb_receipt_amt'].sum() return totals.nlargest(n)
2.6 按职业和雇主进行聚合
grouped = fec_mrbo.groupby('cand_nm')grouped.apply(get_top_amounts,'contbr_occupation',n = 7) #按照职业进行聚合 cand_nm contbr_occupationObama, Barack RETIRED 25305116.38 ATTORNEY 11141982.97 NOT PROVIDED 4866973.96 HOMEMAKER 4248875.80 PHYSICIAN 3735124.94 LAWYER 3160478.87 CONSULTANT 2459912.71Romney, Mitt RETIRED 11508473.59 NOT PROVIDED 11396894.84 HOMEMAKER 8147446.22 ATTORNEY 5364718.82 PRESIDENT 2491244.89 EXECUTIVE 2300947.03 C.E.O. 1968386.11Name: contb_receipt_amt, dtype: float64
grouped.apply(get_top_amounts,"contbr_employer",n=7)
cand_nm contbr_employerObama, Barack RETIRED 22694358.85 SELF-EMPLOYED 18626807.16 NOT EMPLOYED 8586308.70 NOT PROVIDED 5053480.37 HOMEMAKER 2605408.54 STUDENT 318831.45 VOLUNTEER 257104.00Romney, Mitt NOT PROVIDED 12059527.24 RETIRED 11506225.71 HOMEMAKER 8147196.22 SELF-EMPLOYED 7414115.22 STUDENT 496490.94 CREDIT SUISSE 281150.00 MORGAN STANLEY 267266.00Name: contb_receipt_amt, dtype: float64
3 捐赠金额分桶
3.1 使用cut函数将贡献者的数量按贡献大小离散化分桶
bins = np.array([0,1,10,100,1000,10000, 100000,1000000,10000000])labels = pd.cut(fec_mrbo.contb_receipt_amt, bins) #使用cut函数将贡献者的数量按贡献大小离散化分桶labels.head()
411 (10, 100]412 (100, 1000]413 (100, 1000]414 (10, 100]415 (10, 100]Name: contb_receipt_amt, dtype: categoryCategories (8, interval[int64]): [(0, 1] < (1, 10] < (10, 100] < (100, 1000] < (1000, 10000] < (10000, 100000] < (100000, 1000000] < (1000000, 10000000]]
labels.tail()
701381 (10, 100]701382 (100, 1000]701383 (1, 10]701384 (10, 100]701385 (100, 1000]Name: contb_receipt_amt, dtype: categoryCategories (8, interval[int64]): [(0, 1] < (1, 10] < (10, 100] < (100, 1000] < (1000, 10000] < (10000, 100000] < (100000, 1000000] < (1000000, 10000000]]
3.2 将Obama和Romney的数据按名称和分类标签进行分组
grouped = fec_mrbo.groupby(['cand_nm',labels]) #将Obama和Romney的数据按名称和分类标签进行分组,以获得捐赠规模的直方图print(grouped.size().unstack(0))
cand_nm Obama, Barack Romney, Mittcontb_receipt_amt (0, 1] 493.0 77.0(1, 10] 40070.0 3681.0(10, 100] 372280.0 31853.0(100, 1000] 153991.0 43357.0(1000, 10000] 22284.0 26186.0(10000, 100000] 2.0 1.0(100000, 1000000] 3.0 NaN(1000000, 10000000] 4.0 NaN
3.3 对捐款数额进行求和并在桶内进行归一化,以便对按候选人划分的捐款总额百分比进行可视化
bucket_sums = grouped.contb_receipt_amt.sum().unstack(0)normed_sums = bucket_sums.div(bucket_sums.sum(axis = 1),axis = 0) #对捐款数额进行归一化print(normed_sums)
cand_nm Obama, Barack Romney, Mittcontb_receipt_amt (0, 1] 0.805182 0.194818(1, 10] 0.918767 0.081233(10, 100] 0.910769 0.089231(100, 1000] 0.710176 0.289824(1000, 10000] 0.447326 0.552674(10000, 100000] 0.823120 0.176880(100000, 1000000] 1.000000 NaN(1000000, 10000000] 1.000000 NaN
normed_sums[:-2].plot(kind = 'barh')
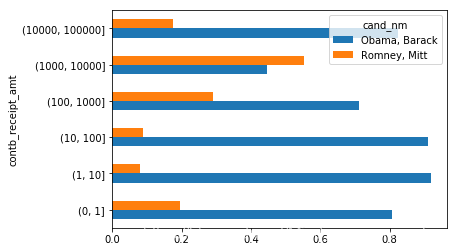
注:排除了两个最大的箱体,因为这些箱体不是由个人捐赠的。
这种分析可以通过多种方式进行改进和提高。例如,你可以通过捐助者姓名和邮政编码聚合捐款,以便为那些进行很多次小额捐赠的人进行调整,他们并不会进行大型捐赠。
4 按州进行捐赠统计
4.1 将数据按照候选人和州进行聚合
grouped = fec_mrbo.groupby(['cand_nm','contbr_st']) #按照候选人和州进行聚合totals = grouped.contb_receipt_amt.sum().unstack(0).fillna(0)totals = totals[totals.sum(1) > 100000]print(totals[:10])
cand_nm Obama, Barack Romney, Mittcontbr_st AK 281840.15 86204.24AL 543123.48 527303.51AR 359247.28 105556.00AZ 1506476.98 1888436.23CA 23824984.24 11237636.60CO 2132429.49 1506714.12CT 2068291.26 3499475.45DC 4373538.80 1025137.50DE 336669.14 82712.00FL 7318178.58 8338458.81
4.2 将每一行除以捐款总额,得到每个候选人按州的捐赠总额的相对百分比
percent = totals.div(totals.sum(1),axis = 0) #将每一行除以捐款总额,就可以得到每个候选人按州的捐赠总额的相对百分比print(percent[:10])
cand_nm Obama, Barack Romney, Mittcontbr_st AK 0.765778 0.234222AL 0.507390 0.492610AR 0.772902 0.227098AZ 0.443745 0.556255CA 0.679498 0.320502CO 0.585970 0.414030CT 0.371476 0.628524DC 0.810113 0.189887DE 0.802776 0.197224FL 0.467417 0.532583
转载地址:https://codingchaozhang.blog.csdn.net/article/details/89384593 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
做的很好,不错不错
[***.243.131.199]2024年04月09日 23时54分48秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
变局之际,聊聊物联网的过去、现在和未来
2019-04-29
缺货涨价很久的MCU的国产和国外厂家汇总!(80家)
2019-04-29
单片机6年想转嵌入式Linux ,不知如何下手?
2019-04-29
拆解 | 某平台19元的儿童电话手表,究竟怎么做到的?
2019-04-29
五一好礼70份免费送:示波器、开发板、焊台等!
2019-04-29
2纳米芯片问世!芯片性能要起飞?!
2019-04-29
ARM Cortex系列那么多处理器,该怎么区分?
2019-04-29
知乎:学计算机的女生都怎么样了?
2019-04-29
华为重磅反击,鸿蒙来了!
2019-04-29
常用电子接口大全,遇到不认识的,就翻出来对照辨认!
2019-04-29
芯片IC附近为啥要放0.1uF的电容?
2019-04-29
电赛 | 19年全国一等奖,北航学子回忆录。
2019-04-29
电赛 | 19年全国一等奖,北航学子回忆录(上)
2019-04-29
电赛 | 19年全国一等奖,北航学子回忆录(下)
2019-04-29
突破!台积电1nm芯片,有了新进展。
2019-04-29
一文读懂全系列树莓派!
2019-04-29
自制一个害羞的口罩,见人就闭嘴,戴着可以喝奶茶
2019-04-29
聊聊我是如何编程入门的
2019-04-29
J-Link该如何升级固件?
2019-04-29
485通信自动收发电路,历史上最详细的解释
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309939609 位访客
访问时间: 2024-05-02 07:35:36
访问IP: 3.17.68.14
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版