本文共 5430 字,大约阅读时间需要 18 分钟。
pandas统计学-相关性系数(pearson、spearman、kendall,pointbiserialr)
相关性检验函数
series.corr(other[, method, min_periods])
参数method:
pearson, spearman, kendall 相关性检验方法;
用途:
检查两个变量之间变化趋势的方向以及程度,值范围-1到+1,0表示两个变量不相关,正值表示正相关,负值表示负相关,值越大相关性越强。
1. person correlation coefficient(皮尔森相关性系数)
1.1.说明:
皮尔逊相关系数通常用r或ρ表示,度量两变量X和Y之间相互关系(线性相关) r=1时X与Y关系可以表示为Y=aX+b,a>0;r=-1时X与Y关系表示Y=aX+b,a<0。如X与Y相互独立相关性为0
1.2.计算公式:两变量ρ(X, Y)皮尔森相关性系数= 协方差cov(X,Y)/标准差的乘积(σX, σY)。< /FONT>
import pandas as pdimport numpy as np#原始数据X1=pd.Series([1, 2, 3, 4, 5, 6])Y1=pd.Series([0.3, 0.9, 2.7, 2, 3.5, 5])X1.mean() #平均值# 3.5Y1.mean() #2.4X1.var() #方差#3.5Y1.var() #2.9760000000000004X1.std() #标准差不能为0# 1.8708286933869707Y1.std() #标准差不能为0#1.725108692227826X1.cov(Y1) #协方差#3.0600000000000005X1.corr(Y1,method="pearson") #皮尔森相关性系数 #0.9481366640102855X1.cov(Y1)/(X1.std()*Y1.std()) #皮尔森相关性系数 # 0.9481366640102856X1.corr(Y1,method='spearman') #0.942857142857143X1.corr(Y1,method='kendall') #0.8666666666666666
2. spearman correlation coefficient(斯皮尔曼相关性系数)
秩: 可以理解成就是一种顺序或者排序,那么它就是根据原始数据的排序位置进行求解
用途:用于解决称名数据和顺序数据相关的问题。适用于两列变量,而且具有等级变量性质具有线性关系的资料。
能够很哈处理序列中相同值和异常值。
公式:
n为等级个数 d为二列成对变量的等级差数
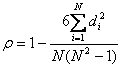
计算过程:
先对两变量(X, Y)排序,记下排序以后位置(X’, Y’),(X’, Y’)值称为秩次,秩次差值就是上面公式中的di,n就是变量中数据的个数,最后带入公式就可求解结果。
斯皮尔曼相关性系数:ρs= 1-6*(1+1+1+9)/6*35=0.657
示例
import pandas as pdimport numpy as np#原始数据X1=pd.Series([1, 2, 3, 4, 5, 6])Y1=pd.Series([0.3, 0.9, 2.7, 2, 3.5, 5])#处理数据删除Nanx1=X1.dropna()y1=Y1.dropna()n=x1.count()x1.index=np.arange(n)y1.index=np.arange(n)#分部计算d=(x1.sort_values().index-y1.sort_values().index)**2dd=d.to_series().sum()p=1-n*dd/(n*(n**2-1))#s.corr()函数计算r=x1.corr(y1,method='spearman')print(r,p) #0.942857142857143 0.9428571428571428
显示:
def show(x1,y1):print('原始位置x 原x 秩次x 排序x 原始位置y 原y 秩次y 排序y 秩次差的平方')for i in range(len(x1)):xx1=x1.sort_values();yy1=y1.sort_values()ix=x1.index[i]ixx=xx1.index[i]iy=y1.index[i]iyy=yy1.index[i]d_2=(ixx-iyy)**2print(' {:5} {:10} {:5} {:5} {:10} {:10} {:5} {:5} {:10.2f}'.format(ix,x1[i],ixx,xx1[i],iy,y1[i],iyy,yy1[i],d_2) ) show(x1,y1)
原始位置x 原x 秩次x 排序x 原始位置y 原y 秩次y 排序y 秩次差的平方 0 1 0 1 0 0.3 0 0.3 0.00 1 2 1 2 1 0.9 1 0.9 0.00 2 3 2 3 2 2.7 3 2.7 1.00 3 4 3 4 3 2.0 2 2.0 1.00 4 5 4 5 4 3.5 4 3.5 0.00 5 6 5 6 5 5.0 5 5.0 0.00
3. kendall correlation coefficient(肯德尔相关性系数)
kendalltau:等级相关系数,适用于两个变量均为有序分类的情况
用途:
肯德尔相关性系数,它也是一种秩相关系数,不过它所计算的对象是分类变量。
分类变量可以理解成有类别的变量,可以分
无序的,比如性别(男、女)、血型(A、B、O、AB);
有序的,比如肥胖等级(重度肥胖,中度肥胖、轻度肥胖、不肥胖)。
通常需要求相关性系数的都是有序分类变量。
计算公式:
R=(P-(n*(n-1)/2-P))/(n*(n-1)/2)=(4P/(n*(n-1)))-1,见附录
举例说明:
评委对选手评分(优、中、差等),想看两个(或者多个)评委对几位选手评价标准是否一致;
医院尿糖化验报告,想检验各个医院对尿糖的化验结果是否一致,可以使用肯德尔相关性系数进行衡量。
用corr函数求解method=“kendall”,假设老师对选手的评价等级---3表示优,2表示中,1表示差:
X= pd.Series([3,1,2,2,1,3])
Y= pd.Series([1,2,3,2,1,1])
Xcorr(Y,method="kendall") #-0.2611165
这时候就可以理解为两位老师对选手们的看法是呈相反趋势的,不过这种相反的程度不很大。
4.scipy.stats.pointbiserialr
scipy.stats.pointbiserialr(x,y )
计算点双线相关系数及其p值。
点双相关用于测量二元变量x和连续变量y之间的关系。与其他相关系数一样,这个相关系数在-1和+1之间变化,0表示没有相关性。-1或+1的相关性意味着确定性关系。
此函数使用快捷方式,但产生的结果相同 。
| 参数: | x : array_like bools 输入数组。 y : array_like输入数组。 |
|---|---|
| 返回: | 相关性 : 浮动 R值 pvalue : 浮动双尾p值 |
笔记


参考
| J. Lev,“The Point Biserial Coefficient of Correlation”,Ann。数学。Statist。,Vol。20,no.1,pp.125-126,1949。 |
| RF Tate,“离散变量与连续变量之间的相关性”。Point-Biserial Correlation。“,Ann。数学。Statist。,Vol。25,np。3,pp.603-607,1954。 |
例子
>>> from scipy import stats>>> a = np.array([0, 0, 0, 1, 1, 1, 1])>>> b = np.arange(7)>>> stats.pointbiserialr(a, b)(0.8660254037844386, 0.011724811003954652)>>> stats.pearsonr(a, b)(0.86602540378443871, 0.011724811003954626)>>> np.corrcoef(a, b)array([[ 1. , 0.8660254], [ 0.8660254, 1. ]])
附录:
kendall秩相关系数
kendall秩相关系数(R)。设有n个统计对象,每个对象有两个属性。将所有统计对象按属性1取值排列,不失一般性,
设此时属性2取值的排列是乱序的。设P为两个属性值排列大小关系一致的统计对象对数。则:
R=(P-(n*(n-1)/2-P))/(n*(n-1)/2)=(4P/(n*(n-1)))-1
Kendall(肯德尔)系数的定义:n个同类的统计对象按特定属性排序,其他属性通常是乱序的。同序对(
concordant pairs)和异序对(discordant pairs)之差与总对数(n*(n-1)/2)的比值定义为Kendall(肯德尔)系数。
属性:
1)如果两个属性排名是相同的,系数为1 ,两个属性正相关。
2)如果两个属性排名完全相反,系数为-1 ,两个属性。
3)如果排名是完全独立的,系数为0。
举例:
假如我们设一组8人的身高和体重在那里A的人是最高的,第三重,等等:
| 李四 | 王五 | 汤姆 | 姚明 | 巩俐 | 蔡琴 | 曹操 | 张飞 | |
| 身高 | 180 | 170 | 160 | 150 | 140 | 130 | 120 | 110 |
| 体重 | 80 | 75 | 90 | 85 | 70 | 60 | 55 | 65 |
我们看到,有一些相关的两个排名之间的相关性,可以使用肯德尔头系数,客观地衡量对应。
注意,A最高,但体重排名为 3 ,比体重排名为 4,5,6,7,8 的重,贡献5个同序对,即AB,AE,AF,AG,AH。
同理,我们发现B、C、D、E、F、G、H分别贡献4、5、4、3、1、0、0个同序对,因此,
P = 5 + 4 + 5 + 4 + 3 + 1 + 0 + 0 = 22.
因而R=(88/56)-1=0.57。这一结果显示出强大的排名之间的规律,符合预期。
程序如下:
import pandas as pdimport numpy as np
#原始数据height=pd.Series([180,170,160,150,140,130,120,110])weight=pd.Series([80,75,90,85,70,60,55,65])
# 处理数据n=weight.count()df=pd.DataFrame({'a':height,'b':weight})df1=df.sort_values('b',ascending=False)df1.index=np.arange(1,df.a.count()+1)df2=df1.sort_values('a',ascending=False)s=pd.Series(df2.index) P=0for i in s.index: P=P+s[s > s[i]].count() s=s.drop(i)
#方法1 R=(P-(n*(n-1)/2-P))/(n*(n-1)/2)=(4P/(n*(n-1)))-1R1 =(P - (n * (n - 1) / 2 - P)) / (n * (n - 1) / 2)#0.5714285714285714print('R1=',R1)R2= (4*P / (n * (n-1)))-1 #0.5714285714285714print('R2=',R2) #方法2corr函数计算r1=height.corr(weight,method='kendall') #0.5714285714285714print('r1=',r1)r2=weight.corr(height,method='kendall') #0.5714285714285714print('r2=',r2)
转载地址:https://chunyou.blog.csdn.net/article/details/83910011 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
