本文共 2825 字,大约阅读时间需要 9 分钟。
吴恩达视频课笔记,网易云课堂
Machine Learning Definition
A computer program is said to learn from experience E with respect to some task T and some performance measure P,if its performance on T, as measured by p,improves with experience E;
(个人认识:经验(训练集)E,目标任务T,性能度量P) question1:
#机器学习主要分为有监督学习和无监督学习
Machine learning algorithms: 1.Supervised learning:the idea is that we are going to teach computer how to do something; 2.Unsupervised learning: we are going to let it learn by itself;Supervised learning (有监督学习)
an example of supervision learning:
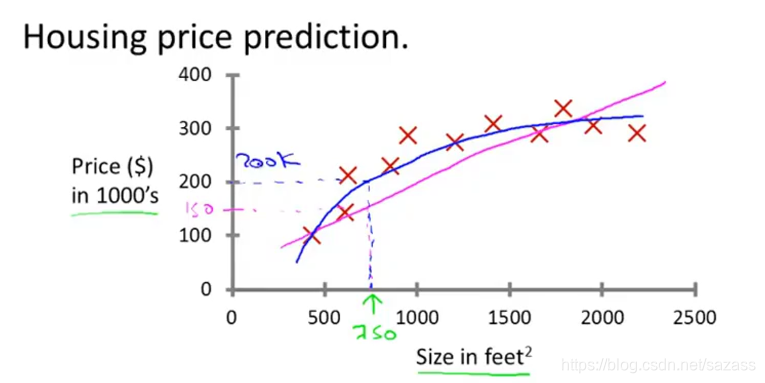 (根据 数据集中特征:面积,来训练模型预估房价)
(根据 数据集中特征:面积,来训练模型预估房价) Supervised learning refers to the fact that we gave the algorithm a data set,in which the ‘right answers’ were given, and the algorithm was to just produce more of these right answers.
#有监督学习:给算法一个数据集,其中包含了"正确答案"(标签),算法的目的就是给出更多的正确答案;Regression problem(回归问题):we are trying to predict a continuous valued output.
#预测连续的数值输出(上述房价问题属于回归问题)this is a example of a classification problrm(分类问题):
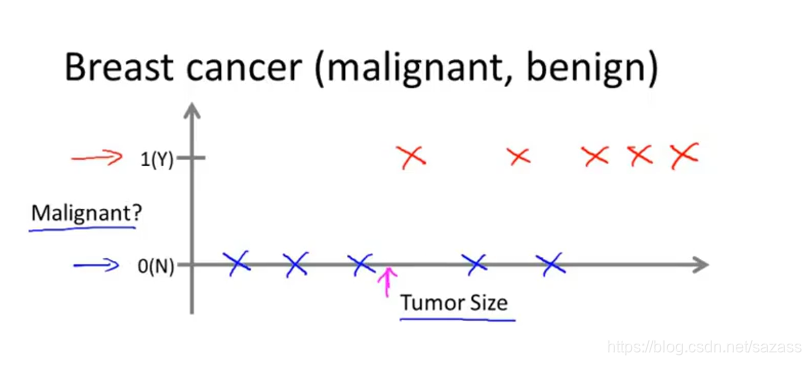 (根据数据集中特征:瘤的尺寸,训练模型来判断瘤属于良性或是恶性)
(根据数据集中特征:瘤的尺寸,训练模型来判断瘤属于良性或是恶性) The trem Classification refers to the fact that here we are trying to predict a discrete(离散值) valued output.
#分类是指我们设法预测一个离散值输出。 分类问题中的离散值输出可以不止2个;机器学习还可以学习多个特征:
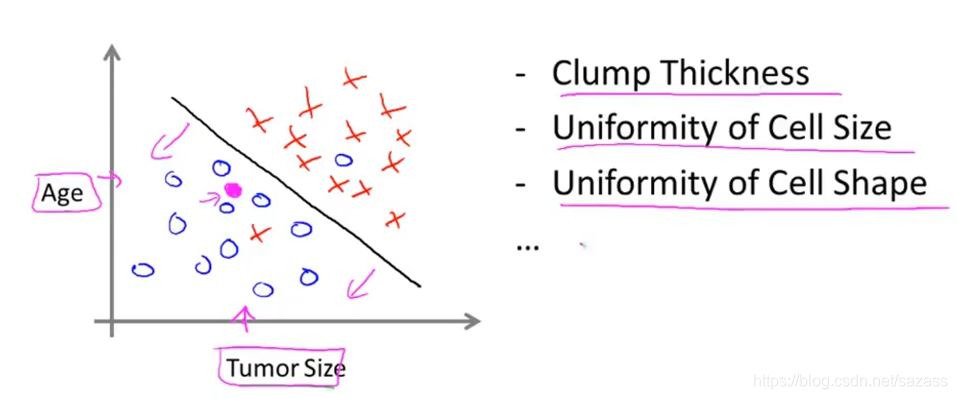 Summary: Supervised learning;Regression problem;classification problrm question2:
Summary: Supervised learning;Regression problem;classification problrm question2: 
Unsupervised Learning(无监督学习)
this is a example of a Unsupervised Learning:
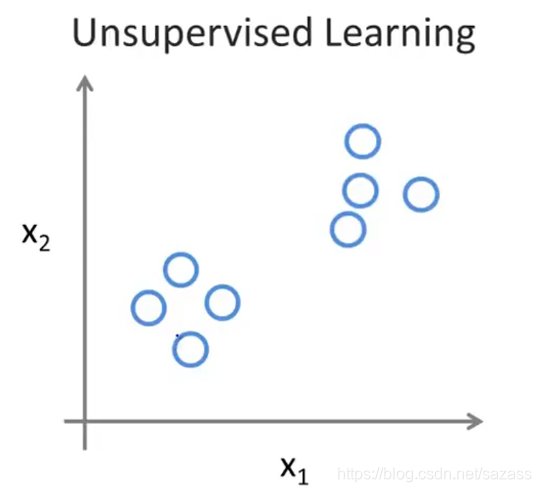 (Does not have any labels or that all has the same labels or really no labels)
(Does not have any labels or that all has the same labels or really no labels) Given this data set , an Unsupervised learning algorithm might that the data lives in two different clusters. So this is called a clustering algorithm(聚类算法)
无监督学习理解:只有数据集,没有明确标签,让计算机自己去学习;
聚类算法:属于无监督学习,为无标签数据集分类;应用案例(Google网页新闻链接,相类似的新闻会被聚类算法归类到统一族,并被放到一起)无监督学习的另一案例:分离一段音频中混合的声音;
简洁的一行代码实现(利用octave):
Advise:
you learn much faster if you use Octave as your programming environment ,and if you use Octave as you learning tool and as your prototyping tool,it will let you learn and prototype`learning algorithm much more quickly.question:

梯度下降
一元变量线性回归案例:
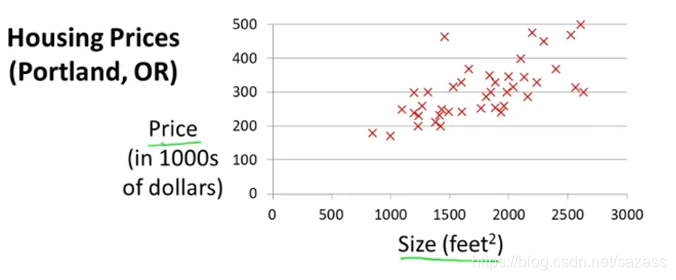
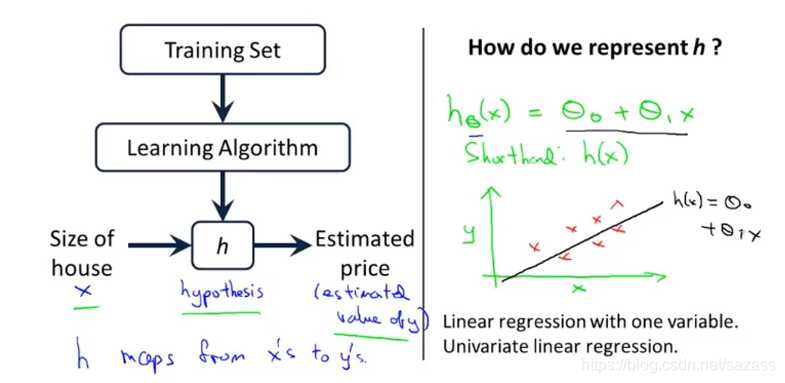
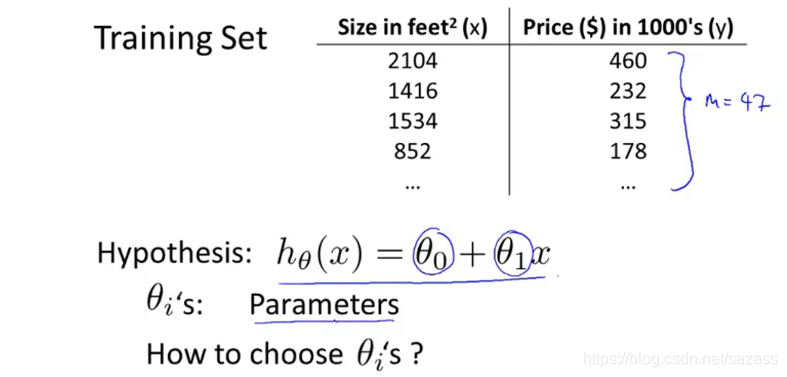 我们需要代价函数来衡量假设函数的拟合程度:
我们需要代价函数来衡量假设函数的拟合程度: 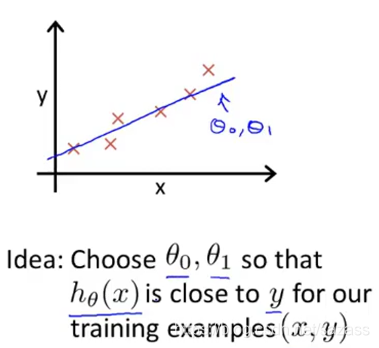
代价函数:一般常见的有最小化平方差代价函数,可得出误差值,具体如下:
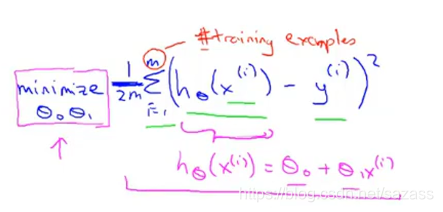 总结:
总结:  我们可以继续简化:
我们可以继续简化: 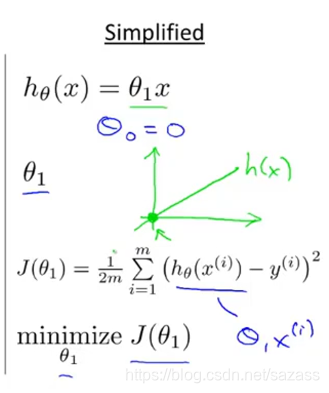
不同的模型参数对应不同的假设函数:
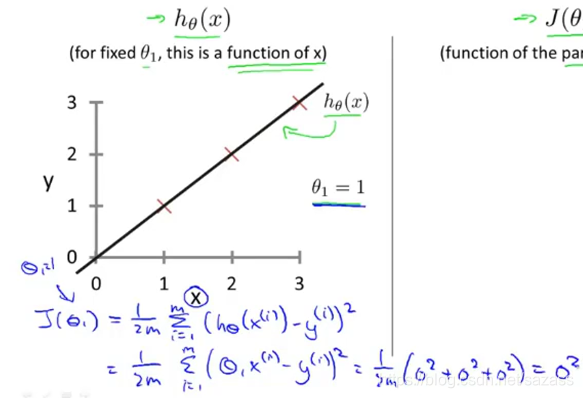
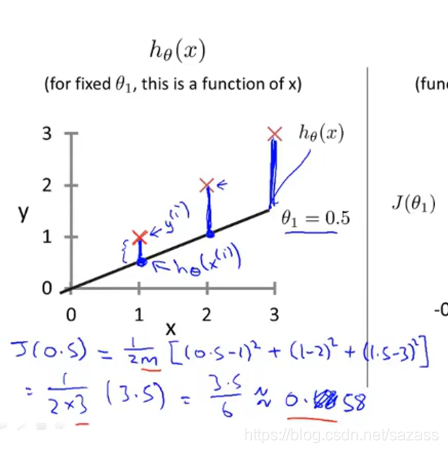
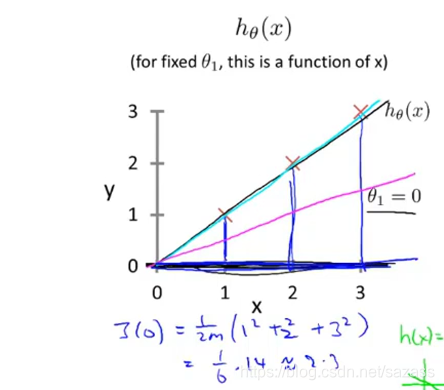 根据这些数据我们可以得到代价函数的图像:
根据这些数据我们可以得到代价函数的图像: 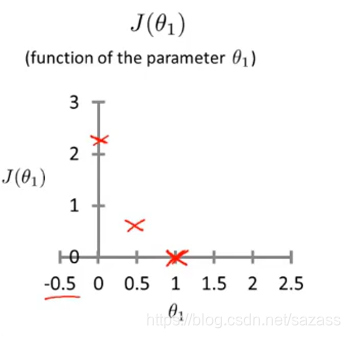 继续推演可得到:
继续推演可得到: 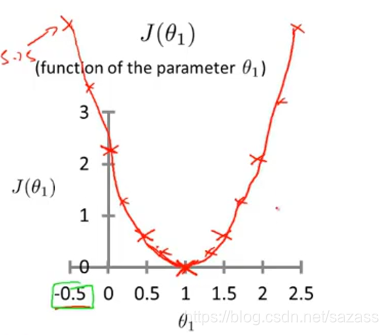 存在一个最低点,再最低点误差值最小,模型与数据集拟合度最高;
存在一个最低点,再最低点误差值最小,模型与数据集拟合度最高; 以上是单变量线性回归问题;
我们继续研究两个变量的线性回归问题,以下是双变量的代价函数图像: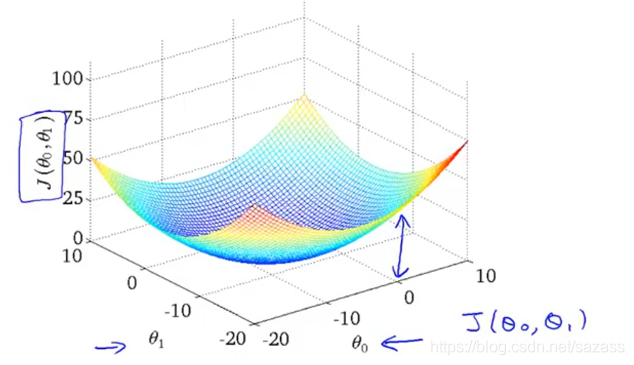 我们可以用以下两个二维图来表示这个模型: 等高线图上的每一点都对应着一组模型参数组合,代表着一个假设函数;
我们可以用以下两个二维图来表示这个模型: 等高线图上的每一点都对应着一组模型参数组合,代表着一个假设函数; 等高线图中,横坐标与纵坐标分别表示一种模型参数,而每个椭圆上的所有点的误差值都相同;
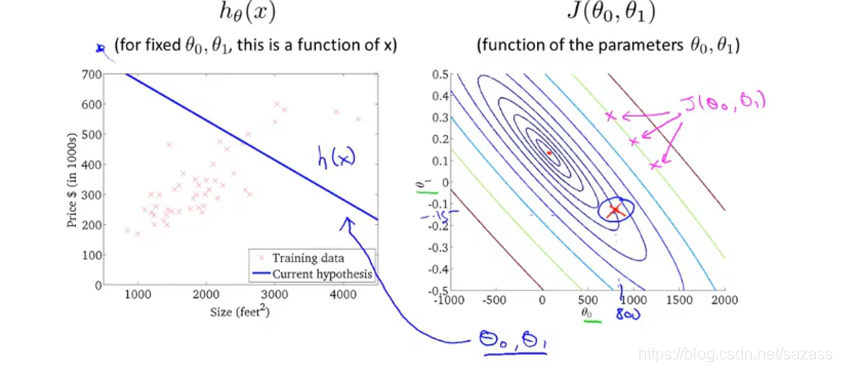 可以在等高线图找出误差值近似最小的点:
可以在等高线图找出误差值近似最小的点: 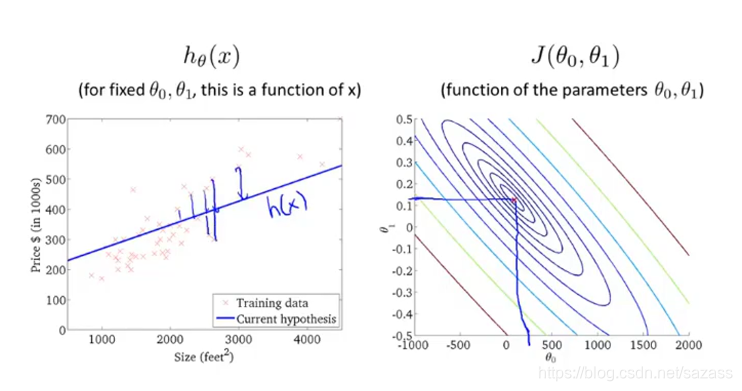
那么我们要解决的问题是如何找到对应的模型参数,使得误差值达到最小值:
我们下面介绍梯度下降算法;梯度下降算法
在以下的双变量代价函数图像中,
想象有山,我们目的是从山上走下来: 在任意一个起点开始,一步一步往低处走去:
在任意一个起点开始,一步一步往低处走去: 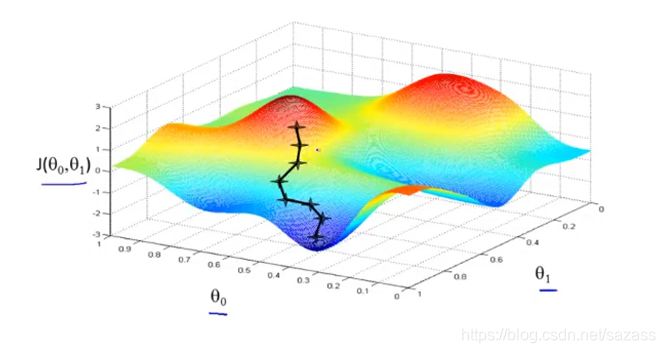 梯度下降算法有一个特点,若是初始点不一致,最后可能走向不同的局部最低点:
梯度下降算法有一个特点,若是初始点不一致,最后可能走向不同的局部最低点: 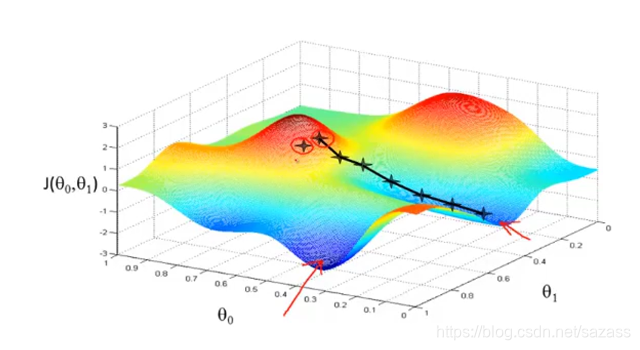 下面是梯度下降算法的具体公式: 模型参数 = 模型参数 - 步长*偏导数 *误差值 :=是赋值运算符
下面是梯度下降算法的具体公式: 模型参数 = 模型参数 - 步长*偏导数 *误差值 :=是赋值运算符  在两个模型参数的情景中,我们每次都需要更新模型参数,以下是错误做法(每次各个模型参数要同时更新赋值,不可存在先后):
在两个模型参数的情景中,我们每次都需要更新模型参数,以下是错误做法(每次各个模型参数要同时更新赋值,不可存在先后): 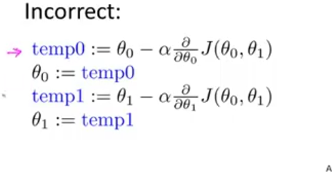
我们在最简单的单变量线性回归问题中运用梯度下降算法:
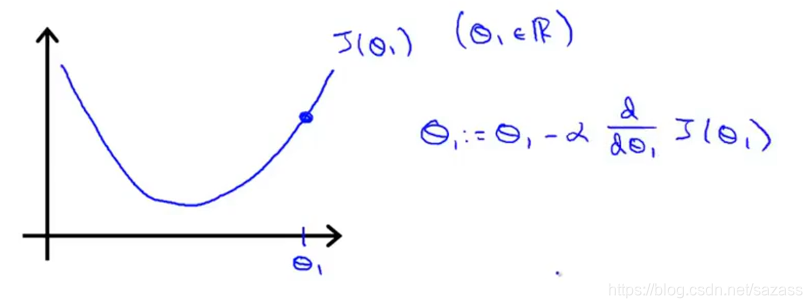
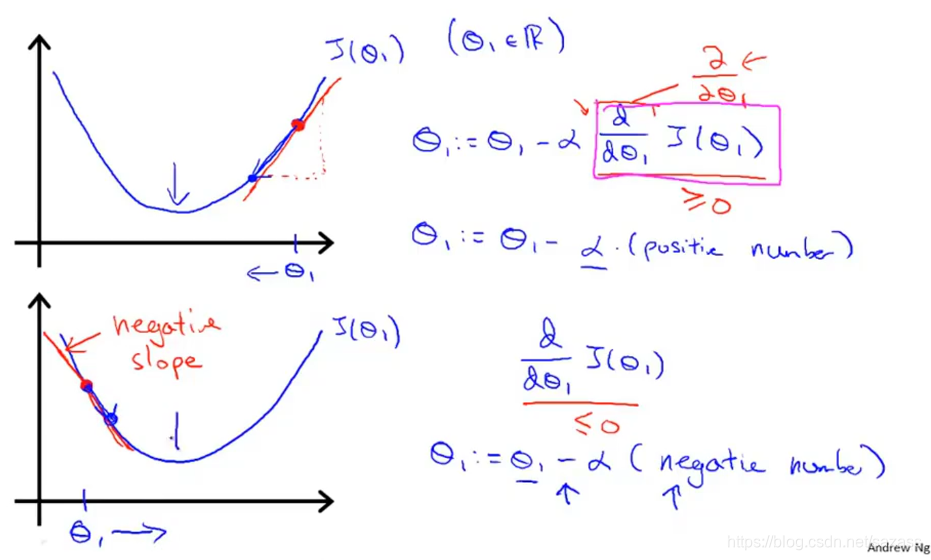
learning rate:步长
步长过小:则训练速度过慢 步长过大:则可能出现越来越偏离最低点,永远达不到最低点的情况: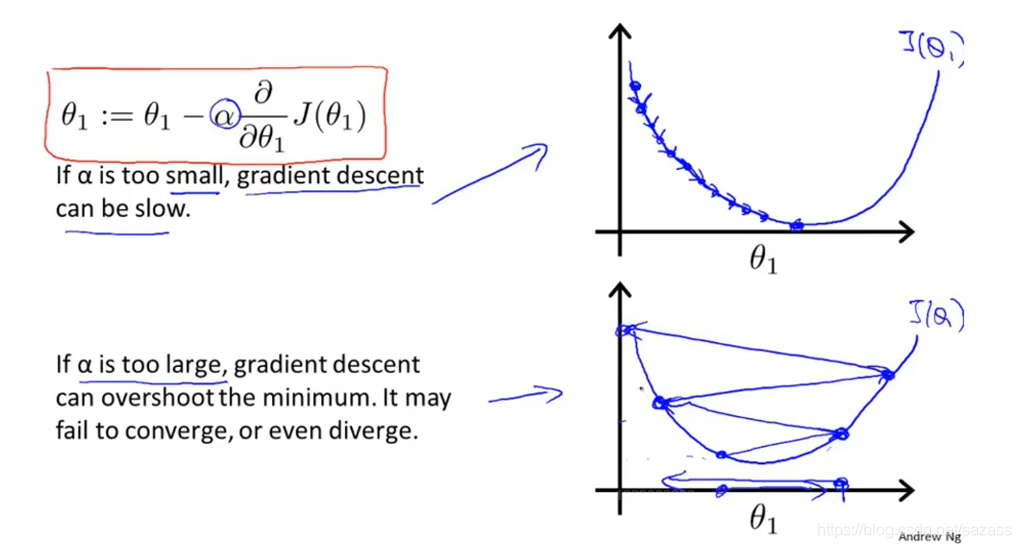
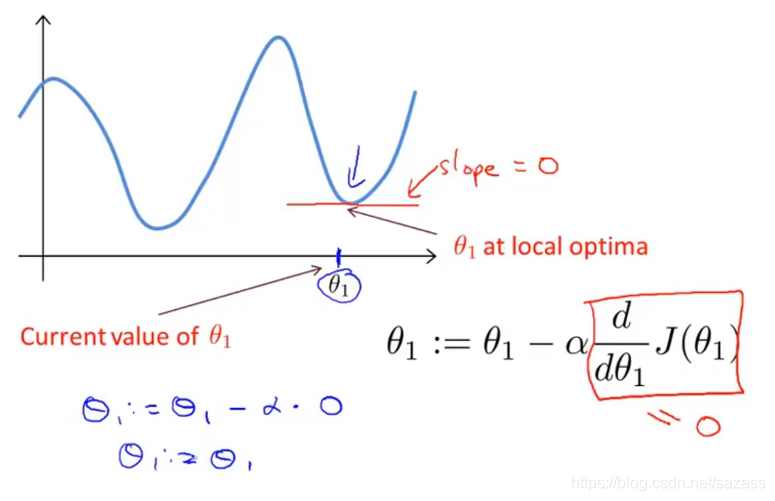
以下是对梯度下降算法公式的展开:
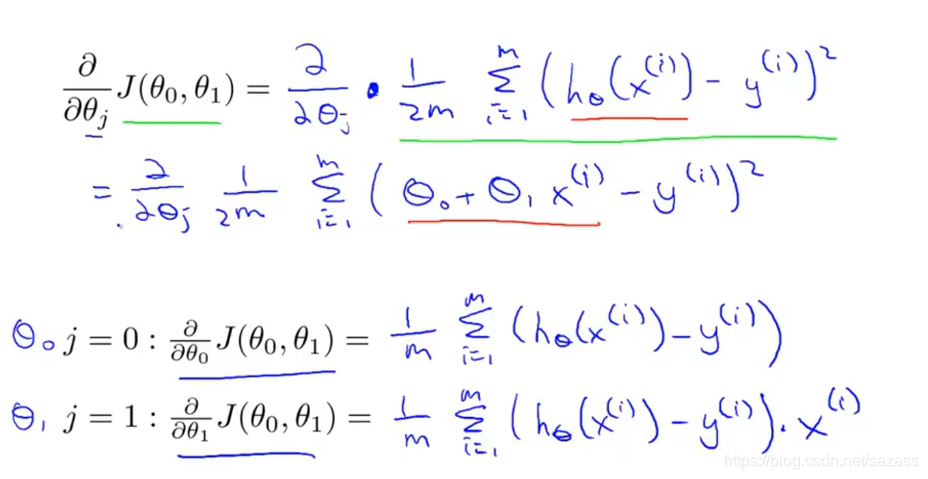
Summary


“batch” :每一步都遍历整个数据集

也可以抽样方式每布遍历少量数据
转载地址:https://chenlinwei.blog.csdn.net/article/details/87820138 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
