爬虫学习(1):urlopen库使用
 知道这个类型就行了,不废话的去解读
知道这个类型就行了,不废话的去解读 
发布日期:2021-06-29 14:38:35
浏览次数:2
分类:技术文章
本文共 1125 字,大约阅读时间需要 3 分钟。
以爬取CSDN为例子:
第一步:导入请求库 第二步:打开请求网址 第三步:打印源码import urllib.requestresponse=urllib.request.urlopen("https://www.csdn.net/?spm=1011.2124.3001.5359")print(response.read().decode('utf-8')) 结果大概就是这个样子:
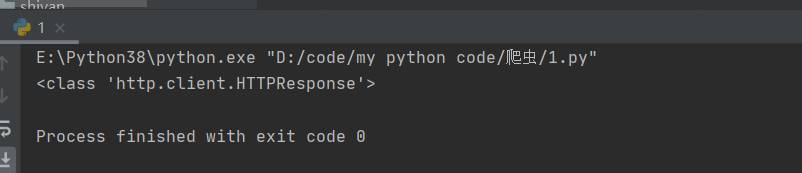
好的,继续,看看打印的是什么类型的:
import urllib.requestresponse=urllib.request.urlopen("https://www.csdn.net/?spm=1011.2124.3001.5359")# print(response.read().decode('utf-8'))print(type(response)) 结果:
知道这个类型就行了,不废话的去解读 ok,再看看别的,比如(解释都在注释了)
import urllib.requestresponse=urllib.request.urlopen("https://www.csdn.net/?spm=1011.2124.3001.5359")# print(response.read().decode('utf-8'))print(type(response))#打印网页类型print(response.status)#打印返回结果的状态print(response.getheaders())#打印响应头信息 
再来看看timeout使用:设置请求时间最长可以是多久,超过就不请求了
import urllib.requestresponse=urllib.request.urlopen("https://www.csdn.net/?spm=1011.2124.3001.5359",timeout=0.1)# print(response.read().decode('utf-8'))# print(type(response))#打印网页类型# print(response.status)#打印返回结果的状态# print(response.getheaders())#打印响应头信息print(response.read()) 为了显示出报错,我就设置了时间为0.1秒,timeout就直接放在打开网页旁边就好了:报错The read operation timed out就是请求超时,0.1秒嘛,肯定超过0.1秒了,就自然报错了
最基本爬取网页,后续待更新
这是我qq群970353786,非盈利转载地址:https://chuanchuan.blog.csdn.net/article/details/113100388 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
初次前来,多多关照!
[***.217.46.12]2024年05月02日 13时02分53秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
利用MySQL进行数据复杂查询(1)
2019-04-29
MySQL 表与表之间的关系
2019-04-29
pymysql 的基础应用
2019-04-29
Python 管理程序改进——连接MYSQL
2019-04-29
Python 爬虫-豆瓣影星图片下载
2019-04-29
网页端数据库操作界面—主题函数文件
2019-04-29
网页端数据库操作界面-Html页面(1)
2019-04-29
Python爬虫 百度热搜热点
2019-04-29
excel的常用函数(二)
2019-04-29
excel文本函数
2019-04-29
电商大战二十年
2019-04-29
编程程软件测试思维方式:如何科学制定测试计划
2019-04-29
BLE蓝牙4.0串口调试助手
2019-04-29
树莓派WIFI设置
2019-04-29
nanopi2 启动信息
2019-04-29
phpstudy https
2019-04-29
Linux下EasyPanel版本安装及升级
2019-04-29
raspberry pi(树莓派) + easycap d60 视频采集
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310050942 位访客
访问时间: 2024-05-02 15:12:29
访问IP: 18.222.67.251
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版