本文共 3448 字,大约阅读时间需要 11 分钟。
导读:本文将讨论监督学习、无监督学习和强化学习这三种类型的机器学习。
作者:塞巴斯蒂安·拉施卡(Sebastian Raschka)、瓦希德·米尔贾利利(Vahid Mirjalili)
来源:大数据DT(ID:hzdashuju)
了解三者之间的根本差别,并通过概念性的示例,我们将形成可应用于实际问题领域的见解,如图1-1所示。

▲图 1-1
01 用监督学习预测未来
监督学习的主要目标是从有标签的训练数据中学习模型,以便对未知或未来的数据做出预测。在这里“监督”一词指的是已经知道训练样本(输入数据)中期待的输出信号(标签)。
图1-2总结了一个典型的监督学习流程,先为机器学习算法提供打过标签的训练数据以拟合预测模型,然后用该模型对未打过标签的新数据进行预测。

▲图 1-2
以垃圾邮件过滤为例,可以采用监督机器学习算法在打过标签的(正确标识垃圾与非垃圾)电子邮件的语料库上训练模型,然后用该模型来预测新邮件是否属于垃圾邮件。
带有离散分类标签的监督学习任务也被称为分类任务,例如上述的垃圾电子邮件过滤示例。监督学习的另一个子类被称为回归,其结果信号是连续的数值。
1. 用于预测类标签的分类
分类是监督学习的一个分支,其目的是根据过去的观测结果来预测新样本的分类标签。这些分类标签是离散的无序值,可以理解为样本的组成员关系。前面提到的邮件垃圾检测就是典型的二元分类任务,机器学习算法学习规则以区分垃圾和非垃圾邮件。
图1-3将通过30个训练样本阐述二元分类任务的概念,其中15个标签为负类(-),另外15个标签为正类(+)。该数据集为二维,这意味着每个样本都与x1和x2的值相关。现在,可以通过监督机器学习算法来学习一个规则——用一条虚线来表示决策边界——区分两类数据,并根据x1和x2的值为新数据分类。
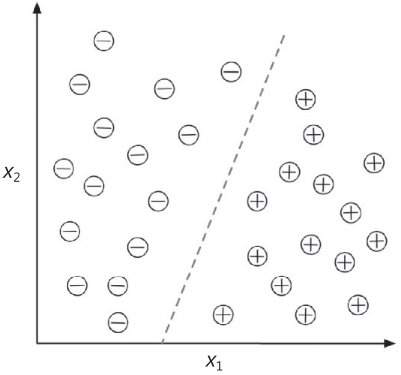
▲图 1-3
但是,类标签集并非都是二元的。经过监督学习算法学习所获得的预测模型可以将训练数据集中出现过的任何维度的类标签分配给尚未打标签的新样本。
多类分类任务的典型示例是手写字符识别。首先,收集包含字母表中所有字母的多个手写示例所形成的训练数据集。字母(“A”“B”“C”等)代表我们要预测的不同的无序类别或类标签。然后,当用户通过输入设备提供新的手写字符时,预测模型能够以某一准确率将其识别为字母表中的正确字母。
然而,该机器学习系统却无法正确地识别0到9之间的任何数字,因为它们并不是训练数据集中的一部分。
2. 用于预测连续结果的回归
上一节学习到分类任务是为样本分配无序的分类标签。第二类监督学习是对连续结果的预测,也称为回归分析。回归分析包括一些预测(解释)变量和一个连续的响应变量(结果),试图寻找那些变量之间的关系,从而能够让我们预测结果。
注意,机器学习领域的预测变量通常被称为“特征”,而响应变量通常被称为“目标变量”。
以预测学生SAT数学成绩为例。假设学习时间与考试成绩相关,以此为训练数据通过机器学习建模,用将来打算参加该项考试学生的学习时间来预测其考试成绩。
均值回归
1886年,Francis Galton在其论文Regression towards Mediocrity in Hereditary Stature中首次提到回归一词。Galton描述了一种生物学现象,即种群身高的变化不会随时间的推移而增加。
他观察到父母的身高不会遗传给自己的孩子,相反,孩子的身高会回归到总体均值。
图1-4说明了线性回归的概念。给定特征变量x和目标变量y,对数据进行线性拟合,最小化样本点和拟合线之间的距离——最常用的平均平方距离。

▲图 1-4
现在可以用从该数据中学习到的截距和斜率来预测新数据的目标变量。
02 用强化学习解决交互问题
另一类机器学习是强化学习。强化学习的目标是开发一个系统(智能体),通过与环境的交互来提高其性能。当前环境状态的信息通常包含所谓的奖励信号,可以把强化学习看作一个与监督学习相关的领域。
然而强化学习的反馈并非标定过的正确标签或数值,而是奖励函数对行动度量的结果。智能体可以与环境交互完成强化学习,并通过探索性的试错或深思熟虑的规划来最大化这种奖励。
强化学习的常见示例是国际象棋。智能体根据棋盘的状态或环境来决定一系列的行动,奖励定义为比赛的输或赢,如图1-5所示。

▲图 1-5
强化学习有许多不同的子类。然而,一般模式是强化学习智能体试图通过与环境的一系列交互来最大化奖励。每种状态都可以与正或负的奖励相关联,奖励可以被定义为完成一个总目标,如赢棋或输棋。例如国际象棋每走一步的结果都可以认为是环境的一个不同状态。
为进一步探索国际象棋的示例,观察一下棋盘上与赢棋相关联的某些状况,比如吃掉对手的棋子或威胁皇后。也注意一下棋盘上与输棋相关联的状态,例如在接下来的回合中输给对手一个棋子。下棋只有到了结束的时候才会得到奖励(无论是正面的赢棋还是负面的输棋)。
另外,最终的奖励也取决于对手的表现。例如,对手可能牺牲了皇后,但最终赢棋了。
强化学习涉及根据学习一系列的行动来最大化总体奖励,这些奖励可能即时获得,也可能延后获得。
03 用无监督学习发现隐藏的结构
监督学习训练模型时,事先知道正确的答案;在强化学习的过程中,定义了智能体对特定行动的奖励。然而,无监督学习处理的是无标签或结构未知的数据。用无监督学习技术,可以在没有已知结果变量或奖励函数的指导下,探索数据结构来提取有意义的信息。
1. 用聚类寻找子群
聚类是探索性的数据分析技术,可以在事先不了解成员关系的情况下,将信息分成有意义的子群(集群)。为在分析过程中出现的每个集群定义一组对象,集群的成员之间具有一定程度的相似性,但与其他集群中对象的差异性较大,这就是为什么聚类有时也被称为无监督分类。
聚类是一种构造信息和从数据中推导出有意义关系的有用技术。例如,它允许营销人员根据自己的兴趣发现客户群,以便制定不同的市场营销计划。
图1-6解释了如何应用聚类把无标签数据根据x1和x2的相似性分成三组。

▲图 1-6
2. 通过降维压缩数据
无监督学习的另一个子类是降维。我们经常要面对高维数据。高维数据的每个观察通常都伴随着大量的测量数据,这对有限的存储空间和机器学习算法的计算性能提出了挑战。
无监督降维是特征预处理中一种常用的数据去噪方法,不仅可以降低某些算法对预测性能的要求,而且可以在保留大部分相关信息的同时将数据压缩到较小维数的子空间上。
有时降维有利于数据的可视化,例如,为了通过二维散点图、三维散点图或直方图实现数据的可视化,可以把高维特征数据集映射到一维、二维或三维特征空间。图1-7展示了一个采用非线性降维将三维瑞士卷压缩成新的二维特征子空间的示例。

▲图 1-7
关于作者:塞巴斯蒂安·拉施卡(Sebastian Raschka),密歇根州立大学博士,他在计算生物学领域提出了几种新的计算方法,还被科技博客Analytics Vidhya评为GitHub上最具影响力的数据科学家。
瓦希德·米尔贾利利(Vahid Mirjalili),密歇根州立大学计算机视觉与机器学习研究员,致力于把机器学习应用到各种计算机视觉研究项目。他在学术和研究生涯中积累了丰富的Python编程经验,其主要研究兴趣为深度学习和计算机视觉应用。
本文摘编自《Python机器学习(原书第3版)》,经出版方授权发布。

延伸阅读《Python机器学习(原书第3版)》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:本书自第1版出版以来,备受广大读者欢迎。与同类书相比,本书除了介绍如何用Python和基于Python的机器学习软件库进行实践外,还对机器学习概念的必要细节进行讨论,同时对机器学习算法的工作原理、使用方法以及如何避免掉入常见的陷阱提供直观且翔实的解释,是Python机器学习入门必读之作。

划重点????
干货直达????
更多精彩????
在公众号对话框输入以下关键词
查看更多优质内容!
PPT | 读书 | 书单 | 硬核 | 干货 | 讲明白 | 神操作
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 1024 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号
????
转载地址:https://blog.csdn.net/zw0Pi8G5C1x/article/details/118061176 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
