本文共 4062 字,大约阅读时间需要 13 分钟。
本文参考:,
1. 字符串子串查找算法KMP
给定一个主串(以 S 代替)和模式串(以 P 代替),要求找出 P 在 S 中出现的位置,此即串的模式匹配问题。Knuth-Morris-Pratt 算法(简称 KMP)是解决这一问题的常用算法之一。
KMP算法与其他字符串子串查找的典型的区别是它先计算子串本身存在的一些相关信息,这样可以保证每次匹配不用从最开始位置查找,而是从最佳的位置开始匹配,从而提高了查找的效率,保证复杂度在O(n+m)规模。KMP算法的精华部分就在于求模式匹配的next数组,如果对状态机有所了解,就能很好的理解这一思想

代码实现:
class Solution: def getnext(self, pstr): pstrlen = len(pstr) next = [-1] * pstrlen i, k = 0, -1 while i < pstrlen - 1: # k = -1时说明i已经在最最左边了,下一步只能往右移动,所以i和k都加1 # pstr[i] = pstr[k]时,说明后缀和前缀匹配的长度增加,所以i和k都加1 if k == -1 or pstr[i] == pstr[k]: i += 1 k += 1 # 为了减少重复计算,当两个字符相等时跳过该位置 if pstr[i] == pstr[k]: next[i] = next[k] else: next[i] = k else: # 当pstr[i] != pstr[k]时,根据next定义,此时k要跳到next[k]位置 k = next[k] return next def strStr(self, tstr, pstr): """ :type tstr: str :type pstr: str :rtype: int """ if len(pstr) < 1: return 0 if len(tstr) < 1: return -1 pstrlen = len(pstr) tstrlen = len(tstr) next = self.getnext(pstr) print(next) i, j = 0, 0 while i < tstrlen and j < pstrlen: if j == -1 or tstr[i] == pstr[j]: i += 1 j += 1 else: j = next[j] if j == pstrlen: return i - j return -1
具体算法解释可以参考:
2.最长连续公共子序列
要求两个字符串的最长连续公共子序列,一般采用的方法是后缀数组法,即先分别求出两个串的后缀数组,然后比较它们之间的连续公共长度。这个有个处理技巧就是为了确认哪个后缀数组属于哪个串,需要在其中一个串后面贴一个标签,避免混淆。

当然另一种是使用动态规划进行求解,因此求出问题的状态转移方程至关重要。下面是求解最长连续公共子序列的状态转移方程,知道了状态转移方程,求解就变得很简单了。
class Solution: def ConsecutiveLCS(self,s1,s2): s1Len=len(s1) s2Len=len(s2) arr=[[0]*(s2Len+1) for i in range(s1Len+1)] res=0 for i in range(1,s1Len+1): for j in range(1,s2Len+1): if s1[i-1]==s2[j-1]: arr[i][j]=arr[i-1][j-1]+1 if res
3.最长公共子序列
要求两个串的公共子序列,则这些子序列不一定是连续的,如下图所示。
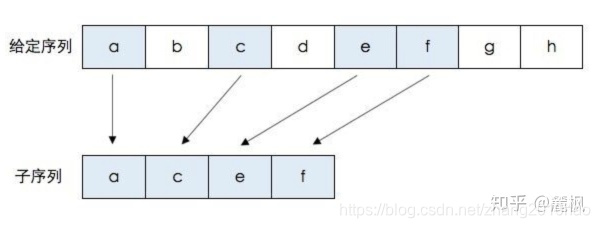
对于这类问题通常的解法是采用动态规划,状态转移方程如下所示:
class Solution: def LCS(self,s1,s2): s1Len=len(s1) s2Len=len(s2) arr=[[0]*(s2Len+1) for i in range(s1Len+1)] for i in range(1,s1Len+1): for j in range(1,s2Len+1): if s1[i-1]==s2[j-1]: arr[i][j]=arr[i-1][j-1]+1 else: arr[i][j]=max(arr[i-1][j],arr[i][j-1]) return arr[s1Len][s2Len]
4.编辑距离算法
编辑距离,又称Levenshtein距离(莱文斯坦距离也叫做Edit Distance),是指两个字串之间,由一个转成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它们越是不同。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
在概念中,我们可以看出一些重点那就是,编辑操作只有三种。插入,删除,替换这三种操作,我们有两个字符串,将其中一个字符串经过上面的这三种操作之后,得到两个完全相同的字符串付出的代价是什么就是我们要讨论和计算的。在这里我们设置每经过一次编辑,也就是变化(插入,删除,替换)我们花费的代价都是1。编辑距离的作用主要是用来比较两个字符串的相似度的。
对于这类问题,我们可以采用动态规划进行解决:用f[m-1,n]+1表示增加操作,f[m,n-1]+1 表示我们的删除操作,f[m-1,n-1]+temp(str1[i] == str2[j],用temp记录它,为0;否则temp记为1)表示我们的替换操作。状态转移方程为:
代码:
class Solution: def EditDistance(self,s1,s2): s1Len=len(s1) s2Len=len(s2) arr=[[0]*(s2Len+1) for i in range(s1Len+1)] for i in range(s1Len+1): arr[i][0]=i for i in range(s2Len+1): arr[0][i]=i for i in range(1,s1Len+1): for j in range(1,s2Len+1): tmp=1 if s1[i-1]==s2[j-1]: tmp=0 arr[i][j]=min([arr[i][j-1]+1,arr[i-1][j]+1,arr[i-1][j-1]+tmp]) return arr[s1Len][s2Len]
5.Jaccard相似度(杰卡德相似度)
杰卡德相似度,指的是文本A与文本B中交集的字数除以并集的字数,公式非常简单:
例:计算“荒野求生”和“绝地求生”的杰卡德相似度。
因为它们交集是{求,生},并集是{荒,野,求,生,绝,地},所以它们的杰卡德相似度=2/6=1/3。
杰卡德相似度与文本的位置、顺序均无关,比如“王者荣耀”和“荣耀王者”的相似度是100%。无论“王者荣耀”这4个字怎么排列,最终相似度都是100%。
在某些情况下,会先将文本分词,再以词为单位计算相似度。比如将“王者荣耀”切分成“王者/荣耀”,将“荣耀王者”切分成“荣耀/王者”,那么交集就是{王者,荣耀},并集也是{王者,荣耀},相似度恰好仍是100%。
适用场景
1)对字/词的顺序不敏感的文本,比如前述的“零售批发”和“批发零售”,可以很好地兼容。
2)长文本,比如一篇论文,甚至一本书。如果两篇论文相似度较高,说明交集比较大,很多用词是重复的,存在抄袭嫌疑。
不适用场景
1)重复字符较多的文本,比如“这是是是是是是一个文本”和“这是一个文文文文文文本”,这两个文本有很多字不一样,直观感受相似度不会太高,但计算出来的相似度却是100%(交集=并集)。
2)对文字顺序很敏感的场景,比如“一九三八年”和“一八三九年”,杰卡德相似度是100%,意思却完全不同。
转载地址:https://blog.csdn.net/zhang2010hao/article/details/85790702 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
